
Scheduling
스케줄링
- Ready State에 있는 프로세스들 중 어떤 프로세스에 CPU를 할당할지에 대한 방법론이다.
- Batch 환경이냐, Timesharing 환경이냐에 따라 스케줄링의 목적이 서로 다르다.
- 프로세스에 CPU를 할당하는 OS의 일부분을 Scheduler라 하고,
스케줄러의 프로세스 선택 알고리즘을 Scheduling Algorithm이라 한다.
- 스케줄러는 OS에 따라 Module로 구현되기도 하고, Function의 형태로 구현되기도 한다.
- 스케줄링이 필요한 시점은 아래와 같다:
- 새 Process가 생성된 경우
- Running 중이던 Process가 Exit한 경우
- Process가 Block된 경우
- I/O Interrupt가 발생된 경우
- Clock Interrupt를 통해 한 프로세스가 CPU Quantum을 초과했음이 감지된 경우
* Clock Interrupt
- 주기적으로 Interrupt를 발생시켜, H/W 자원을 관리하는 Routine을 수행시킨다.
- 현재 처리되고 있는 Process가 CPU 할당에 대한 Quantum(지정된 시간)을 넘기지 않았는지 체크한다.
(즉, 너무 오랫동안 CPU를 점유하고 있지 않았는지 검사한다.)
- 해당 프로세스가 Quantum을 초과했으면, 그 프로세스를 Unschedule한다.
- 스케줄링은 Context Switching 으로 인해 발생되는 Cost를 절감하는 것을 궁극적인 목표로 한다.
- 여기서, Scheduling은 Policy이며, Context Switching은 Mechanism 이다.
- Context Switching 에서 발생되는 Task 들은 아래와 같다:
- User Mode에서 Kernel Mode로의 Mode Switching
- 현재 State 정보 저장
- Address Space(Memory Map) 정보 저장
- Scheduling (다음 실행할 프로세스를 선정)
- PCB로부터의 MMU(Memory Management Unit) Reloading (PCB 데이터 리로딩)
- TLB와 같은 Cache에 대한 Flushing
Process Behavior (프로세스 패턴)
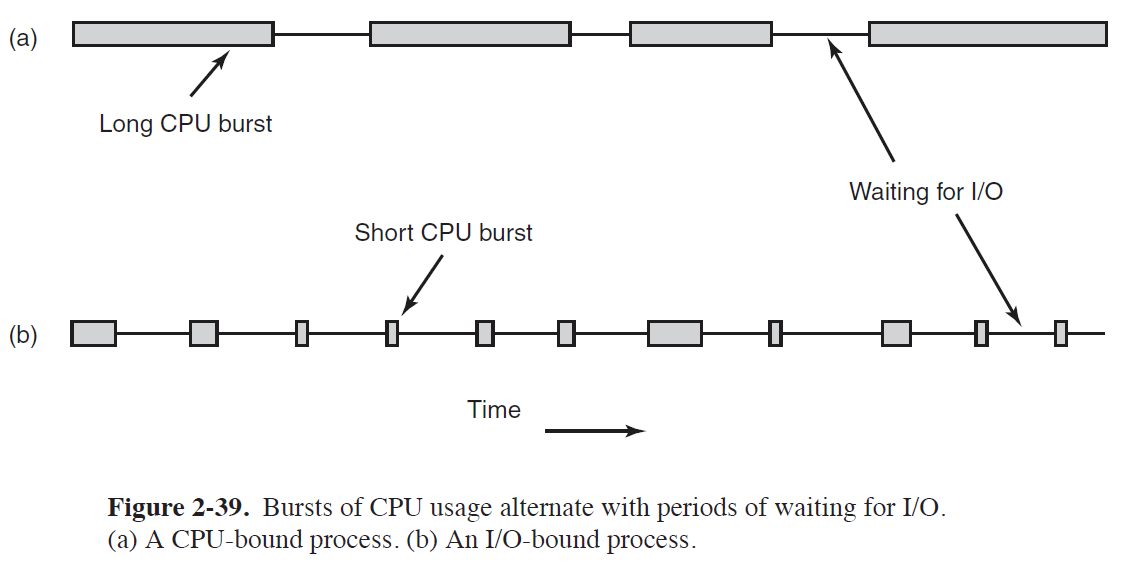
- CPU를 사용하는 패턴에 관한 이야기이다.
- CPU Bound Process: CPU 연산의 비중이 높은 Process이다. (그림의 (a)에 해당)
- I/O Bound Process: I/O 연산의 비중이 높은 Process이다. (그림의 (b)에 해당)
- 한 프로세스가 CPU Bound인지, I/O Bound인지는 CPU 성능에 따라 상대적으로 결정된다.
- Scheduling은 Time Scale의 크기에 따라, 아래와 같이 두 가지로 구분할 수 있다:
- Long Term
- 전체 시스템에서 동시에 구동할 수 있는 최대 프로세스의 수를 정한다.
- Short Term (= CPU Scheduling)
- Ready 상태에 있는 프로세스 중 CPU를 할당할 프로세스를 선정한다.
Scheduling Environment (스케줄링 환경)
| Batch Environment | - 단위 시간 당 처리되는 Job의 수를 중요시한다. - 보통, Non-Preemptive Algorithm을 사용하여, Context Switch로 인한 Overhead의 최소화를 지향한다. - 드물게, Batch 환경에서 사용하는 Preemptvie Algorithm의 경우, CPU Quantum의 크기가 굉장히 크다. |
| Interactive Environment | - 반드시, Preemptive Algorithm을 사용하여 Time Sharing이 구현되어야 하는 환경이다. - 한 프로세스가 CPU Quantum을 초과하면, Unschedule된다. |
| Real-Time Environment | - 프로세스가 처리되어야 하는 Deadline(제한시간)을 지키는 것을 중요시하는, Deterministic한 환경이다. - Preemptive 스케쥴링이 사용될 수도 있고, Non-Preemptive 스케쥴링이 사용될 수도 있다. |
Preemptive Scheduling - Non-Preemptive Scheduling (선점형 스케줄링 - 비선점형 스케줄링)
Preemptive Scheduling (선점형 스케줄링)
- 프로세스마다 CPU를 점유하는 시간(=CPU Quantum)에 제한을 둔 형태의 스케줄링 기법이다.
- 해당 프로세스의 CPU Quantum의 초과 여부는 Clock Interrupt를 이용하여 확인한다.
- 주로 Timesharing System에서 선택하는 방법이다.
Non-Preemptive Scheduling (비선점형 스케줄링)
- 한 프로세스가 CPU를 점유한 이후로 특별한 Event가 발생하지 않는 한,
계속해서 CPU를 점유하게 하는 스케줄링 기법이다.
- Context Switching이 Preemptive 스케쥴링 방식보다는 적게 발생하기 때문에 그에 대한 Cost가 비교적 적은 편이다.
- 주로 Batch System에서 선택하는 방법이다.
Scheduling Algorithms (스케줄링 알고리즘)
- 본 포스트에서 소개하는 스케줄링 알고리즘은 아래와 같다:
- FCFS (First-Come First-Served)
- SJF (Shortest Job First)
- SRTN (Shortest Remaining Time Next)
- Round Robin
- Priority Scheduling
- Multiple Queues
- Guaranteed Scheduling
- Lottery Scheduling
- Fair-Share Scheduling
* Scheduling Algorithm Goals
| All Systems | Fairness (공정성) |
- 모든 프로세스는 공평하게 CPU를 할당받아야 한다. |
| Policy Enforcement (정책의 시행) |
- 시스템을 이용하는 곳의 정책에 부합해야 한다. | |
| Balance (밸런스) |
- CPU를 포함한 모든 H/W 자원들이 원활히 사용되어야 한다. (최대한 바쁘게) | |
| Batch Systems | Throughput (처리율) |
- 단위시간 당 처리할 수 있는 Job의 개수가 많아야 한다. |
| Turnaround Time (소요 시간) |
- Operator에게 Job의 처리를 요청하고, 결과를 받아보기까지 소요되는 시간이 짧아야 한다. | |
| CPU Utilization (CPU 효율) |
- CPU가 바쁘게 움직여야 한다. | |
| Interactive Systems | Response Time (반응 시간) |
- 요청에 대한 처리가 즉각적으로 이루어져야 한다. |
| Proportionality (비례성) |
- 사용자가 기대하는 처리시간을 만족해야 한다. (10개를 처리하는데 10초가 걸린다면, 100개는 100초내에 처리해야 한다.) |
|
| Real-Time Systems | Meeting Deadlines (기한 만족시키기) |
- Job이 제한시간 내에 처리되어야 한다. (특히, Hard Real-Time 환경에서) |
| Predictability (예측) |
- 일정수준 이상의 서비스 품질이 유지되어야 한다. (특히, Streaming 서비스와 같은 Soft Real-Time 환경에서) |
* Starvation Issue
- Ready Queue에 들어온 프로세스가 Scheduling Algorithm에 의해 CPU를 계속해서 할당받지 못하는 상황을 의미한다.
- "CPU를 굶는다."라는 의미에서, Starvation이라 표현한다.
- Scheduler는 Starvation의 최소화를 지향해야 한다.
* Starvation의 해결방법 (= aging)
- Ready Queue에서 오래 대기한 Job들의 우선순위를 높게하고,
CPU를 사용한 시간이 높은 Job들의 우선순위를 낮게한다.
- Starvation Issue가 있는 SJF, SRTN, Priority Scheduling에 적용할 수 있다.
Scheduling Algorith : FCFS (First-Come First-Served)
- 일반적으로, Batch System에서 사용하는 알고리즘이다.
- 대체로, Non-Preemptive Scheduling 방식으로 구현된다.
- Create된 순서대로 프로세스를 처리하는 방식이다.
- 모든 Job이 동등하게 처리된다. (즉, Create된 순서만을 고려하여 우선순위를 설정한다.)
- Starvation이 없다. 언젠가는 처리될 것이기 때문이다.
* FCFS 구조는 평균 Response Time과 Turnaround Time이 커질 가능성이 있다.
\(\mathrm{Response \; Time} \; = \; \mathrm{Waiting \; Time \; + \; CPU \; Burst \; Time}\)
※ 이번 학기에서는 Response Time과 Waiting Time을 같은 개념으로 간주한다.
(이번 학기에만 한정된 개념, 원래는 Response Time안에 Waiting Time이 포함되어 있는 구조이다.)
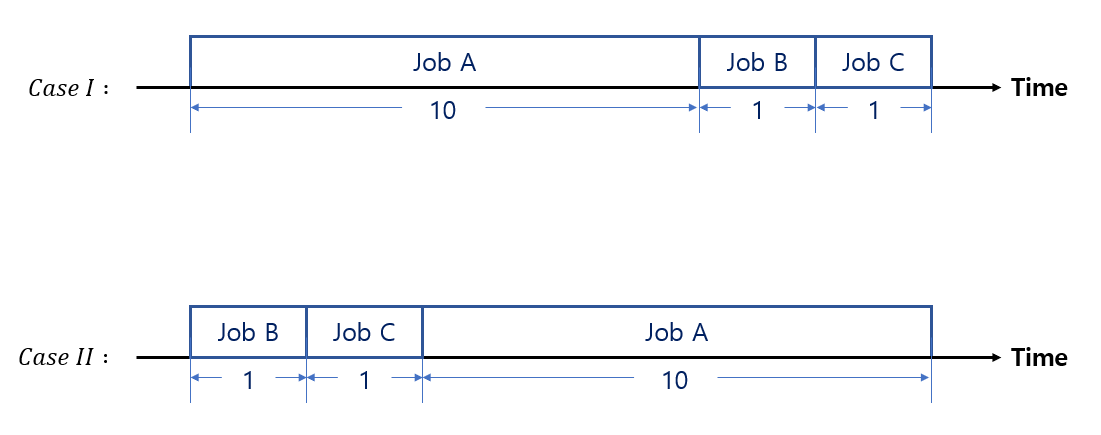
\(Case \; I\)
\(: \; \mathrm{Throughput} \; = {12 \over 3} \; = \; 4\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; A \; = 10\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; B \; = 10 + 1 = 11\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; C \; = 10 + 1 + 1 = 12\)
\(Case \; II\)
\(: \; \mathrm{Throughput} \; = {12 \over 3} \; = \; 4\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; A \; = 1 + 1 + 10 = 12\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; B \; = 1\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; C \; = 1 + 1 = 2\)
※ 위 그림에서 Process Switching으로 인해 발생하는 Overhead는 생략되어 있다.
* FCFS의 문제점
- Average Turnaround Time이 커질 가능성이 있다.
\(\mathrm{Avg \; Turnaround \; Time} \; = \; \sum\limits_{i} (\mathrm{Response \; Time \; for \; Job \;} i) \; / \; \mathrm{The \; Number \; of \; Jobs}\)
\(Case \; I\) (=FCFS)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (10 + 11 + 12) \; / \; 3 = 11\)
\(Case \; II\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (1 + 2 + 12) \; / \; 3 = 5\)
※ 위 그림에서 Process Switching으로 인해 발생하는 Overhead는 생략되어 있다.
Scheduling Algorithm : SJF (Shortest Job First)
- 처리시간이 가장 작은 Job을 먼저 처리하는 방식이다.
- 모든 Job들이 동시에 요청된 경우에 SJF가 최적의 성능을 발휘한다.
- 대체로, Non-Preemptive Scheduling 방식으로 구현된다.
- Job A가 처리되던 도중, Ready Queue에 있는 모든 Job들 중 가장 짧은 시간을 요구하는 Job Z가 새로 삽입되었을 경우,
Job A는 마저 처리하고, 그 이후에 Job Z를 처리한다.
- FCFS와 달리, SJF에서는 새로운 Job이 삽입될 때 마다 처리할 순서를 다시 계산하는 Scheduling Overhead가 존재한다.
- 모든 Job이 동시에 요청된 경우, SJF를 이용한 방법은 최적의 Average Turnaround Time을 도출한다.
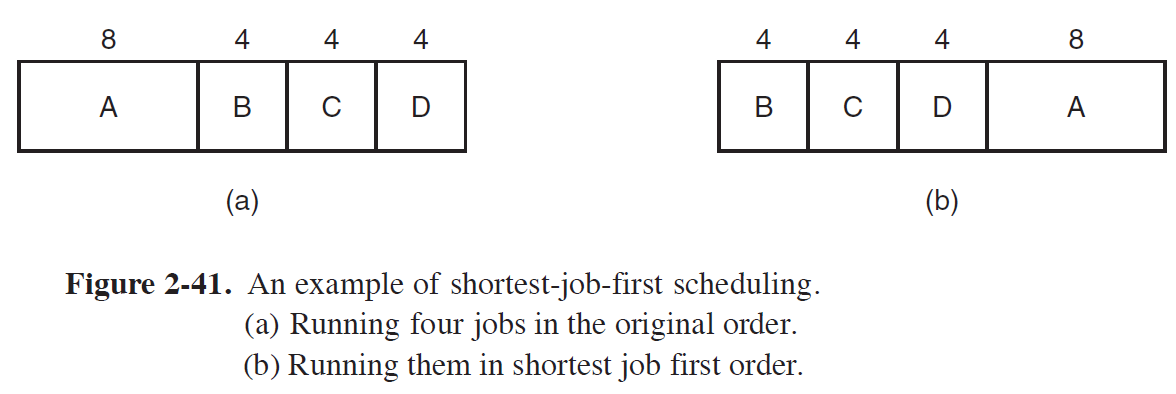
\((a)\) Method
\(: \; \mathrm{Throughput} \; = {20 \over 4} \; = \; 5\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (8 + 12 + 16 + 20) \; / \; 4 = 14\)
\((b)\) Method (=SJF)
\(: \; \mathrm{Throughput} \; = {20 \over 4} \; = \; 5\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (4 + 8 + 12 + 20) \; / \; 4 = 11\)
* SJF의 문제점
1) 현실 상황에서는 CPU Burst Time을 예측하기가 힘들기 때문에 SJF를 적용하기가 쉽지 않다.
2) 특정한 상황에서는, SJF가 최적이 아닌 경우가 발생한다.
- SJF가 최적의 성능을 보이기 위해선, 모든 Job이 동시에 요청되어야 한다.
- 모든 Job들이 Ready Queue에 준비되어 있어서, 한꺼번에 Scheduling이 가능한 환경이어야 한다.
3) CPU Burst가 큰 Job에 대한 Starvation이 발생할 가능성이 있다.
Example. (SJF가 최적이 아닌 경우 예시)
Job A, B는 0초에 동시에 요청되었고, Job C, D, E는 3초에 동시에 요청되었다.
Job A, B, C, D, E의 CPU Burst Time은 각각 2, 4, 1, 1, 1일 때, SJF의 수행결과는 아래 그림과 같다.
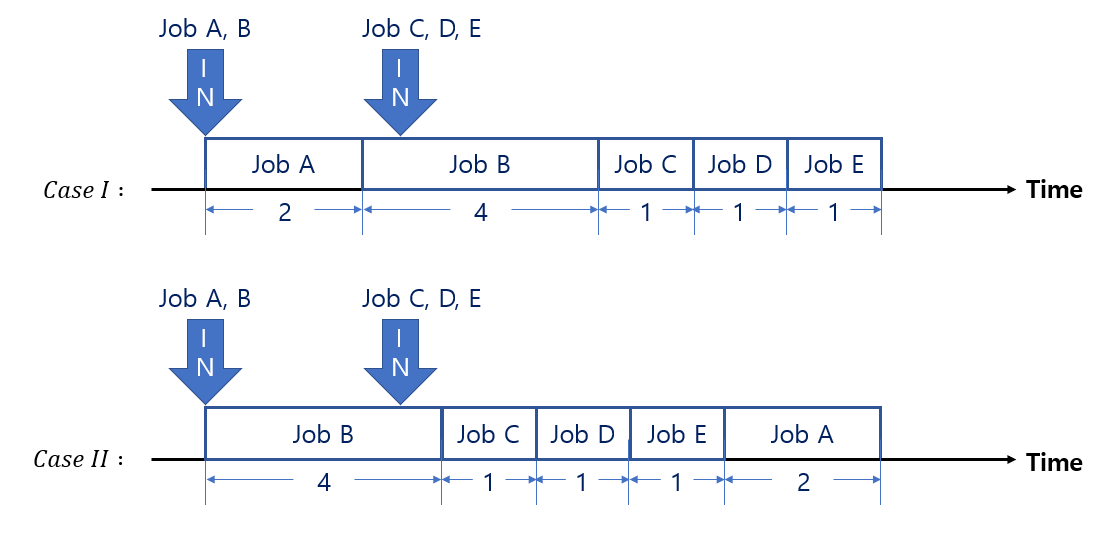
\(Case \; I\) (=SJF)
Turnaround Time
Job A = 2
Job B = 6
Job C = 4 (3초에 요청되었음에 유의!)
Job D = 5 (3초에 요청되었음에 유의!)
Job E = 6 (3초에 요청되었음에 유의!)
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (2 + 6 + 4 + 5 + 6) \; / \; 5 = 4.6\)
\(Case \; II\) (=Not SJF)
Turnaround Time
Job B = 4
Job C = 2
Job D = 3
Job E = 4
Job A = 9
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (9 + 4 + 2 + 3 + 4) \; / \; 5 = 4.4\)
Scheduling Algorithm : SRTN (Shortest Remaining Time Next)
- Preemptive Scheduling 버전의 SJF이다.
- 매 Scheduling마다, 현재 필요한 CPU Burst중 가장 최솟값을 찾아서, 해당 Job을 먼저 처리한다.
(Preemptive 방식이기 때문에, 주기적으로 Scheduling이 일어난다.)
- SRTN에서는 각 Job들의 CPU Burst를 알고 있다 가정한다.
Example.
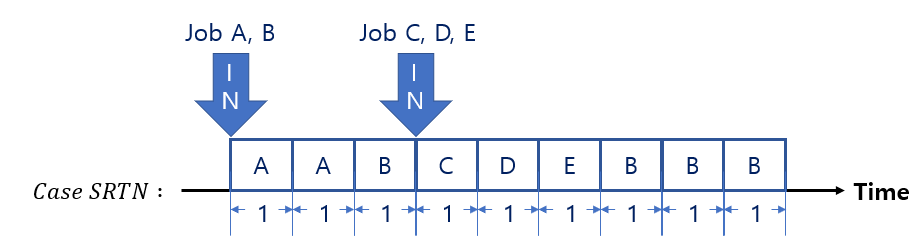
\(Case \; \mathrm{SRTN}\) (= Preemptive SJF)
Turnaround Time
Job A = 2
Job B = 9
Job C = 1
Job D = 2
Job E = 3
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (2 + 9 + 1 + 2 + 3) \; / \; 5 = 3.4\)
* SRTN의 문제점
- Non-Preemptive 방식보다, 잦은 Scheduling으로 인해 발생하는 Overhead의 크기가 더 크다.
(Preemptive 방식의 고질적 문제점이다.)
- SRTN 또한, SJF와 같이 Starvation이 발생할 가능성이 있다.
Scheduling Algorithm : Round Robin (RR)
- Preemptive Scheduling 방식이다.
- Ready Queue의 맨 앞에 있던 Job이 CPU를 Quantum만큼만 사용하고, 다시 Ready Queue의 맨 뒤에 삽입된다.
(Quantum이 존재한다 -> Preemptive Scheduling)
- RR에는 Starvation이 발생할 가능성이 없다.
* Round Robin의 문제점
- Quantum의 값이 작으면, 잦은 Context Switch로 인해 Overhead가 커진다.
- Quantum의 값이 크면, Non-Preemptive Scheduling처럼 Response Time이 커진다.
(즉, Quantum의 값을 정하기가 어렵다.)
Scheduling Algorithm : Priority Scheduling
- Job들에 우선순위를 부여하고, Ready Queue에 있는 Job들 중 우선순위가 가장 높은 Job부터 CPU를 할당한다.
- 우선순위가 같은 Job들 끼리는 FCFS로 진행한다.
* Priority Assignment (우선순위 부여)
1) Static Assignment
- User, Price, 기타 등등에 의해 정적으로 우선순위를 부여한다.
2) Dynamic Assignment
- I/O Bound Process에게 더 높은 우선순위를 부여한다.
(I/O Bound Job은 Quantum을 다 못쓴 채, I/O 연산을 수행할 확률이 높기 때문에, 높은 우선순위를 갖게 하는 것이다.)
- 우선순위 = 1 / \(f\) (\(f\): Quantum중 해당 프로세스가 실질적으로 CPU를 사용한 시간의 비율)
ex) Quantum이 10이고, A 프로세스가 2만큼 CPU를 사용하고 I/O 요청으로 인해 Block되었다면,
이 프로세스의 우선순위는 \(1 / {2 \over 10} = 5\)이다.
Example.
- 각 Job들에 우선순위를 부여한다.
- 같은 우선순위를 가진 Job들끼리는 Round Robin 방식으로 CPU를 할당한다.
- aging 방법 등을 사용하여 Starvation이 발생할 여지를 제거해야 한다.
* Priority Scheduling의 문제점
- Starvation이 발생할 수 있다.
Scheduling Algorithm : Multiple Queues
- 다수의 Queue가 존재하여 Job들이 삽입되고, 각각의 Queue 마다 저마다의 Scheduling 알고리즘을 적용한다.
- 각 Job들은 Queue 사이를 옮겨다닐 수 있다.
* Multi-Level Feedback Queues (MLFQ)
- 각각의 Queue들은 저마다의 Job Type을 갖고, 해당되는 Job들이 삽입된다.
(Job Type: Batch, Interactive, System, CPU-Bound, etc)
- 하나의 Queue 내에서 스케줄링은 Round Robin 방식으로 진행된다.
- 우선순위가 낮은 Queue에는 Quantum을 크게 할당하여 Context Switch로 인한 오버헤드를 줄인다.
- Feedback : 어떤 Job이 처리되기에 알맞는 Queue에 배치되도록 하는 것이다.
ex) 만약, CPU-Bound Job이 높은 우선순위의 Queue에 배치되어 Quantum을 모두 소진하면,
우선순위를 낮추어서 Quantum을 길게 가져갈 수 있게 "Feedback"받는다.
ex) 만약, I/O-Bound Job이 낮은 우선순위의 Queue에 배치되어 Quantum을 모두 소진하지 못한 채 I/O 연산을 수행하게 되면,
우선순위를 높여서 Response Time을 제고할 수 있도록 "Feedback"받는다.
SchedulingAlgorithm : Guaranteed Scheduling
- 할당된 CPU 시간 중, 실질적으로 소진한 CPU 시간이 적은 Job에게 높은 우선순위를 부여한다.
(Ratio가 가장 낮은 Job에 높은 우선순위를 부여한다.)
* Ratio = 실질적인 CPU 소비시간 / CPU 할당 시간
- 어떤 Job에 CPU 할당이 끝나면, 해당 Job의 Ratio를 다시 계산하여 모든 Job들의 우선순위를 갱신한다.
(즉, 모든 Job들의 실질적 CPU 사용 시간을 동일 선상에 위치하게 만든다. = 모든 Job들이 비슷한 Ratio를 가지도록)
SchedulingAlgorithm : Lottery Scheduling
- Job마다 Lottery Ticket을 부여하고, Scheduler는 랜덤하게 Lottery Ticket을 뽑는다.
(이 때, 하나의 Job은 다수의 티켓을 보유할 수 있다.)
- 뽑힌 Lottery Ticket을 보유한 Job에게 CPU를 할당한다.
- 전체 티켓의 총량에서 Job이 티켓을 보유한 만큼, CPU를 할당받을 수 있다는 보장이 있다.
(Priority를 부여하는 방식에서는, 실질적으로 CPU를 할당받는 양을 예측할 수 없다는 점에서 대비적이다.)
- 즉, Lottery Scheduling방식은 Performance Assurance를 제공한다.
* Lottery Scheduling의 특성
1) Highly Responsive
- 새로 Ready Queue에 진입한 Process도 CPU를 바로 할당받을 수 있는 가능성이 있다.
2) Ticket Exchanging
- 동일한 Task를 수행하는 Process끼리는 Lottery Ticket을 주고 받아 협력하며 진행도를 비슷하게 가져갈 수 있다.
3) Propotional Scheduling
- Process들에게 CPU를 특정 비율로 할당해야 하는 경우에 Lottery Scheduling 방식이 적합하다.
ex) Frame Rate이 10, 20, 25인 3개의 Job이 있는 경우, 전체 Ticket 55개를 10개, 20개, 25개로 분배하면 된다.
(다른 Scheduling 방식에서는 비율로써 나누는 것이 쉽지 않다.)
SchedulingAlgorithm : Fair-Share Scheduling
- Process 단위로 CPU를 할당하는 것이 아닌, Process를 구동하는 User들에게 공평하게 CPU를 할당하는 것이다.
ex) 8개의 Process를 구동중인 User A와 2개의 Process를 구동중인 User B는 전체 CPU Time=10을 공평하게 5씩 나누어 갖는다. (Process 단위가 아닌, User 단위로 CPU를 할당한다.)
Scheduling in Real-Time System (실시간 시스템에서의 스케줄링)
- Hard Real-Time 혹은 Soft Real-Time 시스템에서는 Process Behavior가 예측가능한 경우일 확률이 높다.
- Real-Time 시스템에서는 Response Time, Turnaround Time 보다는 Schedulable 여부가 중요하다.
(즉, Dead Line을 충족하도록 Scheduling할 수 있는지가 가장 중요하다.)
* Periodic : Event가 Regular하게 발생되는 경우를 의미한다. (Event란, CPU를 할당하여 처리해야 하는 일을 의미한다.)
* Aperiodic : Event가 불규칙적으로 발생되는 경우를 의미한다. Dead-Line을 충족시키기 어렵다.
* Schedulable 여부 판단식
\(\sum\limits_{i=1}^{m} {C_i \over P_i} \leq 1\)
\(m\) : Periodic하게 발생되는 Event의 개수
\(C_i\) : \(\mathrm{Event_i}\)가 완전히 처리되는데 필요한 CPU Time
\(P_i\) : \(\mathrm{Event_i}\)가 발생되는 주기
ex) \((C_1 = 50ms, P_i = 100ms), (C_2 = 30ms, P_2 = 200ms), (C_3 = 100ms, P_3 = 500ms)\) 인 경우,
\(\sum\limits_{i=1}^{3} {C_i \over P_i} = {50 \over 100} + {30 \over 200} + {100 \over 500} = 0.85 \leq 1\) 이므로,
이 경우는 Dead Line을 충족하도록 Schedulable하다.
만약, 여기서 하나의 Event가 더 추가된다면, 추가되는 Event의 Ratio는 0.15이하여야 할 것이다.
* Static Real-Time Scheduling
- System이 시작되기 전에 Scheduling이 결정되는 것이다.
* Dynamic Real-Time Scheduling
- System이 구동되면서 동적으로 Scheduling이 이루어지는 것이다.
Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)
Scheduling
스케줄링
- Ready State에 있는 프로세스들 중 어떤 프로세스에 CPU를 할당할지에 대한 방법론이다.
- Batch 환경이냐, Timesharing 환경이냐에 따라 스케줄링의 목적이 서로 다르다.
- 프로세스에 CPU를 할당하는 OS의 일부분을 Scheduler라 하고,
스케줄러의 프로세스 선택 알고리즘을 Scheduling Algorithm이라 한다.
- 스케줄러는 OS에 따라 Module로 구현되기도 하고, Function의 형태로 구현되기도 한다.
- 스케줄링이 필요한 시점은 아래와 같다:
- 새 Process가 생성된 경우
- Running 중이던 Process가 Exit한 경우
- Process가 Block된 경우
- I/O Interrupt가 발생된 경우
- Clock Interrupt를 통해 한 프로세스가 CPU Quantum을 초과했음이 감지된 경우
* Clock Interrupt
- 주기적으로 Interrupt를 발생시켜, H/W 자원을 관리하는 Routine을 수행시킨다.
- 현재 처리되고 있는 Process가 CPU 할당에 대한 Quantum(지정된 시간)을 넘기지 않았는지 체크한다.
(즉, 너무 오랫동안 CPU를 점유하고 있지 않았는지 검사한다.)
- 해당 프로세스가 Quantum을 초과했으면, 그 프로세스를 Unschedule한다.
- 스케줄링은 Context Switching 으로 인해 발생되는 Cost를 절감하는 것을 궁극적인 목표로 한다.
- 여기서, Scheduling은 Policy이며, Context Switching은 Mechanism 이다.
- Context Switching 에서 발생되는 Task 들은 아래와 같다:
- User Mode에서 Kernel Mode로의 Mode Switching
- 현재 State 정보 저장
- Address Space(Memory Map) 정보 저장
- Scheduling (다음 실행할 프로세스를 선정)
- PCB로부터의 MMU(Memory Management Unit) Reloading (PCB 데이터 리로딩)
- TLB와 같은 Cache에 대한 Flushing
Process Behavior (프로세스 패턴)
- CPU를 사용하는 패턴에 관한 이야기이다.
- CPU Bound Process: CPU 연산의 비중이 높은 Process이다. (그림의 (a)에 해당)
- I/O Bound Process: I/O 연산의 비중이 높은 Process이다. (그림의 (b)에 해당)
- 한 프로세스가 CPU Bound인지, I/O Bound인지는 CPU 성능에 따라 상대적으로 결정된다.
- Scheduling은 Time Scale의 크기에 따라, 아래와 같이 두 가지로 구분할 수 있다:
- Long Term
- 전체 시스템에서 동시에 구동할 수 있는 최대 프로세스의 수를 정한다.
- Short Term (= CPU Scheduling)
- Ready 상태에 있는 프로세스 중 CPU를 할당할 프로세스를 선정한다.
Scheduling Environment (스케줄링 환경)
| Batch Environment | - 단위 시간 당 처리되는 Job의 수를 중요시한다. - 보통, Non-Preemptive Algorithm을 사용하여, Context Switch로 인한 Overhead의 최소화를 지향한다. - 드물게, Batch 환경에서 사용하는 Preemptvie Algorithm의 경우, CPU Quantum의 크기가 굉장히 크다. |
| Interactive Environment | - 반드시, Preemptive Algorithm을 사용하여 Time Sharing이 구현되어야 하는 환경이다. - 한 프로세스가 CPU Quantum을 초과하면, Unschedule된다. |
| Real-Time Environment | - 프로세스가 처리되어야 하는 Deadline(제한시간)을 지키는 것을 중요시하는, Deterministic한 환경이다. - Preemptive 스케쥴링이 사용될 수도 있고, Non-Preemptive 스케쥴링이 사용될 수도 있다. |
Preemptive Scheduling - Non-Preemptive Scheduling (선점형 스케줄링 - 비선점형 스케줄링)
Preemptive Scheduling (선점형 스케줄링)
- 프로세스마다 CPU를 점유하는 시간(=CPU Quantum)에 제한을 둔 형태의 스케줄링 기법이다.
- 해당 프로세스의 CPU Quantum의 초과 여부는 Clock Interrupt를 이용하여 확인한다.
- 주로 Timesharing System에서 선택하는 방법이다.
Non-Preemptive Scheduling (비선점형 스케줄링)
- 한 프로세스가 CPU를 점유한 이후로 특별한 Event가 발생하지 않는 한,
계속해서 CPU를 점유하게 하는 스케줄링 기법이다.
- Context Switching이 Preemptive 스케쥴링 방식보다는 적게 발생하기 때문에 그에 대한 Cost가 비교적 적은 편이다.
- 주로 Batch System에서 선택하는 방법이다.
Scheduling Algorithms (스케줄링 알고리즘)
- 본 포스트에서 소개하는 스케줄링 알고리즘은 아래와 같다:
- FCFS (First-Come First-Served)
- SJF (Shortest Job First)
- SRTN (Shortest Remaining Time Next)
- Round Robin
- Priority Scheduling
- Multiple Queues
- Guaranteed Scheduling
- Lottery Scheduling
- Fair-Share Scheduling
* Scheduling Algorithm Goals
| All Systems | Fairness (공정성) |
- 모든 프로세스는 공평하게 CPU를 할당받아야 한다. |
| Policy Enforcement (정책의 시행) |
- 시스템을 이용하는 곳의 정책에 부합해야 한다. | |
| Balance (밸런스) |
- CPU를 포함한 모든 H/W 자원들이 원활히 사용되어야 한다. (최대한 바쁘게) | |
| Batch Systems | Throughput (처리율) |
- 단위시간 당 처리할 수 있는 Job의 개수가 많아야 한다. |
| Turnaround Time (소요 시간) |
- Operator에게 Job의 처리를 요청하고, 결과를 받아보기까지 소요되는 시간이 짧아야 한다. | |
| CPU Utilization (CPU 효율) |
- CPU가 바쁘게 움직여야 한다. | |
| Interactive Systems | Response Time (반응 시간) |
- 요청에 대한 처리가 즉각적으로 이루어져야 한다. |
| Proportionality (비례성) |
- 사용자가 기대하는 처리시간을 만족해야 한다. (10개를 처리하는데 10초가 걸린다면, 100개는 100초내에 처리해야 한다.) |
|
| Real-Time Systems | Meeting Deadlines (기한 만족시키기) |
- Job이 제한시간 내에 처리되어야 한다. (특히, Hard Real-Time 환경에서) |
| Predictability (예측) |
- 일정수준 이상의 서비스 품질이 유지되어야 한다. (특히, Streaming 서비스와 같은 Soft Real-Time 환경에서) |
* Starvation Issue
- Ready Queue에 들어온 프로세스가 Scheduling Algorithm에 의해 CPU를 계속해서 할당받지 못하는 상황을 의미한다.
- "CPU를 굶는다."라는 의미에서, Starvation이라 표현한다.
- Scheduler는 Starvation의 최소화를 지향해야 한다.
* Starvation의 해결방법 (= aging)
- Ready Queue에서 오래 대기한 Job들의 우선순위를 높게하고,
CPU를 사용한 시간이 높은 Job들의 우선순위를 낮게한다.
- Starvation Issue가 있는 SJF, SRTN, Priority Scheduling에 적용할 수 있다.
Scheduling Algorith : FCFS (First-Come First-Served)
- 일반적으로, Batch System에서 사용하는 알고리즘이다.
- 대체로, Non-Preemptive Scheduling 방식으로 구현된다.
- Create된 순서대로 프로세스를 처리하는 방식이다.
- 모든 Job이 동등하게 처리된다. (즉, Create된 순서만을 고려하여 우선순위를 설정한다.)
- Starvation이 없다. 언젠가는 처리될 것이기 때문이다.
* FCFS 구조는 평균 Response Time과 Turnaround Time이 커질 가능성이 있다.
\(\mathrm{Response \; Time} \; = \; \mathrm{Waiting \; Time \; + \; CPU \; Burst \; Time}\)
※ 이번 학기에서는 Response Time과 Waiting Time을 같은 개념으로 간주한다.
(이번 학기에만 한정된 개념, 원래는 Response Time안에 Waiting Time이 포함되어 있는 구조이다.)
\(Case \; I\)
\(: \; \mathrm{Throughput} \; = {12 \over 3} \; = \; 4\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; A \; = 10\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; B \; = 10 + 1 = 11\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; C \; = 10 + 1 + 1 = 12\)
\(Case \; II\)
\(: \; \mathrm{Throughput} \; = {12 \over 3} \; = \; 4\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; A \; = 1 + 1 + 10 = 12\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; B \; = 1\)
\(: \; \mathrm{Response \; Time \; for \; Job} \; C \; = 1 + 1 = 2\)
※ 위 그림에서 Process Switching으로 인해 발생하는 Overhead는 생략되어 있다.
* FCFS의 문제점
- Average Turnaround Time이 커질 가능성이 있다.
\(\mathrm{Avg \; Turnaround \; Time} \; = \; \sum\limits_{i} (\mathrm{Response \; Time \; for \; Job \;} i) \; / \; \mathrm{The \; Number \; of \; Jobs}\)
\(Case \; I\) (=FCFS)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (10 + 11 + 12) \; / \; 3 = 11\)
\(Case \; II\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (1 + 2 + 12) \; / \; 3 = 5\)
※ 위 그림에서 Process Switching으로 인해 발생하는 Overhead는 생략되어 있다.
Scheduling Algorithm : SJF (Shortest Job First)
- 처리시간이 가장 작은 Job을 먼저 처리하는 방식이다.
- 모든 Job들이 동시에 요청된 경우에 SJF가 최적의 성능을 발휘한다.
- 대체로, Non-Preemptive Scheduling 방식으로 구현된다.
- Job A가 처리되던 도중, Ready Queue에 있는 모든 Job들 중 가장 짧은 시간을 요구하는 Job Z가 새로 삽입되었을 경우,
Job A는 마저 처리하고, 그 이후에 Job Z를 처리한다.
- FCFS와 달리, SJF에서는 새로운 Job이 삽입될 때 마다 처리할 순서를 다시 계산하는 Scheduling Overhead가 존재한다.
- 모든 Job이 동시에 요청된 경우, SJF를 이용한 방법은 최적의 Average Turnaround Time을 도출한다.
\((a)\) Method
\(: \; \mathrm{Throughput} \; = {20 \over 4} \; = \; 5\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (8 + 12 + 16 + 20) \; / \; 4 = 14\)
\((b)\) Method (=SJF)
\(: \; \mathrm{Throughput} \; = {20 \over 4} \; = \; 5\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (4 + 8 + 12 + 20) \; / \; 4 = 11\)
* SJF의 문제점
1) 현실 상황에서는 CPU Burst Time을 예측하기가 힘들기 때문에 SJF를 적용하기가 쉽지 않다.
2) 특정한 상황에서는, SJF가 최적이 아닌 경우가 발생한다.
- SJF가 최적의 성능을 보이기 위해선, 모든 Job이 동시에 요청되어야 한다.
- 모든 Job들이 Ready Queue에 준비되어 있어서, 한꺼번에 Scheduling이 가능한 환경이어야 한다.
3) CPU Burst가 큰 Job에 대한 Starvation이 발생할 가능성이 있다.
Example. (SJF가 최적이 아닌 경우 예시)
Job A, B는 0초에 동시에 요청되었고, Job C, D, E는 3초에 동시에 요청되었다.
Job A, B, C, D, E의 CPU Burst Time은 각각 2, 4, 1, 1, 1일 때, SJF의 수행결과는 아래 그림과 같다.
\(Case \; I\) (=SJF)
Turnaround Time
Job A = 2
Job B = 6
Job C = 4 (3초에 요청되었음에 유의!)
Job D = 5 (3초에 요청되었음에 유의!)
Job E = 6 (3초에 요청되었음에 유의!)
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (2 + 6 + 4 + 5 + 6) \; / \; 5 = 4.6\)
\(Case \; II\) (=Not SJF)
Turnaround Time
Job B = 4
Job C = 2
Job D = 3
Job E = 4
Job A = 9
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (9 + 4 + 2 + 3 + 4) \; / \; 5 = 4.4\)
Scheduling Algorithm : SRTN (Shortest Remaining Time Next)
- Preemptive Scheduling 버전의 SJF이다.
- 매 Scheduling마다, 현재 필요한 CPU Burst중 가장 최솟값을 찾아서, 해당 Job을 먼저 처리한다.
(Preemptive 방식이기 때문에, 주기적으로 Scheduling이 일어난다.)
- SRTN에서는 각 Job들의 CPU Burst를 알고 있다 가정한다.
Example.
\(Case \; \mathrm{SRTN}\) (= Preemptive SJF)
Turnaround Time
Job A = 2
Job B = 9
Job C = 1
Job D = 2
Job E = 3
\(: \; \mathrm{Throughput} \; = {9 \over 5} \; = \; 1.8\)
\(: \; \mathrm{Avg. \; Turnaround \; Time} \; = (2 + 9 + 1 + 2 + 3) \; / \; 5 = 3.4\)
* SRTN의 문제점
- Non-Preemptive 방식보다, 잦은 Scheduling으로 인해 발생하는 Overhead의 크기가 더 크다.
(Preemptive 방식의 고질적 문제점이다.)
- SRTN 또한, SJF와 같이 Starvation이 발생할 가능성이 있다.
Scheduling Algorithm : Round Robin (RR)
- Preemptive Scheduling 방식이다.
- Ready Queue의 맨 앞에 있던 Job이 CPU를 Quantum만큼만 사용하고, 다시 Ready Queue의 맨 뒤에 삽입된다.
(Quantum이 존재한다 -> Preemptive Scheduling)
- RR에는 Starvation이 발생할 가능성이 없다.
* Round Robin의 문제점
- Quantum의 값이 작으면, 잦은 Context Switch로 인해 Overhead가 커진다.
- Quantum의 값이 크면, Non-Preemptive Scheduling처럼 Response Time이 커진다.
(즉, Quantum의 값을 정하기가 어렵다.)
Scheduling Algorithm : Priority Scheduling
- Job들에 우선순위를 부여하고, Ready Queue에 있는 Job들 중 우선순위가 가장 높은 Job부터 CPU를 할당한다.
- 우선순위가 같은 Job들 끼리는 FCFS로 진행한다.
* Priority Assignment (우선순위 부여)
1) Static Assignment
- User, Price, 기타 등등에 의해 정적으로 우선순위를 부여한다.
2) Dynamic Assignment
- I/O Bound Process에게 더 높은 우선순위를 부여한다.
(I/O Bound Job은 Quantum을 다 못쓴 채, I/O 연산을 수행할 확률이 높기 때문에, 높은 우선순위를 갖게 하는 것이다.)
- 우선순위 = 1 / \(f\) (\(f\): Quantum중 해당 프로세스가 실질적으로 CPU를 사용한 시간의 비율)
ex) Quantum이 10이고, A 프로세스가 2만큼 CPU를 사용하고 I/O 요청으로 인해 Block되었다면,
이 프로세스의 우선순위는 \(1 / {2 \over 10} = 5\)이다.
Example.
- 각 Job들에 우선순위를 부여한다.
- 같은 우선순위를 가진 Job들끼리는 Round Robin 방식으로 CPU를 할당한다.
- aging 방법 등을 사용하여 Starvation이 발생할 여지를 제거해야 한다.
* Priority Scheduling의 문제점
- Starvation이 발생할 수 있다.
Scheduling Algorithm : Multiple Queues
- 다수의 Queue가 존재하여 Job들이 삽입되고, 각각의 Queue 마다 저마다의 Scheduling 알고리즘을 적용한다.
- 각 Job들은 Queue 사이를 옮겨다닐 수 있다.
* Multi-Level Feedback Queues (MLFQ)
- 각각의 Queue들은 저마다의 Job Type을 갖고, 해당되는 Job들이 삽입된다.
(Job Type: Batch, Interactive, System, CPU-Bound, etc)
- 하나의 Queue 내에서 스케줄링은 Round Robin 방식으로 진행된다.
- 우선순위가 낮은 Queue에는 Quantum을 크게 할당하여 Context Switch로 인한 오버헤드를 줄인다.
- Feedback : 어떤 Job이 처리되기에 알맞는 Queue에 배치되도록 하는 것이다.
ex) 만약, CPU-Bound Job이 높은 우선순위의 Queue에 배치되어 Quantum을 모두 소진하면,
우선순위를 낮추어서 Quantum을 길게 가져갈 수 있게 "Feedback"받는다.
ex) 만약, I/O-Bound Job이 낮은 우선순위의 Queue에 배치되어 Quantum을 모두 소진하지 못한 채 I/O 연산을 수행하게 되면,
우선순위를 높여서 Response Time을 제고할 수 있도록 "Feedback"받는다.
SchedulingAlgorithm : Guaranteed Scheduling
- 할당된 CPU 시간 중, 실질적으로 소진한 CPU 시간이 적은 Job에게 높은 우선순위를 부여한다.
(Ratio가 가장 낮은 Job에 높은 우선순위를 부여한다.)
* Ratio = 실질적인 CPU 소비시간 / CPU 할당 시간
- 어떤 Job에 CPU 할당이 끝나면, 해당 Job의 Ratio를 다시 계산하여 모든 Job들의 우선순위를 갱신한다.
(즉, 모든 Job들의 실질적 CPU 사용 시간을 동일 선상에 위치하게 만든다. = 모든 Job들이 비슷한 Ratio를 가지도록)
SchedulingAlgorithm : Lottery Scheduling
- Job마다 Lottery Ticket을 부여하고, Scheduler는 랜덤하게 Lottery Ticket을 뽑는다.
(이 때, 하나의 Job은 다수의 티켓을 보유할 수 있다.)
- 뽑힌 Lottery Ticket을 보유한 Job에게 CPU를 할당한다.
- 전체 티켓의 총량에서 Job이 티켓을 보유한 만큼, CPU를 할당받을 수 있다는 보장이 있다.
(Priority를 부여하는 방식에서는, 실질적으로 CPU를 할당받는 양을 예측할 수 없다는 점에서 대비적이다.)
- 즉, Lottery Scheduling방식은 Performance Assurance를 제공한다.
* Lottery Scheduling의 특성
1) Highly Responsive
- 새로 Ready Queue에 진입한 Process도 CPU를 바로 할당받을 수 있는 가능성이 있다.
2) Ticket Exchanging
- 동일한 Task를 수행하는 Process끼리는 Lottery Ticket을 주고 받아 협력하며 진행도를 비슷하게 가져갈 수 있다.
3) Propotional Scheduling
- Process들에게 CPU를 특정 비율로 할당해야 하는 경우에 Lottery Scheduling 방식이 적합하다.
ex) Frame Rate이 10, 20, 25인 3개의 Job이 있는 경우, 전체 Ticket 55개를 10개, 20개, 25개로 분배하면 된다.
(다른 Scheduling 방식에서는 비율로써 나누는 것이 쉽지 않다.)
SchedulingAlgorithm : Fair-Share Scheduling
- Process 단위로 CPU를 할당하는 것이 아닌, Process를 구동하는 User들에게 공평하게 CPU를 할당하는 것이다.
ex) 8개의 Process를 구동중인 User A와 2개의 Process를 구동중인 User B는 전체 CPU Time=10을 공평하게 5씩 나누어 갖는다. (Process 단위가 아닌, User 단위로 CPU를 할당한다.)
Scheduling in Real-Time System (실시간 시스템에서의 스케줄링)
- Hard Real-Time 혹은 Soft Real-Time 시스템에서는 Process Behavior가 예측가능한 경우일 확률이 높다.
- Real-Time 시스템에서는 Response Time, Turnaround Time 보다는 Schedulable 여부가 중요하다.
(즉, Dead Line을 충족하도록 Scheduling할 수 있는지가 가장 중요하다.)
* Periodic : Event가 Regular하게 발생되는 경우를 의미한다. (Event란, CPU를 할당하여 처리해야 하는 일을 의미한다.)
* Aperiodic : Event가 불규칙적으로 발생되는 경우를 의미한다. Dead-Line을 충족시키기 어렵다.
* Schedulable 여부 판단식
\(\sum\limits_{i=1}^{m} {C_i \over P_i} \leq 1\)
\(m\) : Periodic하게 발생되는 Event의 개수
\(C_i\) : \(\mathrm{Event_i}\)가 완전히 처리되는데 필요한 CPU Time
\(P_i\) : \(\mathrm{Event_i}\)가 발생되는 주기
ex) \((C_1 = 50ms, P_i = 100ms), (C_2 = 30ms, P_2 = 200ms), (C_3 = 100ms, P_3 = 500ms)\) 인 경우,
\(\sum\limits_{i=1}^{3} {C_i \over P_i} = {50 \over 100} + {30 \over 200} + {100 \over 500} = 0.85 \leq 1\) 이므로,
이 경우는 Dead Line을 충족하도록 Schedulable하다.
만약, 여기서 하나의 Event가 더 추가된다면, 추가되는 Event의 Ratio는 0.15이하여야 할 것이다.
* Static Real-Time Scheduling
- System이 시작되기 전에 Scheduling이 결정되는 것이다.
* Dynamic Real-Time Scheduling
- System이 구동되면서 동적으로 Scheduling이 이루어지는 것이다.
Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)