
Address Aggregation
주소 집단화
- Classless 주소 지정 방식에서, 라우팅 테이블의 크기가 증가되는 고질적인 문제를 완화하기 위한 방법이다.
- Subnetting(서브네팅)의 반대개념인 Supernetting(수퍼네팅)은 할당받은 다수의 네트워크 주소를 통합하는 것을 의미한다.
- 수퍼네팅은 개념적으로 존재하는 방법으로, 실제 환경에서는 잘 사용되지 않는 방식이며, 대신 Address Aggregation 방식이 널리 사용된다.
Ex. 8개의 C Class 주소들에 대한 Address Aggregation 예시

- 8개의 네트워크를 통합되면 3Bit의 Host-id 필드가 추가된다.*
- 통합된 네트워크를 관리하는 Site Router에 인접한 Internet Router는 네트워크의 통합 여부를 알 지 못하며, 여전이 해당 네트워크의 원래 주소(203.249.32.0/24 ~ 203.249.39.0/24)로 구분짓는다.
* n개의 네트워크가 통합되면 \(\lceil\log_{2} n\rceil\)Bit의 Host-id 필드가 추가되며, 동일한 만큼의 Net-id 필드가 감소된다.

- 라우터 R1에서는 Organization 1~4를 구분하기 위해 4개의 인터페이스를 구분지어 놓은 라우팅 테이블을 구비해야 할 필요가 있다.
- 라우터 R2에서는 Organization 1~4에 상관없이 해당 기관들에 메세지를 보내기 위해서는 필연적으로 R1을 거쳐야 하기 때문에, 굳이 라우팅 테이블을 복잡하게 유지할 필요가 없다.
- 이처럼, 4개의 기관들이 수퍼네팅을 통해 합쳐진 것은 아니지만, 라우팅 테이블에 의해 논리적으로 합쳐지는 것이 주소 집단화의 대표적 예시이다.
Longest Mask Matching (가장 긴 마스크 부합)
- Classless 주소 지정 체계에서 라우팅 테이블 내의 엔트리가 Mask 값의 크기에 대한 내림차순으로 정렬되어 있어,
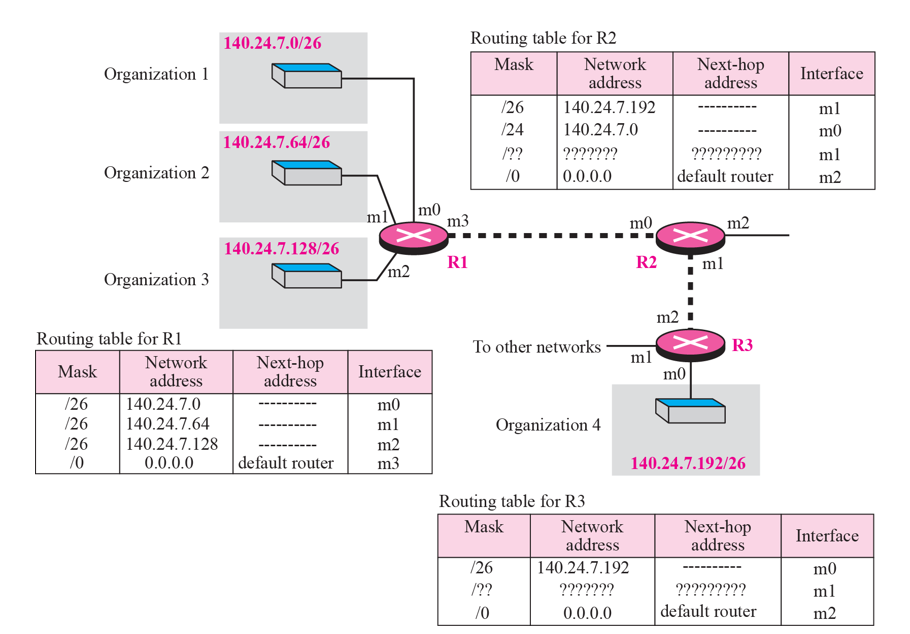
- 위 그림은 1~3번 기관과 4번 기관이 물리적으로 떨어져있지만, 논리적으로 Address Aggregation이 이루어진 형태이다.
- R2에서 기관 1~3은 140.24.7.0/24으로 Aggregation된 상태이고, 기관4의 주소는 140.24.7.192/26와 같은 형태로 더 구체화(Long)된 형태이다.
ex) 140.24.7.193/26과 같은 기관 4에 해당되는 주소가 R2에 도착하면 R2의 라우팅 테이블의 마스크 /26과 더 정밀하게 매칭(Longest Mathcing)되므로 해당 메세지는 정상적으로 기관 4에 전송되게 된다.

- 라우팅 테이블에서 패킷의 주솟값을 보고 적절한 라우팅 엔트리에 매칭시키는 대표적인 방법으로는 Longest Match Algorithm(가장 긴 부합 알고리즘)이 있다.
- 하지만, Longest Match Algorithm은 Mask를 기준으로 정렬되어 있는 엔트리를 Sequential Searching 하는데 평균적으로 \({n \over 2}\) 시간이 걸려, 실행 시간 측면에서 불리하다.
- 실제 라우터의 라우팅 테이블에서 주소와 엔트리를 매칭시키는 알고리즘은 검색과 더불어 엔트리 삽입/삭제 연산에도 용이한 형태로 복잡하게 구현되어 있다.
(실제 라우팅 테이블은 엔트리 삽입/삭제에 용이하도록 Mask를 기준으로 정렬하지 않는다. 정렬을 해놓을 시, 삽입/삭제에 소요되는 시간이 커지기 때문이다.)
Reference: TCP/IP Protocol Suite 4th Edition
(Behrouz A. Forouzan 저, McGraw-Hill, 2010)
Reference: Data Communications and Networking 5th Edition
(Behrouz A. Forouzan 저, McGraw-Hill, 2012)