
Pipeline MIPS #1

- Single Cycle Processor의 경우, Critical Path Delay가 길면 길수록 Clock Frequency가 낮아진다는 단점이 있다.
- Critical Path를 줄이는 가장 전통적이고 단순한 방법으로는 Moore's Law에 의존하는 방법이 있다.
- 즉, 계속해서 Scaling되는 회로 소자로 인해 전자의 양과 전자의 이동 거리가 줄어들어 똑같은 기능을 더 빠르고 더욱 적은 에너지로 구현할 수 있게 하는 방식이다.
- 공정이 5nm 이하로 구현될 수 있다는 의견에는 회의적인 시각이 많다. 즉, 앞으로는 Moore의 법칙에 기댈것이 아니라, 마이크로 아키텍처의 설계를 개선하여 성능을 향상시키는 방향으로 나아가야 한다.
- 이에 대한 해결방안(성능 향상책) 중 하나로 Pipelining이 있다.

- 4명의 사람이 세탁을 진행하고자 한다. 세탁의 과정은 Wash, Sry, Fold 세 단계로 구성되며, 각 단계에서의 소요 시간은 위의 그림과 같다.

- Sequential하게(순서대로, 겹치지 않게) 세탁을 진행할 경우이다.
- Response Time은 90mins이다. (Wash, Dry, Fold 세 단계를 진행하기까지 소요되는 시간)
- Throughput은 0.67 Tasks/hour이다. (90분동안 하나의 Task가 수행되므로, 60분동안 0.67개의 Task를 수행할 수 있다.)
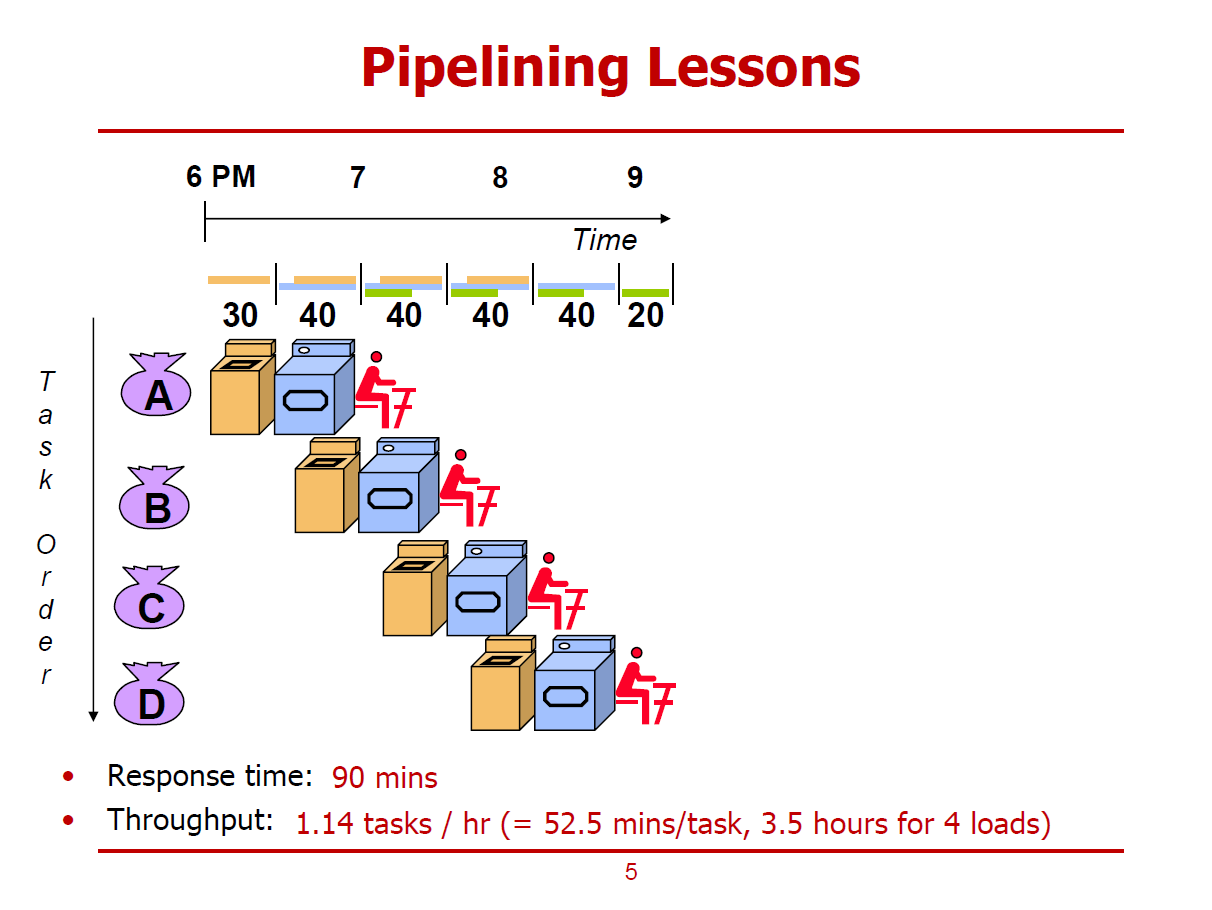
- Sequential한 Laundry처리 방식 대신, Pipelining을 적용한 경우이다.
- Sequential한 Laundry처리 방식과 가장 큰 차이점은, 동시에 복수의 Task를 처리할 수 있다는 점이다.
- Pipelining 방식의 가장 큰 특징은, 주어진 시간 동안 Multitasking이 가능하다는 점이다.
- Pipelining 방식으로 Response Time을 개선할 수는 없으나, Throughput은 개선할 수 있다.
- Response Time은 90mins이다. (Wash, Dry, Fold 세 단계를 진행하기까지 소요되는 시간, 순차적으로 수행했을 때와 차이가 없다.)
- Throughput은 1.14 Tasks/hour이다. (210분동안 4개의 Task가 수행되므로, 60분동안 1.14개의 Task를 수행할 수 있다.)

- Pipelining 방식을 Microprocessor에 적용한 경우이다.
- Pipeline 방식을 적용하는 근본적인 이유는 Throughput을 개선시키기 위함이다.
- 하나의 Instruction을 처리하는 과정을 5개의 Stage로 나누고, 이를 Sequential하게 처리하는 방식과 Pipelined 방식으로 처리하는 것을 표현한 것이다.
Stage 1 : Instruction Fetch
- Instruction Memory로 부터 하나의 Word를 읽어오는 과정이다.
- 2ns가 소요된다 가정한다.
Stage 2 : Register File Access (Read)
- 읽어온 명령어를 해석함과 동시에 Register File에 접근하는 과정이다.
- MIPS의 명령어들은 규칙적인 구조를 갖고 있어, 어떤 Bit Field가 Operand로 사용되는지가 정해져 있어 그에 해당되는 Register에 접근하게 된다.
- Pipelined 경우, Read 연산은 1ns만큼 Stall된 이후에 수행된다 가정한다.
- 1ns가 소요된다 가정한다.
Stage 3 : ALU Operation
- ALU를 이용하여 필요한 연산을 수행한다.
- 기본적인 사칙연산, lw 명령어의 경우, 메모리 주소 계산 연산, Branch 명령어의 경우, 피연산자를 비교하는 뺄셈 연산 등
- 2ns가 소요된다 가정한다.
Stage 4 : Data Access
- lw, sw명령어의 경우, Data Memory에 읽기/쓰기 연산을 수행하기 위해 접근한다.
- 2ns가 소요된다 가정한다.
Stage 5 : Register Access (Write Back)
- 연산 결과를 Register에 저장하는 과정이다.
- Pipelined 경우, Write Back 연산은 먼저 수행된 이후에 1ns만큼 Stall된다 가정한다.
- 1ns가 소요된다 가정한다.
Sequential Execution
Response Time : 8ns
Throughput : 0.125 Tasks/ns
Pipelined Execution
Response Time : 9ns
Throughput : 0.231 Tasks/ns

- 다수의 명령어로 구성된 프로그램을 Pipelined 방식으로 수행하는 경우이다.
- 5개의 Pipeline Stage로 구성된 마이크로 프로세서의 경우 최대 5개의 Stage를 수행할 수 있다.
- Pipelined 방식을 통해 얻을 수 있는 Speedup은 Stage의 개수에 반비례한다고 볼 수 있다. (꼭 그렇다 할 수는 없다.)
- Stage간 수행 시간이 균형을 이루는 것이 가장 이상적이다.
- 균형이 맞지 않아, Critical Path가 유달리 길게 책정될 경우, 그 시간만큼 Stall되어야 하기 때문이다.
- Pipelined 방식은 Throughput을 개선하는 방식이며, Latency는 개선되지 않고 오히려 증가할 수도 있다.
※ 여기서, Time to execute an Instruction은 Latency를 의미하는 개념이 아니다. 단순히, 명령어를 처리하는 속도를 의미한다.

- MIPS의 ISA 구조는 Pipeline을 적용하기에 유리한 구조이다.
1. 모든 명령어가 4byte로 구성된다. (CISC 구조는 그렇지 않다.)
- 모든 Instruction Fetch 과정에서 간단하게 항상 4byte만큼을 읽어오면 된다.
2. 모든 명령어가 규칙적인 형태이다.
- 명령어의 종류가 달라도 최대한 비슷한 형태를 유지하려 노력한다.
- I-type, R-type, J-type 간에도 공통점이 많다. (OP-Code가 MSB부터 6bit인 점)
- 공통점이 많아, 명령어 해석의 경우의 수가 적어 Decoding에 유리하다. (MUX를 통해 쉽게 구현할 수 있다.)
3. 유일한 Load/Store Addressing 구조를 갖는다.
- 메모리 값을 Operand로 하는 명령어는 lw, sw명령어 밖에 없는 구조를 갖는것을 의미한다.
- 어떤 연산에 대한 Operand는 Register 혹은 Immediate Field 둘 중 하나에 저장되어 있으며, 메모리에 있는 값을 직접적으로 Operand로 사용할 수 없는 구조이다.
- Memory의 값을 Operand로 사용하는 경우, Address 값을 계산하는 과정은 ALU Stage를 이용하고, 메모리에 접근하는 과정은 Data Access Stage를 이용하는 방식으로 기존의 Stage를 재활용하는 방식으로 처리할 수 있다.
- 이로 인해 Pipeline Stage가 단순한 형태를 띌 수 있다. (메모리 접근을 위한 Stage를 따로 설계할 필요가 없어진다.)
4. 메모리 주솟값은 4byte 단위로 Alignment 되어있다.
- Align되어 있지 않으면, lw 명령의 경우, 2byte 데이터는 이곳에서 읽어오고, 다른 2byte 데이터는 저곳에서 마저 읽어와야하는 번거로움이 발생할 수 있다.
- 즉, Align 되어있는 메모리 구조로 인해 데이터를 한 번의 명령어로 읽어올 수 있다.

- Pipeline은 5개의 Stage로 구성하고자 하며, 각 Stage들은 검은색 실선으로 구분되어 있다.
- 각 Stage들은 왼쪽에서 오른쪽으로 진행된다.
- 검정색 Data Path : 순방향으로 진행되는 Data Path이다. (현재 Stage에서 수행 가능하거나, 바로 다음 Stage에서 처리되는 경우)
- 주황색 Data Path : 역방향으로 진행되는 Data Path이다. (현재 명령어를 위한 값이 아닌, 다음 명령어를 위해 이용되는 값이다. 즉, 몇 Stage 이후에 반영되는 값들이다. 이전 Stage에 반영되는 것이 아니다.)
1. IF Stage
- Instruction Memory로부터 32bit 명령어를 읽어온다.
- PC값을 4만큼 증가하거나, MUX를 통해 PC값을 다른 값으로 변경하는 과정(Branch 명령의 결과)이 수행된다.
2. ID Stage
- 명령어를 해석하고, 동시에 특정 Bit Field를 활용하여 레지스터에 읽기 연산을 수행한다.
- Immediate Field를 32bit만큼 Extension하는 연산도 이 단계에 포함된다.
3. EX Stage
- ALU를 활용하는 단계이다.
- 단순 사칙연산 명령, 주소 계산, 분기를 위한 오프셋 계산등의 연산을 수행한다.
4. MEM Stage
- lw, sw 명령을 수행하기 위해 Data Memory에 접근하는 단계이다.
5. WB Stage
- 계산 결과를 다시 레지스터에 저장하는 단계이다.
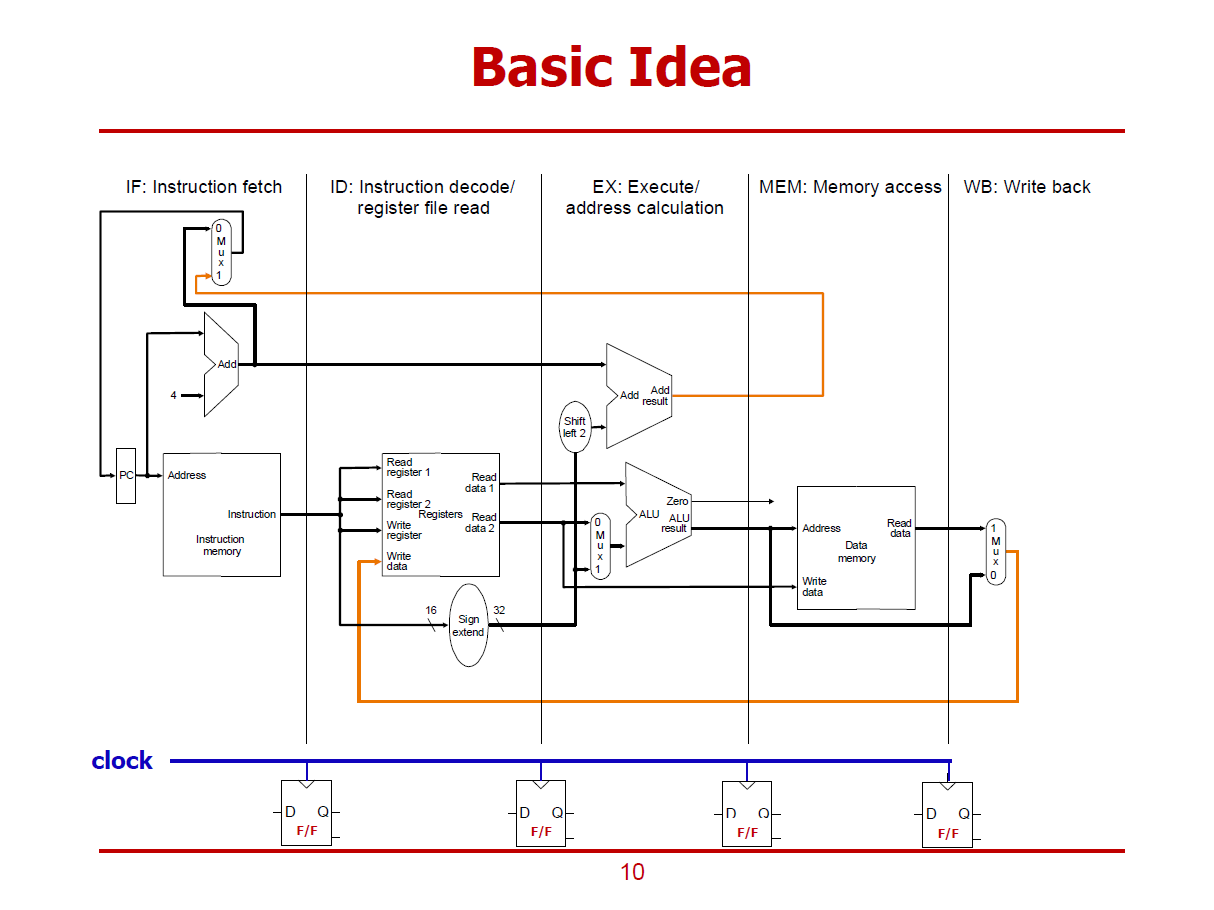
- 각 Stage 사이에 Clock으로 동기화 된 Flip-Flops들을 배치하여 각 단계에서의 출력값들이 Flip-Flops들에 머물게 된다.
- Flip-Flops에 보관된 값들은 Clock이 Rising-Edge가 될 때, 다음 Stage로 출력된다.
- 각 Stage 사이에 Flip-Flops들이 위치함으로써 하나의 Stage가 한 Cycle에 맞춰서 구현된다.

- 데이터 읽기 연산을 수행하는 Stage는 오른쪽 Half에 Shading을 한다.
ex) add 명령의 경우, MEM Stage에서 메모리 읽기 연산을 수행하지 않는다.
- 데이터 쓰기 연산을 수행하는 Stage는 왼쪽 Half에 Shading을 한다.
- H/W 자원을 공유하는 Stage들의 경우, 모듈 외곽을 파선으로 구성한다. (ID와 WB는 하나의 레지스터 파일을 공유한다.)

- 해저드는 Pipeline 방식의 마이크로 아키텍처에서, 현재 명령어를 처리하면서 다음 명령어에 대한 처리 사이클이 진행되지 못하는 상태를 의미한다.
- 즉, 파이프라이닝이 제대로 진행되지 않는 현상을 해저드라고 한다.
1. Structure Hazard
- 내가 사용해야 하는 H/W 자원끼리의 충돌이 발생한 경우이다.
- 동시에 처리되는 명령어들에서 같은 H/W 자원을 동시에 요구하면 구조 해저드가 발생하게 된다.
2. Data Hazard
- 순차적으로 수행되는 명령어들 간에, 전후 명령어끼리 의존관계에 있는 경우이다.
- 파이프라인 기법은 앞선 명령어가 완전히 수행되기 이전에 다음 명령어가 실행되는 것이기 때문에, 전후 명령어가 의존 관계에 있으면 파이프라이닝이 정상적으로 진행되기 어려워진다.
3. Control Hazard
- Branch 명령어와 관련된 해저드이다.
- Branch Outcome을 바로 알 수 없어서 다음 명령어를 Fetch할 수 없는 경우이다.
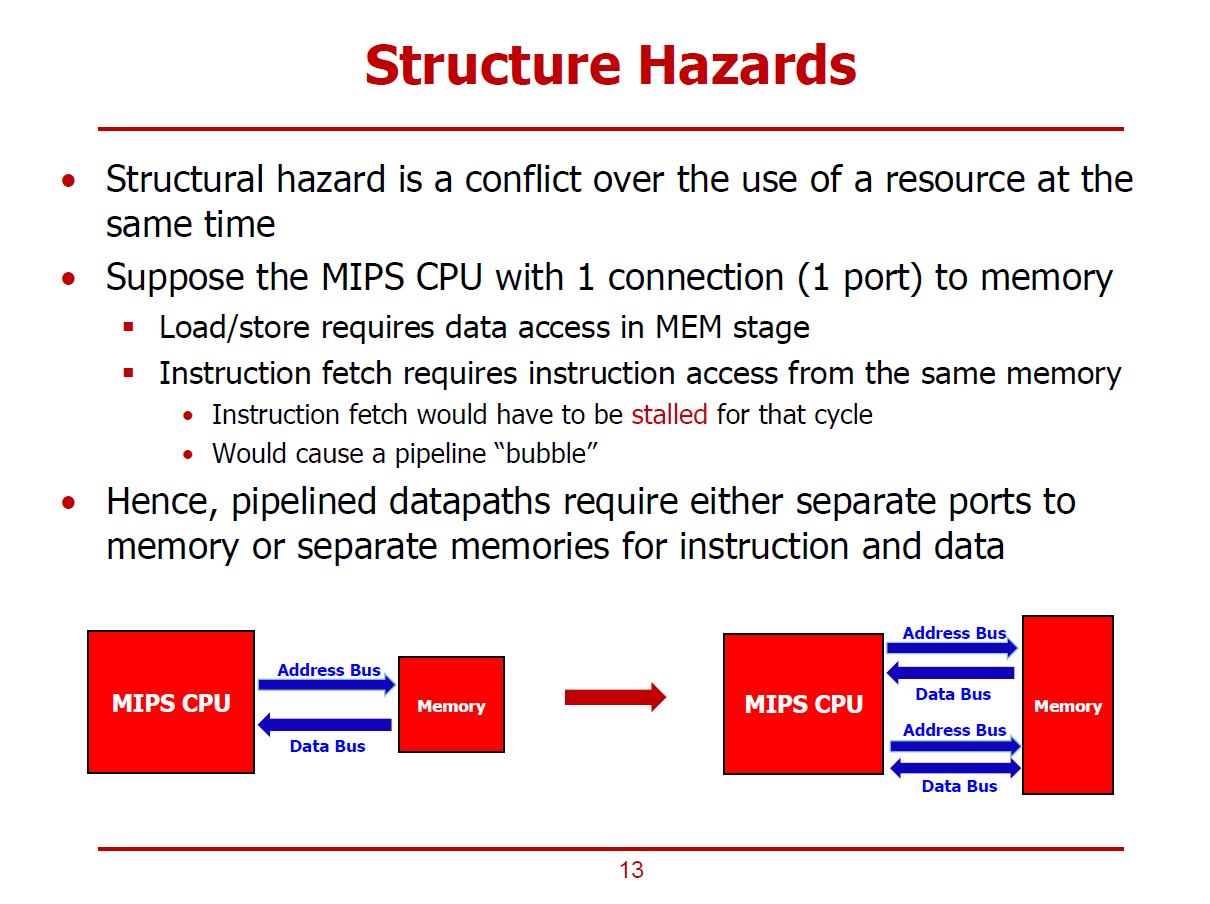
- 의미가 가장 명확한 형태의 해저드이다.
- H/W 자원을 여러 명령어에서 동시에 요구할 때 발생하는 Conflict(=Hazard)이다.
- CPU와 Memory간에는 Instruction Fetch를 위한 포트, Data Access Memory를 위한 포트, 두 가지 포트가 존재한다.
- 구조 해저드를 어느정도 완화하기 위해 CPU와 Memory 사이에 복수의 Connection을 설계한 것이라 볼 수 있다.

- CPU와 Memory 사이에 하나의 Port가 존재한다고 가정했을 때 발생할 수 있는 해저드 형태이다.
- 위와 같은 가정하에서, 6ns - 8ns 구간에서 lw명령어의 MEM Stage에서도 메모리를 사용해야 하고, add명령어의 IF Stage에서도 메모리를 사용해야 한다.

- 데이터 해저드는 순차적으로 실행되는 명령어들 간에 Dependency(의존 관계)가 있는 경우를 의미한다.
- $s0는 \(\texttt{add}\) 명령에서 WB Stage가 완료된 이후에 Update되는데, \(\texttt{sub}\)명령어의 ID Stage에서 $s0의 데이터를 요구하는 상황이다.
- H/W에서는 이러한 상황의 발생 가능성을 Detection할 수 있어야 한다.
- \(\texttt{add}\)명령어 처리 과정에서 WB Stage가 완료될 때 까지 \(\texttt{sub}\) 명령어를 2 Cycle만큼 Stall(Bubble)해야 한다.
- Stalling은 기능적으로 문제가 없으나 성능이 저하된다는 단점이 있다.
- Stalling(Bubbling)보다 나은 해결책으로 Forwarding(Bypassing)이 있다.

- Stall(Bubble)의 단점을 보완한 해결책으로 Forwarding(Bypass)가 있다.
- 포워딩은 이전 명령어로부터 내부 정보를 미리 전달받는 방법이다.
- add 명령어의 $s0의 데이터는 사실 WB Stage 이전에 EX Stage가 수행되면 도출되는 값이기 때문에, EX Stage가 수행되고 난 후에 데이터를 전달받는다.
- 포워딩은 더 많은 H/W 자원을 요구한다는 단점이 있다.
ex) EX Stage에서 다음 명령어에 데이터를 전달하기 위한 H/W 구조를 필요로 한다.

- 포워딩으로 Stall을 피할 수 없는 경우를 Load-Use Case라고 한다.
- lw 명령어에서 Load할 값을 사용해야 하는 의존 명령어가 바로 뒤따르는 경우를 의미한다.
- lw 명령어에서 $s0의 데이터는 MEM Stage가 완료된 이후에 확정된다.
- sub 명령어에서는 EX Stage에 $s0의 데이터를 필요로 하기 때문에 lw 명령어의 MEM Stage에서 포워딩을 수행해도 1 Cycle만큼의 Bubble이 불가피하게 사용된다.
- 즉, 포워딩만을 이용한 방법은 Bubble을 줄일 수는 있으나 완전히 제거할 수 있다고 보장할 수 있는 방법은 아님을 알 수 있다.
- 해저드 유무를 판별하고, 해저드를 피하기 위해 Bubble을 배치하는 기법을 H/W Interlock이라고 한다.
- 기능을 해치지 않는 선의 Instruction Re-Scheduling(명령어 재배치) 방법으로도 Bubble의 수를 줄일 수 있다. (이 방법 또한 만능은 아니다.)
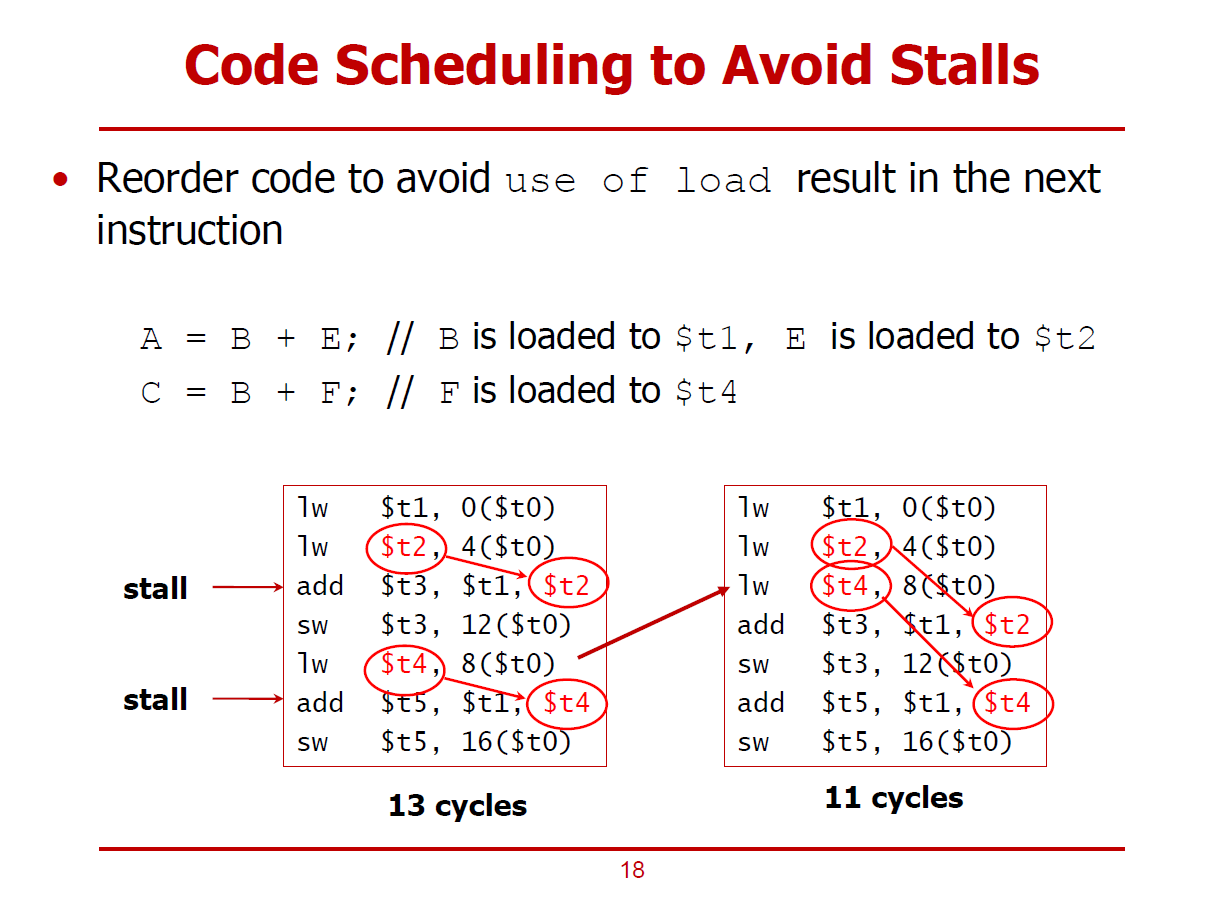
- Instruction을 재배치하는 방법으로 2 Cycle을 절감하는 예시이다.
- 왼편 코드의 빨간색 동그라미에 해당되는 명령어들이 의존 관계에 있는 Load-Use Case에 해당된다.
- 최적의 Cycle수는 11Cycle이나 Bubble로 인해 포워딩을 수행해도 두 사이클 증가한 13Cycle로 늘어난 형태이다.

- 컨트롤 해저드는 Branch 명령어에서 분기 조건이 계산되기 전까지는, 다음 명령어의 Next Fetch를 수행할 수 없게 되는 상황을 의미하는 해저드이다. (즉, 분기 명령어의 ID Stage를 진행할 때, 다음 명령어의 IF Stage가 진행되어야 하는데, 분기 명령어의 EX Stage 이후에 다음 명령어의 IF Stage를 진행할 수 밖에 없는 상황이다.)
- 그림과 같이, Update된 PC값("Taken target address is known here")과 분기 명령어의 분기 조건("Branch is resolved here")은 EX Stage가 수행되고 나서야 결정된다.
- 위 그림에서 beq 명령어는 분기 조건과 분기 주소가 결정되는 EX Stage가 수행되기 전까지는 다음 명령어가 진행될 수 없기 때문에 필연적으로 두 개의 Bubble을 초래하게 된다.

- 컨트롤 해저드에서 두 개의 버블을 하나로 줄이는 방법이다.
- ID Stage에서 두 개의 레지스터 값을 비교하여 분기 여부와 분기 주소까지 계산하는 H/W를 추가하는 방법이다.
- 다음 명령어에 정보를 전달하는 방식이므로 Forwarding Logic을 필요로하게 된다.
- 분기 여부와 분기 주솟값을 EX Stage가 아닌, ID Stage가 수행된 이후에 알아내기 위한 추가적인 H/W Logic을 필요로 하게 된다.
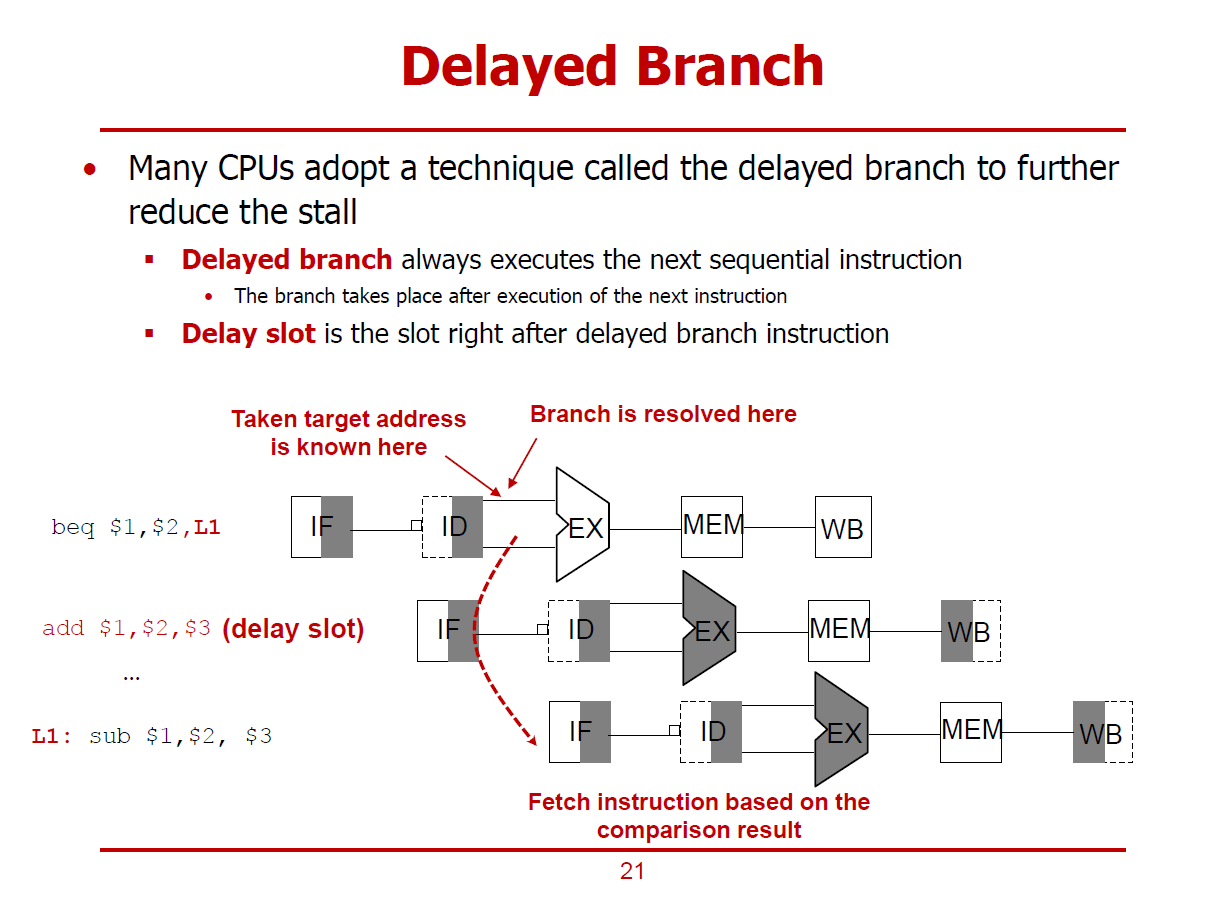
- 분기 명령어 바로 다음에 분기 명령어와 독립적인(관계 없는) 명령어를 배치하여 파이프라이닝을 그대로 진행하는 방법이다.
- 분기 명령어 바로 다음 명령어가 위치하는 부분을 Delay Slot이라고 한다.
- Compiler나 Assembler가 Independent 명령어를 Code-Rescheduling을 통해 Delay Slot에 배치하거나, Independent 명령어를 발견하지 못하면 Nop 명령어를 Delay Slot에 배치하게 된다.
(단, MIPS ISA에서 nop 명령어는 컴파일러나 어셈블러에 의해 아무런 의미가 없는 명령어로 치환된다.)
- 버블이 없어지므로, Throughput을 개선할 수 있다.

- bne 명령어 다음의 Delay Slot에 nop 명령어를 배치하는 식으로 Bubble의 개수를 줄일 수 있다.
- nop 명령어 대신 Independent Insturction인 add $s1, $s2, $s3를 배치하여 보다 나은 성능 개선을 이끌어 낼 수도 있다.

- jal 명령어는 다시 되돌아 올 주소(PC+4)를 ra 레지스터에 저장하는 명령어이다.
- 단, Delayed Branch 기법을 사용하는 MIPS R4000 SPEC의 프로세서는 ra 레지스터에 PC+4 대신, PC+8을 저장한다.
- PC+4 위치의 Delay Slot은 분기 명령어가 처리되는 도중에 같이 처리될 것이기 때문에 PC+8 위치의 명령어 주솟값을 저장하는 것이다.

- 통계 및 분석을 통해 분기 여부를 미리 예측하는 방법이다.
ex) 1,000번 iteration하는 Loop의 경우, 분기할 가능성이 높다고 판별하는 식의 예측
- 특히, 많은 Stage로 구성된 CISC 기반 프로세서에서는 Forwarding이나 Re-Scheduling을 동원해도 많은 Stall penalty가 초래될 수 있어 분기를 예측하는 방식은 RISC 기반 프로세서보다 효과적으로 작용한다.
- Prediction에 실패할 경우, Flush(처리중인 명령어의 수행 결과를 취소함)를 수행하게 된다.

- beq명령어의 ID Stage가 완료된 후에 Prediction correct/incorrect 여부를 파악할 수 있다.
- 예측에 실패했을 경우, beq 명령어 다음에 실행되던 명령어가 Flush된다.

- Pipeline 방식은 프로세서의 Throughput을 개선할 수 있는 방법이다.
- Pipeline 방식은 Structurem Data, Control 해저드가 존재한다.
- ISA 구조는 Pipeline 구현의 복잡도에 많은 영향을 끼치는 요소이다.
- RISC구조의 MIPS는 Pipeline을 구현하기에 알맞는 ISA이다.