
Pipeline MIPS #3
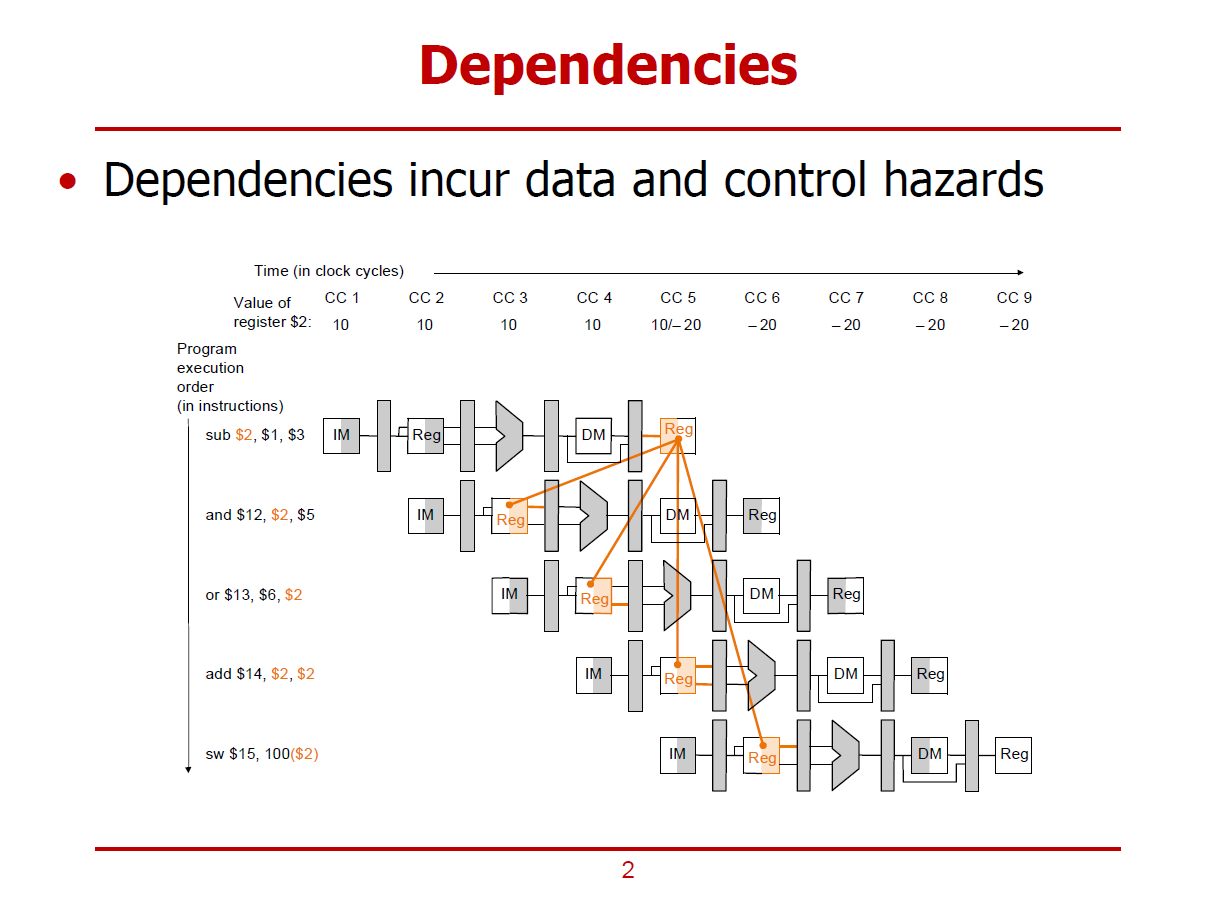
- 명령어와 명령어 사이에 Dependency(의존성)가 존재할 경우에 관한 설명이다.
- 그림의 맨 윗쪽에는 시간축이 표시되어 있다. 각 Cycle마다 $s2 레지스터의 상태를 표시하고 있다. (CC : Clock Cycle)
- Dependency는 Data 해저드와 Control 해저드를 초래한다.
- 첫 번째 sub 명령어에서는 $s2 레지스터가 WB Stage에서 사용하고자 하며, 나머지 명령어들에서는 ID Stage에서 사용하고자한다.
- 즉, 첫 번째 sub 명령어와 나머지 명령어들은 $s2 레지스터에 대한 의존성이 있다.
- 보통, Flip-Flops에서는 한 사이클에 하나의 값만을 저장하고 있으나, 본 포스트에서는 구현을 달리하여 레지스터 파일이 한 사이클에 두 개의 값을 가질 수 있도록 한다. (Implementation Specific한 영역이다.)
- 즉, CC 5 에서는 사이클 초반부에는 $2레지스터에 10을, 사이클 후반부에는 -20를 저장한다고 가정한다.
(sub 명령어를 통해, $1 레지스터와 $3 레지스터의 뺄셈 연산 결과가 -20이 나왔다고 가정한다.)
- CC 5 후반부부터는 $2 레지스터에 쓰기 연산을 수행하는 Stage가 없으므로, 값 -20이 유지된다.
- 두 번째 명령어(and)부터 마지막 명령어(sw)까지는 $2 레지스터에 값 -20을 기대하는 상황이다. (이들 명령어 입장에서는 sub 명령어에 의해 $2 레지스터의 값이 수정된 결과를 받아야 한다.)
- 그러나, 두 번째 명령어(and)와 세 번째 명령어(or)는 sub 명령어가 결과값(-20)을 쓰기 이전에 $2 레지스터의 값을 요구하고 있으므로, Data 해저드의 위험이 있다. ($s2의 값으로 결과값(-20)을 기대하고 있었으나, 10이 저장되어 있는 상태이다.)
- 네 번째 명령어(add)는 가정한 내용대로, sub 명령어의 WB Stage에서 결과값을 바로 넘겨받아 Data 해저드를 회피한다고 가정한다.

- Data 해저드에 대한 S/W적인 해결방법이다.
- 가장 직관적인 방법으로, 컴파일러에 의한 nop 명령어 삽입하는 방식이다.
- nop 명령어는 실제로 확정되어 있지는 않으나, 본 포스트에서는 0x0000 0000에 해당된다 가정한다.
- 이는, $0 레지스터를 0번 Shift하여 $0에 저장할 것을 명령하는 의미없는 sll 명령어이다. (논리적 nop 명령어)
- sub 명령어와 and 명령어 사이에 2개의 nop 명령어를 삽입하여, Data 해저드 위험이 있는 and 명령어와 or 명령어의 ID Stage가 sub 명령어의 WB Stage 이후에 위치하도록 기능적으로 미루는 방식이다.
- nop 명령어 삽입은 기능적으로 문제가 없으나, 성능의 저하를 불러온다.
- nop 삽입법보다는, Code-Rescheduling 방법이 성능의 저하를 줄일 수 있다.
- 필요한 값이 실질적으로 확정되는 Stage에서 바로 넘겨주는 Forwarding 방법을 통해 Data 해저드를 피할 수도 있다.

- 의존성이 있는 명령어들이 필요한 값이 확정되는 대로 바로 넘겨받게 H/W적으로 Data 해저드를 회피하는 방법을 Forwarding이라고 한다.
- sub 명령어에서 $2 레지스터의 결과값(-20)이 실질적으로 확정되는 EX Stage이후의 파이프라인 레지스터에서 명령어들에게 바로 값을 넘겨주는 방식이다.
- nop 명령어 사용을 지양하고, Forwarding을 위한 H/W Logic을 추가적으로 설계해야 함을 감안하고, 파이프라이닝 Throughput을 최대한으로 끌어내는 방법이다.
1. and 명령어에서 수행되는 Forwarding
- and 명령어는 EX의 시작 단계에서 MUX를 통해 sub 명령어의 EX/MEM 파이프라인 레지스터의 값(-20) 혹은 and 명령어의 ID/EX 파이프라인 레지스터의 값(10) 중 하나를 입력받는다.
(그림에서 MUX는 주황색 선들의 접점이라 볼 수 있다.)
- 여기서는, -20 값을 전달받아야 하므로, MUX는 sub 명령어의 EX/MEM 파이프라인 레지스터에 저장된 값을 선택할 것이다.
2. or 명령어에서 수행되는 Forwarding
- or 명령어 또한, EX의 시작 단계에서 MUX를 통해 MEM/WB 파이프라인 레지스터의 값(-20) 혹은 or 명령어의 ID/EX 파이프라인 레지스터의 값(10) 중 하나를 입력받는다.
- 여기서는, -20 값을 전달받아야 하므로, MUX는 sub 명령어의 MEM/WB 파이프라인 레지스터에 저장된 값을 선택할 것이다.
3. add 명령어에서 수행되는 Forwarding
- 엄밀히 설명하면, add 명령어에서도 Forwarding이 이루어졌다고 할 수 있으나, 본 포스트에서는 특수한 H/W 설계를 통해 sub 명령어의 WB Stage의 전반부에서 값을 add 명령어의 ID Stage의 후반부에 넘겨받았다고 가정한다.
※ 마지막 sw 명령어는 Data 해저드의 위험이 없으므로, 별다른 특이사항을 갖지 않는다.

- 의존성이 있는 두 명령어 사이에서 위 조건 중 하나라도 만족되면 Data 해저드의 발생 위험을 의심해야 한다.
- 4페이지 그림에서 sub 명령어와 and 명령어는 1a 조건이 만족된다. (실제로 Data 해저드 위험이 있다.)
- 4페이지 그림에서 sub 명령어와 or 명령어는 2b 조건이 만족된다. (실제로 Data 해저드 위험이 있다.)
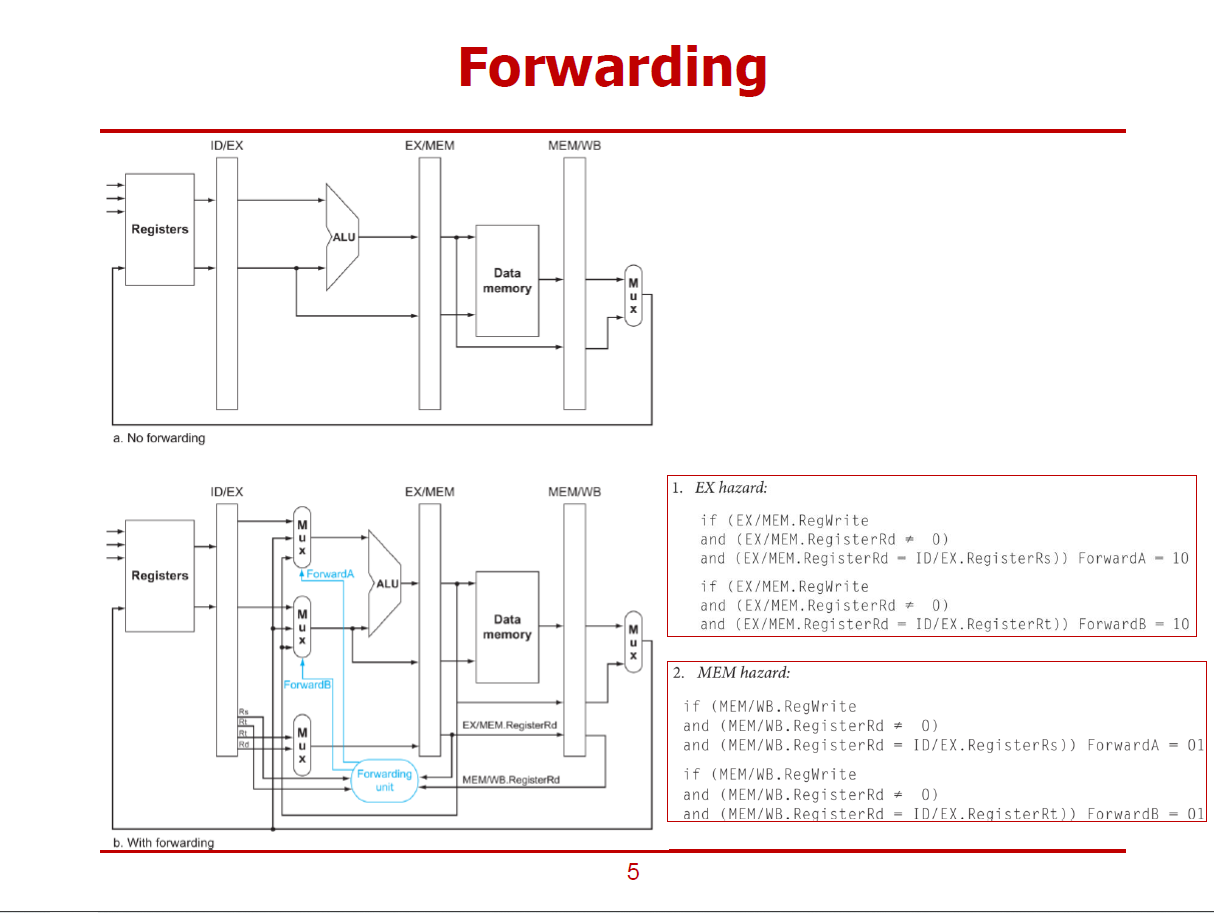
- a는 Forwarding이 수행되지 않는 H/W 구조, b는 Forwarding을 위한 H/W Logic 구조이다.
- 여기서 Forwarding Unit의 역할은 ForwardA, ForwardB 신호선을 적절히 Select하여,
레지스터 파일, EX/MEM 파이프라인 레지스터, MEM/WB 파이프라인 레지스터 중 어느 곳에서 값을 가져올지를 결정한다.
- 해저드로 판정되지 않으면, ForwardA와 ForwardB는 모두 00으로 초기화 된다.
EX 해저드
- 바로 인접한 두 명령어 사이에 Data 해저드가 있는 경우이다.
- EX 해저드로 판정할 수 있는 세 가지 조건은 아래와 같다. (세 조건이 모두 만족되면 EX 해저드이다.)
1. RegWrite 신호값이 1
2. EX/MEM 파이프라인 레지스터가 zero 레지스터가 아님
3. EX/MEM 파이프라인 레지스터에 위치한 Rd 값 == ID/EX 파이프라인 레지스터의 두 값(Rs, Rt) 중 하나 (즉, 적절한 값을 넘겨받지 않는 상황이면)
- EX 해저드로 판정되면, EX/MEM으로 부터 값을 넘겨받도록, Forwarding Unit이 10(MUX의 세 번째 입력값)을 생성한다.
MEM 해저드
- 사이에 하나의 명령어를 둔 두 명령어 사이에 Data 해저드가 있는 경우이다.
- MEM 해저드로 판정할 수 있는 세 가지 조건은 아래와 같다. (모든 조건이 모두 만족되면 MEM 해저드이다.)
1. RegWrite 신호값이 1
2. MEM/WB 파이프라인 레지스터가 zero 레지스터가 아님
3. MEM/WB 파이프라인 레지스터에 위치한 Rd 값 == I01D/EX 파이프라인 레지스터의 두 값(Rs, Rt) 중 하나 (즉, 적절한 값을 넘겨받지 않는 상황이면)
- MEM 해저드로 판정되면, MEM/WB으로부터 값을 넘겨받도록, Forwarding Unit이 01(MUX의 두 번째 입력값)을 생성한다.
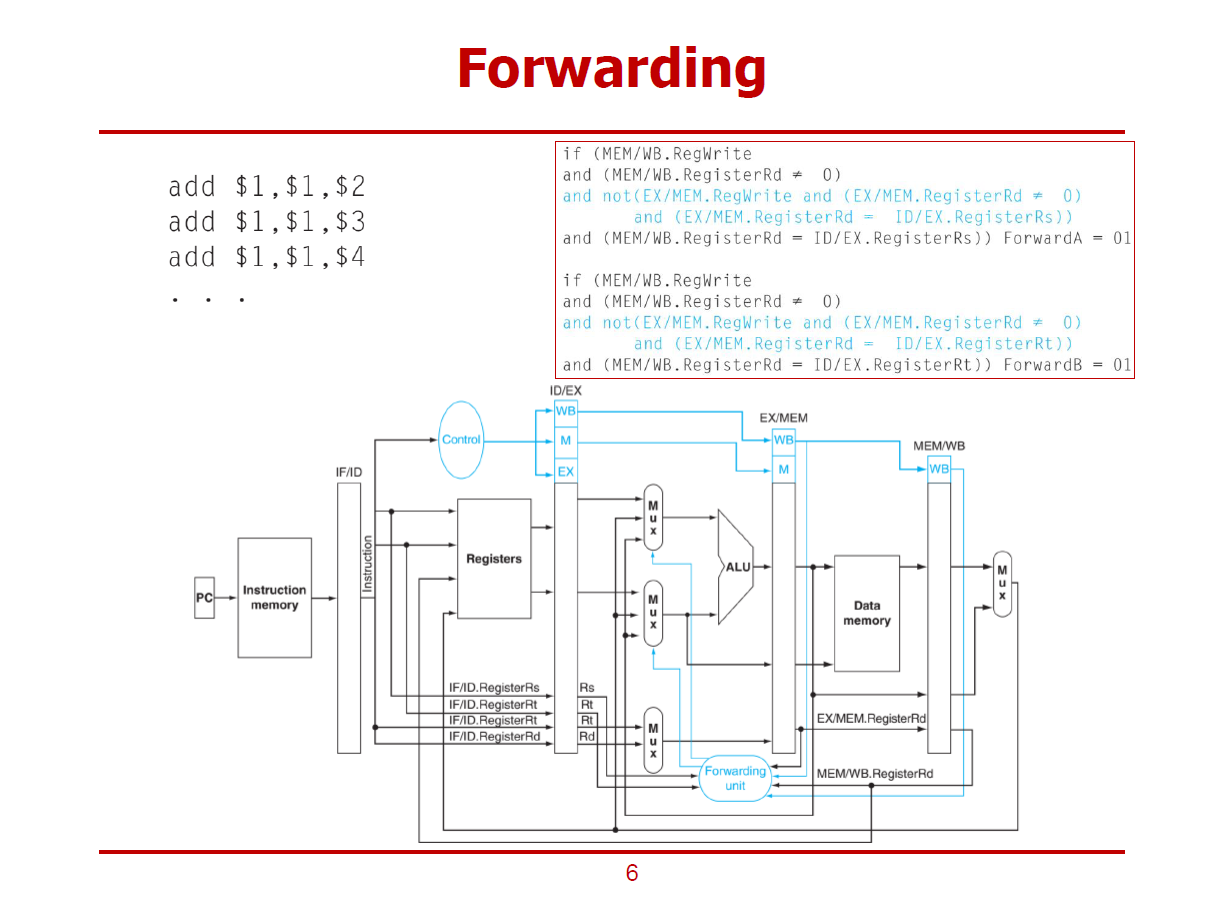
- 3번째 명령어 입장에서는 2번째 명령어의 결과를 활용해야 한다. (가장 최근의 결과를 반영해야 한다. 즉, EX 해저드로 판정해야 한다.)
- 이러한 상황에서, 만약 MEM 해저드를 판별하고자 한다면,
첫 번째 명령어와의 의존성(MEM 해저드)은 존재하면서,
두 번째 명령어와의 의존성(EX 해저드)는 존재하지 않음을 확신할 때, MEM 해저드로 판별할 수 있다.
- 위 그림의 오른쪽 코드는 MEM 해저드를 판별하는 코드이다.
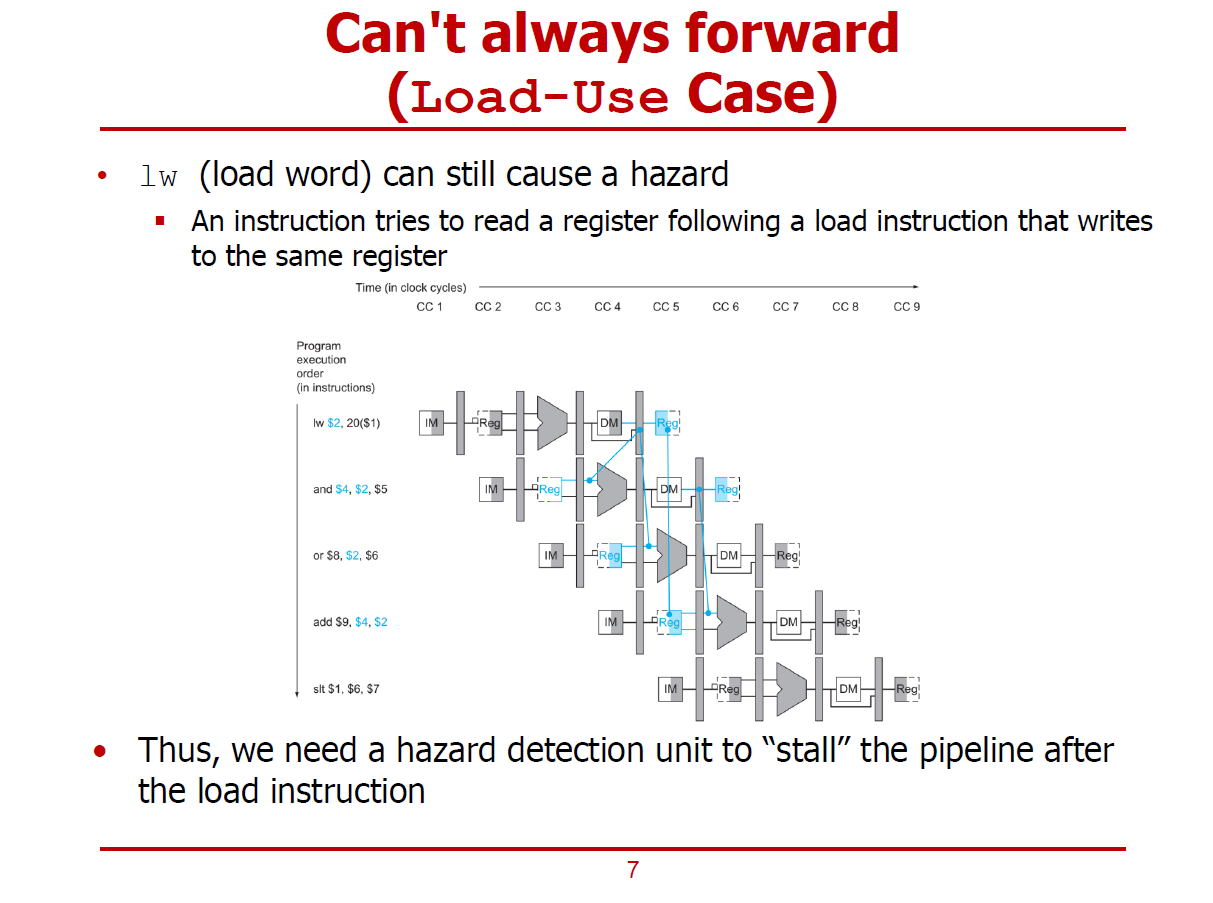
- Forwarding Unit을 통해서도 Stall을 방지할 수 없는 경우가 Load-Use Case이다.
- Load-Use Case는 lw 명령어 이후에 load한 결과물을 이용해야 하는 경우가 이에 해당된다.
- 2번째 명령어(and)의 경우에는 EX 단계(CC4 시작)에서 1번째 명령어(lw)의 WB 단계(CC5 시작)에서의 결과를 받아야 하므로, 한 Cycle 만큼의 Stall은 피할 수 없다.
- Stall이 불가피한 상황을 감지하여, Stall을 수행하기 위해 Hazard Detection Unit이 필요하게 된다.
- Hazard Detection Unit이 상황을 감지하면, lw 명령어 이후에 Bubble(Stall)을 생성하게 된다.
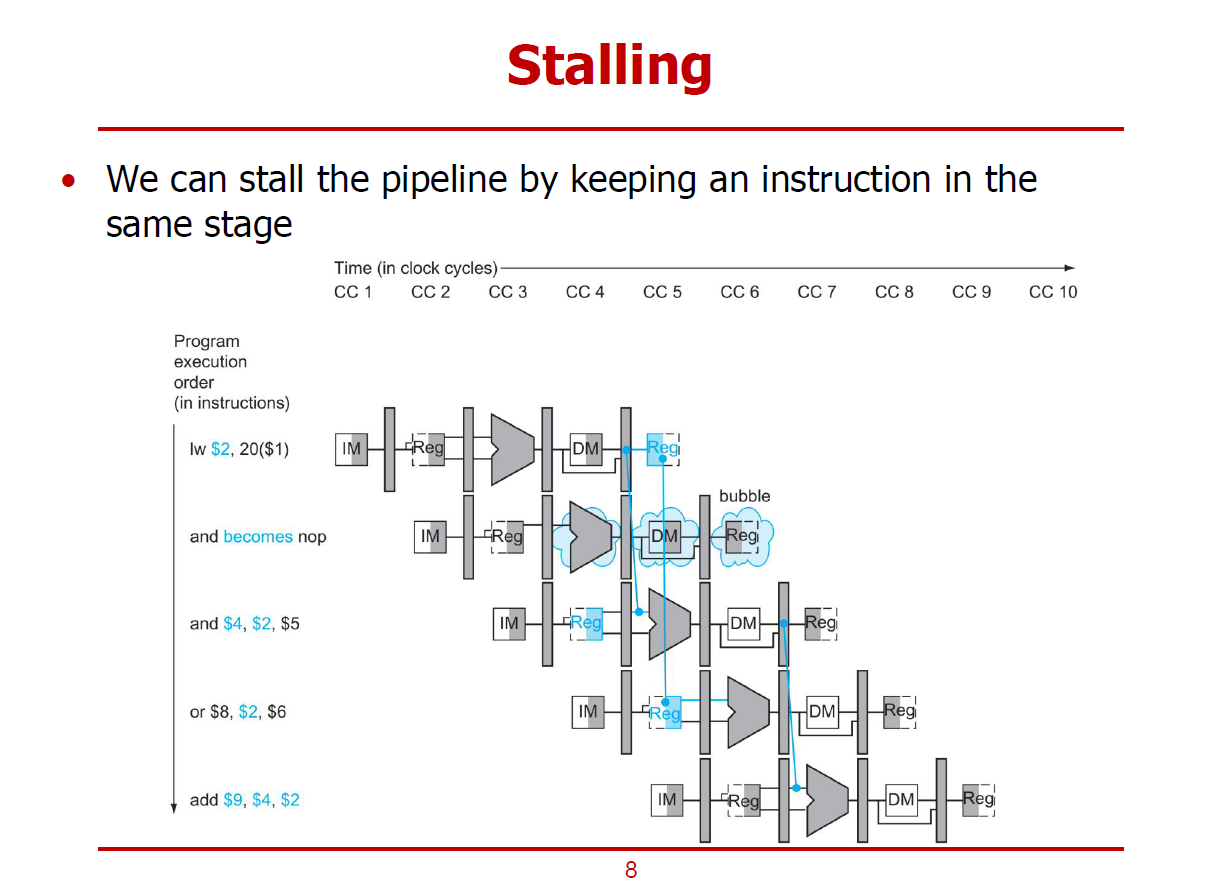
- Hazard Detection Unit이 감지에 성공하면, and 명령어의 ID Stage 이후에 하나의 Bubble이 삽입된다.
(그림에 마지막 명령어 slt가 밀려나 없어졌음에 유의하자.)
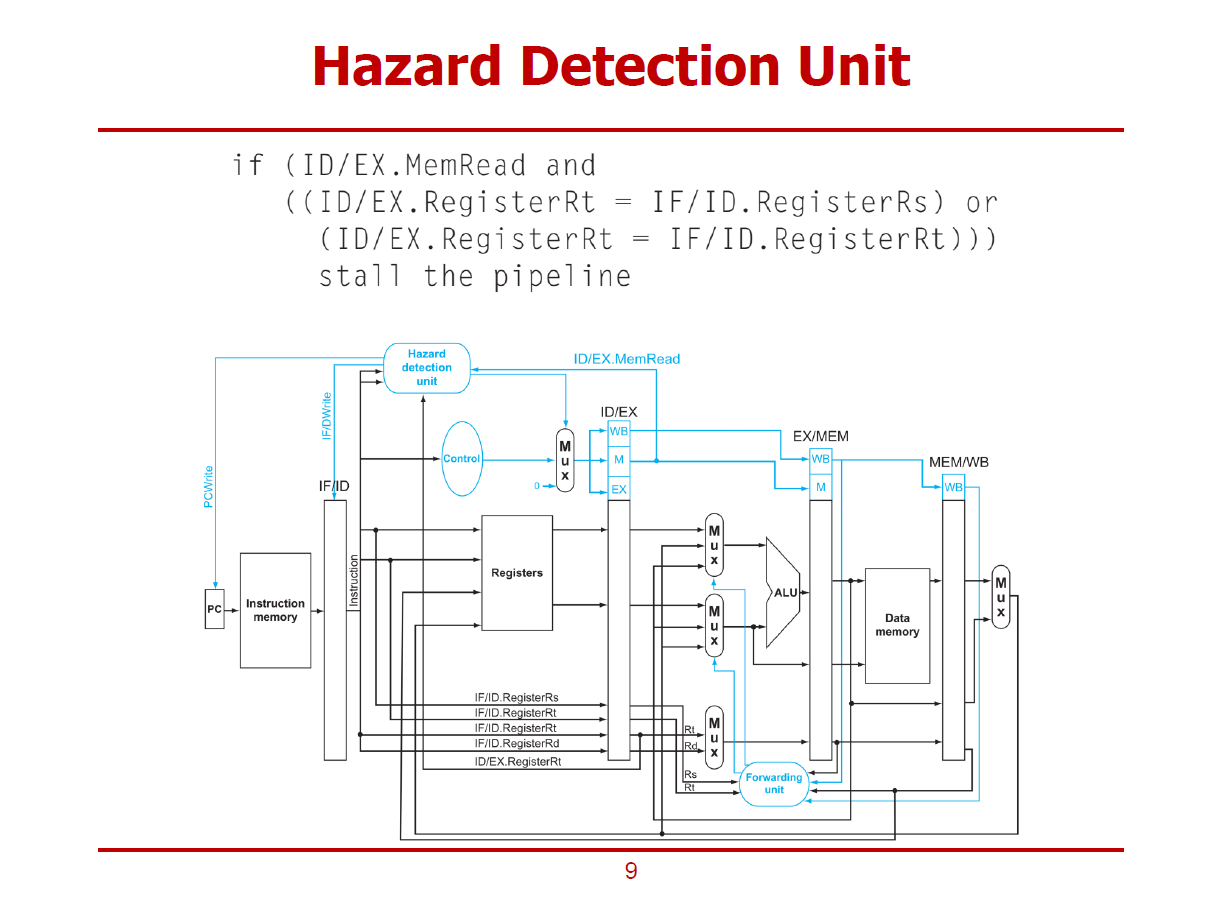
- 해저드를 감지하는 방법에 관하여 설명한다.
- 해저드를 Detection하고 파이프라인을 Stall하는 것은 nop 명령어 삽입을 구현하는 것과 비슷하다.
- Hazard Detection Unit은 ID Stage에 위치하여 IF/ID의 Source 레지스터와 ID/EX Stage의 Source 레지스터가 같은 지를 판정한다. (판정은 Decoding 결과 Load 명령어로 판정이되면 수행된다.)
- 메모리를 읽는 연산을 수행할 때, 해저드가 발생할 수 있으므로, ID/EX에서 메모리 읽기 연산을 수행하는 명령어인지를 판별한다.
- 메모리를 읽는 연산으로 판정되면, Rt 레지스터에 해당되는 부분이 다음 명령어의 Source 레지스터와 동일한지를 확인한다. (즉, 로드한 데이터를 다음 명령어에서 바로 활용 되는지를 판별하는 것이다.)
- 동일하다 판정되면 파이프라인을 Stall 시킨다.
- Hazard Detection Unit은 PC와 IF/ID 파이프라인 레지스터에 연결된 Control 신호(PCWrite, IF/IDWrite)를 이용하여 PC 값 업데이트를 막거나 IF 단계를 막아서 Stall시킨다.
- Control Unit(하늘색 타원)에서는 명령어에 따른 9가지의 Control Signal을 생성하여 IF/ID 파이프라인 레지스터를 제외한 파이프라인 레지스터에 보낸다.
Hazard Detection Unit에 입력되는 값
ID/EX.MemRead : ID/EX 파이프라인 레지스터에서 출력되는 값이다.
IF/ID Output : IF/ID 파이프라인 레지스터에서 출력되는 값이다.
Hazard Detection Unit에서 출력되는 값
1.Hazard Detection Unit 왼편에 위치한 신호 : 한 사이클을 중지할 수 있게 한다.
PCWrite : PC값 업데이트를 중지(Stall)시킬 수 있다.
IF/IDWrite : IF/ID 파이프라인 레지스터에 쓰기를 중지시킬 수 있다.
2. Hazard Detection Unit 오른편에 위치한 신호 : nop 명령어가 삽입된 것과 같은 효과를 낸다.
MUX Selection : 파이프라인을 Stall할 것으로 결정되면, MUX의 0값이 선택되어,
9가지 모든 Control 신호가 0으로 설정되어 각각의 파이프라인 레지스터에 전달된다.
(마치 nop 명령어가 삽입된 것과 비슷한 효과를 낸다.)
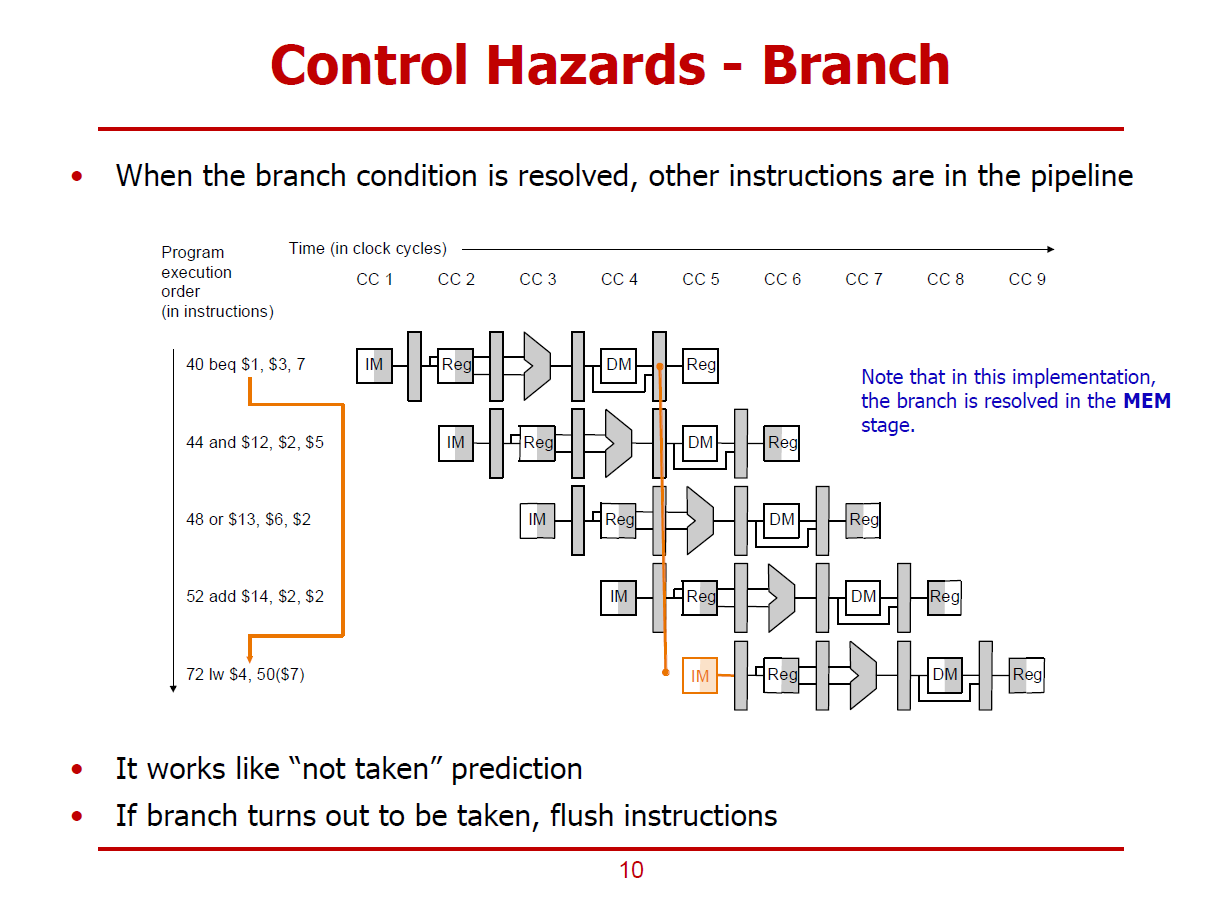
- "Not Taken"Prediction Rule을 적용한다. (beq명령어에서는 분기가 일어나지 않는다 가정하는 것)
- 즉, beq 명령어로 해석되면, 분기 조건 결과에 상관없이 44, 48, 52에 위치한 명령어들도 일단 프로세서가 정상적으로 처리하는 것이다.
- Branch 여부는 MEM Stage에서 정해진다. (두 Operand의 차이값이 EX Stage가 수행된 이후에 결정되기 때문이다.)
- 만약, Branch 조건이 True로 판정된 경우, 실행중이던 44, 48, 52의 명령어들을 Flush해야 한다.
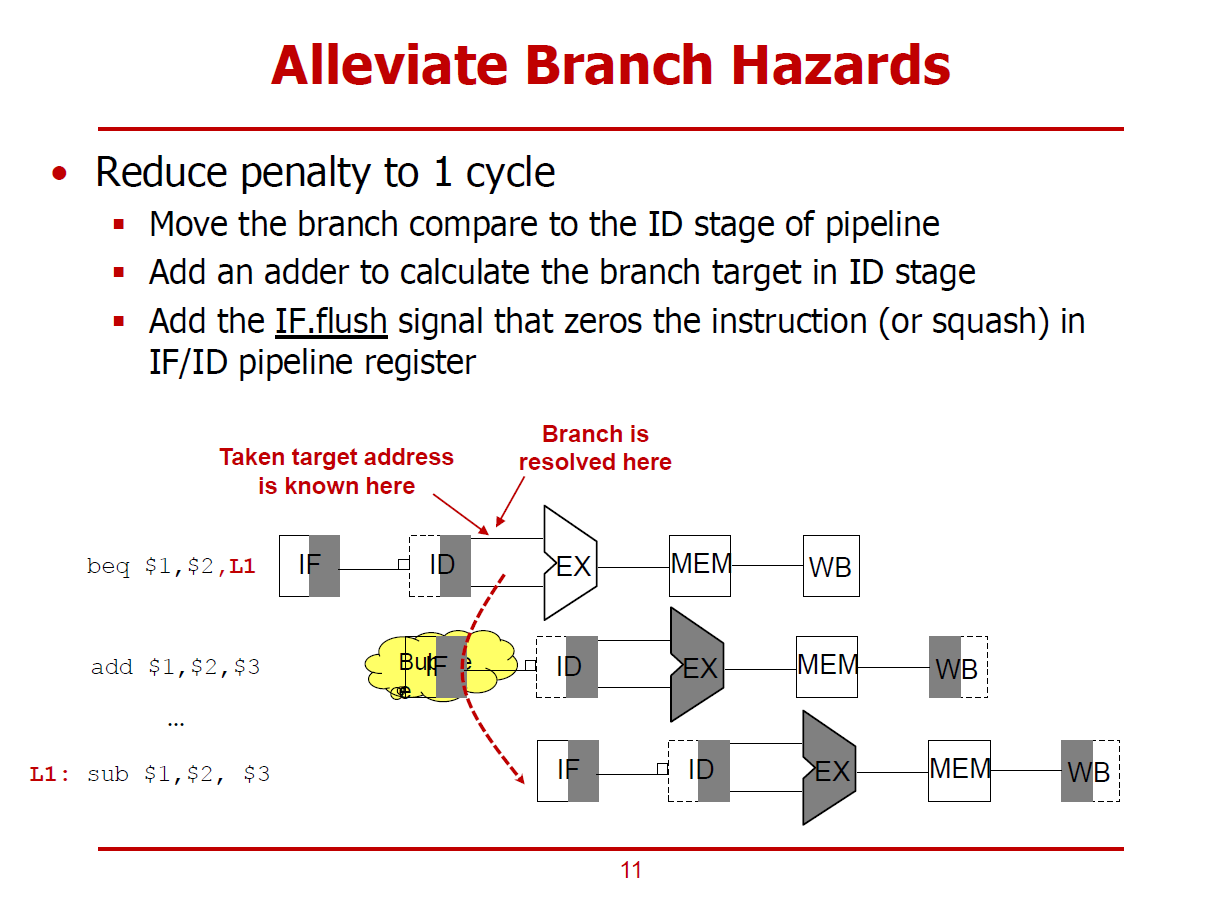
- 일반적인 경우, Branch 조건이 판정되는 시기는 MEM Stage이다.
- MEM Stage까지 대기한 후, 이후의 명령어들을 Flush하게 된다면 성능 면에서의 손해가 크다. (3개의 명령어가 Flush되기 때문이다.)
- 이러한 Panelty를 최소화하기 위한 부가적인 Logic(Branch Compare Logic)이 필요하다.
- Branch Compare Logic은 Branch 명령어의 피연산자들을 ID Stage에서 비교할 수 있게 한다.
(여기서, 비교 연산은 두 값의 일치 여부만 계산하는 것을 의미하며, 뺄셈 연산까지 포함하지는 않는다.)
(단순히 값의 일치 여부를 계산하는 Logic은 덧셈/뺄셈 Logic보다 간단하다.)
- Compare 연산은 n Bit by n Bit 방식의 XOR 연산으로 수행되며, 그 n개의 결과들을 모두 OR연산한 결과(1bit)가 0일 경우에는 두 값이 같다 판정하며, 그 이외의 값이 나올 경우에는 두 값이 같지 않다고 판정하게 된다.
(즉, XOR 연산 결과가 0이면 두 값이 같은 것으로, 0이 아니면 두 값이 다른 것으로 판정한다.)
- 또한, Branch Predictor는 명령어를 Flush하는 Logic도 구현되어 있어야 한다.
- IF.flush Control 신호가 입력되면, IF/ID 파이프라인 레지스터에 있는 값을 모두 0으로 만든다.
- ID Stage가 수행되면 분기 주소와 분기 여부를 확정지을 수 있게하는 Logic이 구현되었고, Prediction Policy(본 포스트에서는 "Not Taken" Policy)에 의거하여 명령어들을 처리한다고 가정한다.
- 만약 beq 명령어의 ID Stage가 완료된 후, 분기를 해야된다고 판정되면, add 명령어를 Flush해야 한다. (Stall이 아님)

- "Not Taken" Policy를 따르는 Branch Predictor에서 beq 명령어의 Branch 조건이 True로 판정되어 예측과 달리, 분기를 해야한다면, 기존에 처리되던 and 명령어를 Flush해야 한다.
(이러한 결론은 ID Stage 이후에 분기 여부와 분기 주소를 계산할 수 있는 Logic이 추가적으로 구현되었다는 가정 하에 이루어진다.)
- beq 명령어의 레이블 값이 7이다. 그러므로 분기할 주소는 7*4 + (PC + 4) = 28 + 44 = 72가 된다.
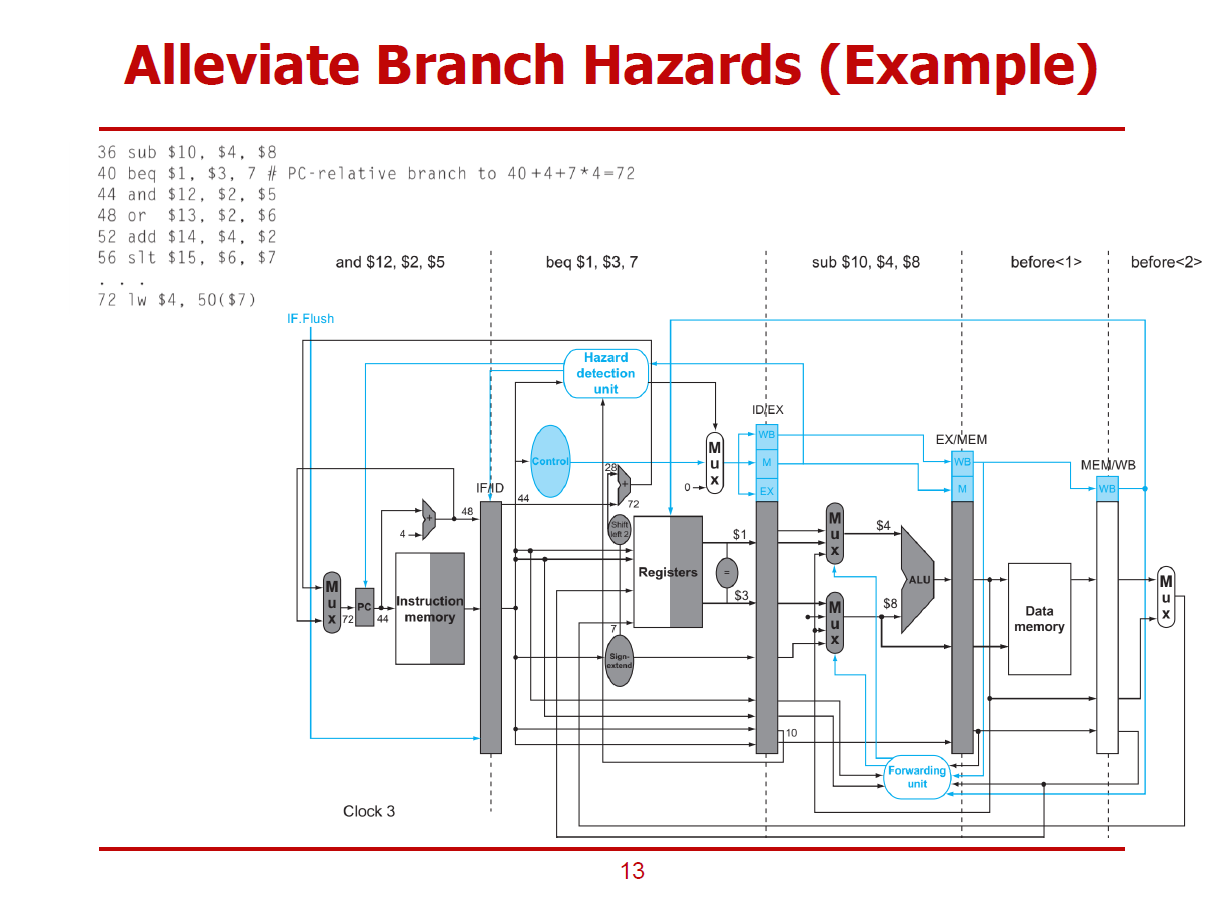
- Control 해저드(Branch 해저드)로 인한 성능 저하를 Alleviate(완화하다)하는 예시이다.
- ID Stage에서의 연산을 마친 beq 명령어는 분기 여부와 분기 주소가 모두 확정된다.
- Control 유닛 오른쪽에 작은 Adder에서는 분기 주소가 계산된다. (Base + Offset)
- Register 파일 오른쪽에 Equal 기호가 있는 작은 타원에서는 분기 명령어의 피연산자들이 같은 값인지를 판별하는 bit by bit XOR연산과 OR 연산이 수행된다.
- 같은 시각에, IF Stage에서는 PC 값이 이미 44로 업데이트 되어 Instruction Memory에 넘겨주고 있다. (즉, and 명령어가 IF Stage에서 처리되고 있다.)
- 같은 시각에 ID Stage에서는 분기를 해야한 것으로 판정되어 PC에 분기 주소 72를 전달한다.
- ID Stage가 처리된 and 명령어를 Flush하기 위해 IF.Flush 신호를 활성화한다.
- IF.Flush 신호에 의해 IF/ID 파이프라인 레지스터에 입력된 값(and 명령어 처리 결과)이 모두 0으로 초기화된다.
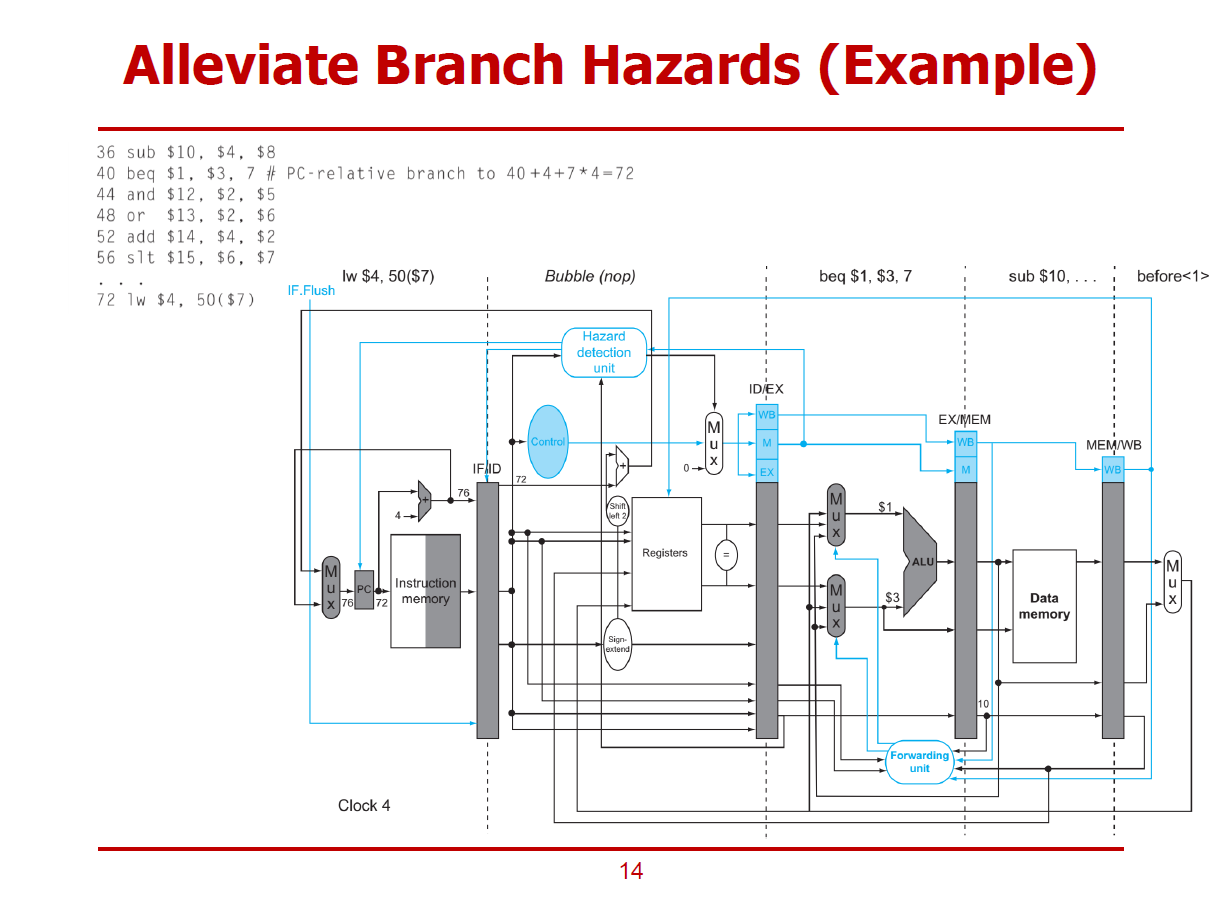
- and 명령어가 Flush된 후, 분기 주소에 위치한 lw 명령어가 정상적으로 실행되는 그림이다.

- 어떤 프로그램이 1,000억개의 명령어로 구성되었다할 때, 이 프로그램의 Execution Time(실행 시간)은 얼마일 것인가?
- 실행 시간을 계산하기 위해서는, 명령어의 개수, CPI, 한 클럭당 소요되는 시간을 서로 곱해야 한다.

- 완벽한 파이프라이닝을 통해 해저드 없이 매 사이클마다 하나의 명령어가 Fetch되고, 하나의 명령어가 처리된다 가정한다.
- 즉, CPI = 1이다. (해저드 없이, 매 사이클 당 하나의 명령어가 처리되므로)
- SPECINT2000 벤치마크에 의해 명령어의 분포가 위 그림과 같다고 판정되었다 가정한다.
- 또한, SPECINT2000 벤치마크에 의해 전체 프로그램의 25%를 차지하는 Load 명령어 중, 40%의 명령어가 Load-Use Case를 갖고 있다하며, 전체 프로그램의 11%를 차지하는 Branch 명령어에서 25%의 확률로 분기 예측이 실패한다고 판정되었다 가정한다.

가정
- load 명령의 40%는 Load-Use Case에 해당된다.
- branch 명령의 25%는 Branch Prediction에 실패한다.
- jump 명령어의 바로 다음에 위치한 명령어는 무조건 Flush된다. (ID Stage 이후에 jump 주소가 계산되기 때문이다.)
CPI
- load 명령어와 branch 명령어는 Stall이 없는 환경에서는 CPI = 1이다.
- load 명령어와 branch 명령어는 Stall이 있는 환경에서는 CPI = 2이다.
따라서, load 명령어의 Average CPI = 1 * 60% + 2 * 40% = 1.4 이다.
따라서, branch 명령어의 Average CPI = 1 * 75% + 2 * 25% = 1.25이다.
또한, jump 명령어의 Average CPI = 2가 된다. (무조건적으로 Flush하기 때문이다.)
따라서, 이 프로그램 전체의 Average CPI는 아래와 같다.
Average CPI = 25% * 1.4(Load) + 10% * 1(Store) + 11% * 1.25(Branch) + 2% * 2(Jump) + 52% * 1(R-Type) = 1.15

- Exception은 Interrupt는 같은 의미로 혼용되는 경우가 많다.
- 엄밀히, Exception은 CPU 내부에서 일어나는 Event이다.
- ISA에서 정의되지 않은 OP-Code, 0으로 나누는 연산, 산술 연산에서의 Overflow 발생과 같은 일들이 Exception에 해당된다.
(단, Overflow의 경우 아키텍처에 따라 Exception을 발생시키거나, 다른 방법으로 해결하기도 한다.)
- Interrupt는 I/O가 알려주는 Event이다.
Pipeline MIPS #3
- 명령어와 명령어 사이에 Dependency(의존성)가 존재할 경우에 관한 설명이다.
- 그림의 맨 윗쪽에는 시간축이 표시되어 있다. 각 Cycle마다 $s2 레지스터의 상태를 표시하고 있다. (CC : Clock Cycle)
- Dependency는 Data 해저드와 Control 해저드를 초래한다.
- 첫 번째 sub 명령어에서는 $s2 레지스터가 WB Stage에서 사용하고자 하며, 나머지 명령어들에서는 ID Stage에서 사용하고자한다.
- 즉, 첫 번째 sub 명령어와 나머지 명령어들은 $s2 레지스터에 대한 의존성이 있다.
- 보통, Flip-Flops에서는 한 사이클에 하나의 값만을 저장하고 있으나, 본 포스트에서는 구현을 달리하여 레지스터 파일이 한 사이클에 두 개의 값을 가질 수 있도록 한다. (Implementation Specific한 영역이다.)
- 즉, CC 5 에서는 사이클 초반부에는 $2레지스터에 10을, 사이클 후반부에는 -20를 저장한다고 가정한다.
(sub 명령어를 통해, $1 레지스터와 $3 레지스터의 뺄셈 연산 결과가 -20이 나왔다고 가정한다.)
- CC 5 후반부부터는 $2 레지스터에 쓰기 연산을 수행하는 Stage가 없으므로, 값 -20이 유지된다.
- 두 번째 명령어(and)부터 마지막 명령어(sw)까지는 $2 레지스터에 값 -20을 기대하는 상황이다. (이들 명령어 입장에서는 sub 명령어에 의해 $2 레지스터의 값이 수정된 결과를 받아야 한다.)
- 그러나, 두 번째 명령어(and)와 세 번째 명령어(or)는 sub 명령어가 결과값(-20)을 쓰기 이전에 $2 레지스터의 값을 요구하고 있으므로, Data 해저드의 위험이 있다. ($s2의 값으로 결과값(-20)을 기대하고 있었으나, 10이 저장되어 있는 상태이다.)
- 네 번째 명령어(add)는 가정한 내용대로, sub 명령어의 WB Stage에서 결과값을 바로 넘겨받아 Data 해저드를 회피한다고 가정한다.
- Data 해저드에 대한 S/W적인 해결방법이다.
- 가장 직관적인 방법으로, 컴파일러에 의한 nop 명령어 삽입하는 방식이다.
- nop 명령어는 실제로 확정되어 있지는 않으나, 본 포스트에서는 0x0000 0000에 해당된다 가정한다.
- 이는, $0 레지스터를 0번 Shift하여 $0에 저장할 것을 명령하는 의미없는 sll 명령어이다. (논리적 nop 명령어)
- sub 명령어와 and 명령어 사이에 2개의 nop 명령어를 삽입하여, Data 해저드 위험이 있는 and 명령어와 or 명령어의 ID Stage가 sub 명령어의 WB Stage 이후에 위치하도록 기능적으로 미루는 방식이다.
- nop 명령어 삽입은 기능적으로 문제가 없으나, 성능의 저하를 불러온다.
- nop 삽입법보다는, Code-Rescheduling 방법이 성능의 저하를 줄일 수 있다.
- 필요한 값이 실질적으로 확정되는 Stage에서 바로 넘겨주는 Forwarding 방법을 통해 Data 해저드를 피할 수도 있다.
- 의존성이 있는 명령어들이 필요한 값이 확정되는 대로 바로 넘겨받게 H/W적으로 Data 해저드를 회피하는 방법을 Forwarding이라고 한다.
- sub 명령어에서 $2 레지스터의 결과값(-20)이 실질적으로 확정되는 EX Stage이후의 파이프라인 레지스터에서 명령어들에게 바로 값을 넘겨주는 방식이다.
- nop 명령어 사용을 지양하고, Forwarding을 위한 H/W Logic을 추가적으로 설계해야 함을 감안하고, 파이프라이닝 Throughput을 최대한으로 끌어내는 방법이다.
1. and 명령어에서 수행되는 Forwarding
- and 명령어는 EX의 시작 단계에서 MUX를 통해 sub 명령어의 EX/MEM 파이프라인 레지스터의 값(-20) 혹은 and 명령어의 ID/EX 파이프라인 레지스터의 값(10) 중 하나를 입력받는다.
(그림에서 MUX는 주황색 선들의 접점이라 볼 수 있다.)
- 여기서는, -20 값을 전달받아야 하므로, MUX는 sub 명령어의 EX/MEM 파이프라인 레지스터에 저장된 값을 선택할 것이다.
2. or 명령어에서 수행되는 Forwarding
- or 명령어 또한, EX의 시작 단계에서 MUX를 통해 MEM/WB 파이프라인 레지스터의 값(-20) 혹은 or 명령어의 ID/EX 파이프라인 레지스터의 값(10) 중 하나를 입력받는다.
- 여기서는, -20 값을 전달받아야 하므로, MUX는 sub 명령어의 MEM/WB 파이프라인 레지스터에 저장된 값을 선택할 것이다.
3. add 명령어에서 수행되는 Forwarding
- 엄밀히 설명하면, add 명령어에서도 Forwarding이 이루어졌다고 할 수 있으나, 본 포스트에서는 특수한 H/W 설계를 통해 sub 명령어의 WB Stage의 전반부에서 값을 add 명령어의 ID Stage의 후반부에 넘겨받았다고 가정한다.
※ 마지막 sw 명령어는 Data 해저드의 위험이 없으므로, 별다른 특이사항을 갖지 않는다.
- 의존성이 있는 두 명령어 사이에서 위 조건 중 하나라도 만족되면 Data 해저드의 발생 위험을 의심해야 한다.
- 4페이지 그림에서 sub 명령어와 and 명령어는 1a 조건이 만족된다. (실제로 Data 해저드 위험이 있다.)
- 4페이지 그림에서 sub 명령어와 or 명령어는 2b 조건이 만족된다. (실제로 Data 해저드 위험이 있다.)
- a는 Forwarding이 수행되지 않는 H/W 구조, b는 Forwarding을 위한 H/W Logic 구조이다.
- 여기서 Forwarding Unit의 역할은 ForwardA, ForwardB 신호선을 적절히 Select하여,
레지스터 파일, EX/MEM 파이프라인 레지스터, MEM/WB 파이프라인 레지스터 중 어느 곳에서 값을 가져올지를 결정한다.
- 해저드로 판정되지 않으면, ForwardA와 ForwardB는 모두 00으로 초기화 된다.
EX 해저드
- 바로 인접한 두 명령어 사이에 Data 해저드가 있는 경우이다.
- EX 해저드로 판정할 수 있는 세 가지 조건은 아래와 같다. (세 조건이 모두 만족되면 EX 해저드이다.)
1. RegWrite 신호값이 1
2. EX/MEM 파이프라인 레지스터가 zero 레지스터가 아님
3. EX/MEM 파이프라인 레지스터에 위치한 Rd 값 == ID/EX 파이프라인 레지스터의 두 값(Rs, Rt) 중 하나 (즉, 적절한 값을 넘겨받지 않는 상황이면)
- EX 해저드로 판정되면, EX/MEM으로 부터 값을 넘겨받도록, Forwarding Unit이 10(MUX의 세 번째 입력값)을 생성한다.
MEM 해저드
- 사이에 하나의 명령어를 둔 두 명령어 사이에 Data 해저드가 있는 경우이다.
- MEM 해저드로 판정할 수 있는 세 가지 조건은 아래와 같다. (모든 조건이 모두 만족되면 MEM 해저드이다.)
1. RegWrite 신호값이 1
2. MEM/WB 파이프라인 레지스터가 zero 레지스터가 아님
3. MEM/WB 파이프라인 레지스터에 위치한 Rd 값 == I01D/EX 파이프라인 레지스터의 두 값(Rs, Rt) 중 하나 (즉, 적절한 값을 넘겨받지 않는 상황이면)
- MEM 해저드로 판정되면, MEM/WB으로부터 값을 넘겨받도록, Forwarding Unit이 01(MUX의 두 번째 입력값)을 생성한다.
- 3번째 명령어 입장에서는 2번째 명령어의 결과를 활용해야 한다. (가장 최근의 결과를 반영해야 한다. 즉, EX 해저드로 판정해야 한다.)
- 이러한 상황에서, 만약 MEM 해저드를 판별하고자 한다면,
첫 번째 명령어와의 의존성(MEM 해저드)은 존재하면서,
두 번째 명령어와의 의존성(EX 해저드)는 존재하지 않음을 확신할 때, MEM 해저드로 판별할 수 있다.
- 위 그림의 오른쪽 코드는 MEM 해저드를 판별하는 코드이다.
- Forwarding Unit을 통해서도 Stall을 방지할 수 없는 경우가 Load-Use Case이다.
- Load-Use Case는 lw 명령어 이후에 load한 결과물을 이용해야 하는 경우가 이에 해당된다.
- 2번째 명령어(and)의 경우에는 EX 단계(CC4 시작)에서 1번째 명령어(lw)의 WB 단계(CC5 시작)에서의 결과를 받아야 하므로, 한 Cycle 만큼의 Stall은 피할 수 없다.
- Stall이 불가피한 상황을 감지하여, Stall을 수행하기 위해 Hazard Detection Unit이 필요하게 된다.
- Hazard Detection Unit이 상황을 감지하면, lw 명령어 이후에 Bubble(Stall)을 생성하게 된다.
- Hazard Detection Unit이 감지에 성공하면, and 명령어의 ID Stage 이후에 하나의 Bubble이 삽입된다.
(그림에 마지막 명령어 slt가 밀려나 없어졌음에 유의하자.)
- 해저드를 감지하는 방법에 관하여 설명한다.
- 해저드를 Detection하고 파이프라인을 Stall하는 것은 nop 명령어 삽입을 구현하는 것과 비슷하다.
- Hazard Detection Unit은 ID Stage에 위치하여 IF/ID의 Source 레지스터와 ID/EX Stage의 Source 레지스터가 같은 지를 판정한다. (판정은 Decoding 결과 Load 명령어로 판정이되면 수행된다.)
- 메모리를 읽는 연산을 수행할 때, 해저드가 발생할 수 있으므로, ID/EX에서 메모리 읽기 연산을 수행하는 명령어인지를 판별한다.
- 메모리를 읽는 연산으로 판정되면, Rt 레지스터에 해당되는 부분이 다음 명령어의 Source 레지스터와 동일한지를 확인한다. (즉, 로드한 데이터를 다음 명령어에서 바로 활용 되는지를 판별하는 것이다.)
- 동일하다 판정되면 파이프라인을 Stall 시킨다.
- Hazard Detection Unit은 PC와 IF/ID 파이프라인 레지스터에 연결된 Control 신호(PCWrite, IF/IDWrite)를 이용하여 PC 값 업데이트를 막거나 IF 단계를 막아서 Stall시킨다.
- Control Unit(하늘색 타원)에서는 명령어에 따른 9가지의 Control Signal을 생성하여 IF/ID 파이프라인 레지스터를 제외한 파이프라인 레지스터에 보낸다.
Hazard Detection Unit에 입력되는 값
ID/EX.MemRead : ID/EX 파이프라인 레지스터에서 출력되는 값이다.
IF/ID Output : IF/ID 파이프라인 레지스터에서 출력되는 값이다.
Hazard Detection Unit에서 출력되는 값
1.Hazard Detection Unit 왼편에 위치한 신호 : 한 사이클을 중지할 수 있게 한다.
PCWrite : PC값 업데이트를 중지(Stall)시킬 수 있다.
IF/IDWrite : IF/ID 파이프라인 레지스터에 쓰기를 중지시킬 수 있다.
2. Hazard Detection Unit 오른편에 위치한 신호 : nop 명령어가 삽입된 것과 같은 효과를 낸다.
MUX Selection : 파이프라인을 Stall할 것으로 결정되면, MUX의 0값이 선택되어,
9가지 모든 Control 신호가 0으로 설정되어 각각의 파이프라인 레지스터에 전달된다.
(마치 nop 명령어가 삽입된 것과 비슷한 효과를 낸다.)
- "Not Taken"Prediction Rule을 적용한다. (beq명령어에서는 분기가 일어나지 않는다 가정하는 것)
- 즉, beq 명령어로 해석되면, 분기 조건 결과에 상관없이 44, 48, 52에 위치한 명령어들도 일단 프로세서가 정상적으로 처리하는 것이다.
- Branch 여부는 MEM Stage에서 정해진다. (두 Operand의 차이값이 EX Stage가 수행된 이후에 결정되기 때문이다.)
- 만약, Branch 조건이 True로 판정된 경우, 실행중이던 44, 48, 52의 명령어들을 Flush해야 한다.
- 일반적인 경우, Branch 조건이 판정되는 시기는 MEM Stage이다.
- MEM Stage까지 대기한 후, 이후의 명령어들을 Flush하게 된다면 성능 면에서의 손해가 크다. (3개의 명령어가 Flush되기 때문이다.)
- 이러한 Panelty를 최소화하기 위한 부가적인 Logic(Branch Compare Logic)이 필요하다.
- Branch Compare Logic은 Branch 명령어의 피연산자들을 ID Stage에서 비교할 수 있게 한다.
(여기서, 비교 연산은 두 값의 일치 여부만 계산하는 것을 의미하며, 뺄셈 연산까지 포함하지는 않는다.)
(단순히 값의 일치 여부를 계산하는 Logic은 덧셈/뺄셈 Logic보다 간단하다.)
- Compare 연산은 n Bit by n Bit 방식의 XOR 연산으로 수행되며, 그 n개의 결과들을 모두 OR연산한 결과(1bit)가 0일 경우에는 두 값이 같다 판정하며, 그 이외의 값이 나올 경우에는 두 값이 같지 않다고 판정하게 된다.
(즉, XOR 연산 결과가 0이면 두 값이 같은 것으로, 0이 아니면 두 값이 다른 것으로 판정한다.)
- 또한, Branch Predictor는 명령어를 Flush하는 Logic도 구현되어 있어야 한다.
- IF.flush Control 신호가 입력되면, IF/ID 파이프라인 레지스터에 있는 값을 모두 0으로 만든다.
- ID Stage가 수행되면 분기 주소와 분기 여부를 확정지을 수 있게하는 Logic이 구현되었고, Prediction Policy(본 포스트에서는 "Not Taken" Policy)에 의거하여 명령어들을 처리한다고 가정한다.
- 만약 beq 명령어의 ID Stage가 완료된 후, 분기를 해야된다고 판정되면, add 명령어를 Flush해야 한다. (Stall이 아님)
- "Not Taken" Policy를 따르는 Branch Predictor에서 beq 명령어의 Branch 조건이 True로 판정되어 예측과 달리, 분기를 해야한다면, 기존에 처리되던 and 명령어를 Flush해야 한다.
(이러한 결론은 ID Stage 이후에 분기 여부와 분기 주소를 계산할 수 있는 Logic이 추가적으로 구현되었다는 가정 하에 이루어진다.)
- beq 명령어의 레이블 값이 7이다. 그러므로 분기할 주소는 7*4 + (PC + 4) = 28 + 44 = 72가 된다.
- Control 해저드(Branch 해저드)로 인한 성능 저하를 Alleviate(완화하다)하는 예시이다.
- ID Stage에서의 연산을 마친 beq 명령어는 분기 여부와 분기 주소가 모두 확정된다.
- Control 유닛 오른쪽에 작은 Adder에서는 분기 주소가 계산된다. (Base + Offset)
- Register 파일 오른쪽에 Equal 기호가 있는 작은 타원에서는 분기 명령어의 피연산자들이 같은 값인지를 판별하는 bit by bit XOR연산과 OR 연산이 수행된다.
- 같은 시각에, IF Stage에서는 PC 값이 이미 44로 업데이트 되어 Instruction Memory에 넘겨주고 있다. (즉, and 명령어가 IF Stage에서 처리되고 있다.)
- 같은 시각에 ID Stage에서는 분기를 해야한 것으로 판정되어 PC에 분기 주소 72를 전달한다.
- ID Stage가 처리된 and 명령어를 Flush하기 위해 IF.Flush 신호를 활성화한다.
- IF.Flush 신호에 의해 IF/ID 파이프라인 레지스터에 입력된 값(and 명령어 처리 결과)이 모두 0으로 초기화된다.
- and 명령어가 Flush된 후, 분기 주소에 위치한 lw 명령어가 정상적으로 실행되는 그림이다.
- 어떤 프로그램이 1,000억개의 명령어로 구성되었다할 때, 이 프로그램의 Execution Time(실행 시간)은 얼마일 것인가?
- 실행 시간을 계산하기 위해서는, 명령어의 개수, CPI, 한 클럭당 소요되는 시간을 서로 곱해야 한다.
- 완벽한 파이프라이닝을 통해 해저드 없이 매 사이클마다 하나의 명령어가 Fetch되고, 하나의 명령어가 처리된다 가정한다.
- 즉, CPI = 1이다. (해저드 없이, 매 사이클 당 하나의 명령어가 처리되므로)
- SPECINT2000 벤치마크에 의해 명령어의 분포가 위 그림과 같다고 판정되었다 가정한다.
- 또한, SPECINT2000 벤치마크에 의해 전체 프로그램의 25%를 차지하는 Load 명령어 중, 40%의 명령어가 Load-Use Case를 갖고 있다하며, 전체 프로그램의 11%를 차지하는 Branch 명령어에서 25%의 확률로 분기 예측이 실패한다고 판정되었다 가정한다.
가정
- load 명령의 40%는 Load-Use Case에 해당된다.
- branch 명령의 25%는 Branch Prediction에 실패한다.
- jump 명령어의 바로 다음에 위치한 명령어는 무조건 Flush된다. (ID Stage 이후에 jump 주소가 계산되기 때문이다.)
CPI
- load 명령어와 branch 명령어는 Stall이 없는 환경에서는 CPI = 1이다.
- load 명령어와 branch 명령어는 Stall이 있는 환경에서는 CPI = 2이다.
따라서, load 명령어의 Average CPI = 1 * 60% + 2 * 40% = 1.4 이다.
따라서, branch 명령어의 Average CPI = 1 * 75% + 2 * 25% = 1.25이다.
또한, jump 명령어의 Average CPI = 2가 된다. (무조건적으로 Flush하기 때문이다.)
따라서, 이 프로그램 전체의 Average CPI는 아래와 같다.
Average CPI = 25% * 1.4(Load) + 10% * 1(Store) + 11% * 1.25(Branch) + 2% * 2(Jump) + 52% * 1(R-Type) = 1.15
- Exception은 Interrupt는 같은 의미로 혼용되는 경우가 많다.
- 엄밀히, Exception은 CPU 내부에서 일어나는 Event이다.
- ISA에서 정의되지 않은 OP-Code, 0으로 나누는 연산, 산술 연산에서의 Overflow 발생과 같은 일들이 Exception에 해당된다.
(단, Overflow의 경우 아키텍처에 따라 Exception을 발생시키거나, 다른 방법으로 해결하기도 한다.)
- Interrupt는 I/O가 알려주는 Event이다.