
6장 변수, 바인딩, 식 및 제어문
6.1 Variables(변수)
- 명령형 PL의 중요한 특징 중 하나는 변수의 생성을 허용하는 것이다.
- 변수의 Attribute(속성)은 일반적으로 프로그래밍 과정에서 변할 수는 있으나, 컴파일 시간에 한 번 정해지면 변할 수 없다.
- 변수에는 항상 어떤 값이 존재해야 하며, 이 값은 변할 수 있다. (정의되지 않은 값도 값으로 간주한다.)
※ PL의 가장 기본적인 추상화 메커니즘은 Identifier(Name; 식별자, 이름)를 사용하는 것이다.
Variable(변수)의 정의 (ISO 국제 규격)
- 변수란, 선언문 또는 묵시적 선언으로 생성된다.
- 변수는 아래 4가지 요소로 구성된다.
1. Identifier(식별자, 이름)
2. Data Attribute(데이터 속성)들의 집합
3. 하나 이상의 Reference(참조, 주소)
4. Value(데이터 값)
- 주소와 데이터 값들의 관계는 변할 수 있다.
Variable(변수)의 정의 (D.W.Barron)
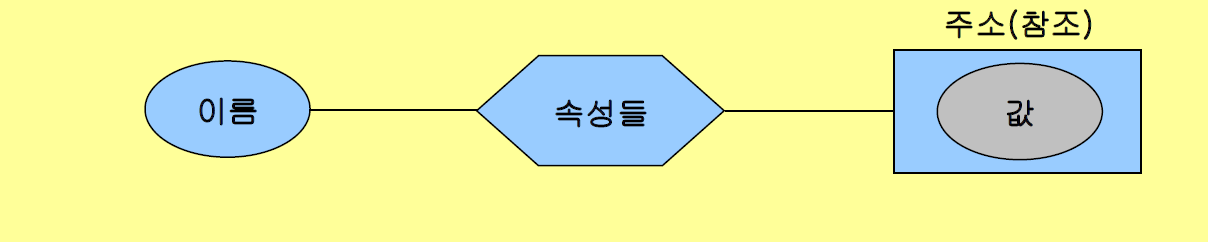
- 회색 원은 변수가 현재 저장하고 있는 값을 의미한다.
- 이름과 속성, 주소가 연결되어 있는 형태이다. 즉, 이름을 통해 속성이나 주소를 알아낼 수 있다.
Ex. D.W.Barron의 변수 정의에 배정문을 적용한 형태 예시
- Assignment Statement : \(\texttt{x := 3.14159}\)

- 변수의 주소는 로더가 프로그램이 적재될 장소를 확정지어야 정해지는 값이다.
6.2 Binding(바인딩)
- 변수의 4가지 요소에 값을 확정하는 행위, 이름에 특정 Attribute(속성)를 연결하는 과정(기본적인 추상화)을 Binding(바인딩)이라 한다.
- 즉 바인딩이란, 프로그램의 기본 단위에 이 기본 단위가 택할 수 있는 Attribute를 결정하는 행위를 의미한다.
ex) 어떤 PL에서는 상수 선언과 같이 이름에 값을 연결하는 과정을 Declaration(선언)보다는 바인딩이라 표현하기도 한다.
- PL에서 이름에 의미를 부여하기 위해 Location(주소), Value(값) 개념이 필요하다. (변수의 Attribute(속성) 개념과 유사하다.)
바인딩 시간
- 프로그램이 생성 및 실행되는 동안, 바인딩 할 대상(속성)을 파악하는 시간을 의미한다.
- 바인딩 시간은 PL에 많은 제한을 가하는 매우 중요한 요소 중 하나이다.
Static Binding(정적 바인딩)
- Compilation Time(번역 시간) 동안 이루어지는 바인딩이다.
Dynamic Binding(동적 바인딩)
- Runtime(Execution; 실행 시간) 동안 이루어지는 바인딩이다.
- 일반적으로, 동적 바인딩이 정적 바인딩보다 더 빈번히 수행된다.
바인딩 시간의 종류
- 대표적으로, Runtime(실행 시간), Translation Time(번역 시간), Language Implementation Time(언어 구현 시간), Language Definition Time(언어 정의 시간) 으로 구성된다.
| 실행 시간 | 번역 시간 | 언어 구현 시간 | 언어 정의 시간 |
| ← 늦은 바인딩 | 이른 바인딩 → |
1. Runtime(Execution; 실행 시간)
- 변수에 값을 확정하는 과정, 변수 및 자료 구조에 메모리를 할당하는 과정이 수행되는 시간이다.
- 실행 시간은 두 가지 개념으로 분할된다. (모듈 시작 시간, 실행 시간의 사용 시점)
1.A 모듈 프로그램이 실행되는 시간에 발생되는 바인딩
- 대부분의 PL에서 중요한 바인딩들은 Module Program(Subprogram, Block) 실행 시작 시간에 발생된다.
- 대부분의 PL에서, Parameter(형식 매개변수)와 Argument(실 매개변수)를 바인딩하거나, Local Variable(지역 변수)에 대한 메모리 할당 등이 모듈 시작 시간에 수행된다.
1.B 프로그램 실행 시, 사용 시점에서 수시로 발생되는 바인딩
- Assignment Statement(배정문)에서 변수에 값을 바인딩하는 것이 대표적이다.
- APL과 같은 일부 PL에서는 이 시간동안 변수에 메모리를 할당하는 바인딩을 수행하기도 한다.
2. Translation Time(번역 시간) = 컴파일/링크/로드 시간
- 컴파일러 언어에서, 중요한 바인딩들은 대부분 번역 시간에 정적 바인딩된다.
- 번역 시간동안 발생되는 바인딩으로는 변수와 자료 구조, 레코드 항목들의 Data Type(데이터 형), 자료 구조의 크기 등을 확정하는 바인딩이 있다. (주로, 데이터 형이 결정된다.)
- 번역 시간은 실행순으로, 컴파일 시간, 링크 시간, 로드 시간으로 구성된다.
- Fortran은 변수에 대한 메모리 할당은 번역 시간 중 로드 시간에 수행된다.
3. Language Implementation Time(언어 구현 시간)
- 컴퓨터에서 언어의 컴파일러를 생성할 때, 해당 언어의 특징이 구현되는 시간을 의미한다.
- 모든 PL에서, 언어 정의 시에 해당 언어의 Language Construct(구성자)들에 대한 많은 특성을 구체적으로 한정짓지 않고, 언어가 실제 시스템에 구현될 때 구체적인 특성까지 확정하도록 하는 구조를 띄고 있다.
ex) C언어에서, int 타입의 크기(4Byte 혹은 2Byte)가 시스템마다 다른 이유가 이것 때문이다.
- 구성자의 구체적 특성이란, 허용되는 정수의 자릿수, 실수의 유효 숫자 개수, 수치의 H/W적인 표기법* 등이 해당된다.
* 수치의 H/W적 표기법
- Endianness(빅-엔디안, 리틀-엔디안), 보수 표기법(1의 보수, 2의 보수)와 같은 표기를 의미한다.
- 고성능 컴퓨터의 경우, 위와 같은 표준 이외에 자신의 시스템에 최적화 된 표기를 사용하기도 한다.
4. Language Definition Time(언어 정의 시간)
- PL의 대부분의 구조(허용되는 자료 구조, 프로그램 구조, 문법 구조, 혼합형 연산 지원 여부 등)가 정의되는 시간이다.
- 대부분의 PL에서는 정의 시간에 많은 바인딩을 수행하고, 언어 구현 시간에 수행되는 바인딩을 최소화한다.
(이는, 프로그램이 한 특정 기종이나 구현에 구애받지 않도록하는 호환성을 제고하기 위함이다.)
- Fortran에 비해, C가 언어의 구현 시간에 일어나는 바인딩을 줄였기 때문에, C 프로그램은 Fortran 프로그램보다 호환성과 이식성이 우수하다.
- Ada와 Java는 정의 시간동안 많은 바인딩을 수행하고, 구현 시간 동안의 바인딩을 극도로 제한하여 호환성이 매우 높다.
Example 6.1 (프로그래밍 언어 개념 p.171)
아래 단순 배정문에서 발생되는 바인딩과 바인딩 시간에 관해서 논하여 보자.
\(\texttt{y = x + 10;}\)
1. 변수 x에 대한 값은 아래와 같은 경우에 확정짓게 된다.
- x가 배정 연산자(=)의 왼쪽에 존재했을 때
- 매개변수로 연결되어 호출되었을 때
- 입력문에 의해 배정되었을 때
2. 변수 x에 대한 데이터 형
- 컴파일러 언어*에서 x의 데이터 형은 프로그램 작성시에 확정된다.
- 즉, 번역 시간(컴파일 시간) 동안에 확정된다.
- 컴파일 시간에 데이터 형이 결정됨으로써, x가 실행 시간에 취할 수 있는 값의 종류, x에 할당되는 메모리 크기 또한 결정된다.
* 대표적인 컴파일러 언어로 Java, C, Fortran, PL/I 등이 있다.
3. 변수 x가 취할 수 있는 데이터 형의 종류
- 대부분의 PL에서는 언어 정의 시간 동안에 데이터 형의 종류(int, float 등)가 확정된다.
- Pascal은 사용자가 데이터 형을 추가할 수 있기 때문에 번역 시간 동안에 확정된다.
- Snobol4는 프로그램 실행 시간 동안 사용자가 데이터 형의 종류를 확장시킬 수 있게 구현했다.
4. 상수 10의 표현 방법
- "10진수로써의 상수 10" 이라는 의미는 언어 정의 시간에 바인딩된 것이다.
- "10의 H/W적인 표현"은 언어 구현 시간에 바인딩된 것이다.
- 일반적으로, 메모리에 상수 10을 할당하는 바인딩은 번역 시간에 수행된다.
5. Operator "+"와 "="의 성질과 의미
- + 기호를 덧셈 연산를 의미하게 하는 것은 언어 정의 시간에 확정된 것이다.
- +기호에 붙는 Operand(피연산자)를 통해 어떤 데이터 형에 대한 덧셈 연산을 수행할 지를 결정한다.
- 컴파일러 언어에서는 피연산자의 데이터 형이 컴파일 시간에 확정되므로, 연산 종류 또한 컴파일 시간에 바인딩된다.
- 덧셈 연산의 한계 값 개념(유효 숫자 등)은 언어 구현 시간에 바인딩된다.
PL마다의 바인딩 시간에 따른 차이
- 여러 PL들의 주된 차이점은 서로 상이한 바인딩 시간으로 인해 발생한다.
Fortran
- 대부분의 바인딩이 번역 시간에 이루어지는 Static Binding이므로, 큰 배열과 많은 연산을 수행하기에 유리하다.
- 값에 대한 바인딩이 번역 시간에 대부분 이루어져, 입력값을 처리하기가 어렵다.
Snobol4
- 대부분의 바인딩이 실행 시간에 이루어지기 때문에, 큰 배열에 많은 연산을 수행하는데에 불리하다.
- 실행 시간까지 바인딩을 늦추어 입력값에 대한 적절한 바인딩이 가능하므로, 입력값을 처리하기가 쉽다.
실행 Efficiency(효율성)을 중시한 PL
- Fortran, Algol, Cobol, C등의 컴파일러 언어가 이에 해당된다.
- 많은 바인딩이 번역 시간동안 수행되는 것을 지향한다.
Flexibility(유연성)를 중시한 PL
- Snobol4, APL, Lisp 등의 인터프리터 언어가 이에 해당된다.
- 대부분의 바인딩을 실행 시간까지 지연시켜, 데이터에 대한 맞춤 바인딩을 수행한다.
+) 실행 효율성과 유연성을 모두 추구한 PL/I 언어에서는 프로그래머가 바인딩 시간을 선택할 수 있는 일부 Option(선택권)을 가지므로, Memory Management에 대한 선택권이 있다.
- 일반적으로, 언어를 정의할 때 바인딩 시간이 명세화되지만, 바인딩이 실제로 수행되는 시간은 해당 언어의 구현에 의해 최종적으로 확정되게 된다.
- 즉, PL설계 시에 바인딩이 초기에 이루어지는 것을 지향하지만, PL구현 시에 불가피하게 바인딩이 지연될 수도 있다.
ex) C 언어는 변수의 데이터 형이 컴파일 시간에 결정되도록 설계되었지만, C언어 구현 시에, 실행 시간까지 변수의 데이터 형을 확정짓지 않을 수도 있다.
※ 주요 PL에서의 식별자 바인딩 시간
| Static Binding (번역 시간 바인딩) |
컴파일 시간 * 프로그램 작성 시간까지 포함 |
1) Fortran, Algol, PL/I, Pascal, Cobol 등의 컴파일러 언어는 대부분의 변수형을 확정 2) 상숫값의 H/W적 표현을 확정 |
| Linkage Edit 시간 | 1) Fortran : COMMON문(메모리를 공유하는 서로다른 변수)에 주어진 이름의 상대 주소 확정 2) Fortran, Algol, PL/I : 서브 프로그램 이름에 관한 상대 주소 확정 |
|
| Load Time (적재 시간, 절대 주솟값이 확정) |
1) Fortran, Cobol : 모든 변수에 메모리(절대 주소) 할당 2) PL/I : 정적 변수에 메모리(절대 주소) 할당 3) Algol, Pascal : 전역 변수에 메모리(절대 주소) 할당 4) Fortran : DATA문에서 정의된 값을 변수에 배정 |
|
| Dynamic Binding (실행 시간 바인딩) |
모듈이 실행되기 시작한 시간 (호출 시간) |
1) Argument를 Parameter에 연결 by Value : Argument를 지역 변수에 배정 by Reference : Argument를 Parameter 변수로 사용 가능하도록 주소를 배정 by name : 사용 시, 주소와 값을 계산할 수 있는 Thunk Routine의 주소 확정 (주소와 값을 동시에 전달) 2) Algol, Pascal : 지역 변수에 대한 메모리 할당 (활성 레코드가 생성됨) 3) PL/I : AUTOMATIC 변수에 대한 메모리 할당 |
| 수시로 바인딩되는 시간 | 1) PL/I : BASED 변수의 메모리 (ALLOCATE문, FREE문) 2) APL, Lisp, Snobol4 : 변수들에 데이터 형 배정, 메모리 할당 3) 모든 PL : 배정문 등에서 변수의 값을 배정 |
6.3 Declarations (선언)
- 선언이란, 실행 시 사용될 데이터의 Attribute(속성)*을 언어의 번역기에게 알리는 프로그램 Statement(문장)를 의미한다.
- 바인딩을 제공하는 중요한 방법이다.
- 선언문은 크게 Explicit Declaration Statement(명시적 선언문)와 Implicit Declaration Statement(암시적 선언문)으로 나타난다.
- 많은 PL에서, 간접적인 선언 방법으로써 명시적 선언이 없으면 암시적 선언으로 간주하는 Default Declaration(디폴트 선언) 방식을 택했다.
- 선언을 통해 실행 효율성을 제고할 수 있고, 선언을 생략함으로써 유연성을 제고할 수 있다.
- Lisp, APL, Snobol4에서는 선언문을 사용하지 않아서 간결한 프로그래밍이 가능하지만, 동적 형 검사로 인한 실행 시간 저하, 데이터 표현의 효율 저하, 복잡한 메모리 관리 방식과 같은 단점이 있다.
- APL은 선언문 개념을 갖고 있지 않으며, 배열은 무조건 동적으로 생성된다.
- Java, C/C++, Fortran, Algol, Pascal과 같은 대부분의 PL에서는 구체적인 선언 방식과 내용 수정에 관한 규칙과 같은 제약 조건이 있어 프로그래밍을 복잡하게 하지만, 효율적인 실행이 가능하다.
- Java에서는 배열 선언 시, 데이터 형과 배열의 차원수를 필수적으로 요구하며, 크기와 첨자의 범위는 선택적으로 요구함으로써 실행 효율성과 유연성을 동시에 갖는다.
- 특히, Fortran은 배열 선언문에서 데이터 형, 차원의 수, 각 차원의 첨자 범위 등 많은 사항을 요구함으로써 효율적인 배열 처리가 가능하다.
- PL/I에는 효율성과 유연성을 이상적으로 조화한 많은 특징을 보유하고 있다.
* Attribute of Data (데이터의 속성)
- 데이터 형, 크기, 이름, 생성 시기, 소멸 시기, 참조하기 위한 첨자 등
선언문의 3가지 목적
1. 메인 메모리의 효율적인 사용 및 접근이 가능하다.
- 선언문의 주요 사용 목적은 실행 시간동안, Immutable한 자료 구조의 속성들을 한정하는 것이다.
- 자료 구조들의 속성을 한정함으로써, 시간 복잡도, 공간 복잡도가 개선된다.
2. 효율적인 메인 메모리 관리가 가능하다.
- 선언문이 제공하는 자료 구조의 크기, 생성/소멸 시기 등을 번역 시간동안 알게되어, 실행 시간 동안에 효율적인 메모리 할당이 가능해진다.
- Algol 형태 PL에서는 선언을 통해 변수, 배열의 생성/소멸 시기를 파악할 수 있어, 실행 시간동안 간결한 Stack 기법을 사용한다.
- 인터프리터 언어에서는 배열 선언 개념이 없어, 복잡하고 비효율적인 메모리 기법인 Heap 기법을 사용한다.
- Java에서는 실행 시 배열 객체를 생성하는 방식을 택했다. (Heap 기법 + Stack 기법)
3. Static Type Checking(정적 형 검사)이 가능하다.
- 번역을 통해 자료 구조의 데이터 형을 한 번에 파악하는 작업이다. (모든 변수에 데이터 형 선언을 요구한다.)
- 선언문은 번역 시간 동안 데이터 형을 파악할 수 있게하여 혼합형 연산*을 형 고정 연산**으로 변환할 수 있게 한다.(혼합형 연산의 시간/공간적 문제를 보완한다.)
- 정적 형 검사를 함으로써, 번역하는 동안 데이터 형을 파악해서 혼합형 연산으로 구성된 목적 코드를 형 고정 연산으로 구성된 목적 코드로 변환할 수 있다.
- 정적 형 검사를 통해 잘못 사용된 데이터 형을 감지하는 등 많은 오류를 번역 시간동안 검증할 수 있게 하여 신뢰성을 제고한다.
- 데이터의 생성/소멸/수정에 관한 많은 제약이 존재하나, 실행 효율성이 높다.
- Java, C, Fortran, Algol, Pascal 등의 컴파일러 언어에서 정적 형 검사가 수행된다.
* Type Specific Operation(형 고정 연산)
- Operand와 결과값의 데이터 형이 고정된(일치하는) 연산
- H/W적으로 구현되는 연산이다.
** Generic Operation(Mixed Operation; 혼합형 연산)
- Operand와 결과값이 데이터 형이 고정되지 않은(혼재된) 연산이다.
- S/W적으로 구현되는 연산이다. (S/W Simulating을 통한 구현)
- 대부분의 PL에서는 혼합형 연산을 지원한다.
- C++에서는 Operator Overloading을 통해 사용자가 직접 혼합형 연산을 정의할 수 있다.
- 혼합형 연산이 실행될 때 마다 Operand의 데이터 형을 검사하고, 이를 위해 각 데이터들의 명세표를 보관하고 있으므로 시간/공간 복잡도가 저해된다.
※ Dynamic Type Checking(동적 형 검사)
- 실행 시간 동안 혼합형 연산을 검사하는 방법이다.
- 선언문을 사용하지 않는다.
- 간결한 프로그래밍이 가능하며, 유연성이 높다.
- 실행 시간이 지연되고, 데이터 표현상의 효율이 저해되며, 복잡한 메모리 관리 기법이 요구된다.
- Lisp, APL, Snobol 4 등의 인터프리터 언어에서 동적 형 검사가 수행된다.
6.4 배정문 (Assignment Statement)
- Assignment(배정) 연산은 변수의 내용을 변경하는 원시적인 연산이다.
- 대표적인 PL들의 배정문 형태는 아래 표와 같다.
| Programming Language | Assignment Statement |
| C, Java, Fortran | \(\text{A = B}\) |
| Algol, Pascal | \(\text{A := B}\) |
| APL | \(\text{A ← B}\) |
| Basic | \(\text{LET A = B}\) |
| Cobol | \(\text{MOVE B TO A}\) |
L-Value & R-Value
- 배정문 "\(\texttt{A := B}\)"에서 변수 B는 변수의 속성 중 값을, 변수 A는 참조를 의미한다.
- 배정문에서 L-Value(Left Value)는 변수의 4 요소 중 참조를 의미한다.
- 배정문에서 R-Value(Right Value)는 변수의 4 요소 중 값을 의미한다.
- R-Value로서의 수식은 해당 수식을 계산한 결과값이며, L-Value로서의 수식은 일반적으로 존재하지 않는다.
- Bliss 언어에서 변수명은 배정문 좌우 위치에 관계없이 항상 L-Value를 의미한다. R-Value는 '.'(Dot) 연산자를 변수명 앞에 붙여서 표현한다.
ex) Bliss에서의 배정문 예시
- 첫 문장은, B의 I-Value(주소)를 변수 A에 저장하는 동작이다.
- 두 번째 문장은 B와 C의 R-Value(값)을 더하여 변수 A에 저장하는 동작이다.
A ← B
A ← .B + .C
- Algol 68에서는 변수를 선언할 때, 데이터 형(\(\texttt{type, mode}\) 앞에 키워드 \(\texttt{ref}\)를 붙여 해당 변수가 L-Value임을 명시한다. 이러한 표기법에 제한이 없어 포인터 개념을 다양하게 사용할 수 있지만 코드가 난해해지기 쉽다는 단점이 있다.
- Algol 68에서 수식 계산 시, 최종 R-Value값을 구하기 위한 Dereferencing(포인터가 가리키는 값을 찾아가는 것)이 자동으로 수행된다.
단순 배정문
- 단순 배정문의 일반적인 Syntax(구문)은 아래 BNF 표기와 같다.
<목적지_변수> <배정_연산자> <식>
- PL/I과 Basic에서는 "="(Equal) 기호가 배정 연산자이자, 관계 연산자이기 때문에 혼돈을 초래할 수 있다.
- Algol 60은 배정 연산자로써 ":="를 처음 사용하였고, 많은 후속 언어가 이를 뒤따랐다.
- Fortran, Pascal, Ada와 같은 언어들에서 배정문은 독립된 문장으로 나타내며, 목적지 변수는 단일 변수로 제한된다.
다중 목적지 배정문
- 수식의 값을 한 개 이상의 목적지 변수에 배정하는 배정문 구문이다.
- C, C++, Java에서는 한 구문에 배정 연산자를 여러 번 사용할 수 있다.
ex) PL/I의 다중 목적지 배정문 예시
SUM, TOTAL = 0
조건 목적지 배정문
- C++, Java에서는 3항 연산자(\(\texttt{A ? B : C}\))를 통해 배정문에 조건 목적지를 허용한다.
ex) 삼항 연산자를 통한 배정문과 동치 관계에 있는 조건문 예시
flag ? count1 : count2 = 0
// 위 문장은 아래 문장과 논리적으로 같다.
if(flag) count1 = 0; else count2 = 0;
Compound Assignment Operator (복합 배정 연산자)
- 배정 형태를 축약시키는 연산자이다.
- Algol 68에서 처음 도입되었으며, C에서 다른 형태로 채택되었다.
- C에서의 복합 배정 연산자는 "=" 연산자 앞에 다른 연산자를 접합시킨 형태이다. (\(\texttt{+=, -=, *=, /=, %=}\))
- C, C++, Java는 대부분의 이항 연산자에 대해서 복합 배정 연산자를 제공한다.
단항 배정 연산자
- C, C++, Java에서는 증감 연산자(\(\texttt{++, --}\))로써 배정문을 축약하는 기능을 제공한다.
- 증감 연산자는 B언어를 계승한 C가 처음으로 구현된 PDP-11 컴퓨터에 H/W적으로 설계되었다.
(증감 연산자는 PDP-11의 H/W 구조에 기반한 것이 아니라, B언어로 부터 유래된 것이다.)
- Prefix Operator(전위 연산자)는 Operand 앞에 위치한 증감 연산자를 의미한다.
- Postfix Operator(후위 연산자)는 Operand 뒤에 위치한 증감 연산자를 의미한다.
Ex. 단항 배정 연산자를 통한 배정문의 축약 예시
count++;
// 위 문장은 아래 문장과 논리적으로 같다.
count = count + 1;
// 또는
count += 1;
- \(\texttt{- count ++}\)와 같이, 두 개의 단항 연산자가 혼재되어 있을 경우, 오른쪽에서 왼쪽으로 결합 법칙이 적용된다. (즉, count가 1만큼 증가된 후, 음수화 된다.)
배정문의 결과값
- C, C++, Java에서 배정문 자체는 목적지에 배정된 값을 반환한다. 이로 인해, 배정문 또한 Operand로 이용될 수 있다.
- C, C++, Java에서 배정 연산자는 관계 연산자보다 우선순위기 낮기 때문에, 적절한 소괄호 사용이 필수적이다.
- C, C++에서는 배정 연산자를 조건식에도 사용할 수 있는데 이는 프로그램의 안전성을 결여시키는 원인이 된다.
ex) C, C++에서는 \(\texttt{if}\)문의 조건식으로 "="연산자를 사용할 수 있는데 이는 "=="연산자와 혼동되어 논리 오류를 발생시킬 수 있다.
ex) Java에서는 \(\texttt{if}\)문의 조건식으로써 Boolean 수식만을 허용한다.
- 배정 연산자가 왼쪽 Operand를 변경하는 것은 배정 연산자의 부수효과에 해당된다.
Ex. 배정문을 Operand로 활용하는 예시
while((ch = getchar()) != EOF) {...}
혼합형 배정문
- 배정 연산자의 좌우에 위치하는 데이터의 형이 서로 다른 경우를 처리하는 배정문이다.
- 혼합형 배정을 허용하는 모든 PL에서 암시적 데이터 형 변환은 우변의 식이 평가된 이후에 수행된다.
(이에 대한 다른 방법으로, 우변의 모든 Operand를 평가하기 전에 목적지 형으로 데이터 형 변환을 수행하는 방법도 존재한다.)
- 혼합형 배정문의 설계 시, 고려사항은 아래와 같다.
1. 식의 타입이 배정되는 변수의 데이터 형과 동일해야 하는가?
2. 두 데이터 형이 일치하지 않은 경우에 암시적 데이터 형 변환을 허용할 것인가?
- Fortran, C/C++에서는 혼합형 식에 사용되는 형태와 유사한 암시적 데이터 형 변환 규칙을 혼합형 배정에 적용했다.
(즉, 암시적 데이터 형 변환이 자유롭게 이루어진다.)
- Java에서는 요구된 데이터 형 변환이 확대 데이터 형 변환인 경우에만 배정을 허용한다.
(즉, Java에서 Narrowing은 허용되지 않는다.)
- Pascal은 암시적 데이터 형 변환이 수행될 수 있는 조건이 존재한다.
(예를 들어, integer값은 real 변수에 배정될 수 있으나, 역은 불가능하다.)
- Ada, Modula-2에서는 혼합형 배정을 불허한다.
6.5 상수 및 변수 초기화
- 이름이 부여된 상수는 프로그램의 Readability(판독성)과 Reliability(신뢰성)을 제고한다.
- 상수 또한 주소를 가질 수 있지만, 프로그램 종료시까지 하나의 데이터 값만을 갖고 있기에 변수의 속성 중, 참조가 결여된 형태를 띈다.
- Literal(리터럴)은 단순히 상수를 대표하는 문자열로, 실제로 메모리에 저장되는 상수와는 다른 개념이다.
- 상수의 특성 설계시 고려사항은 아래와 같다.
1. 상수는 단순 변수에만 사용 가능한가, 아니면 배열, 레코드와 같은 구조적 데이터 형에도 사용이 가능한가
2. 상숫값으로 사용되는 식에서는 단순 상수만을 허용하는가, 아니면 번역 시간이나 실행 시간에 평가되는 임의의 식까지도 허용하는가
3. 상숫값이 배정되는 시점은 언제인가, 프로그램 실행 이전 한 번인가, 아니면 상수가 정의된 블럭이 시작될 때마다 인가
4. 언어가 Predefined Constant(미리 정의된 상수)를 갖고 있는가
- Pascal에서는 상수 정의를 통해 상수의 값과 상수의 이름을 Synonym(동의어)으로 취급한다. (즉, 값을 이름으로 대체한 것이다.) 블럭이 시작될 때, 상수를 정의한 식(값)이 상수 이름에 배정된다.
- Pascal에서 상숫값은 숫자, 문자열, 열거형 등의 단순 데이터 형(스칼라 형)으로 제한된다.
- Pascal에서 상수 선언 시, 예약어 \(\texttt{const}\)를 이용한다. 또한, 내장형 상수로 \(\texttt{true, false, maxint}\)를 보유하고 있다. (3개 밖에 없다.)
- Pascal에서는 변수 초기화 기능을 제공하지 않는다. 즉, 선언과 동시에 초기화할 수 없다.
Ex. Pascal에서 블럭을 처리하는 구문의 BNF 표기
- 아래 BNF 표기에서, 상수 정의가 레이블을 제외한 다른 모든 선언문보다 앞서야 함을 알 수 있다.
<block> ::=<declaration-part> <statement-part>
<declaration-part> ::= [<label-declaration-part>]
[<constant-part>]
[<type-definition-part>]
[<variable-declaration-part>]
[<procedure-and-function-declaration-part>]
<constant-part> ::= const <constant-defn> { :<constant-defn>}
<constant-defn> ::=<identifier> = <constant>
<constant> ::= <integer-number> | <real-number> | <string> | [<sign>] <constant-identifier>
Ex. Algol 68에서의 상수 정의
- \(\texttt{real}\)은 키워드이며, Algol 68에서 배정 연산자는 ":="임에 유의하자. ("="는 상수 선언 연산자)
real root2 = 1.4142135
- Ada에서는 예약어 \(\texttt{constant}\)를 이용하여 상수를 선언한다. Pascal과 대조적으로, 상수 선언 시 식의 사용을 허용한다.
- Ada에서는 상숫값이 번역 시간에 확정되지 않아 상숫값으로 함수를 사용할 수 있다.
- Ada에서는 단순 데이터형부터 구조적 데이터 형에 대한 상수도 허용한다.
(즉, 배열, 레코드 형 상수가 존재할 수 있다.)
- Algol 68에서는 상수 선언과 변수 초기화를 구분하기 위해, 변수 초기화에는 ":="연산자를, 상수 선언에는 "="연산자를 사용하여 구분한다.
- Fortran에서 DATA문들은 번역 시간에 변수들이 값으로 초기화되는 형태이다.
- Pascal에서는 본질적으로 초기화 특징을 제공하지 않는다.
- Ada에서는 초기화가 위치한 블럭이 실행될 때마다 매번 초기화시킨다. 패키지를 이용하여 초기화를 한 번만 수행시키게 하는 방법도 제공하고 있다.
Ex. Ada에서의 변수, 상수 선언문 예시
- \(\texttt{X}\)는 값이 17인 정수형 상수, \(\texttt{Y}\)는 초기값이 17인 정수형 변수이다.
X : constant INTEGER := 17;
Y : INTEGER := 17;
Ex. ANSI C에서의 배열, 상수 선언문 예시
- C에서 \(\texttt#define}\)을 통한 Literal를 제외한, \(\texttt{const}\)를 통한 상수 선언은 ANSI 표준으로부터 도입된 개념이다.
- 아래 코드의 배열에 대한 3가지 선언/초기화 구문은 모두 같은 동작을 수행하게 된다.
const float pi = 3.1415926;
// 아래 세 구문은 모두 같다.
int a[2][3] = {{1, 2, 3}, {4, 5, 6}};
int a[2][3] = {1, 2, 3, 4, 5, 6};
int a[][] = {{1, 2, 3}, {4, 5, 6}};
Ex. Java에서의 상수 선언문
- Java에서는 예약어로 \(\texttt{const}\)를 확보했으나 사용되지 않고, 메모리 속성을 이용하여 상수를 선언한다.
(\(\texttt{static final}\) 키워드는 "끝까지 사라지지 않는"의 의미를 갖는 전역 변수 선언 키워드이다.)
- 인터페이스에서는 사용되는 모든 식별자가 상수를 의미하므로, 인터페이스 환경에서는 메모리 속성이 생략 가능해진다.
static final float pi = 3.1415926;
Ex. Java에서의 배열 선언
- Java에서 배열은 객체로 취급되어, 생성문에 \(\texttt{new}\) 연산자가 요구된다.
int [] ia = new int [3];
int ib [] = {1, 2, 3}; // new 연산자의 생략이 가능하다.
6.6 표현식 (Expression)
- Expression(표현식)은 하나 이상의 Operand를 이용하여 데이터 값의 계산을 기술한 것이다.
- 표현식은 Operand, Operator, Function Call로 구성된다.
- 식 평가는 Operand의 값을 구하여 지시된 연산을 행하여 수행한다.
- 프로그램에서 사용된 모든 변수들에 결합된 값들이 그 프로그램의 State Space(상태 공간) 또는 Enviornment(환경)을 형성한다고 표현한다.
- Referential Transparency(참조 투명성) : 식의 평가는 값만을 생성하며, 환경을 변경하지 않는 성질을 의미한다.
- 그러나 대부분의 언어에서는 식에 사용된 함수가 변수 값을 변경시키는 식으로 환경을 변경시킬 가능성이 존재한다.
- Ada, Lisp 등 몇몇 언어의 초기 설계에서 참조 투명성을 유지하려 Side-Effect(부수 효과, 환경(값)을 변경시키는 효과)를 금지하려 했으나, 결국 함수에서 부수 효과가 허용되었다.
- 식에서 Operand와 Operator들이 결합되는 순서를 연산자들 간 우선순위를 부여하여 정의했다.
- 연산자 간 우선순위는 묵시적으로 존재하며, 괄호는 연산자 우선순위를 명시적으로 변환하는데 이용된다.
- 일반적으로, 동일한 우선순위를 같은 연산자들의 경우, 왼쪽부터 처리하는 Left-Associative(좌-결합) 법칙을 따른다.
- APL 등의 소수의 언어는 Right-Associative(우-결합) 법칙을 따른다.
ex) Fortran, PL/I, Algol 60, Pascal, Ada에서의 연산자 간 우선순위
| Fortran | PL/I | Algol 60 | Pascal | Ada | |
| High Priority | ** (제곱) | Unary +. Unary -, **, ┓ |
↑ (제곱) | not | ** (제곱) |
| *, / | *, / | ×, /, ÷ | *, /, div, mod, and | ×, /, mod, rem | |
| +, - | +, - | +, - | +, -, or | +, -, not(Unary) | |
| .EQ., .NE., .LT., .LE., .GT., .GE. |
|| | <, ≤, =, ≥, >, ≠ | =, <, >, <=, >=, <>, in | +, -, & | |
| .NOT. | =, <=, >=, >, < | ┓ | =, /=, <, <=, >, >= | ||
| .AND. | ┓=, ┓<, ┓> | ∧ | and, or, xor | ||
| .OR. | ∨ | ||||
| ⊃ | |||||
| Low Priority | ≡ |
ex) C에서의 연산자 간 우선순위

- Applicative Order(평가 적용 순서) : Operand와 Operator로 구성된 식을 평가하는 순서이다.
- 일반적으로, "Operand1 OP Operand2" 와 같은 식에서는 두 개의 Operand를 평가한 후 결과를 얻기 위해 연산자 OP를 적용하는 방법을 택한다.
- 그러나, 논리 연산자는 다수의 Operand로 구성된 식에서, 모든 Operand를 활용하지 않고도 식을 평가할 수 있는 경우가 존재한다.
ex) "x = 0 or y / x < 1" 에서 x가 0이면, 이 수식의 값은 항상 1이다. 하지만 분모에 0이 오면 Arithmetic Error가 발생하게 된다.
- ICL 1900 Pascal 컴파일러에서는 Boolean Expression에서 일부 평가를 생략할 수 있도록 이러한 Boolean Operator의 특성을 허용했다.
- CDC 6000 Pascal 컴파일러에서는 반대로 이러한 특성을 불허했다.
ex) "x != 0 and y / x < 1"에서 x가 0일 경우, 이 수식의 값은 무조건 0이다. 그럼에도 불구하고 and 연산자 이후의 표현식(y / x < 1)를 계산하면 Arithmetic Error가 발생한다.(0으로 나누는 오류)
- 위와 같은 수식에서, 일부 표현식으로 인해 값이 결정되면 더 이상 수식 평가를 진행하지 않게 하는 Short Circuit(단락 회로) 평가 기법이 존재한다.
- x cand y = if x then y else false
- x cor y = if x then true else y
- C/C++, Java에서는 논리연산자 &&, ||는 단락 회로 평가를 기본적으로 수행하는 연산자이다.
- 즉, Short Circuit은 논리식의 전체가 아닌, 일부만 Evaluation하여 논리식의 정답을 도출해내는 기법이다.
ex) C언어 문장 "(x==y)&&(x++/--y)"는 프로그래머의 의도대로 흘러가지 않을 가능성이 있다. (&& 연산자는 단락 회로 평가를 수행하기 때문이다.)
- Modula-2에서는 AND, OR 연산자가 단락 회로 평가를 기본적으로 수행하는 연산자이다.
- Ada에서는 단락 회로 연산자 and then과 or else를 지원한다. 이들의 우선순위는 and와 or 연산자와 동일하다.
6.7 조건문 (Condition Statements)
- 조건에 따라 실행되는 부분이 달라질 때 사용하는 문장이다.
- 조건문은 Fortran에서 처음으로 도입되었다.
ex) Fortran에서의 조건문은 조건 분기문 형태로 제공된다. (goto문의 단점인 판독성 저하가 일어난다.)
1. \(\texttt{IF(BCOND) L1, L2}\)
- BCOND가 참이면 L1으로 분기, 그렇지 않으면 L2로 분기한다.
- 즉, 논리적으로 goto문과 동일하다.
2. \(\texttt{IF(BCOND) <stmt>}\)
- BCOND가 참이면 <stmt>를 수행한다.
- <stmt>는 단일 문장만을 허용하여, 복수의 문장을 사용하고자 할 경우 goto문과 레이블 사용을 조장하여 판독성을 저해시킨다.
3. IF(ACOND) L1, L2, L3
- ArithmeticCOND의 값이 0 미만이면 L1, 0이면 L2, 0 초과이면 L3로 분기한다.
- 즉, 논리적으로 goto문과 동일하다.
- ANSI Fortran 77에서는 종결부에 ENDIF를 사용하는 if-then-else 구조를 갖추어 Dangling else 문제를 해결한다.
ex) Algol 60에서의 조건문 \(\texttt{if cond then S1 else S2}\) 형태로 조건문을 지원한다.
- S1, S2는 복합문이며, else는 선택절이다.
- Dangling else 문제가 발생할 수 있어 이에 대한 해결책이 요구된다.
* if-then-else 구조는 또한 nested if문을 변형하여 개선할 수도 있다.

- Readability가 떨어지는 Nested-if문을 대신하여 elif 구조가 도입되었다.
ex) Ada에서는 if-then-else 구문을 제공하여 endif를 사용하지 않고. 가독성을 제고한다.
ex) Algol 68에서는 elif(else if)구조를 처음으로 제공하였다.
Case Statement
- 프로그래머가 상호 배제적인 택일의 집합에서 한 개만을 선택하도록 하는 구조이다.
- Algol-W 언어에서 Hoare와 Wirth에 의해 Case문이 채택되었다.
- nested if-then-else문을 모방하여, 더 분명한 계산을 제공한다.
- C/C++, Java에서 Case 구조는 switch문으로 제공된다.
Ex. Algol-W Case Statement
case <integer expression> of
begin
S1; S2; ...; Sn
end- integer expression의 값이 1이면 S1, 2이면 S2 가 실행되는 구조이다.
- integer expression의 값에 해당되는 문장이 없으면 오류가 발생하는 문제가 있다.
Ex. Pascal Case Statement
case <expr> of
<case label list> : <stmt>
...
<case label list> : <stmt>
end- <case label list>에서는 <expr>이 갖는 데이터 형의 상수 형태만을 허용한다.
- <expr>의 데이터 형에는 열거형이 포함되는 등 자유도가 높다.
- <expr>이 <case label list>의 어느 항목과도 일치하지 않으면, 결과가 정의되지 않는다.
- goto문은 case로 분기할 수 없다.
- 각각의 label들은 모두 유일하다.
Ex. Pascal Case Statement 응용 (열거형 <expr>)
type months = {Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec};
var thismonth : months;
case thismonth of
Feb, Apr, Jun, Jul, Aug : birthday := 4;
Sep : birthday := 1;
Jan, Mar, May, Oct, Nov, DEc : birthday := 0;
end;
Ex. Ada Case Statement
<case stmt> ::=case <expression> is
{ when <choice> {|<choice>} ⇒ <sequence of stmts>}
end case;
<choice> ::=<simpleExpression> | <discreteRange> | others- <expression>은 정수형, 열거형일 수 있다.
- 발생할 수 있는 모든 경우를 처리할 수 있는 others절을 이용할 수 있다.
Case Statement 설계 시 고려사항
1. Selector Expression(선택자 식)으로 허용된 데이터 형은 무엇인가?
2. Case 레이블에 허용되는 데이터 형은 무엇인가?
3. Case문 내부/외부로부터 Case 레이블로 분기될 수 있는가?
4. 레이블간의 Mutual Exclusion(상호 배제)를 요구하는가? (레이블들은 서로 달라야 하는가?)
5. 수식으로부터 발생되는 모든 경우들을 처리해야 하는가?
6.8 반복문 (Iterative Stetments)
- 한 개 이상의 문장을 0번 이상 실행시키는 문장이다.
- 반복 수행은 컴퓨터의 중요 특성 중 하나로, 초기 PL에서부터 응용되어져 왔다.
- 함수형 언어에서는 반복문을 제공하지 않아, Recursion을 통해 반복 구조를 구현한다.
반복문의 차이
1. 반복의 제어 방법
2. 반복문 내에서 구체적인 제어가 수행되는 위치
3. 반복 방법 (사용자 지정 반복, 논리 제어 반복, 제어 변수 반복)
사용자 지정 반복 (loop-repeat, goto, exit, break, continue)
- 제한적 형태의 goto문인 exit문을 통해 반복 수행을 끝낸다.
* loop-repeat문
loop
if not <condition> then exit
<statement>
repeat- Loop 탈출 방법으로 조건/무조건 분기문을 이용한다. (exit: 제한적 goto문 응용)
- goto문, 레이블을 제거한 Bliss 언어에서는 7가지의 exit문을 제공한다. (exitblock, exitcase, exitcommand, exitselect, exitloop, exitset, exit)
- Bliss 이후의 버전들(Bliss-II, Bliss-360, CommonBliss(VAX: DEC-10, DEC-20))에서는 exit <label> 구조만 제공하여, 복잡성을 제거했다. (여기서, <label>은 Scope의 이름이다.)
- C/C++에서는 exit대신, break문을 통해 반복문을 탈출하며, continue문을 통해 작은 반복구간을 가질 수 있다.
(continue: 반복문에서 continue구문의 아랫 부분을 생략한채로, 다음 Iteration으로 진행하게 한다.)
- Java에서의 break에는 C/C++의 break 개념에 break <label> 구조를 추가하여, 반복 영역뿐 아니라, 다양한 영역을 탈출하는데 이용할 수 있다.
논리 제어 반복문 (while, repeat-until, do-while)
- 조건이 참이면 반복을 계속하고, 거짓이면 반복을 멈추는 반복문 구조이다.
- 국제 표준 규격에서, 논리 제어 반복문은 while문으로써 제공되게 하였다.
* while문
while (<condition>)
<statement>
* repeat-until문
repeat
<statement>
until <bcond>
- 조건 검사가 반복 영역의 시작 부분이 아닌, 끝 부분에 행해지는 구조를 until문이라 한다.
- bcond가 false이면(true일 때 까지) <statement>를 수행한다. (do-while문과 반대 구조)
- until문에서는 Loop Body가 적어도 한 번은 수행된다.
* do-while문
do
<statement>
while (<condition>)- <condition>이 true이면 <statement>를 수행한다. (repeat-until문과 반대 구조)
- C/C++, Java에서는 until문으로써 do-while문을 제공한다.
반복 제어 변수 반복문 (for, do)
- 반복 변수, 제어 변수를 사용하여 고정된 횟수의 반복을 표현하는 반복문 구조이다. (for문)
* Algol 60에서의 for-Structure
for <var> := <init> step <incr> until <final>
do <statement>- 반복 변수와 최종값을 먼저 비교한다.
- 초기값<init>, 증분값<incr>, 최종값<final>(임의의 수식)으로 구성된다.
- 데이터형으로 실수형, 정수형, 혼합형 연산을 허용한다.
- 최종값, 증분값을 비교시 매번 재평가된다.
ex) Algol 60 for문 응용 예시
a step b until c
v := a
L1 : if (v - c) * sign(b) > 0 then goto exit;
<statements>
v := v + b
goto L1;
exit;- 반복문 정상 종료 시, 반복 변수 값은 더 이상 정의되지 않는다.
- 반복문을 goto문으로 탈출 시, 반복 변수값이 유지된다.
- 외부에서 for문 내부로 제어를 이동할 경우에 대한 결과는 미정의 상태이다.
for문 설계 시, 고려사항
1. 반복변수 <var>이 택할 수 있는 값들의 데이터 형은 무엇인가?
2. 식 초기값<init>, 최종값<final>, 증가값<incr>에 어느 정도 복잡한 식이 허용되며, 연산 결과는 어떤 데이터 형이 되어야 하는가?
3. 반복 실행이 진행될 때 최종값과 증가값은 얼마나 자주 평가되는가?
4. 반복변수가 최종값과 비교되는 때는 언제인가?
5. 반복문 안에서 배정문을 반복변수가 변경될 수 있는가?
6. 반복문의 수행이 끝난 후 반복변수가 가지는 값은?
7. 반복문 안팎으로 제어가 이동되는 것이 허용되는가?
8. 반복변수의 Scope는 어디인가?
ex) N.Wirth가 채택한 Pascal에서 for문의 두 가지 형태
for <var> := <init> to <final> do <stmt>
for <var> := <init> downto <final> do <stmt>- to, downto 구조 모두 한 칸씩 오르고 내려오는 구조이다.
- 변수의 초기값, 최종값을 동일한해야 하며, 스칼라 형을 허용하며, 실수형은 제외된다.
- 초기값, 최종값은 Loop 시작 전, 한 번만 계산된다.
- 변수와 최종값 먼저 비교한다.
- 종료 후 반복 변수의 값은 미정의한다.
- 반복문 변수로 열거형 사용이 가능하다.
- 증분값: to, downto
ex) Pascal에서는 반복문에 열거형을 연결시킬 수 있다.
for i := january to december do <stmt>
ex) Fortran II의 DO문 (최초의 반복문)
- 적어도 한 번은 수행된다.
- 초기값, 증분값, 최종값은 정수형 상수나 변수가 위치할 수 있다.
- 반복문 수행 후 반복 변수의 값에 대한 언급이 일절 없다.
ex) Algol 68의 for문, while문
[for <vble>][from <Exp1>][by <Exp2>][to <Exp3>]
[while <Exp4>] do <S> od- by는 증분값 단위를 의미한다.
- Exp1, Exp2, Exp3에서 정수 수식은 한 번만 평가된다.
(Algol 60에서는 임의의 수식을 매번 평가한다.)
- 반복 변수의 Scope는 Loop Body이다. (Ada가 이를 계승했다.)
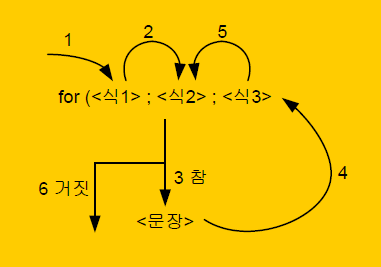
ex) C, Java의 for문
for (<Exp1> ; <Expr2> ; <Expr3>)
<Statement>- <Exp1> : 반복 변수의 초기화 식
- <Exp2> : 조건식
- <Exp3> : 제어 변수의 값을 수정하는 식 (증분값 지정)
ex) C, Java의 for문 실행 순서
6.9 goto문
- Label을 사용하여 프로그램의 어느 한 지점에서 레이블로 제어를 보내어 실행 순서를 바꾸는 문장이다.
(goto문은 모든 레이블 제어 문장을 지칭하는 개념이다.)
- 이러한 직접적인 순서 제어 기법은 기계어의 특성을 그대로 표현한 형태로써 사용하기에 편리하고, 프로그램의 효율적 실행을 보장한다.
- APL, 어셈블리어에서는 명시적 순서 제어 구조로 goto-레이블 구조만을 제공한다.
- Pascal에서는 goto-레이블 구조를 사용하기에 많은 제약이 존재한다.
- Fortran, Basic, Cobol에서는 goto문을 사실상 사용할 수 없다.
- C를 계승한 Java에서는 goto가 예약어로 지정되어 있으나, 사용할 수는 없다.
- 순수 Lisp와 Bliss(시스템 PL)에서는 goto-레이블 구조를 사용할 수 없다.
- goto문을 제거함으로써 다양한 순서 제어문이 요구되었다. (택일문, 반복문, 재귀 등)
레이블과 goto문의 기본 사용법
1. 레이블을 위치를 지칭하는 Tag로만 사용하는 방법
- 레이블을 번역하는 동안에 기계어 코드에서 분기할 위치를 알리기 위한 수단으로서만 활용하는 방법이다.
2. 레이블을 제한된 자료 항목으로 간주하는 방법
- 실행 시간 동안 레이블을 읽고 계산하지는 않지만, 레이블 변수, 레이블 배열, 비지역 레이블 참조, 서브프로그램에서 레이블 매개변수 사용등을 허용하는 방법이다.
- Algol 계열 언어는 이러한 중간 단계 레이블을 사용하는 전형적인 언어들이다.
- Algol 프로그램을 실행하는 동안, 레이블-goto 구조의 부분적 S/W 시뮬레이션을 필연적으로 요구하게 된다.
3. 레이블을 실행 시간 동안 제한이 없는 자료 항목으로 간주하는 방법
- 가장 일반적인 goto-레이블 구조 접근 방법으로, 실행 시간에 필요한 경우 레이블을 읽거나 계산할 수 있도록 허용하는 방법이다.
- Snobol4, APL에서 채택되었다.
goto문의 장단점
- 일반적인 컴퓨터에서 goto문과 레이블 제어 구조가 곧바로 H/W에 제공된다. (구조가 간결한 기본 연산이기 때문이다.)
- goto-레이블 구조는 완전한 범용성을 띄고 있다. (이론적으로, goto-레이블 구조만으로 모든 알고리즘을 표현할 수 있다.)
- 과한 goto문의 사용(비구조적 설계)은 디버깅, 가독성 저하, 유지 보수를 어렵게 한다.
- Fortran에서 산술 if 문은 논리 if문보다 더 많은 goto문 개념을 사용하기 때문에 논리 if문을 사용하는 것이 바람직하다.