
Cache #1
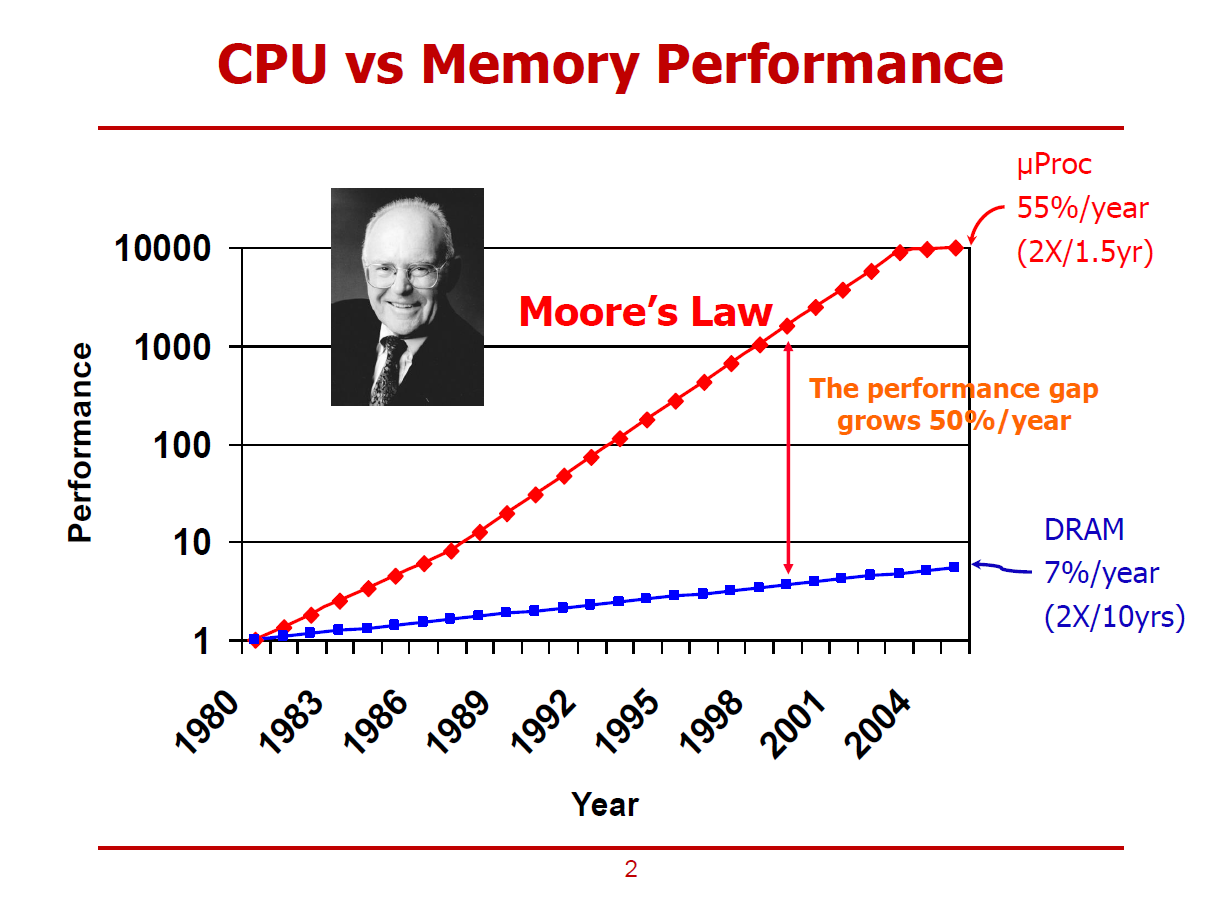
- 위 그림은 CPU와 D램 메모리의 성능 추이를 나타낸 그래프이다.
- 1980년대의 CPU 성능과 메모리 성능을 1.0이라 설정했다.
Moore's Law
- 약 1.5년마다, CPU에 집적시킬 수 있는 트랜지스터의 수가 두 배씩 증가한다는 법칙(주장)을 의미한다.
- CPU의 성능 향상률에 반해, D램 메모리의 성능 향상률은 매년 7% 선에 그쳤다.
- 즉, CPU와 D램 메모리 사이의 성능 간극이 매년마다 50%씩 벌어지고 있는 추세이다.
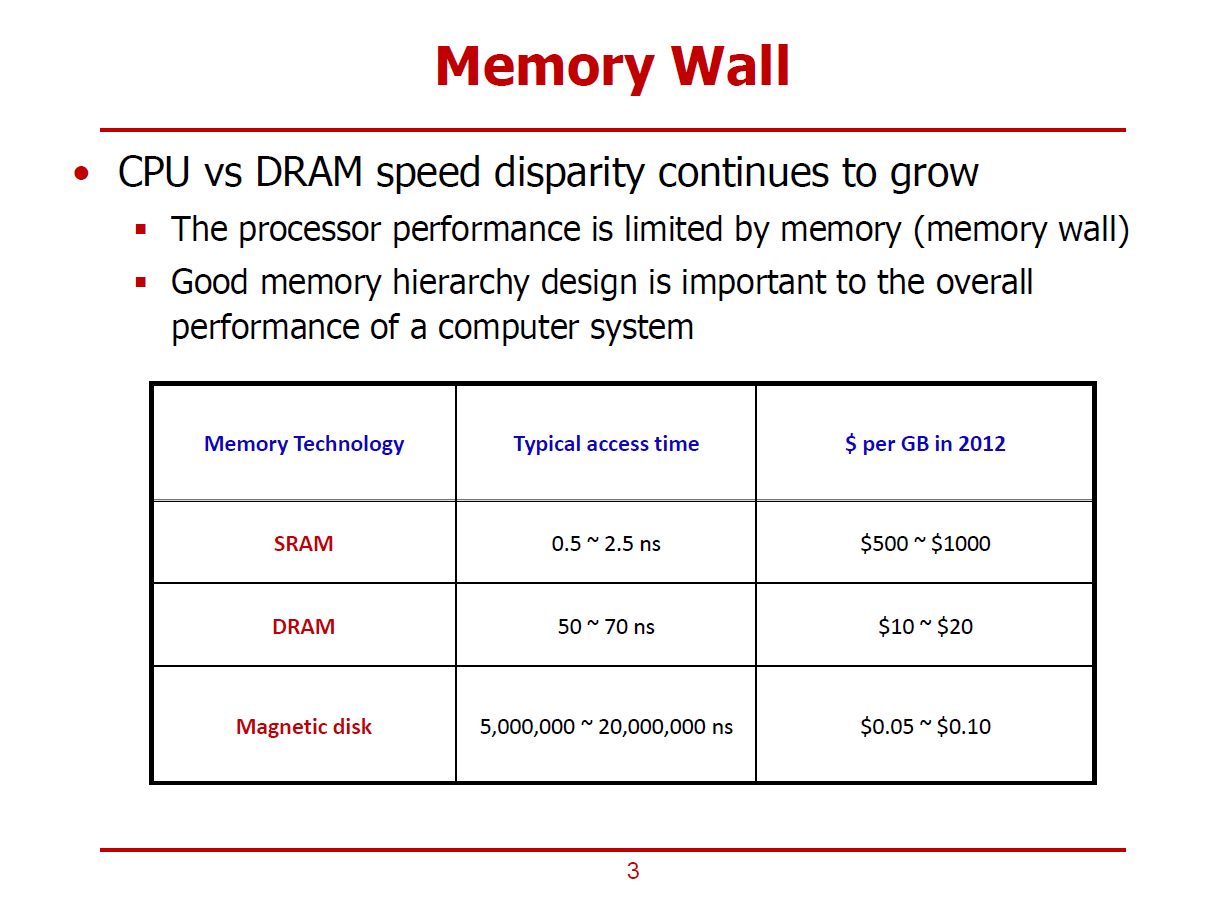
Memory Wall
- 컴퓨터 시스템의 전체적인 성능이 CPU에 뒤쳐지고 있는 메모리에 의해 결정되는 현상을 의미한다.
SRAM
- CPU 내부에 삽입할 수 있으며, 트랜지스터 로직 공정과 동일한 공정을 거친다.
- 여타 메모리보다 빠른 성능을 가진 대신, 용량 대비 가격 경쟁력이 떨어진다.
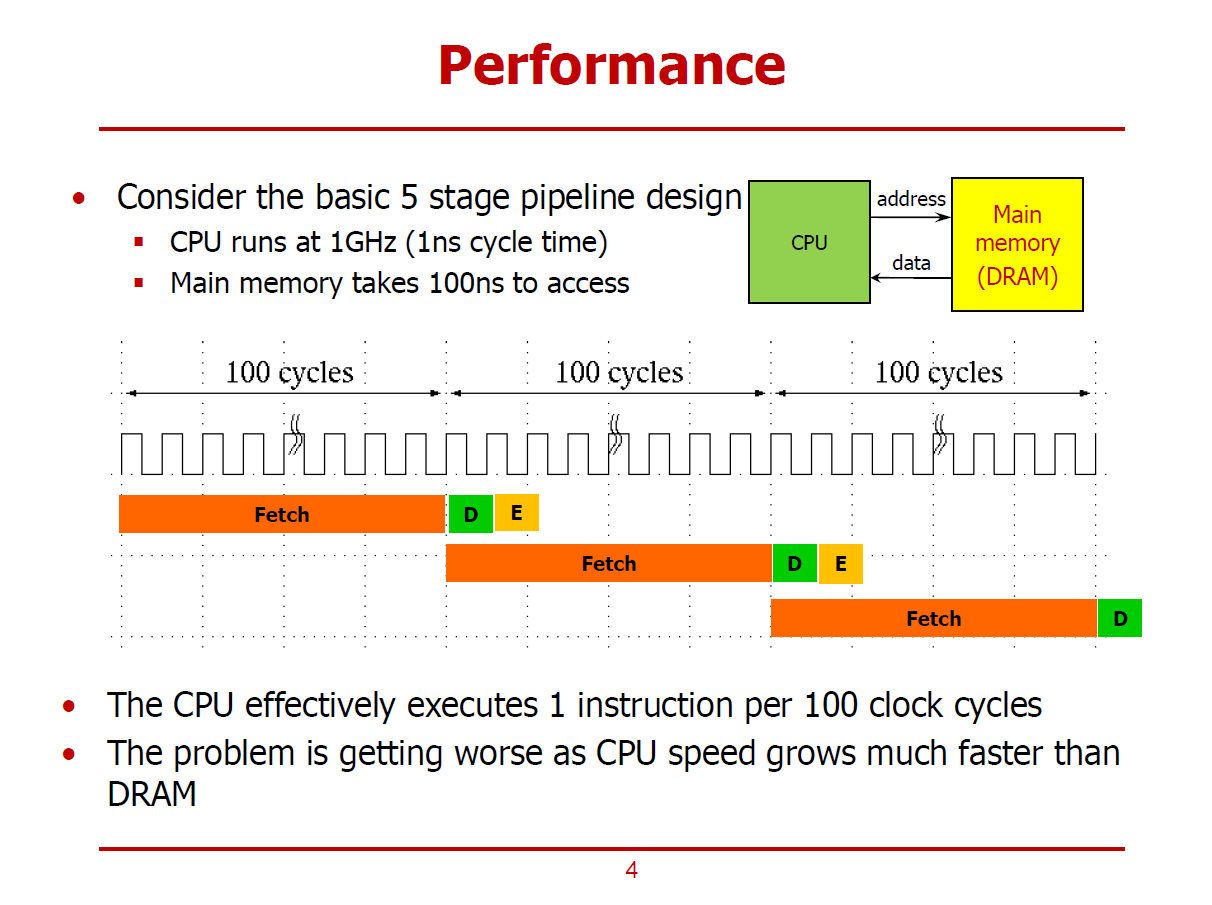
- CPU보다 상대적으로 느린 DRAM이 컴퓨터 시스템 전체 성능에 어떻게 영향을 미치는 가에 대한 이야기이다.
- 기존에 다뤘던, Instruction을 5개의 Stage로 나누어 Pipelining 방식으로 처리하는 MIPS 프로세서 예시이다.
- CPU의 Clock Cycle은 1GHz이다. (즉, 1ns마다 하나의 Clock Cycle이 생성된다.)
- 위 Pipeline Execution Diagram에서는 IF Stage에 100 Cycle이 소요된다.
(비교적 많은 시간이 소요되는 이유는 IF가 메인 메모리(DRAM)에 접근해야 하는 Stage이기 때문이다.)
- MEM, WB Stage는 생략한다.
- ID, EX Stage에 비해 IF Stage에서 많은 시간이 소요됨을 알 수 있다.
- 유독 IF Stage에서 많은 시간이 소요되는 것을 보고, 메모리에 접근하는 과정에서 많은 시간이 소요된다 결론 지을 수 있다.
- 즉, 가장 오랜 시간이 걸리는 IF Stage에서 100 Cycle이 소요되므로, 해당 프로세서에서는 100 Cycle마다 하나의 명령어를 처리할 수 있게 된다. (즉, CPI = 100 이다.)
- Moore's Law에 의해, CPU와 메모리 간 성능 차이가 커질수록 위와 같은 성능 저하 문제는 심각해진다.
ex) 메모리의 성능은 그대로인 상태에서 CPU의 Clock Cycle이 2GHz로 개선되면, CPI = 200으로 증가한다. (성능 저하)
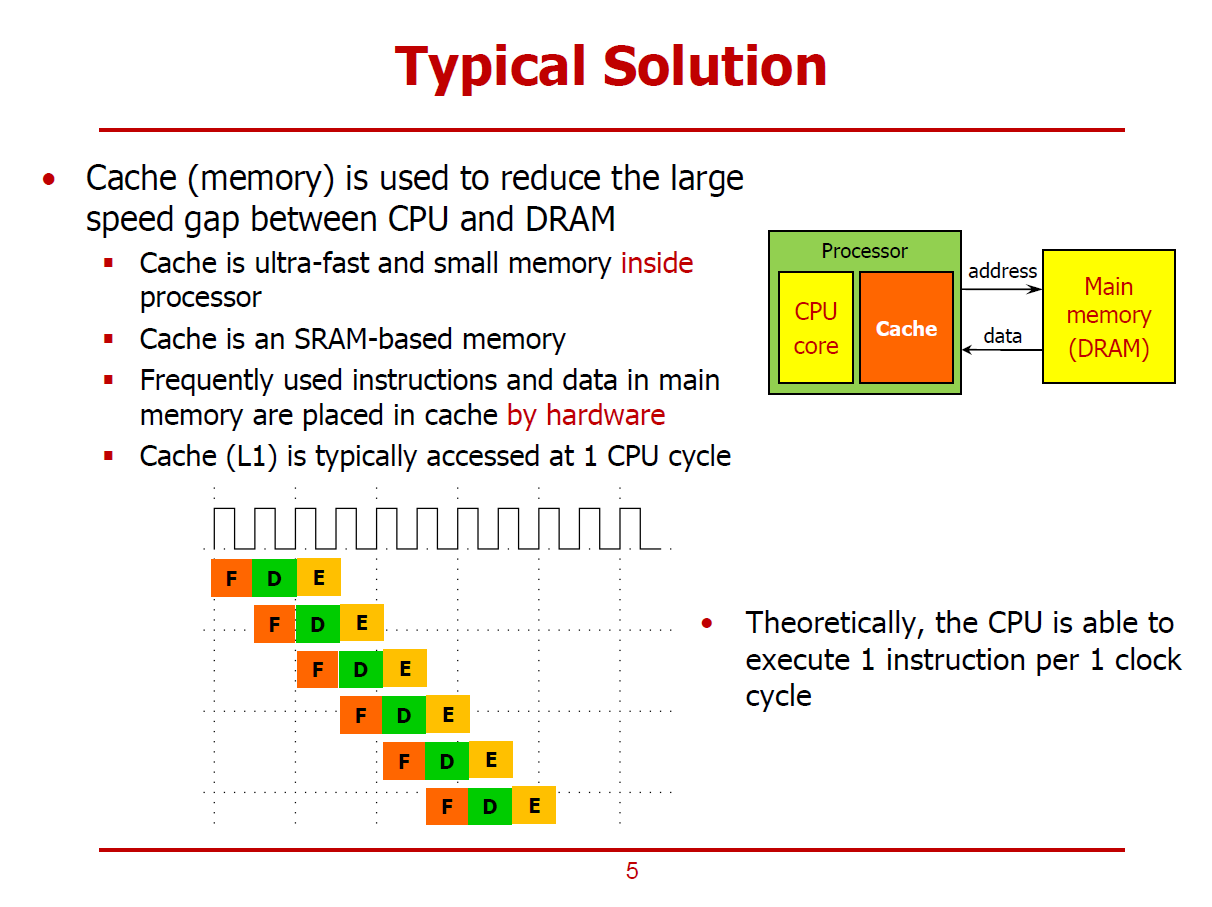
- 앞 장에서 확인한 성능 저하를 해결하기 위해 CPU Architect들은 프로세서를 구성할 때, Core 뿐만 아니라, Cache(SRAM 기반의 메모리)도 집적시킨다.
- 자주 사용되는 명령어, 데이터들이 Cache에 저장된다.
- Cache는 100% H/W에 의해 운영되며, S/W적으로 제어할 수 있는 방법은 없다.
- Cache를 제어한다 함은, 메인 메모리에 저장되어 있는 명령어, 데이터 중 빈번히 사용되는 것들을 Cache에 저장하는 것을 의미한다.
(자주 사용하는 명령어, 데이터를 프로그래머가 선정하여 Cache에 저장시킬 수 없다.)
- CPU는 자주 사용하는 명령어, 데이터를 Cache에서 Fetch 함으로써 시간을 절약할 수 있다.
- Cache 또한 여러 Level로 이루어져 있으며, 가장 빠른 L1 Cache는 보통 CPU Cycle과 클럭 주기를 같이하여 CPU가 한 사이클 안에 데이터를 Fetch할 수 있다.
※ Cache는 꼭 SRAM으로만 설계되어야 하는 것은 아니며, Embeded DRAM과 같이 다른 소자로 구성하는 방식도 존재한다. 단, 거의 모든 Cache는 SRAM으로 생산된다.
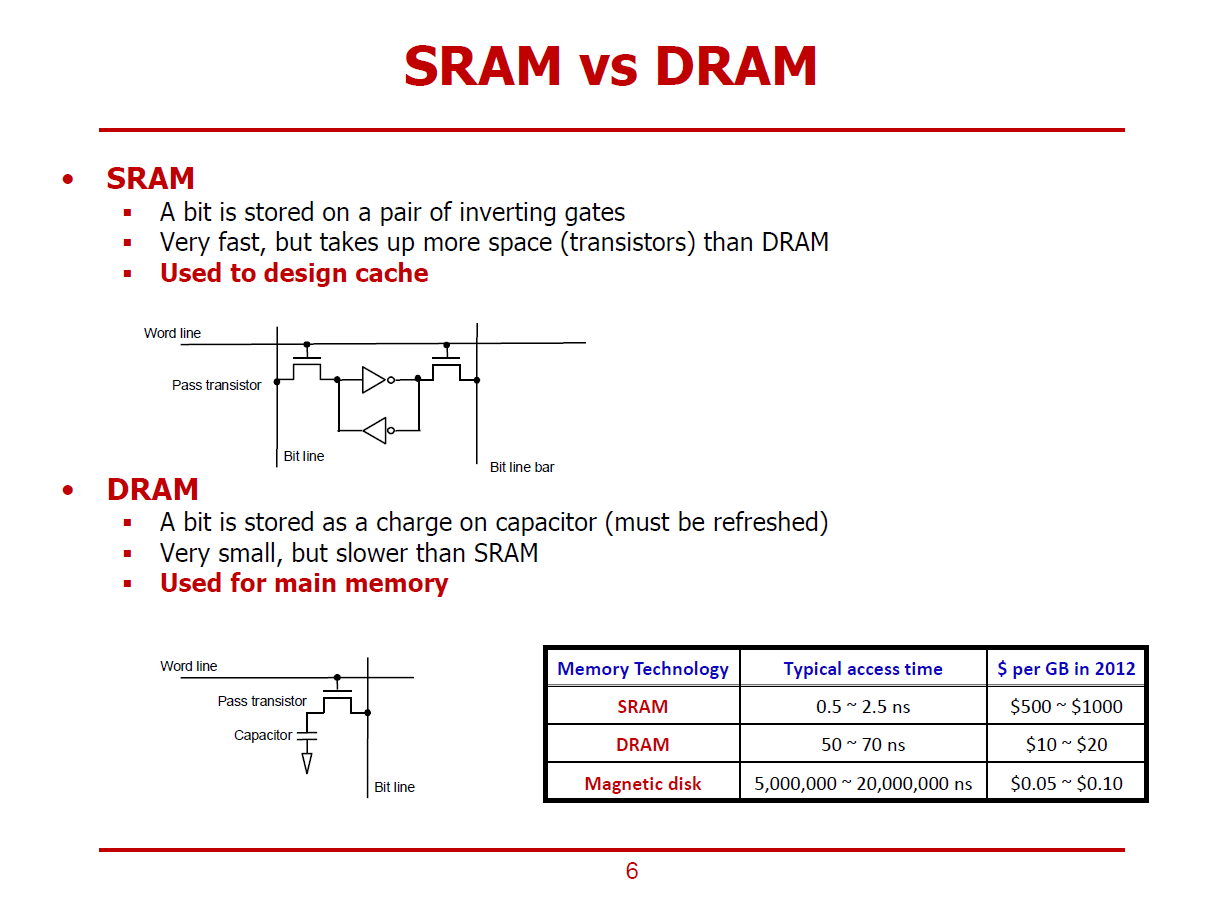
SRAM
- Cross-Coupled Inverter가 데이터를 보관하는 형태이다.
- 트랜지스터 기반의 Positive-Feedback 기법을 통해 매우 빠른 동작 속도를 구현할 수 있다.
- 그림의 SRAM은 하나의 Bit 값을 표현하는 Cell이며, 내부의 Inverter 하나는 두 개의 트랜지스터로 설계된다.
- 즉, 1Bit를 표현하는 하나의 Cell에는 두 개의 Inverter와 두 개의 byy를 집적하기 위해 총 6개의 트랜지스터가 필요하다.
- 또한, SRAM은 표현할 수 있는 Bit 수 대비 DRAM보다 많은 실리콘 공간을 요구한다.
- 이에 반해, DRAM은 1Bit를 표현하는데 하나의 Pass Transistor만을 요구하기 때문에 SRAM보다 가격적 측면에서 월등하다.
DRAM
- 기본적으로 Capacitor가 Logic에 이용된다.
- Capacitor는 Charge(전하)를 저장할 수 있는 회로소자로, 전하가 꽉 차있으면 1이라 간주하며, 전하가 없으면 0이라 간주한다.
- 여기서 Pass Transistor는 Capacitor에 전하를 채우거나 비우는 역할을 한다.
- 즉, DRAM에서는 1Bit를 표현하기 위해 하나의 Capacitor와 하나의 Pass Transistor만 필요로 하기에 비용 측면에서 효율적이다.
- 단, Capacitor에서는 시간이 지남에 따라 Leakage Current가 흐를 수 있으므로(전하가 누설되는 현상이 있을 수 있으므로), 특히 1을 표현하기 위해서는 주기적인 Refresh를 통해 전하를 채워주는 과정이 필요하다.
- 또한, Pass Transistor를 거쳐서 전하를 비우거나 채우고, 프로세서와 멀리 위치해있는 탓에 SRAM과 대비하여 처리 속도가 느리다.
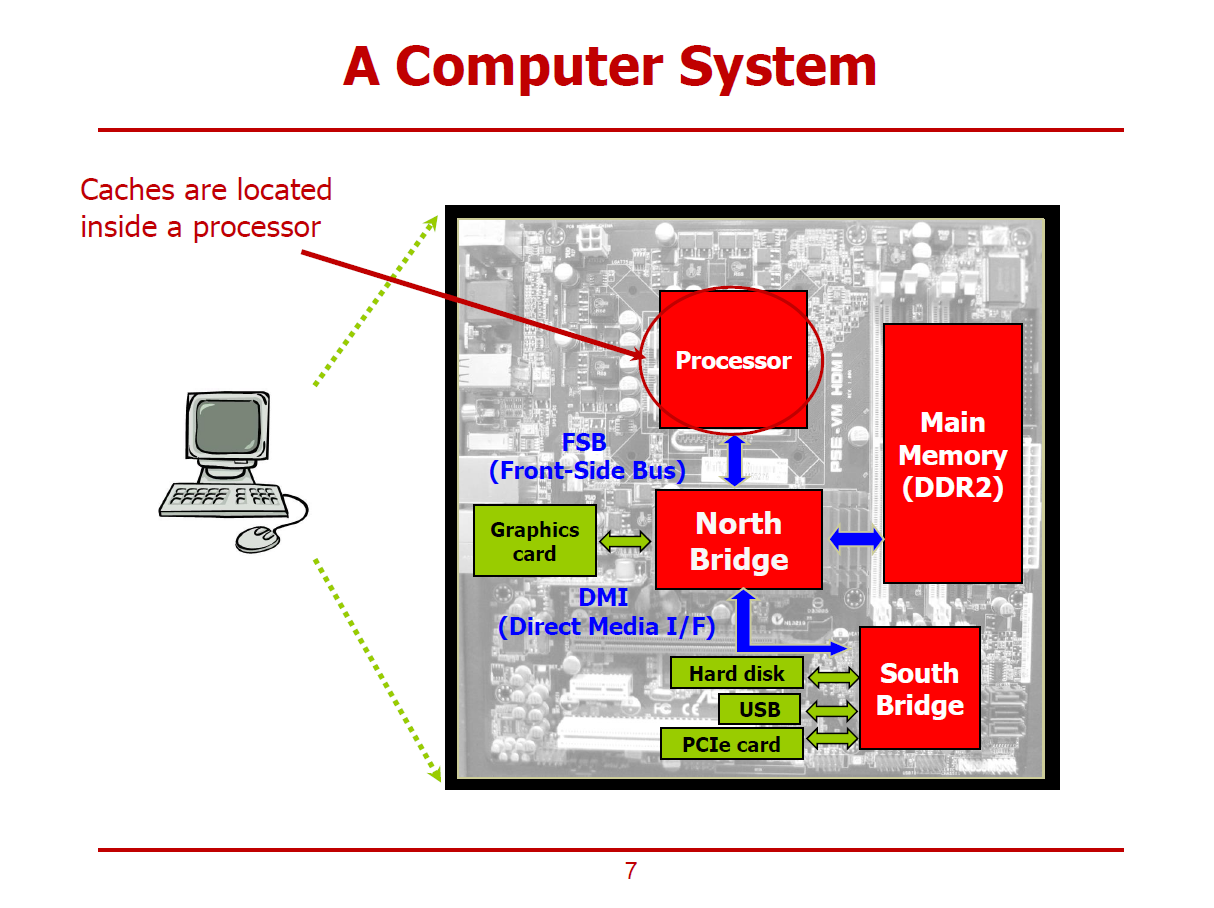
- 비교적 구 버전 컴퓨터의 구성 소자들에 대한 그림이다.
- 프로세서에 적재하지 못한 소자들을 North Bridge/South Bridge 칩셋에 집적한 구조이다.
- 현재와 달리, 메인 메모리를 프로세서가 아닌 North Bridge가 제어했다.
- 또한, North Bridge는 FSB를 통해 프로세서와 데이터를 주고 받았다.
- 현재는 프로세서 내에 Cache가 적재되어있는 형태이다.
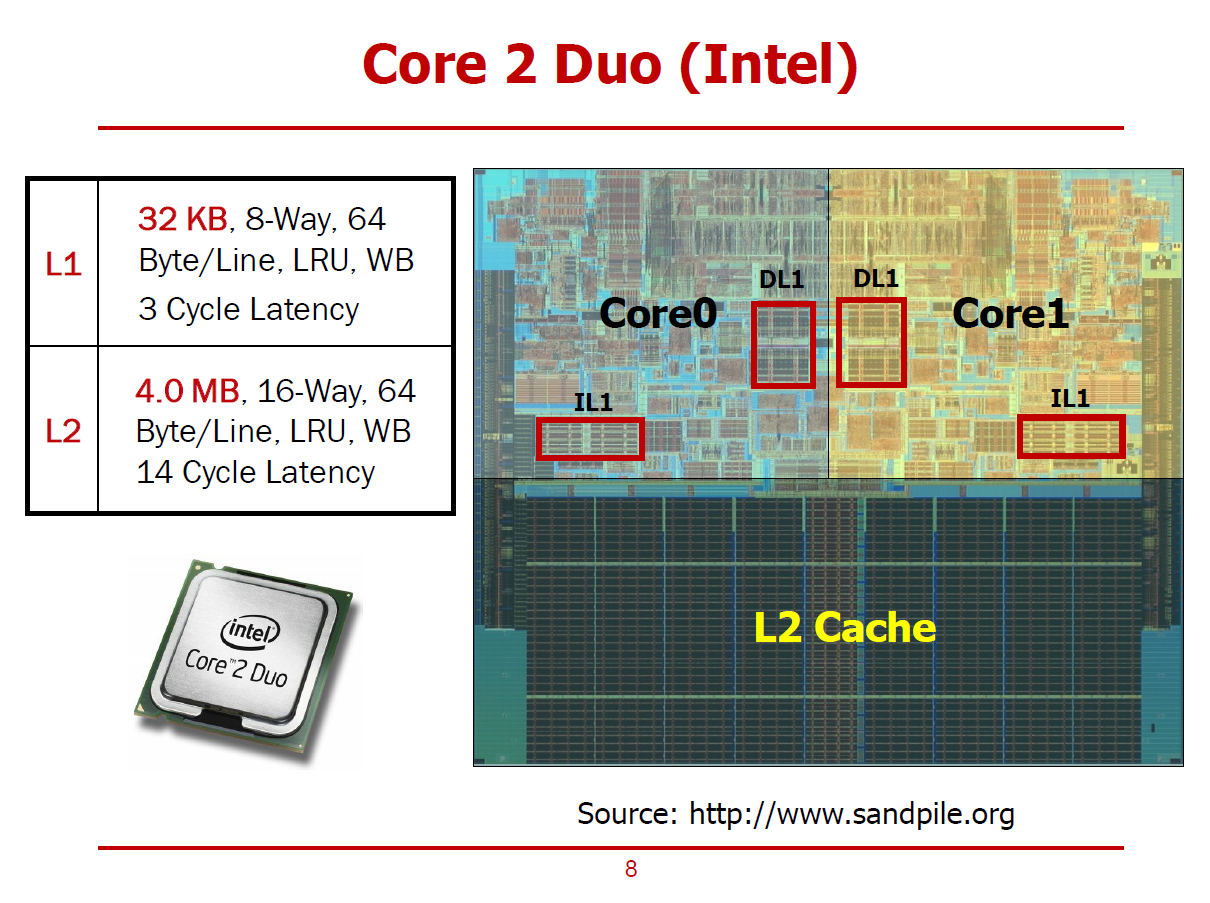
- Intel사의 2000년대 프로세서인 Core 2 Duo의 구조이다.
- 2개의 코어와 L1, L2 Cache가 적재되어 있는 형태이다.
- DL1은 Data Cache를 의미하며, IL1은 Instruction Cache를 의미한다.
- 즉, Level 1 Cache는 명령어를 위한 Cache와 데이터를 위한 Cache가 서로 구분된다.
- 즉, Core와 L1 Cache 사이에는 명령어를 주고받기 위한 Path와 데이터를 주고 받기 위한 Path가 따로 존재할 것이다.
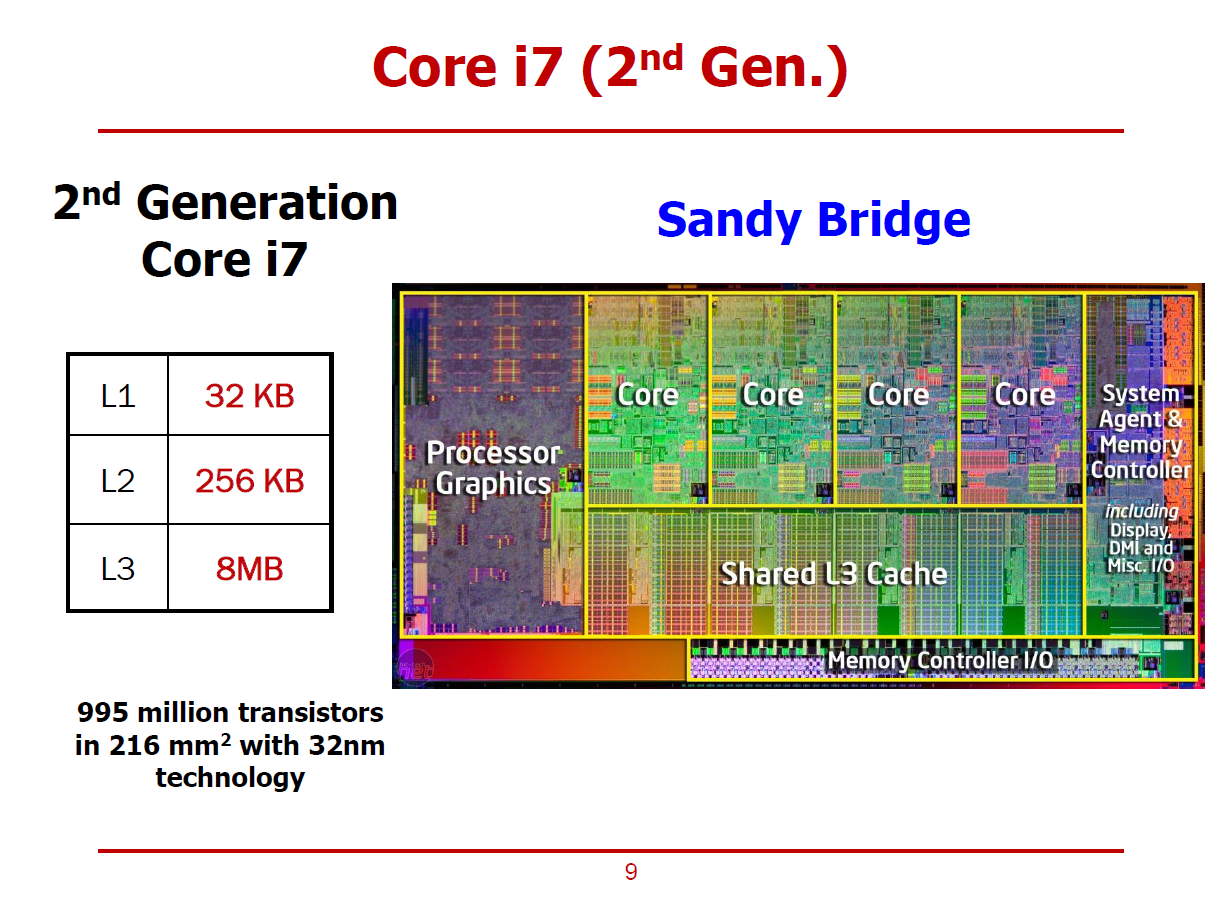
- Intel 사의 2세대 Sandy Bridge i7 프로세서에서는 Cache의 레벨이 3단계까지 증가되었다.
- 또한, Sandy Bridge에서는 보다 많은 North Bridge의 소자들이 프로세서에 함께 적재되었다.
(Moore's Law에 의해 더 많은 트랜지스터를 적재할 수 있음에 따른 결과이다.)
- 프로세서 내부의 Memory Controller와 Memory Controller I/O를 통해 프로세서에서 메모리를 제어할 수 있게 되었다.
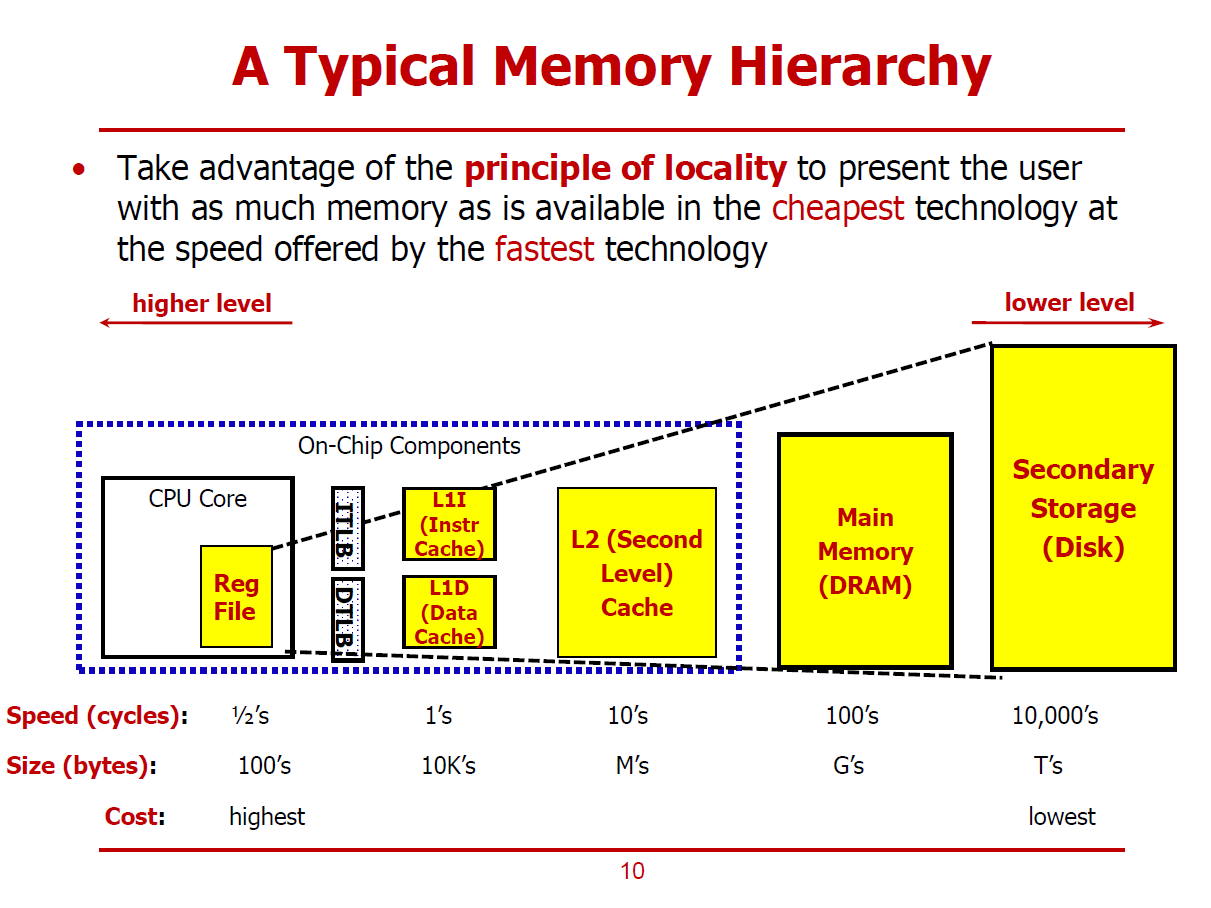
- 메모리의 처리 시간과 용량은 비례 관계에 있다.
(즉, 용량이 큰 메모리는 많은 처리 시간을 요구하며, 처리 시간이 짧은 메모리는 대용량으로 구현할 수 없다.)
Principle of Locality
- 비용 측면에서 우수한 기술을 용량이 큰 메모리를 설계하는 데에 사용한다.
ex) 자기 기술로써 구현한 4TB 하드디스크 드라이브
- 속도 측면에서 우수한 기술을 용량이 작은 메모리를 설계하는 데에 사용한다.
ex) 8KB L1 Cache
※ L1 Cache를 L1I와 L1D로 따로 설계함으로써 Structure 해저드를 예방할 수 있다.
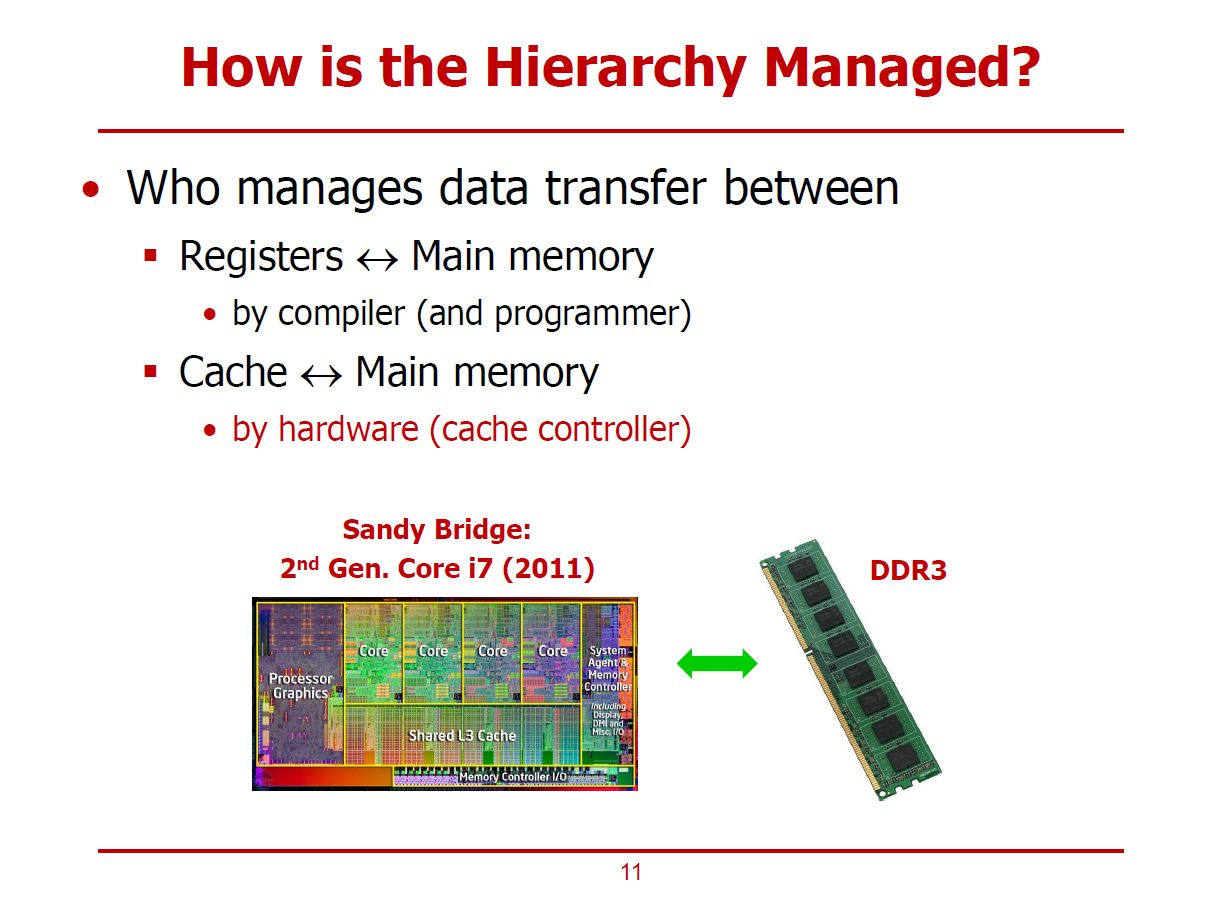
- Data Transfer를 Management하는 주체에 관한 이야기이다.
- 컴파일러 혹은 프로그래머에 의한, Register Spilling을 통해 레지스터와 메인 메모리 사이로 데이터를 옮길 수 있다.
- Cache Controller에 의해, Cache와 메인 메모리 사이로 데이터를 옮길 수 있다. (only H/W 영역)
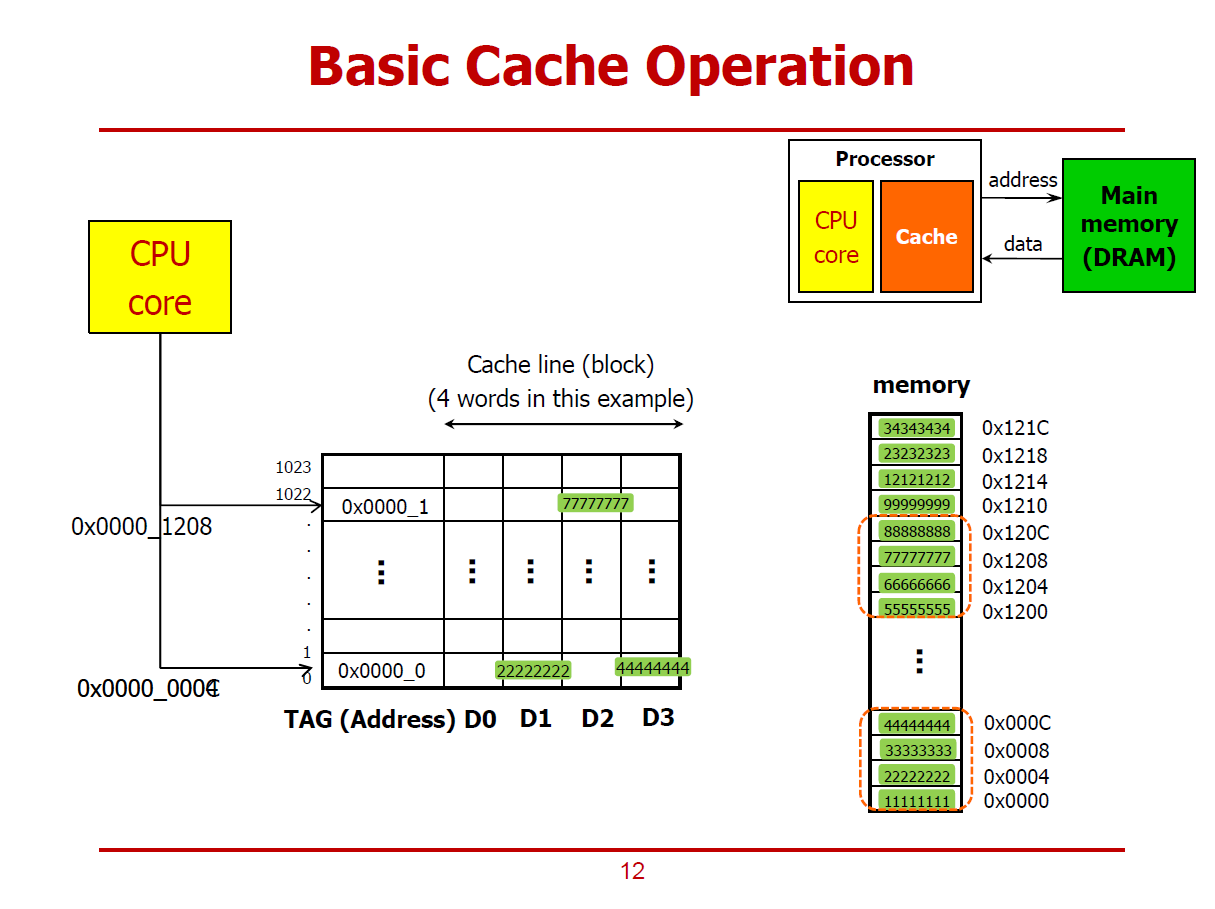
- D0, D1, D2, D3에는 각각 하나의 Word를 저장할 수 있다.
- TAG는 주소와 비슷한 역할을 한다.
- 즉, 위 그림의 Cache는 4개의 Word를 총 1,024개 저장할 수 있는 구조이다.
- Cache Line(Cache Block) = 4개의 Words를 저장하고 있는 하나의 Row를 의미한다.
- 즉, 1,024개의 Cache Line으로 구성된 것이다.
- 그림에서의 Cache Line의 크기는 4 Words이며, 이는 프로세서의 설계 방식에 따라 달라질 수 있다.
- 녹색 배경을 가친 수치들은 각각 1Word 데이터를 의미한다.
- 하나의 데이터들은 1Word 크기를 차지하므로, 메모리의 주솟값 또한 4씩 증가한다. (Word-Alignment)
1. CPU Core가 메인 메모리의 0x0000_0004 위치의 데이터(0x2222_2222)를 요구하는 경우
- Cache는 메인 메모리에게 데이터를 받아 CPU Core에게 전달하게 된다.
- 이 때, 메인 메모리는 0x2222_2222값 뿐만 아니라, 하나의 Cache Line을 채우기 위해 해당 데이터가 위치하는 4 Words 블럭 모두를 전달한다.
- 즉, Cache가 메인 메모리에 0x2222_2222를 요청하면, 메인 메모리는 Cache에게 0x1111_1111부터 0x4444_4444까지 4개의 Words를 동시에 Cache에게 전송한다.
2. 1번 연산 이후에, CPU Core가 메인 메모리의 0x000C 위치의 데이터(0x4444_4444)를 요구하는 경우
- 1번 연산을 통해 0x4444_4444 데이터를 이미 Cache가 보유하고 있는 상황이다.
- 그러므로, Cache에서 바로 CPU Core에게 전달할 수 있다.
- 이러한 상황이 Locality를 활용한 성능향상의 한 예시이다.
3. 1번, 2번 연산 이후에, CPU Core가 메인 메모리의 0x0000_1208 위치의 데이터(0x7777_7777)를 요구하는 경우
- 0x7777_7777은 Cache가 메인 메모리로 부터 Load한 이력이 없으므로, 해당 데이터를 메인 메모리에 요청한다.
- 요청을 받은 메인 메모리는 해당 데이터의 Locality Data(0x5555_5555 ~ 0x8888_8888) 모두를 Cache에게 전송한다.
※ Cache는 메인 메모리로부터, CPU가 요청한 1 Word 데이터만 불러오는 것이 아닌, 그 주변의 데이터들도 불러올 확률이 높다 생각하여, 이러한 Locality(주변 데이터)들까지 모두 불러온다.
Access Granularity
- Cache와 메인 메모리 사이에 주고받는 데이터의 크기를 의미한다.
- Cache 라인 단위로 주고 받으며, Cache 라인의 크기는 프로세서 제조사별로 차이가 있다.

1. Temporal Locality (시간 측면에서의 Locality)
- CPU가 특정 메모리 주소에 접근할 경우, 해당 주소는 빠른 시간내에 다시 접근할 확률이 높음을 의미한다.
- Temporal Locality를 활용하여, 가장 최근에 접근했던 데이터는 캐쉬에 저장한다.
2. Spatial Locality (공간 측면에서의 Locality)
- CPU가 특정 메모리 주소에 접근할 경우, 해당 주소 인근의 데이터들에 다시 접근할 확률이 높음을 의미한다.
- Spatial Locality를 활용하여, 캐쉬 블럭을 가져올 때, 여러 Word의 데이터를 가져오게 된다.

- 배열, 변수의 내용을 모두 Cache에 저장했다 가정한다.
- 변수 D가 저장된 메모리를 Loop를 돌며 100회 접근하게 된다. 즉 Cache는 D를 저장해놓으면 99번의 메모리 접근 연산을 하지 않아도 된다. (Temporal Locality 활용)
- Loop를 돌며 배열 A, B, C에 저장된 일련의 데이터들이 차례대로 요청된다. 즉, Cache는 하나의 배열 데이터가 요청된 경우, 일련의 데이터들을 한꺼번에 가져오는 것이 CPU 입장에서 효율적일 것이다. (Spatial Locality 활용)
※ CPU가 추후에 접근할 것이라 생각하는 데이터를 미리 Cache에 저장해 놓는다.

1. Block (Cache Line)
- Cache와 DRAM 사이에 주고받는 데이터의 단위이다.
- 현재 대부분의 PC의 경우, Block의 단위는 64 Bytes이다.
2. Hit
- 프로세서(코어)가 요청한 데이터가 Cache에 존재하는 상황을 의미한다.
- 즉, Hit가 발생한 것은 성능 향상을 의미한다.
Hit Rate : Hit가 일어날 확률
ex) 100회의 메모리 접근 시도 중, 90회는 해당 데이터가 Cache에 존재한 경우, Hit Rate는 90%이다.
Hit Time : Hit가 일어났을 때, Cache에 접근하는 데에 소요되는 시간
3. Miss
- 프로세서(코어)가 요청한 데이터가 Cache에 없는 상황을 의미한다.
- 즉, Miss가 발생한 것은 요청한 데이터를 가져오기 위해 메인 메모리에 접근해야 함을 의미한다.
Miss Rate : Miss가 일어날 확률
ex) 100회의 메모리 접근 시도 중, 90회는 해당 데이터가 Cache에 존재한 경우, Miss Rate는 10%이다.
Miss Penalty : Miss가 발생하여, 하위 레벨 Cache혹은 메인메모리에 접근하는 데에 소요되는 시간
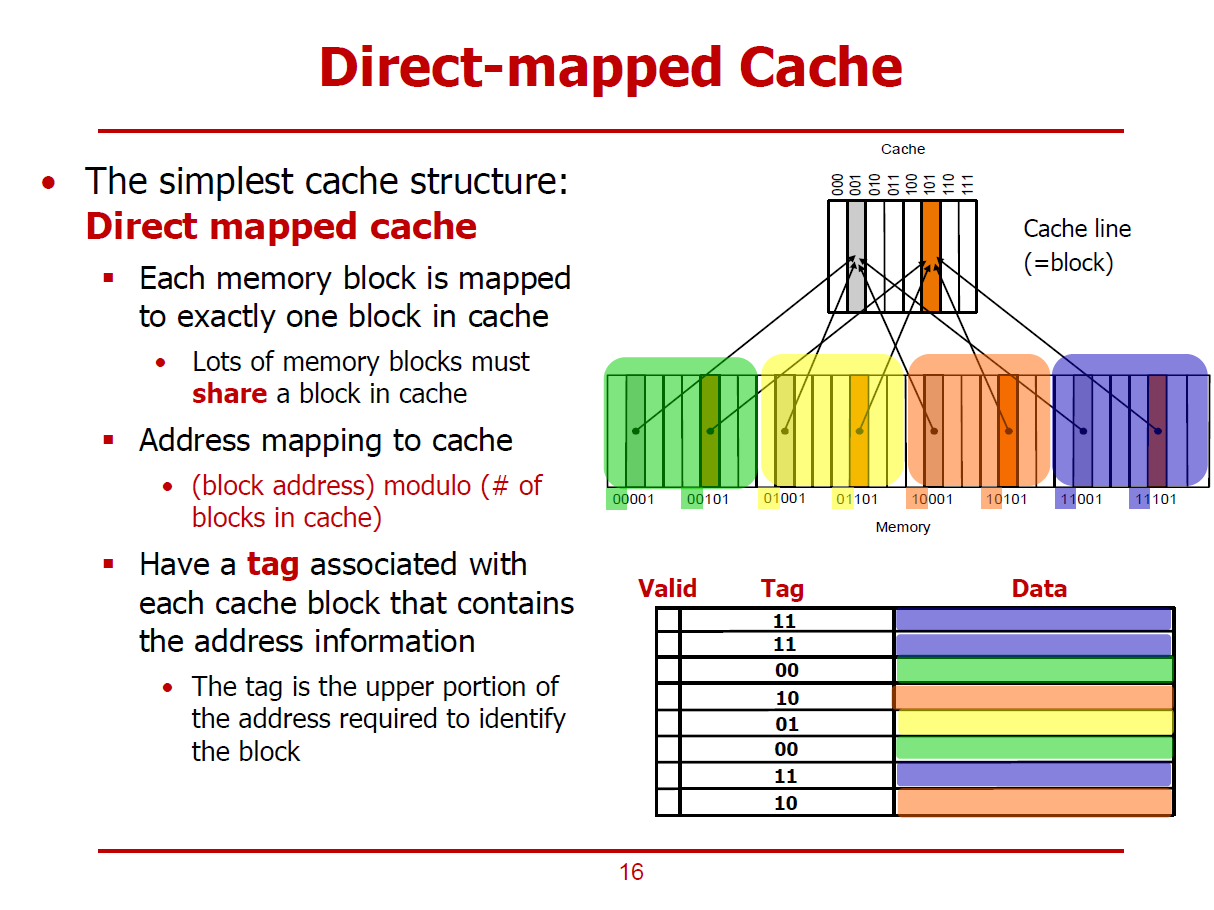
- 어떤 데이터를 어떤 Cache에 저장하며 어떻게 접근해야 할지에 관한 이야기이다.
- 가장 간단한 형태의 Cache를 Direct Mapped Cache라고 한다.
- 메인 메모리의 특정 Block이 저장될 Cache의 위치가 정확히 정해져있는 형태이다.
(메모리가 저장될 Cache 위치가 1대1로 Mapping되어 있는 형태)
- 일반적으로, 각각의 Block은 64 Bytes이며,모든 프로세서에 통용되는것은 아니다.
- Cache의 크기는 메인 메모리보다 클 수 없으므로, 하나 이상의 메인 메모리 블럭이 하나의 Cache Block을 공유한다.
- 그림에서는 각 Memory 블럭들이 주솟값을 기준으로 차례대로 Cache Line에 저장되며, 어떤 메모리 블럭이 마지막 Cache Line에 저장되었다면, 그 다음 메모리 블럭은 다시 처음 Cache Line에 중첩되어 저장되는 것으로 표현했다.
- 즉, 32개의 메모리 블럭과 8개의 Cache Line이 존재할 경우, 하나의 Cache Line에 4개의 메모리 블럭이 저장된다.
- 즉, 메모리 블럭의 하위 3bits 주솟값으로 어느 Cache Line에 저장되는 지를 구분할 수 있다. (Cache Line이 8개로 이루어져 있기 때문이다.)
- 즉, Cache Line의 주소는 메모리 블럭 주소를 8로 나눈 나머지로 계산할 수 있다. (Modulo 연산)
- 또한, Cache에 저장된 각각의 메모리 블럭을 구분짓기 위해, 메모리 블럭의 상위 Bits 또한 Cache에 저장되어야 한다.
(이를 Tag라 부른다.)
- 위 그림에서 001 Cache에는 메모리 블럭의 하위 3bits가 001인 4개의 데이터들이 저장되며, 각각의 데이터들의 Tag(상위 2bits)는 00, 01, 10, 11이다.
- 이외에 Cache를 공유하는 방법으로 Mapping Function을 사용하는 방법 등이 있다.

- 메인 메모리는 기본적으로 Byte-Addressable한 구조이다. (Word-Addressable한 구조는 Byte-Addressable한 구조 위에서 논리적으로 구현된 형태인 것이다.)
- Word-Address는 Byte-Address에서 하위 2bit를 Chopping한 형태이다. (1Word = 4Bytes 이기 때문이다.)
- Block-Address는 Byte-Address에서 하위 6bit를 Chopping한 형태이다. (1Block = 64Bytes 이기 때문이다.)
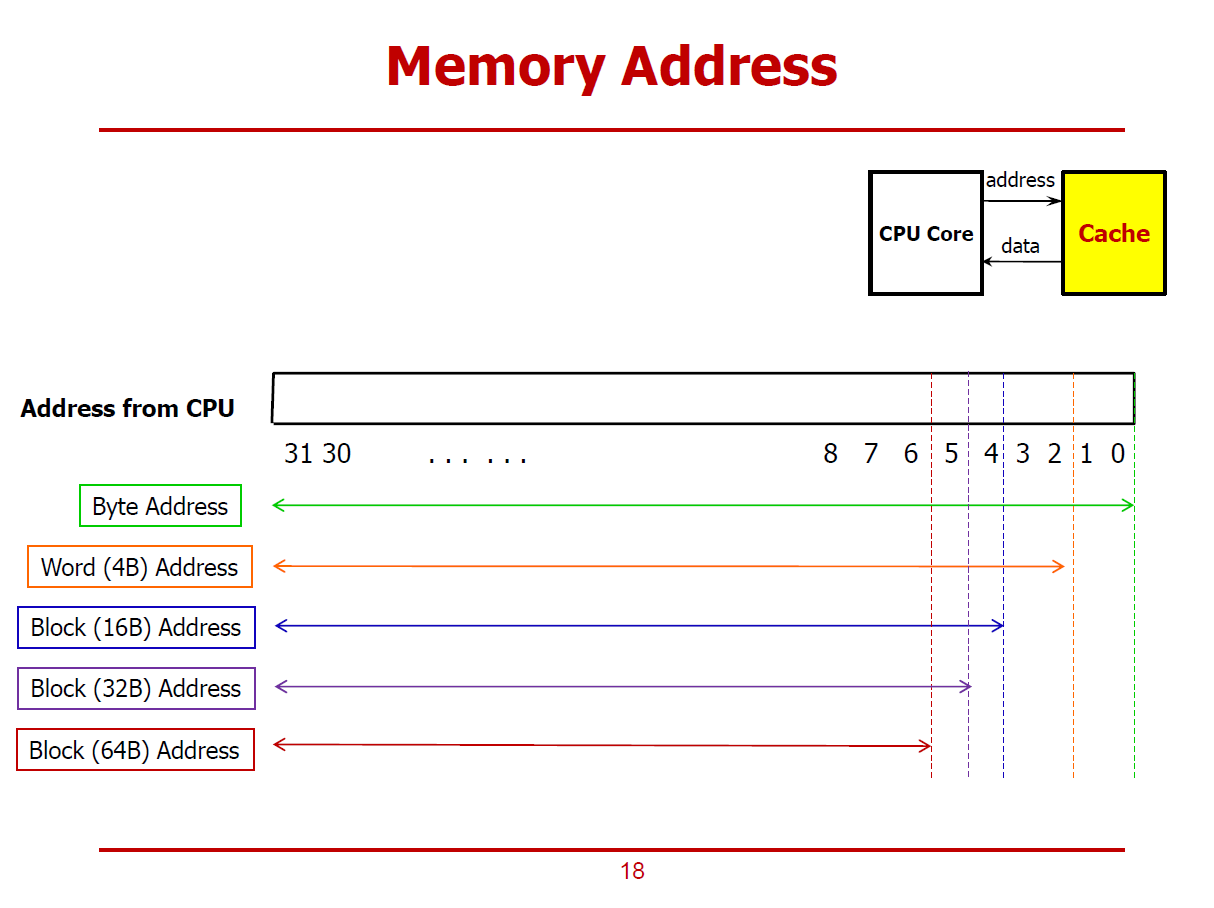
- Addressable한 주솟값의 단위가 커질수록, Chopping되는 하위 bits수를 나타낸 그래프이다.
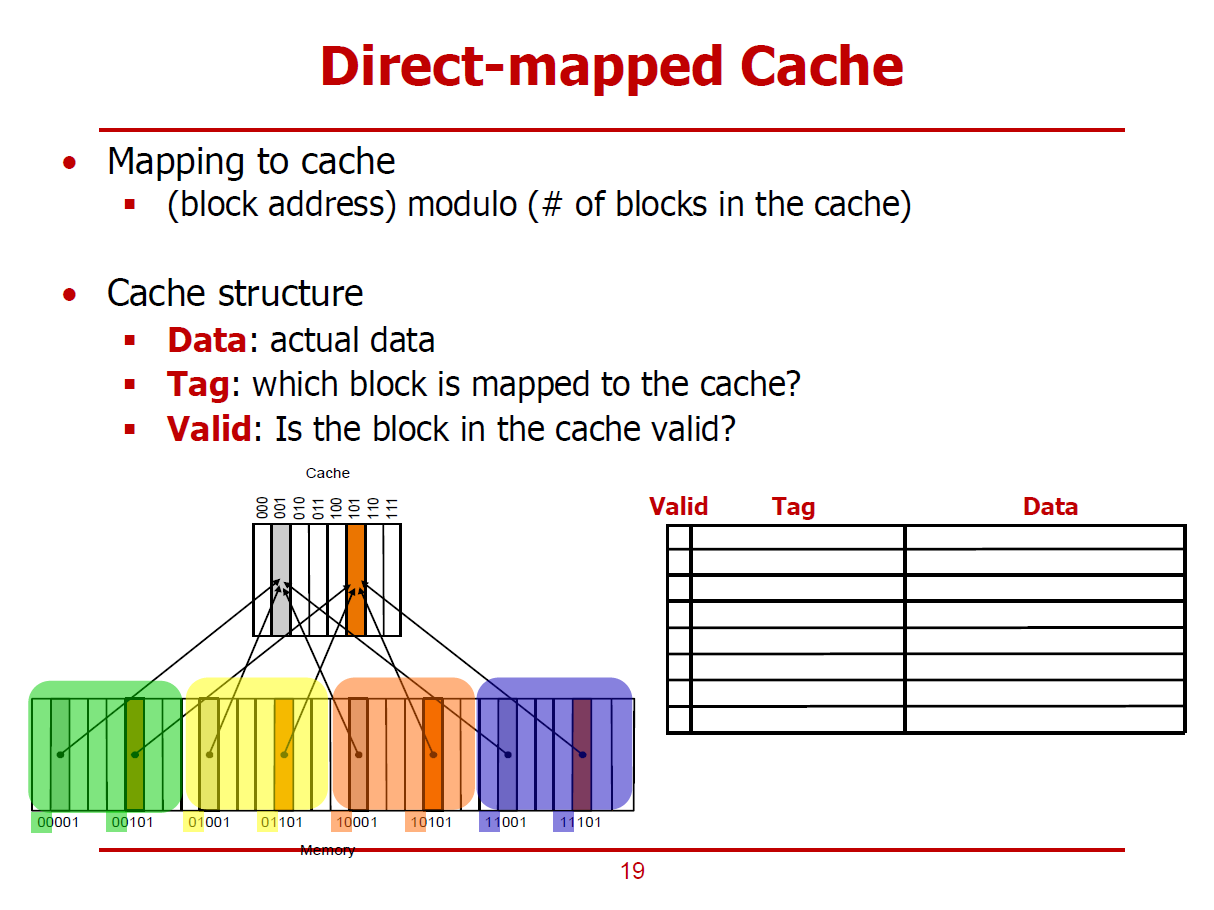
- 메모리 블럭이 속한 Cache 주소 = 메모리 블럭 주소 MOD Cache Line의 개수
(Cache Line의 개수가 2의 거듭제곱 형태라는 가정하에 이루어지는 공식이다.)
Cache Structure
1. Data
- Cache에 저장되는 실제 데이터 값을 의미한다.
2. Tag
- 한 Cache에 저장되어 있는 여러 데이터들을 구분짓기 위한 정보이다.
- 즉, 메모리의 어느 주소와 Mapping 되어 있는가에 대한 정보이다.
3. Valid
- 실제로 Cache와 메모리 사이의 상호작용을 통해 저장된 데이터인지를 구분하는 정보이다.
- 즉, 어떤 요인에 의해 강제로 설정된 쓰레기 값인지 아닌지를 구분하는 정보이다.
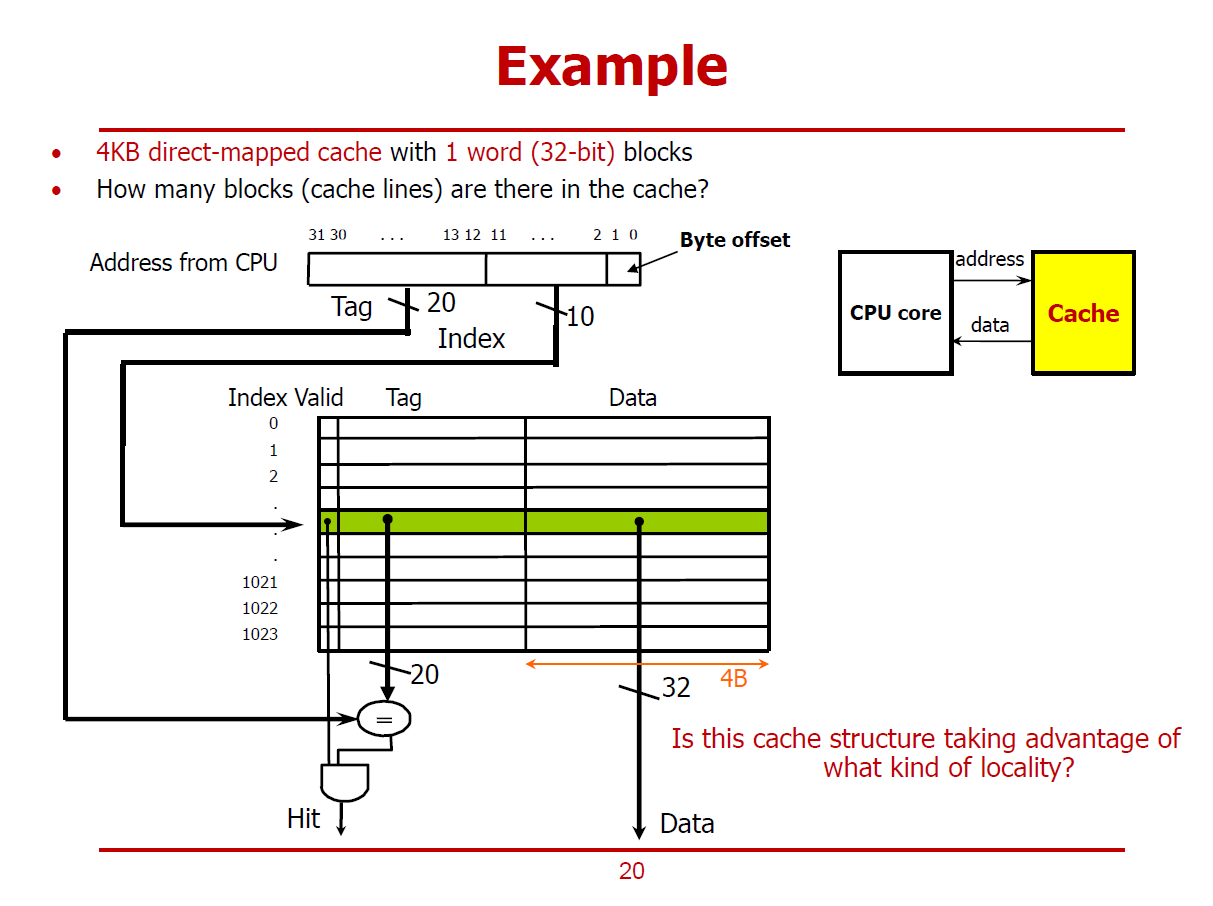
- 4KB 용량을 가진 Cache는 1 Word의 Cache Line들을 가지며, Direct-Mapped Cache 구조로 설계되었다 가정한다.
(즉, Cache와 메인 메모리간에 데이터를 1 Word 단위로 주고받는다.)
- 4KB Cache는 1 Word의 Cache Line이 총 1,024개로 구성되어 있다.
Address from CPU
1. Byte Offset (2bits)
- CPU는 기본적으로 Byte Address를 사용하기 때문에, Word 단위로 Cache에 저장되어 있는 데이터를 Byte로 구분하기 위한 오프셋 값이다.
2. Index (10bits)
- 1,024개의 Cache Line을 구분짓기 위한 값이다.
3. Tag (20bits)
- 하나의 Cache Line에 중첩되어 저장된 여러 데이터 중 하나를 구분짓기 위한 값이다.
- 여기에 더불어, Valid Bit가 1이어야 정상적인 데이터로 간주된다.
※ 이 예시는 Temporal Locality를 활용한 방법이다.
- CPU가 Cache에게 하나의 Word를 요청했으며, Cache는 메인 메모리로 부터 하나의 Word를 가져왔다.
- 메인 메모리로부터 여러 데이터를 가져오지 않았다는 점에서 Spatial Locality가 있다고 보기 어렵다.

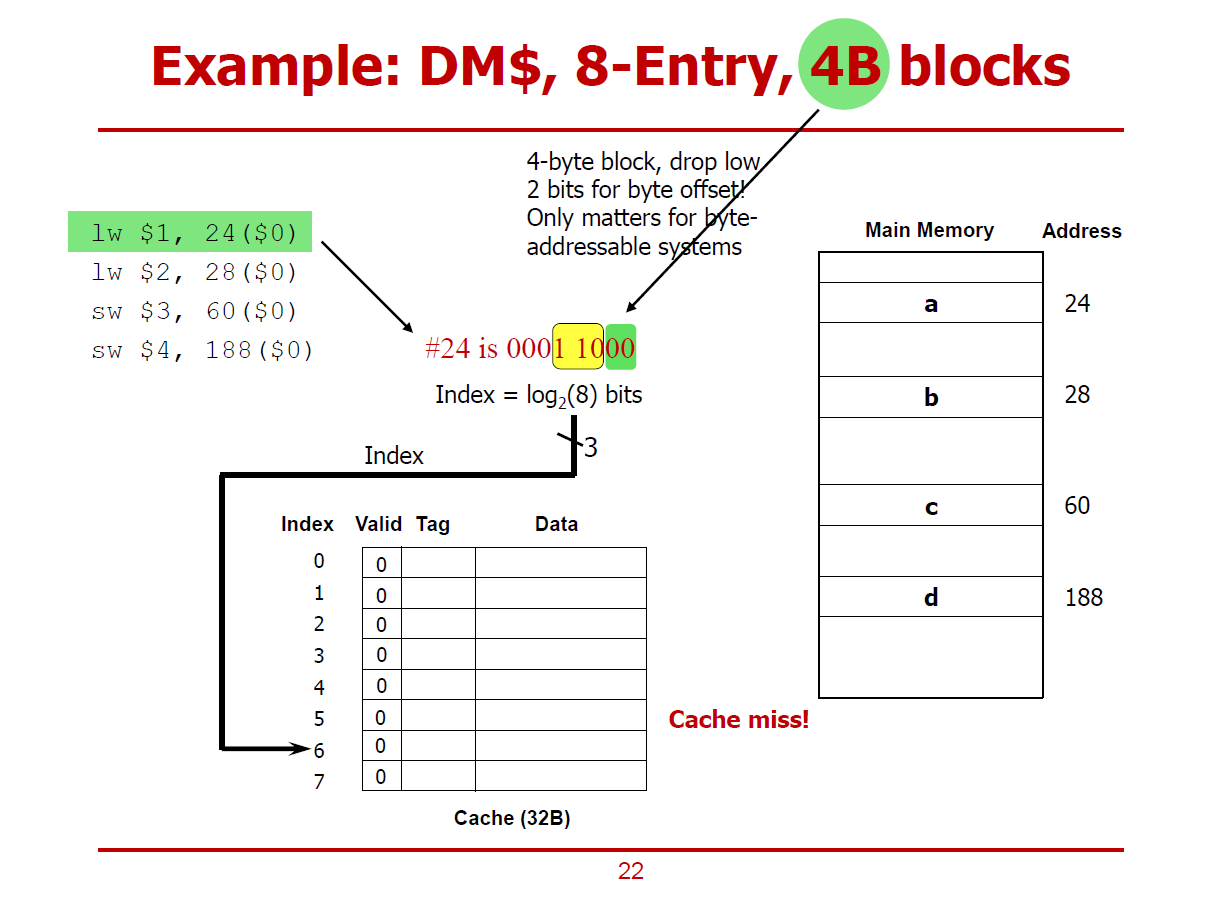
- 하위 2bits 데이터 00을 통해 Byte-Address를 구분한다.
- 그 다음 3 bits 데이터 110(6)을 통해 Cache Line을 구분한다.
- 최상위 3bits 데이터 000을 통해 Tag를 구분한다.
- 그러나, 여기서 Valid 비트가 0이므로 Cache Miss가 발생했으므로, 메인 메모리에 직접 접근해야 한다.
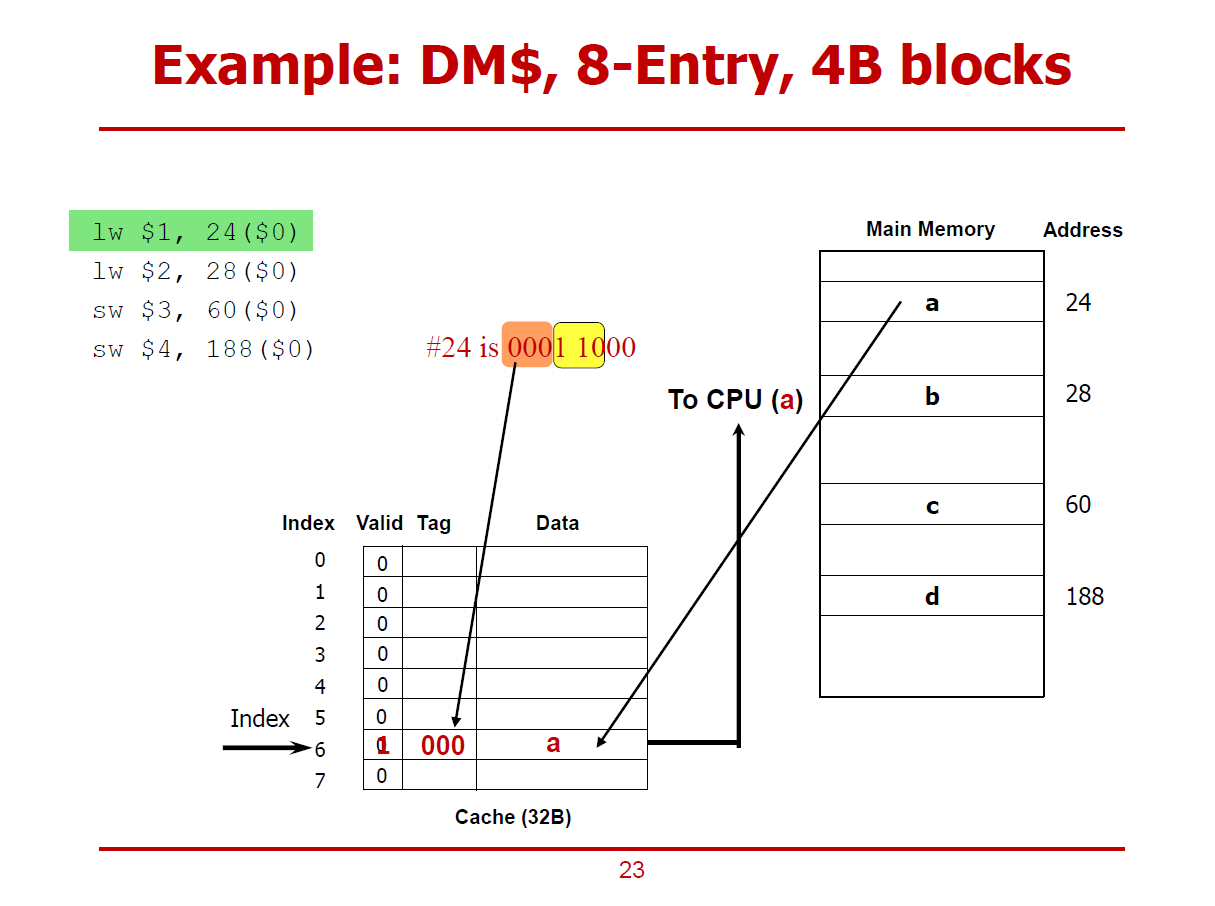
- 메인 메모리의 0001 1000(24)에 해당되는 값(a)을 Cache에 적절히 저장한다.
- 저장한 이후, Valid Bit를 1로 설정하여 유효한 값임을 표시한다.
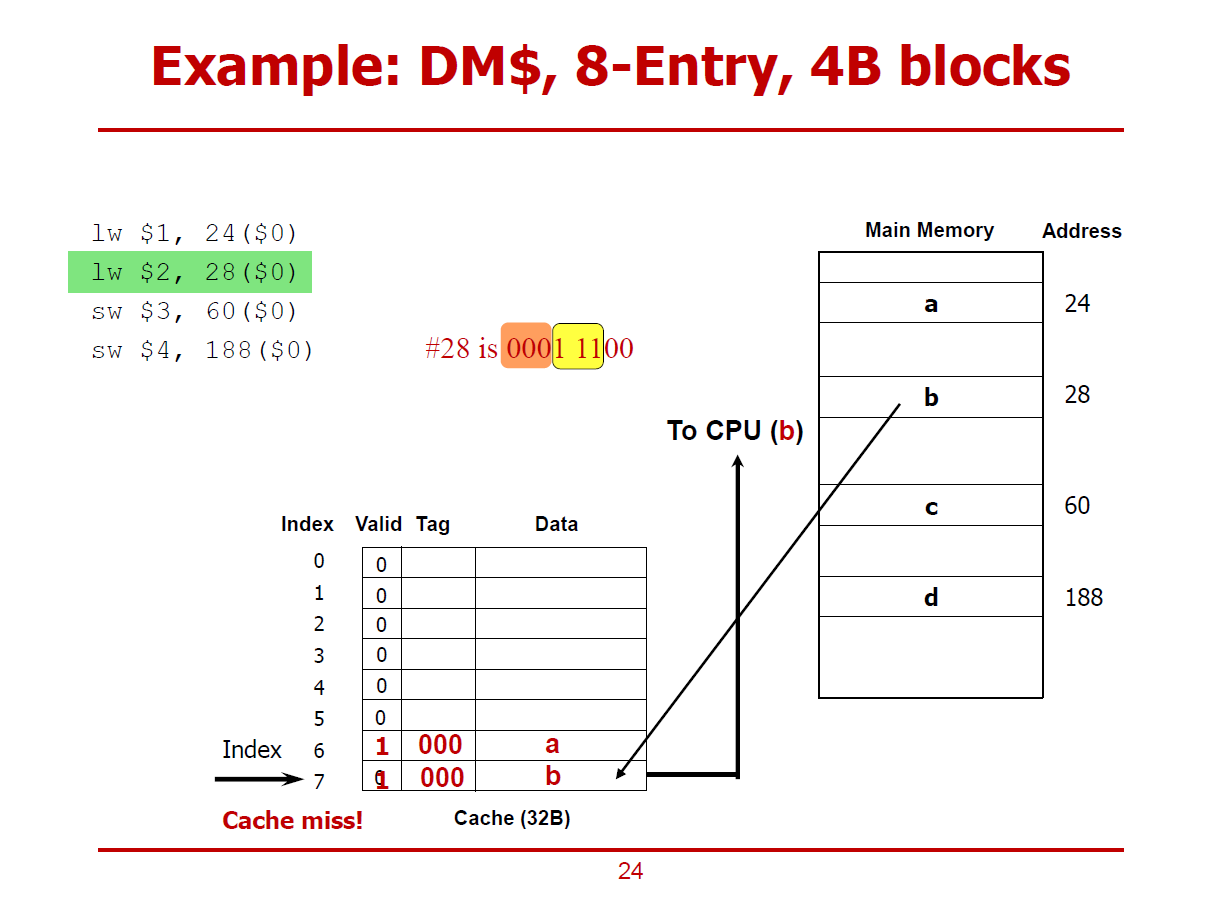
- 메모리의 28 Offset에 해당되는 데이터가 Cache Miss된 이후, Cache에 저장되는 절차이다.

- 베이스 주소($0)으로 부터 60번째 데이터가 먼저 Cache에 저장되어 있는가를 확인하는 절차이다.
- 60은 001 111 00이며, Tag = 001, Cache Line = 111, Byte-Address = 00이다.
- 검색 결과, Valid Bit가 1이지만, Tag가 일치하지 않아, Cache Miss인 상황이다.
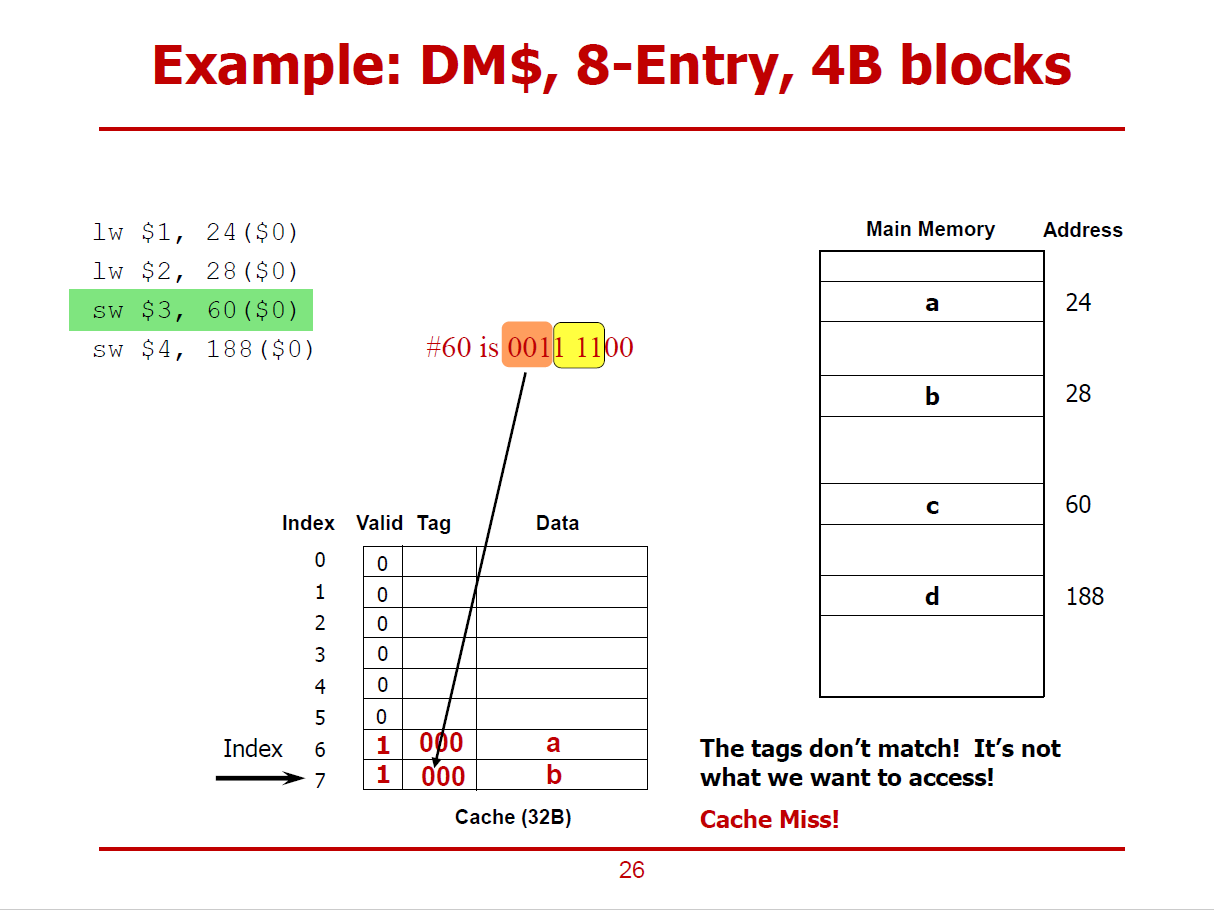
- 검색 결과, Valid Bit가 1이긴 하지만, Tag가 일치하지 않아, Cache Miss인 상황이다.
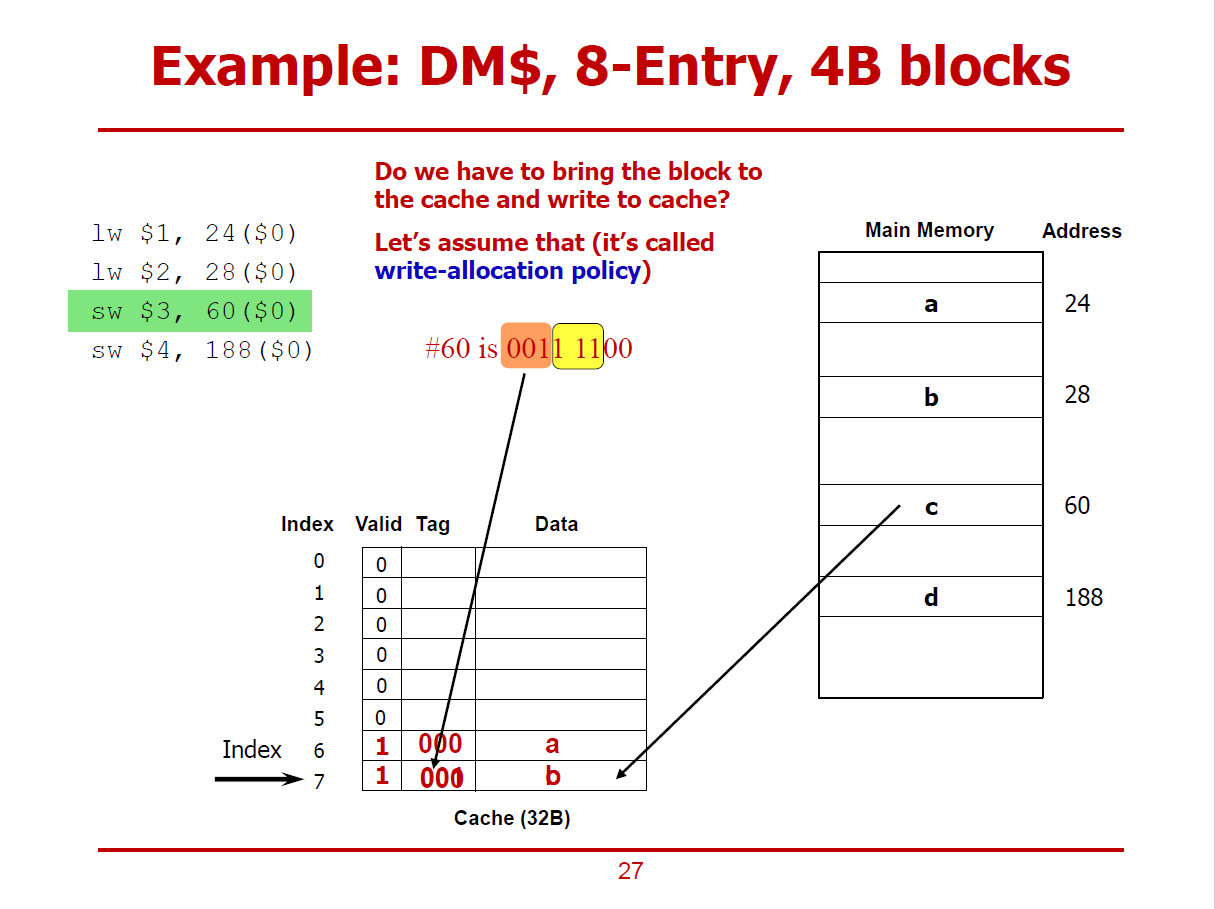
- Cache Miss가 발생한 이후, c에 해당되는 데이터가 Cache에 덮어쓰여지게 된다.
(Write-Allocation Policy 하에 이루어지는 동작이다.)

- Cache에는 3번 레지스터의 값으로 새로 바뀌었다. (sw명령어임을 상기하자)
- 이제 Cache의 값을 메인 메모리에다 써야한다.
- 아직까진, 메인 메모리에는 c 값이 위치하고 있다.
- 즉, Cache의 값과 메인 메모리 값이 다른 상황이다.
- 이렇게 값이 다른 상황에서 메인 메모리의 값을 Update하는 것을 미루는 것을 Write-Back이라 표현한다.
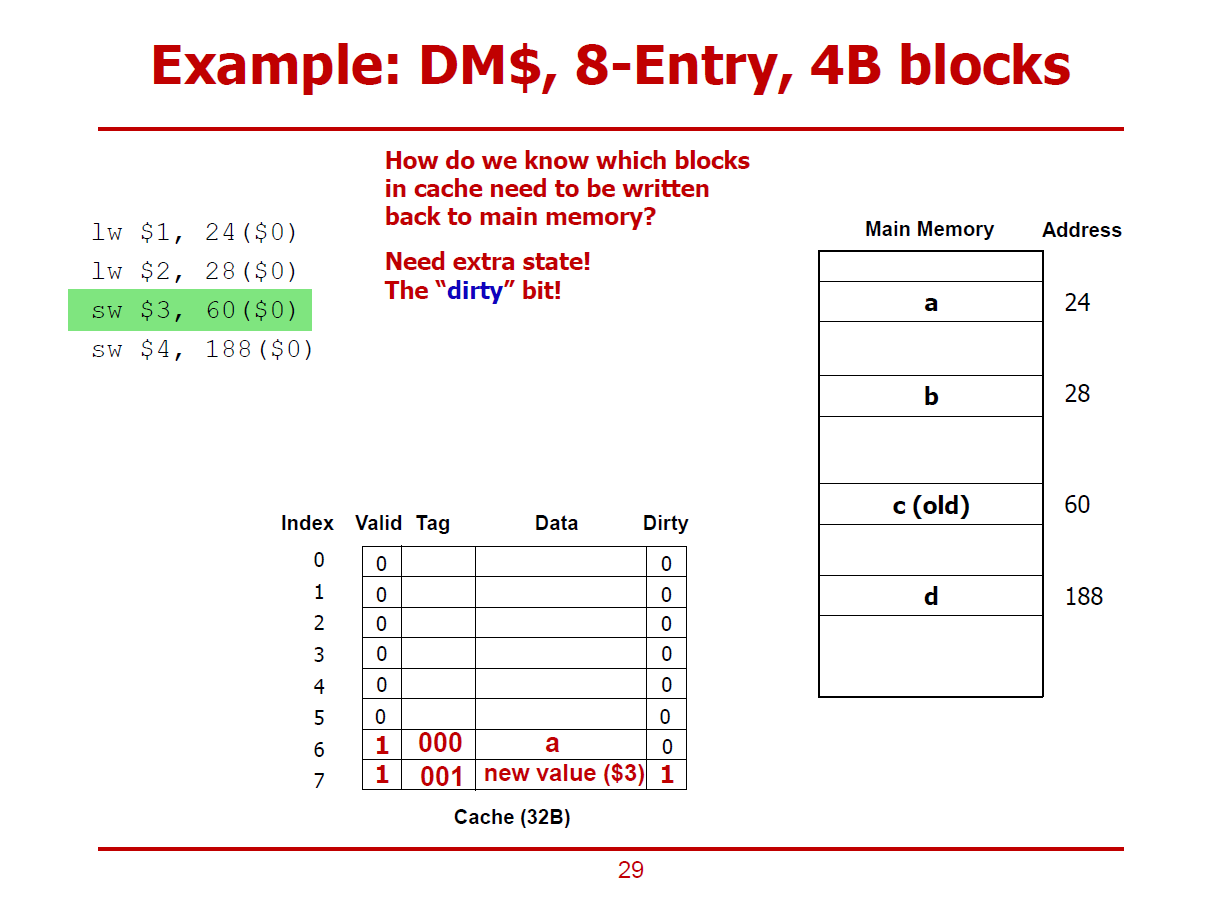
- Write-Back Cache 구조에서는 Dirty Bit 구조를 필요로 한다.
- Dirty Bit는 Cache값은 Update 되었으나, 메인 메모리에는 아직 쓰지 않은 상태인 경우 1로 설정된다.
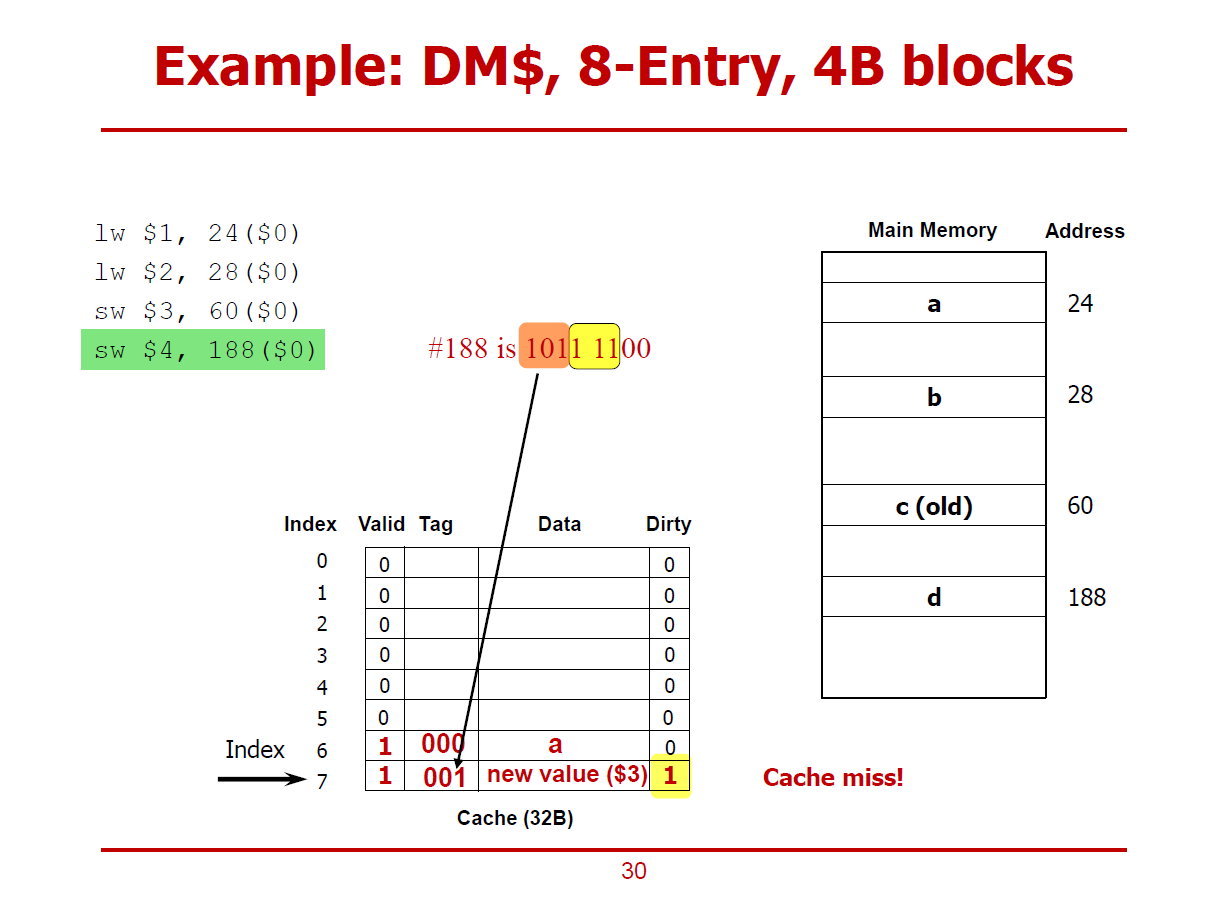
- 새로운 명령어 (188 Offset에 저장하는 sw명령어)를 실행하는 과정이다.
- 마찬가지로, 111(7)에 해당되는 Cache Line의 Valid bit는 1이나, Tag가 서로 다르므로 Cache Miss가 일어난 상황이다.
- 단, 해당 Cache Line의 Dirty Bit가 1이므로, 기존의 데이터를 올바른 메인 메모리 주소(60)에 저장하고 나서 188 Offset에 해당되는 값을 Cache에 저장하게 된다. (Write-Allocation 방법)

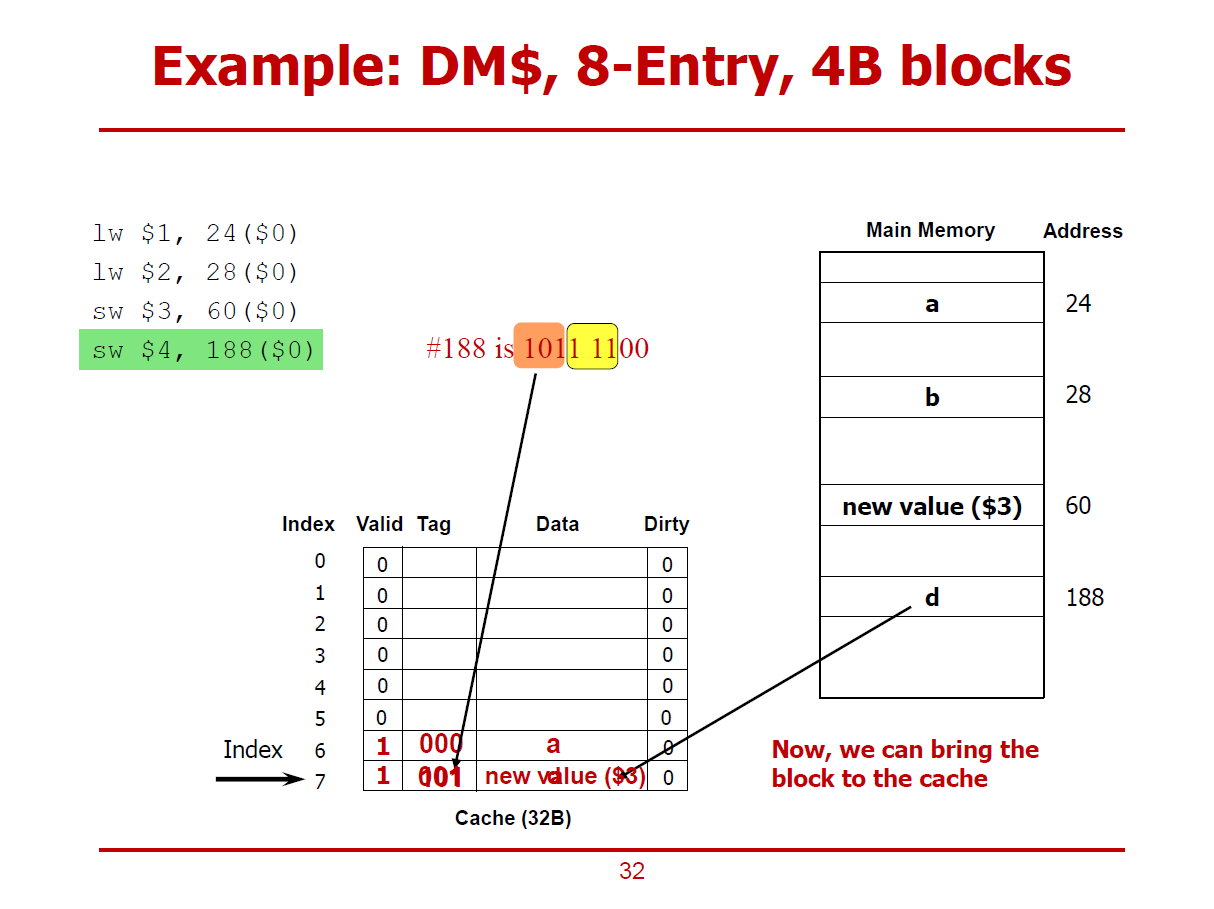
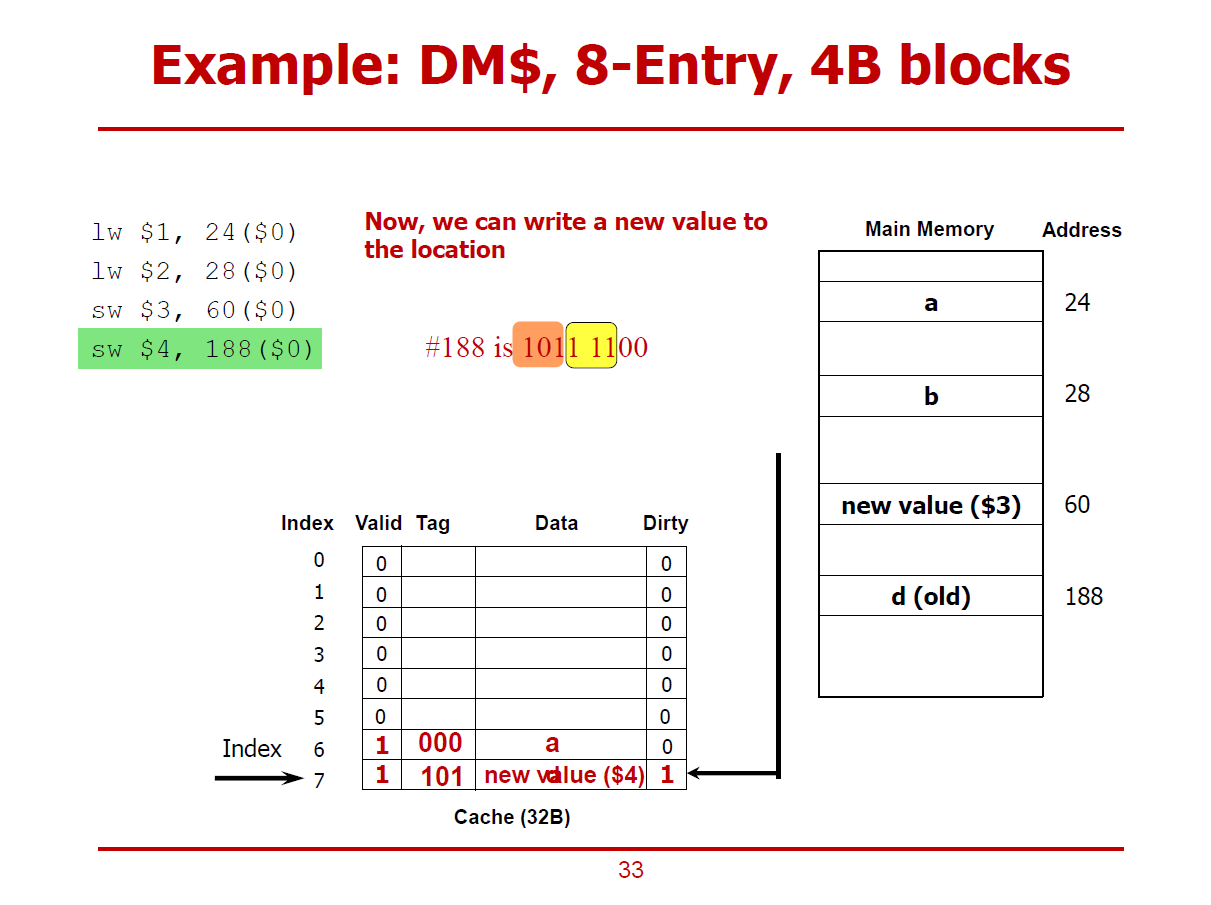

- Write-Allocation, Write-Back에 관한 내용이다.
- Cache Hit중, CPU가 읽고자하는 데이터가 Cache에 존재하는 상황을 Read-Hit이라 하고, CPU가 메인 메모리에 쓰고자 하는 데이터가 이미 Cache로 옮겨와 있는 상황을 Write_Hit라 한다.
(Read-Miss, Write_Miss또한 위와 같은 맥락으로 해석할 수 있다.)
- CPU가 Cache에서 데이터를 읽을 때, Read-Hit 혹은 Read-Miss가 발생하게 된다.
- Read-Hit의 경우, CPU가 Cache에서 데이터를 읽어오게 된다.
- Read-Miss의 경우, CPU가 원하는 데이터가 Cache에 없는 상황이므로, 메인 메모리에서 원하는 데이터가 포함되어있는 Cache Line을 Cache에게 저장한 후, Cache에서 CPU에 데이터가 전달된다.
- Write-Miss의 경우, Write-Allocation을 진행할 수도 있고, Write No Allocation을 진행할 수도 있다.
1. Write Allocation
- 메인 메모리에서 원하는 데이터가 속한 Cache Line을 Cache로 옮기고. CPU가 Cache에 접근하여 데이터를 가져가는 작업이다.
2. Write No Allocation
- CPU가 메인 메모리에 원하는 데이터를 직접 요청하는 작업이다.
- Cache에 데이터를 쓰는 경우, Write-Back을 진행할 수도 있고, Write-Through를 진행할 수도 있다.
1. Write-Back
- Cache에는 값을 쓰지만, 하위 레벨 Cache나 메인 메모리에는 당장 값을 쓰지 않는 형태의 작업이다.
- Cache에 쓴 값이 추후에 하위 레벨 Cache나 메인 메모리에 저장해야 될 때 비로소 값을 옮기게 된다.
2. Write-Through
- Cache에 Update하는 동시에 메인 메모리에도 값을 쓰는 형태의 작업이다.
※ 일반적으로, Write-Allocation은 Write-Back과 함께 쓰인다.
※ 일반적으로, Write No-Allocation은 Write-Through와 함께 쓰인다.
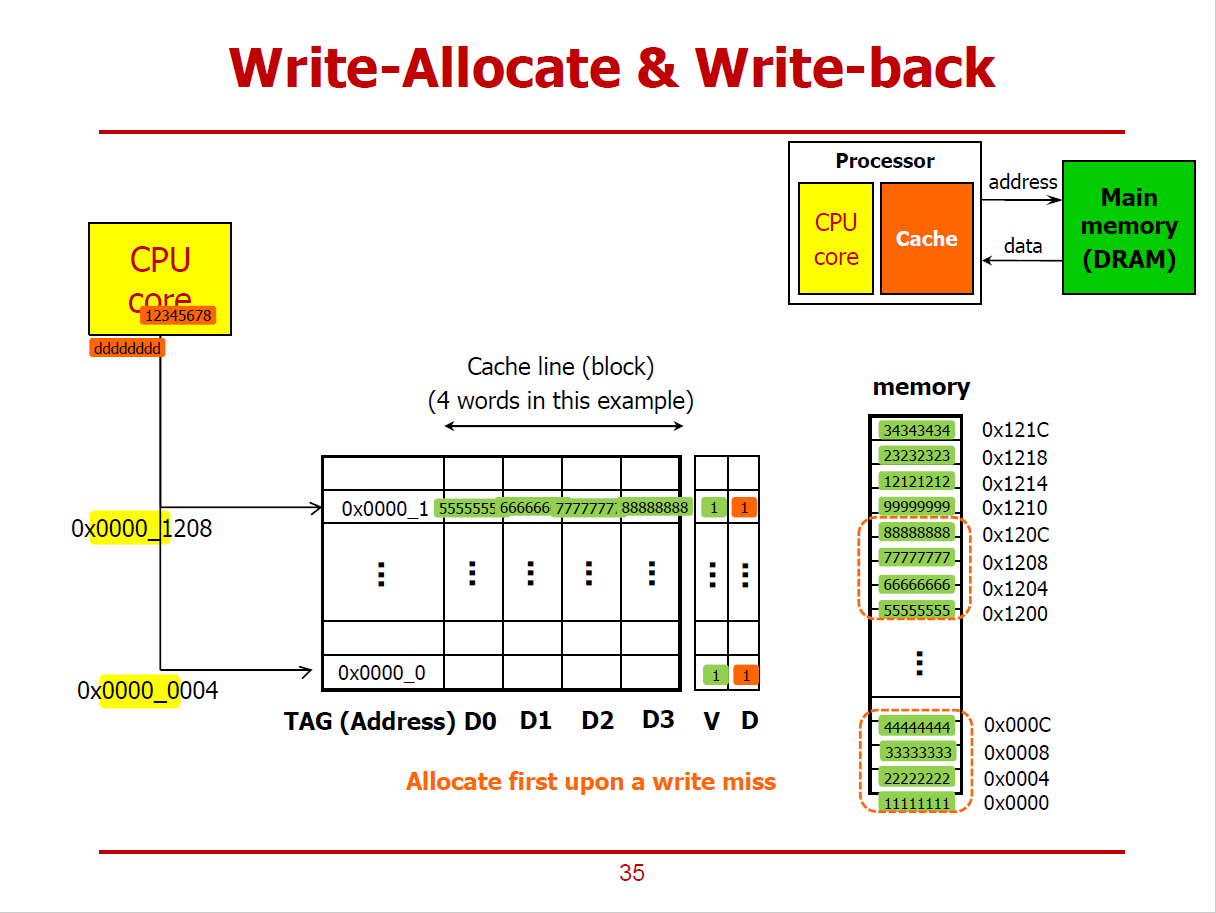
- Write-Allocation과 Write-Back 방식으로 진행되는 예시이다.
- 즉, 원하는 데이터를 메인 메모리에서 Cache로 가져오고난 후에 CPU가 Cache에 접근하여 데이터를 처리하는 방식이다.
- 또한, Cache에 데이터를 쓴 후, 해당 데이터를 옮겨야 할 상황이 발생하면 하위 레벨 Cache나 메인 메모리에 데이터를 쓰는 방식이다. (Cache가 Update되는 즉시, 하위 메모리에 옮기지 않는다.)
1. Cache Hit 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_1208이다.
- 즉, 메인 메모리의 7777 7777값 대신 새로운 값을 쓰고자 하는 것이다.
- 해당 위치에 CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니 Tag와 Index가 일치하여 Cache Hit가 발생했다.
(즉, 새로 쓸 위치에 해당되는 기존의 데이터(7777_7777)가 이미 Cache에 저장되어 있었다.)
- Write-Back Policy로 진행되기 때문에, CPU는 Cache에만 데이터를 새로 쓴 상태(Cache에는 7777_7777대신 1234_5678이 저장된 상태)이며, 메인 메모리에는 여전히 7777_7777이 저장되어 있는 상황이다.
- 메인 메모리에는 아직 옮기지 않았으므로, 해당 데이터가 속한 Cache Line의 Dirty Bit값은 1로 설정된다.
2. Cache Miss 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_0004이다.
- 즉, 메인 메모리의 2222 2222값 대신 새로운 값을 쓰고자 하는 것이다.
- CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니, 2222_2222 데이터에 해당되는 Tag와 Index가 존재하지 않아 Cache Miss가 발생했다.
- Write Allocation 방법을 통해 메인 메모리로부터 Cache로 데이터를 먼저 옮기고 난 후에 CPU가 Cache에서 해당 데이터를 가져가게 된다.
- 즉, 2222_2222 데이터가 속한 Cache Line(1111_1111부터 4444_4444까지의 데이터들)이 모두 Cache에 저장된다.
- CPU는 Cache의 2222_2222가 위치한 곳에 2222_2222 대신 dddd_dddd를 저장한다.
- 그러나 Write_Back 정책에 의해, 메인 메모리에는 반영하지 않고, Dirty Bit를 1로 설정하는 것으로 마무리한다.
- 즉, dddd_dddd가 Replacement되기 전까지는(Dirty Bit가 1로 설정된 시간동안에는) Cache가 메인 메모리에서 같은 주소에 저장하고 있는 값이 다르다.
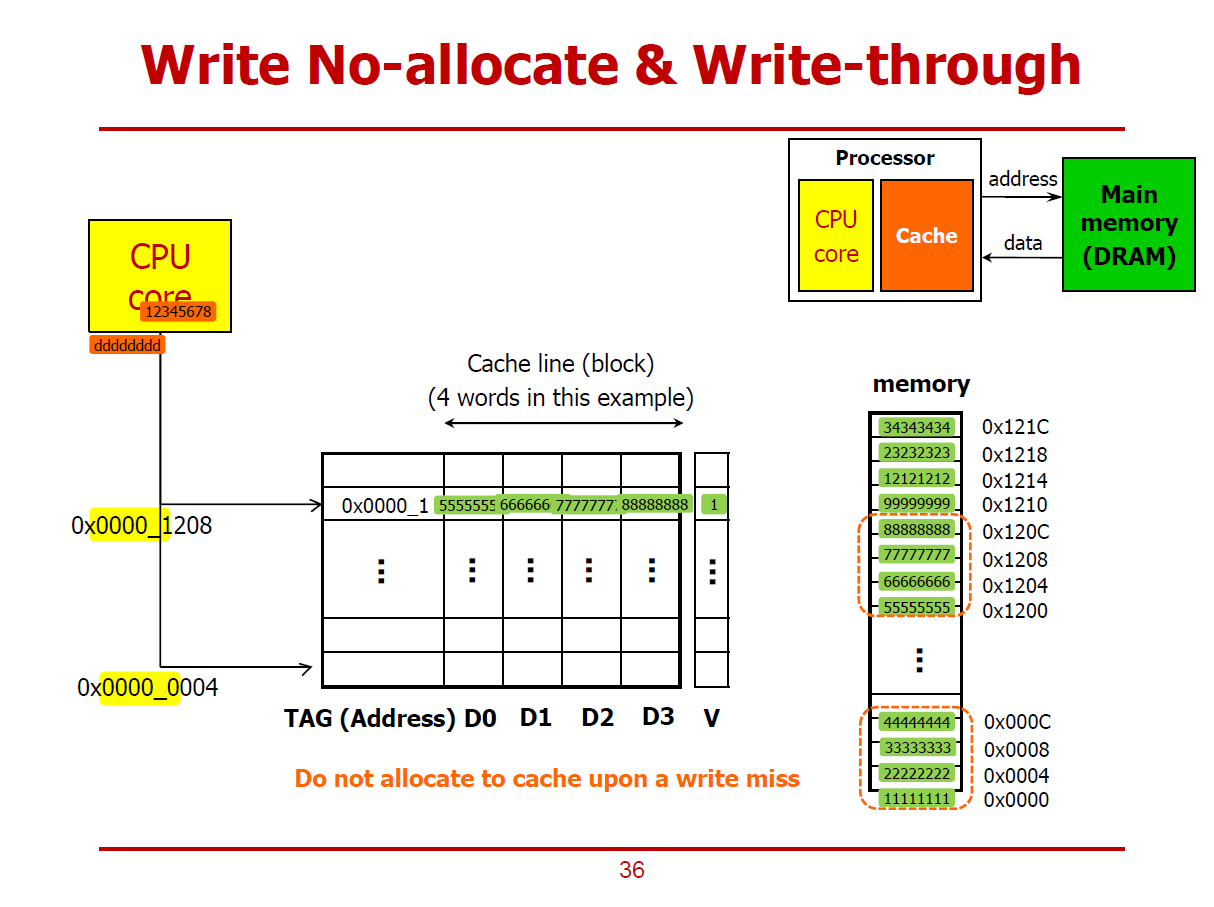
- 35페이지와 동일한 쓰기 동작을 Write No-Allocation과 Write-Through 방식으로 진행하는 예시이다.
1. Cache Hit 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_1208이다.
- 즉, 메인 메모리의 7777 7777값 대신 새로운 값을 쓰고자 하는 것이다.
- 해당 위치에 CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니 Tag와 Index가 일치하여 Cache Hit가 발생했다.
(즉, 새로 쓸 위치에 해당되는 기존의 데이터(7777_7777)가 이미 Cache에 저장되어 있었다.)
- Write-Through Policy로 진행되기 때문에, CPU는 Cache에 데이터를 새로 쓰는 동시에, 해당 메모리 위치에도 값을 저장하여 동기화시키는 상황이다.
- Cache에 값을 저장함과 동시에 메인 메모리에도 저장하므로 Dirty Bit를 필요로하지 않는다.
- Cache와 함께 메인 메모리도 동시에 Update하는 방식을 Write-Through라고 한다.
2. Cache Miss 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_0004이다.
- 즉, 메인 메모리의 2222 2222값 대신 새로운 값을 쓰고자 하는 것이다.
- CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니, 2222_2222 데이터에 해당되는 Tag와 Index가 존재하지 않아 Cache Miss가 발생했다.
- Write No-Allocation 방법을 통해 데이터를 Cache를 거치지 않고, 곧바로 메인 메모리에까지 데이터를 저장한다., 굳이 Cache에까지 데이터를 할당(저장)하지 않는다.(No-Allocation)
- 즉, 데이터 dddd_dddd가 메모리의 0x0000_0004 위치에 곧바로 저장된다.
※ Write No-Allocation & Write-Through 방식에서는 Cache와 메인 메모리의 값들이 서로 동기화되어 있다. (다르지 않다.)

- Cache에는 읽기/쓰기 동작이 수행될 수 있다.
- CPU가 다루고자 하는 값이 Cache에 존재하면 Hit, 그렇지 않으면 Miss이다.
1. Read Hit
- CPU가 읽고자하는 값이 Cache에 이미 저장되어 있는 상황이다.
2. Read Miss
- CPU가 읽고자하는 값이 Cache에 있지 않는 상황이다.
- 메인 메모리로부터 데이터를 읽어오기 위해 CPU Core를 잠시 중단한다.
- 원하는 데이터가 속한 Cache Line을 메인 메모리로부터 Cache로 가져온다.
- 그 이후, CPU가 원하는 데이터 (Cache Line을 구성하는 데이터 중 하나)를 Cache에서 CPU로 넘기고 나서야 CPU Core가 다시 가동된다.
- 즉, 메인 메모리에서 Cache로 데이터를 옮기면서, CPU Core가 중단되는 성능 저하가 일어나게 된다.
3. Write Hit
- CPU가 쓰고자하는 값이 Cache에 이미 저장되어 있는 상황이다.
1) Write-Through 방식: 데이터 쓰기 동작을 Cache에도 진행하며, 메인 메모리에도 진행하는 방식이다.
- Cache와 메인 메모리가 항상 Synchronization되어 있는 형태라 관리하기에 용이하다.
- 그러나, 항상 Cache와 메인 메모리에 동시에 쓰기 연산을 수행하므로, 에너지/성능 측면에서의 손실이 발생한다.
2) Write-Back 방식: 데이터 쓰기 동작을 Cache에만 진행하며, Replacement가 발생하기 전까지 데이터를 메인 메모리에 옮기지 않는다.
4. Write Miss
- CPU가 쓰고자하는 값이(메모리 주소가) Cache에 없는 상황이다.
1) Write-Allocate with Write-Back
- CPU가 쓰고자하는 값(메모리 주소)을 메인 메모리로부터 Cache로 불러온다. (Write-Allocate 방식)
- CPU가 Cache에 값을 쓴 후, 곧바로 메인 메모리에 반영하지 않고, Replacement가 발생하면 그제서야 메인 메모리에 반영시킨다. (Write-Back)
2) Write No-Allocate with Write-Through
- CPU가 쓰고자하는 값(메모리 주소)을 메인 메모리에서 바로 불러온다. (Write No-Allocate 방식)
- 즉, 데이터가 메인 메모리에만 반영되며, 이 과정에서 Cache는 개입되지 않는다.
- CPU가 Cache에 값을 쓴 후, 곧바로 Cache에서 메인 메모리에 반영한다. (Write-Through 방식)
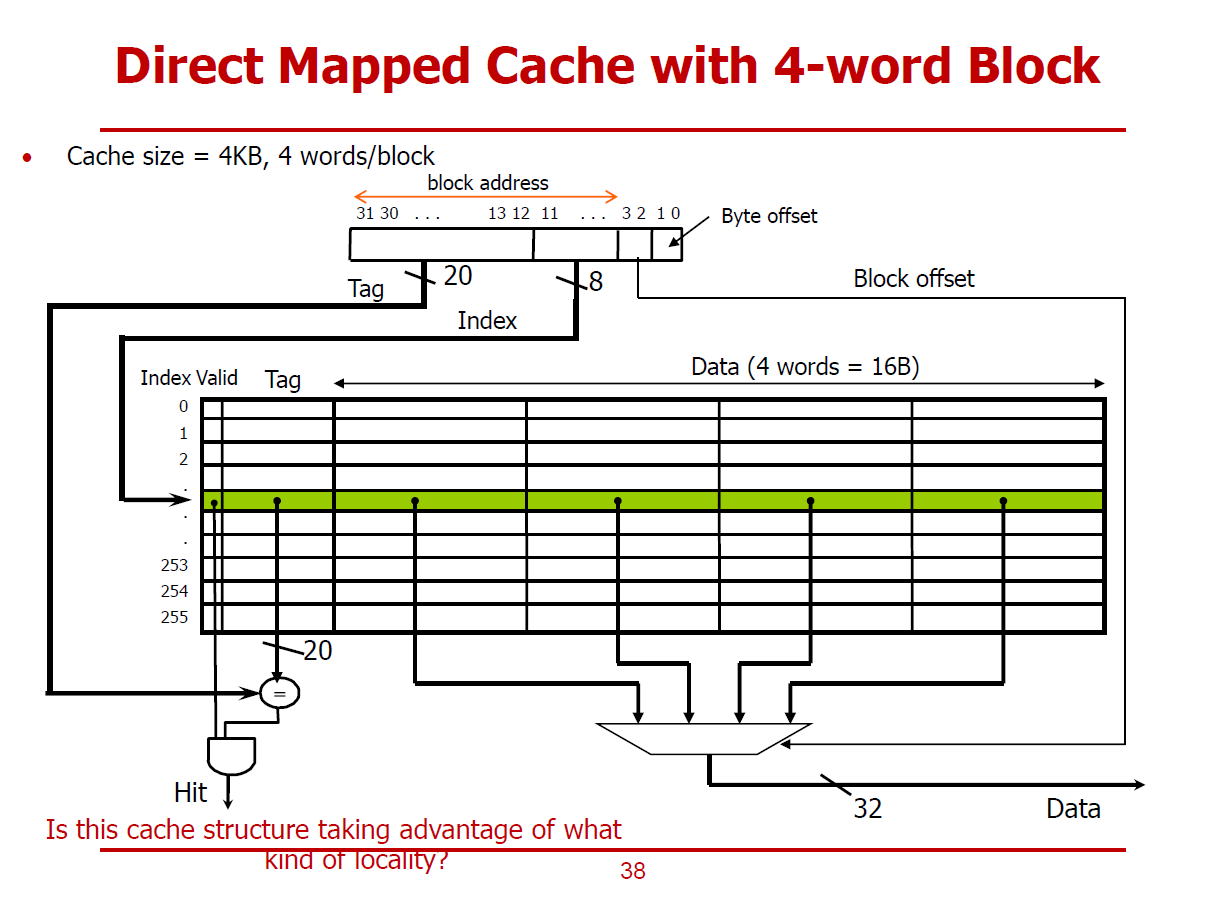
- 4-Word Block : 하나의 Cache Block(Cache Line)이 4 Word로 구성되어 있는 형태를 의미한다.
- 또한, 전체 Cache 크기는 4KB라 가정한다.
- 32bits 메모리 주소 중, 상위 28bits는 Cache Block을 구분짓게 하는 Block Address가 된다.
(Tag[31:12] 20bits, Index[11:4] 8bits)
- 즉, 4 Word(16 Bytes)를 구분짓기 위해 4 bits(\(2^4=16\))가 필요한 것이다.
- Cache Line의 수(엔트리 개수)는 256개로 구성된다. (16Bytes * 256 = 4,096Bytes = 4KB)
- 즉, Index[11:4] 8bits로 엔트리를 구분지을 수 있다.
- Tag[31:12] 20bits는 주소의 역할을 한다. (Cache의 주소인 동시에, 메인 메모리 주소)
(Hit, Miss 여부는 Tag Comparison과 Valid Bit Check를 통해 알아낼 수 있는 것이다.)
- 하나의 Cache Line에 위치한 4개의 Word중, CPU가 원하는 4Bytes 데이터를 구분짓기 위해 Block Offset[3:2] 2bits를 사용하여, 4개의 Word 중 하나를 선정한다.
- 위와 같은 과정을 통해 선정된 하나의 Word 데이터가 CPU로 향하게 된다.
- 선정된 하나의 Word 중 하나의 Byte를 선정하기 위해 Byte Offset[1:0] 2bits를 사용할 수도 있다.
(Byte Addressable한 접근이 필요한 경우)
※ 위 그림의 Direct Mapped Cache는 Temporal Locality와 Spatial Locality를 모두 활용하고 있다.
- 요청한 Word를 Cache에 보관한다는 측면에서 Temporal Locality를 활용한다고 볼 수 있다.
- 요청한 Word뿐만 아니라, 주변의 3개의 Word 또한 가져오게 되므로 Spatial Locality를 활용한다고도 볼 수 있다.
- Block의 크기가 클 수록 Spatial Locality를 극대화하기 유리하다. (더 많은 주변 데이터를 가져올 수 있기 때문이다.)
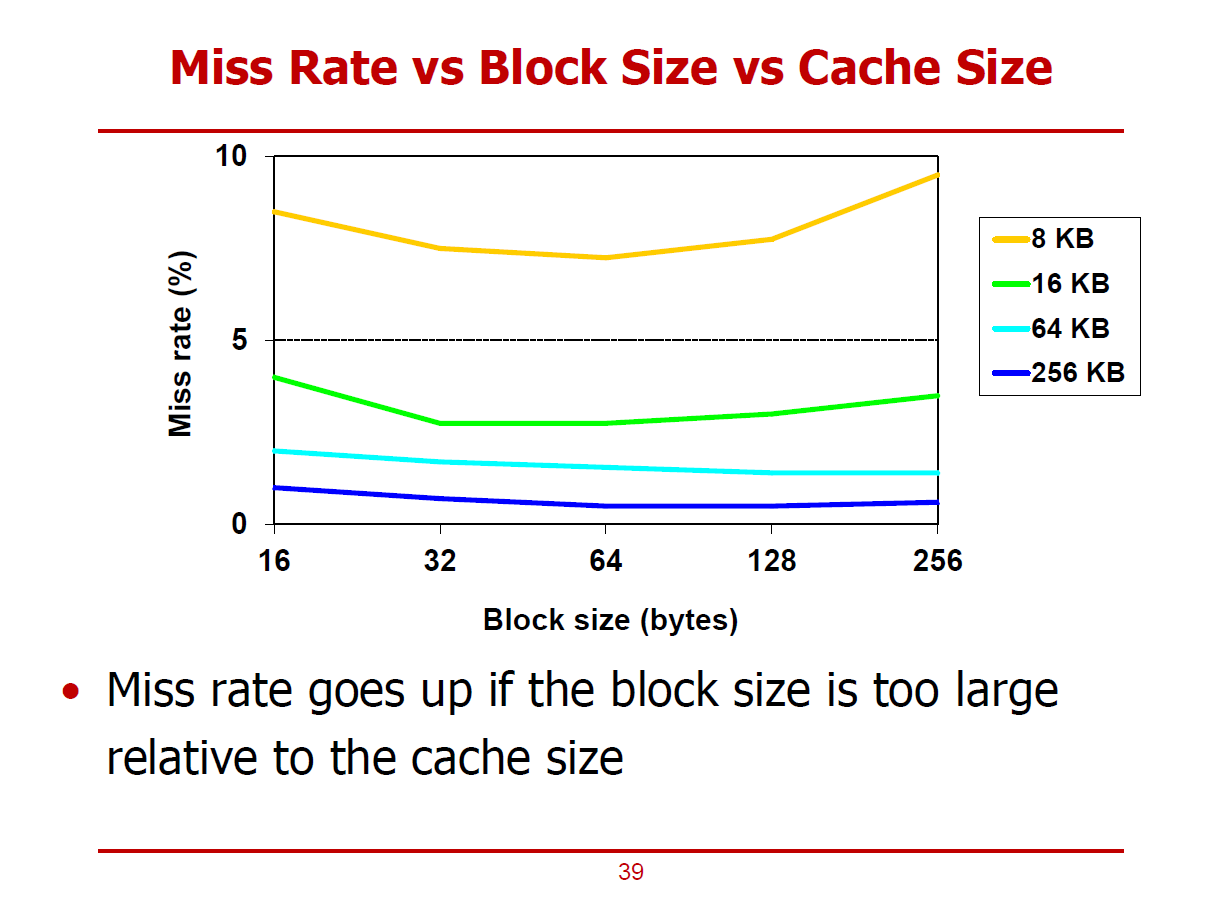
- Block Size에 따른 Miss Rate 변화 그래프이다.
- Legend에서의 8KB ~ 256KB는 Cache의 전체 크기를 의미한다.
- 8KB 수준의 작은 Cache에서는 Block의 크기가 증가함에 따라 Miss Rate이 상승됨을 볼 수 있다.
- Block 크기가 커질수록 Cache Line의 개수는 줄어들게 되어 다른 Cache Line을 가져올 기회를 뺏는 것이기 때문이다.
- 그러므로, Block Size를 적절히 설정하는 것이 중요하다.
- 근래에 빅 데이터를 다루게 되면서 Locality가 저하됨이 발견되어 Block Size를 줄이는 것도 고려중에 있다.

- 16KB Direct Mapped Data Cache를 설계한다 가정하자.
- 하나의 Cache Line(Data)은 4 Words로 구성되어 있으며, MIPS와 같은 32bits 주소 체계를 갖고 있다.
- Cache의 총 크기는 16KB이며, 한 Cache Line의 크기는 16Bytes이므로, Cache Line(엔트리)의 개수는 1,024개 이다.
- 4개의 Word를 구분하기 위해 Block Offset[3:2] 2bits를 이용한다.
- 1,024개의 Cache Line을 구분하기 위해 Index[13:4] 10bits를 이용한다.
- Tag는 18bits로, Dirty Bit는 1 bit, Valid Bit는1bit로 구성된다.
- 즉, 하나의 Cache Line에는 Data를 위한 4 Word 이외에 20bits가 추가적으로 필요하다.
- 즉, 하나의 Cache Line에는 Data(16Bytes = 128bits) + Tag(18bits) + Dirty(1bit) + Valid(1bit) = 148bits로 구성된다.
- 즉, 전체 Cache의 크기는 148 bits * 1,024 = 18.5KB로 구성된다.
- 즉, 15.6%의 오버헤드가 존재함을 확인할 수 있다. (\({16KB \over 18.5KB} = 0.156\))
Cache #1
- 위 그림은 CPU와 D램 메모리의 성능 추이를 나타낸 그래프이다.
- 1980년대의 CPU 성능과 메모리 성능을 1.0이라 설정했다.
Moore's Law
- 약 1.5년마다, CPU에 집적시킬 수 있는 트랜지스터의 수가 두 배씩 증가한다는 법칙(주장)을 의미한다.
- CPU의 성능 향상률에 반해, D램 메모리의 성능 향상률은 매년 7% 선에 그쳤다.
- 즉, CPU와 D램 메모리 사이의 성능 간극이 매년마다 50%씩 벌어지고 있는 추세이다.
Memory Wall
- 컴퓨터 시스템의 전체적인 성능이 CPU에 뒤쳐지고 있는 메모리에 의해 결정되는 현상을 의미한다.
SRAM
- CPU 내부에 삽입할 수 있으며, 트랜지스터 로직 공정과 동일한 공정을 거친다.
- 여타 메모리보다 빠른 성능을 가진 대신, 용량 대비 가격 경쟁력이 떨어진다.
- CPU보다 상대적으로 느린 DRAM이 컴퓨터 시스템 전체 성능에 어떻게 영향을 미치는 가에 대한 이야기이다.
- 기존에 다뤘던, Instruction을 5개의 Stage로 나누어 Pipelining 방식으로 처리하는 MIPS 프로세서 예시이다.
- CPU의 Clock Cycle은 1GHz이다. (즉, 1ns마다 하나의 Clock Cycle이 생성된다.)
- 위 Pipeline Execution Diagram에서는 IF Stage에 100 Cycle이 소요된다.
(비교적 많은 시간이 소요되는 이유는 IF가 메인 메모리(DRAM)에 접근해야 하는 Stage이기 때문이다.)
- MEM, WB Stage는 생략한다.
- ID, EX Stage에 비해 IF Stage에서 많은 시간이 소요됨을 알 수 있다.
- 유독 IF Stage에서 많은 시간이 소요되는 것을 보고, 메모리에 접근하는 과정에서 많은 시간이 소요된다 결론 지을 수 있다.
- 즉, 가장 오랜 시간이 걸리는 IF Stage에서 100 Cycle이 소요되므로, 해당 프로세서에서는 100 Cycle마다 하나의 명령어를 처리할 수 있게 된다. (즉, CPI = 100 이다.)
- Moore's Law에 의해, CPU와 메모리 간 성능 차이가 커질수록 위와 같은 성능 저하 문제는 심각해진다.
ex) 메모리의 성능은 그대로인 상태에서 CPU의 Clock Cycle이 2GHz로 개선되면, CPI = 200으로 증가한다. (성능 저하)
- 앞 장에서 확인한 성능 저하를 해결하기 위해 CPU Architect들은 프로세서를 구성할 때, Core 뿐만 아니라, Cache(SRAM 기반의 메모리)도 집적시킨다.
- 자주 사용되는 명령어, 데이터들이 Cache에 저장된다.
- Cache는 100% H/W에 의해 운영되며, S/W적으로 제어할 수 있는 방법은 없다.
- Cache를 제어한다 함은, 메인 메모리에 저장되어 있는 명령어, 데이터 중 빈번히 사용되는 것들을 Cache에 저장하는 것을 의미한다.
(자주 사용하는 명령어, 데이터를 프로그래머가 선정하여 Cache에 저장시킬 수 없다.)
- CPU는 자주 사용하는 명령어, 데이터를 Cache에서 Fetch 함으로써 시간을 절약할 수 있다.
- Cache 또한 여러 Level로 이루어져 있으며, 가장 빠른 L1 Cache는 보통 CPU Cycle과 클럭 주기를 같이하여 CPU가 한 사이클 안에 데이터를 Fetch할 수 있다.
※ Cache는 꼭 SRAM으로만 설계되어야 하는 것은 아니며, Embeded DRAM과 같이 다른 소자로 구성하는 방식도 존재한다. 단, 거의 모든 Cache는 SRAM으로 생산된다.
SRAM
- Cross-Coupled Inverter가 데이터를 보관하는 형태이다.
- 트랜지스터 기반의 Positive-Feedback 기법을 통해 매우 빠른 동작 속도를 구현할 수 있다.
- 그림의 SRAM은 하나의 Bit 값을 표현하는 Cell이며, 내부의 Inverter 하나는 두 개의 트랜지스터로 설계된다.
- 즉, 1Bit를 표현하는 하나의 Cell에는 두 개의 Inverter와 두 개의 byy를 집적하기 위해 총 6개의 트랜지스터가 필요하다.
- 또한, SRAM은 표현할 수 있는 Bit 수 대비 DRAM보다 많은 실리콘 공간을 요구한다.
- 이에 반해, DRAM은 1Bit를 표현하는데 하나의 Pass Transistor만을 요구하기 때문에 SRAM보다 가격적 측면에서 월등하다.
DRAM
- 기본적으로 Capacitor가 Logic에 이용된다.
- Capacitor는 Charge(전하)를 저장할 수 있는 회로소자로, 전하가 꽉 차있으면 1이라 간주하며, 전하가 없으면 0이라 간주한다.
- 여기서 Pass Transistor는 Capacitor에 전하를 채우거나 비우는 역할을 한다.
- 즉, DRAM에서는 1Bit를 표현하기 위해 하나의 Capacitor와 하나의 Pass Transistor만 필요로 하기에 비용 측면에서 효율적이다.
- 단, Capacitor에서는 시간이 지남에 따라 Leakage Current가 흐를 수 있으므로(전하가 누설되는 현상이 있을 수 있으므로), 특히 1을 표현하기 위해서는 주기적인 Refresh를 통해 전하를 채워주는 과정이 필요하다.
- 또한, Pass Transistor를 거쳐서 전하를 비우거나 채우고, 프로세서와 멀리 위치해있는 탓에 SRAM과 대비하여 처리 속도가 느리다.
- 비교적 구 버전 컴퓨터의 구성 소자들에 대한 그림이다.
- 프로세서에 적재하지 못한 소자들을 North Bridge/South Bridge 칩셋에 집적한 구조이다.
- 현재와 달리, 메인 메모리를 프로세서가 아닌 North Bridge가 제어했다.
- 또한, North Bridge는 FSB를 통해 프로세서와 데이터를 주고 받았다.
- 현재는 프로세서 내에 Cache가 적재되어있는 형태이다.
- Intel사의 2000년대 프로세서인 Core 2 Duo의 구조이다.
- 2개의 코어와 L1, L2 Cache가 적재되어 있는 형태이다.
- DL1은 Data Cache를 의미하며, IL1은 Instruction Cache를 의미한다.
- 즉, Level 1 Cache는 명령어를 위한 Cache와 데이터를 위한 Cache가 서로 구분된다.
- 즉, Core와 L1 Cache 사이에는 명령어를 주고받기 위한 Path와 데이터를 주고 받기 위한 Path가 따로 존재할 것이다.
- Intel 사의 2세대 Sandy Bridge i7 프로세서에서는 Cache의 레벨이 3단계까지 증가되었다.
- 또한, Sandy Bridge에서는 보다 많은 North Bridge의 소자들이 프로세서에 함께 적재되었다.
(Moore's Law에 의해 더 많은 트랜지스터를 적재할 수 있음에 따른 결과이다.)
- 프로세서 내부의 Memory Controller와 Memory Controller I/O를 통해 프로세서에서 메모리를 제어할 수 있게 되었다.
- 메모리의 처리 시간과 용량은 비례 관계에 있다.
(즉, 용량이 큰 메모리는 많은 처리 시간을 요구하며, 처리 시간이 짧은 메모리는 대용량으로 구현할 수 없다.)
Principle of Locality
- 비용 측면에서 우수한 기술을 용량이 큰 메모리를 설계하는 데에 사용한다.
ex) 자기 기술로써 구현한 4TB 하드디스크 드라이브
- 속도 측면에서 우수한 기술을 용량이 작은 메모리를 설계하는 데에 사용한다.
ex) 8KB L1 Cache
※ L1 Cache를 L1I와 L1D로 따로 설계함으로써 Structure 해저드를 예방할 수 있다.
- Data Transfer를 Management하는 주체에 관한 이야기이다.
- 컴파일러 혹은 프로그래머에 의한, Register Spilling을 통해 레지스터와 메인 메모리 사이로 데이터를 옮길 수 있다.
- Cache Controller에 의해, Cache와 메인 메모리 사이로 데이터를 옮길 수 있다. (only H/W 영역)
- D0, D1, D2, D3에는 각각 하나의 Word를 저장할 수 있다.
- TAG는 주소와 비슷한 역할을 한다.
- 즉, 위 그림의 Cache는 4개의 Word를 총 1,024개 저장할 수 있는 구조이다.
- Cache Line(Cache Block) = 4개의 Words를 저장하고 있는 하나의 Row를 의미한다.
- 즉, 1,024개의 Cache Line으로 구성된 것이다.
- 그림에서의 Cache Line의 크기는 4 Words이며, 이는 프로세서의 설계 방식에 따라 달라질 수 있다.
- 녹색 배경을 가친 수치들은 각각 1Word 데이터를 의미한다.
- 하나의 데이터들은 1Word 크기를 차지하므로, 메모리의 주솟값 또한 4씩 증가한다. (Word-Alignment)
1. CPU Core가 메인 메모리의 0x0000_0004 위치의 데이터(0x2222_2222)를 요구하는 경우
- Cache는 메인 메모리에게 데이터를 받아 CPU Core에게 전달하게 된다.
- 이 때, 메인 메모리는 0x2222_2222값 뿐만 아니라, 하나의 Cache Line을 채우기 위해 해당 데이터가 위치하는 4 Words 블럭 모두를 전달한다.
- 즉, Cache가 메인 메모리에 0x2222_2222를 요청하면, 메인 메모리는 Cache에게 0x1111_1111부터 0x4444_4444까지 4개의 Words를 동시에 Cache에게 전송한다.
2. 1번 연산 이후에, CPU Core가 메인 메모리의 0x000C 위치의 데이터(0x4444_4444)를 요구하는 경우
- 1번 연산을 통해 0x4444_4444 데이터를 이미 Cache가 보유하고 있는 상황이다.
- 그러므로, Cache에서 바로 CPU Core에게 전달할 수 있다.
- 이러한 상황이 Locality를 활용한 성능향상의 한 예시이다.
3. 1번, 2번 연산 이후에, CPU Core가 메인 메모리의 0x0000_1208 위치의 데이터(0x7777_7777)를 요구하는 경우
- 0x7777_7777은 Cache가 메인 메모리로 부터 Load한 이력이 없으므로, 해당 데이터를 메인 메모리에 요청한다.
- 요청을 받은 메인 메모리는 해당 데이터의 Locality Data(0x5555_5555 ~ 0x8888_8888) 모두를 Cache에게 전송한다.
※ Cache는 메인 메모리로부터, CPU가 요청한 1 Word 데이터만 불러오는 것이 아닌, 그 주변의 데이터들도 불러올 확률이 높다 생각하여, 이러한 Locality(주변 데이터)들까지 모두 불러온다.
Access Granularity
- Cache와 메인 메모리 사이에 주고받는 데이터의 크기를 의미한다.
- Cache 라인 단위로 주고 받으며, Cache 라인의 크기는 프로세서 제조사별로 차이가 있다.
1. Temporal Locality (시간 측면에서의 Locality)
- CPU가 특정 메모리 주소에 접근할 경우, 해당 주소는 빠른 시간내에 다시 접근할 확률이 높음을 의미한다.
- Temporal Locality를 활용하여, 가장 최근에 접근했던 데이터는 캐쉬에 저장한다.
2. Spatial Locality (공간 측면에서의 Locality)
- CPU가 특정 메모리 주소에 접근할 경우, 해당 주소 인근의 데이터들에 다시 접근할 확률이 높음을 의미한다.
- Spatial Locality를 활용하여, 캐쉬 블럭을 가져올 때, 여러 Word의 데이터를 가져오게 된다.
- 배열, 변수의 내용을 모두 Cache에 저장했다 가정한다.
- 변수 D가 저장된 메모리를 Loop를 돌며 100회 접근하게 된다. 즉 Cache는 D를 저장해놓으면 99번의 메모리 접근 연산을 하지 않아도 된다. (Temporal Locality 활용)
- Loop를 돌며 배열 A, B, C에 저장된 일련의 데이터들이 차례대로 요청된다. 즉, Cache는 하나의 배열 데이터가 요청된 경우, 일련의 데이터들을 한꺼번에 가져오는 것이 CPU 입장에서 효율적일 것이다. (Spatial Locality 활용)
※ CPU가 추후에 접근할 것이라 생각하는 데이터를 미리 Cache에 저장해 놓는다.
1. Block (Cache Line)
- Cache와 DRAM 사이에 주고받는 데이터의 단위이다.
- 현재 대부분의 PC의 경우, Block의 단위는 64 Bytes이다.
2. Hit
- 프로세서(코어)가 요청한 데이터가 Cache에 존재하는 상황을 의미한다.
- 즉, Hit가 발생한 것은 성능 향상을 의미한다.
Hit Rate : Hit가 일어날 확률
ex) 100회의 메모리 접근 시도 중, 90회는 해당 데이터가 Cache에 존재한 경우, Hit Rate는 90%이다.
Hit Time : Hit가 일어났을 때, Cache에 접근하는 데에 소요되는 시간
3. Miss
- 프로세서(코어)가 요청한 데이터가 Cache에 없는 상황을 의미한다.
- 즉, Miss가 발생한 것은 요청한 데이터를 가져오기 위해 메인 메모리에 접근해야 함을 의미한다.
Miss Rate : Miss가 일어날 확률
ex) 100회의 메모리 접근 시도 중, 90회는 해당 데이터가 Cache에 존재한 경우, Miss Rate는 10%이다.
Miss Penalty : Miss가 발생하여, 하위 레벨 Cache혹은 메인메모리에 접근하는 데에 소요되는 시간
- 어떤 데이터를 어떤 Cache에 저장하며 어떻게 접근해야 할지에 관한 이야기이다.
- 가장 간단한 형태의 Cache를 Direct Mapped Cache라고 한다.
- 메인 메모리의 특정 Block이 저장될 Cache의 위치가 정확히 정해져있는 형태이다.
(메모리가 저장될 Cache 위치가 1대1로 Mapping되어 있는 형태)
- 일반적으로, 각각의 Block은 64 Bytes이며,모든 프로세서에 통용되는것은 아니다.
- Cache의 크기는 메인 메모리보다 클 수 없으므로, 하나 이상의 메인 메모리 블럭이 하나의 Cache Block을 공유한다.
- 그림에서는 각 Memory 블럭들이 주솟값을 기준으로 차례대로 Cache Line에 저장되며, 어떤 메모리 블럭이 마지막 Cache Line에 저장되었다면, 그 다음 메모리 블럭은 다시 처음 Cache Line에 중첩되어 저장되는 것으로 표현했다.
- 즉, 32개의 메모리 블럭과 8개의 Cache Line이 존재할 경우, 하나의 Cache Line에 4개의 메모리 블럭이 저장된다.
- 즉, 메모리 블럭의 하위 3bits 주솟값으로 어느 Cache Line에 저장되는 지를 구분할 수 있다. (Cache Line이 8개로 이루어져 있기 때문이다.)
- 즉, Cache Line의 주소는 메모리 블럭 주소를 8로 나눈 나머지로 계산할 수 있다. (Modulo 연산)
- 또한, Cache에 저장된 각각의 메모리 블럭을 구분짓기 위해, 메모리 블럭의 상위 Bits 또한 Cache에 저장되어야 한다.
(이를 Tag라 부른다.)
- 위 그림에서 001 Cache에는 메모리 블럭의 하위 3bits가 001인 4개의 데이터들이 저장되며, 각각의 데이터들의 Tag(상위 2bits)는 00, 01, 10, 11이다.
- 이외에 Cache를 공유하는 방법으로 Mapping Function을 사용하는 방법 등이 있다.
- 메인 메모리는 기본적으로 Byte-Addressable한 구조이다. (Word-Addressable한 구조는 Byte-Addressable한 구조 위에서 논리적으로 구현된 형태인 것이다.)
- Word-Address는 Byte-Address에서 하위 2bit를 Chopping한 형태이다. (1Word = 4Bytes 이기 때문이다.)
- Block-Address는 Byte-Address에서 하위 6bit를 Chopping한 형태이다. (1Block = 64Bytes 이기 때문이다.)
- Addressable한 주솟값의 단위가 커질수록, Chopping되는 하위 bits수를 나타낸 그래프이다.
- 메모리 블럭이 속한 Cache 주소 = 메모리 블럭 주소 MOD Cache Line의 개수
(Cache Line의 개수가 2의 거듭제곱 형태라는 가정하에 이루어지는 공식이다.)
Cache Structure
1. Data
- Cache에 저장되는 실제 데이터 값을 의미한다.
2. Tag
- 한 Cache에 저장되어 있는 여러 데이터들을 구분짓기 위한 정보이다.
- 즉, 메모리의 어느 주소와 Mapping 되어 있는가에 대한 정보이다.
3. Valid
- 실제로 Cache와 메모리 사이의 상호작용을 통해 저장된 데이터인지를 구분하는 정보이다.
- 즉, 어떤 요인에 의해 강제로 설정된 쓰레기 값인지 아닌지를 구분하는 정보이다.
- 4KB 용량을 가진 Cache는 1 Word의 Cache Line들을 가지며, Direct-Mapped Cache 구조로 설계되었다 가정한다.
(즉, Cache와 메인 메모리간에 데이터를 1 Word 단위로 주고받는다.)
- 4KB Cache는 1 Word의 Cache Line이 총 1,024개로 구성되어 있다.
Address from CPU
1. Byte Offset (2bits)
- CPU는 기본적으로 Byte Address를 사용하기 때문에, Word 단위로 Cache에 저장되어 있는 데이터를 Byte로 구분하기 위한 오프셋 값이다.
2. Index (10bits)
- 1,024개의 Cache Line을 구분짓기 위한 값이다.
3. Tag (20bits)
- 하나의 Cache Line에 중첩되어 저장된 여러 데이터 중 하나를 구분짓기 위한 값이다.
- 여기에 더불어, Valid Bit가 1이어야 정상적인 데이터로 간주된다.
※ 이 예시는 Temporal Locality를 활용한 방법이다.
- CPU가 Cache에게 하나의 Word를 요청했으며, Cache는 메인 메모리로 부터 하나의 Word를 가져왔다.
- 메인 메모리로부터 여러 데이터를 가져오지 않았다는 점에서 Spatial Locality가 있다고 보기 어렵다.
- 하위 2bits 데이터 00을 통해 Byte-Address를 구분한다.
- 그 다음 3 bits 데이터 110(6)을 통해 Cache Line을 구분한다.
- 최상위 3bits 데이터 000을 통해 Tag를 구분한다.
- 그러나, 여기서 Valid 비트가 0이므로 Cache Miss가 발생했으므로, 메인 메모리에 직접 접근해야 한다.
- 메인 메모리의 0001 1000(24)에 해당되는 값(a)을 Cache에 적절히 저장한다.
- 저장한 이후, Valid Bit를 1로 설정하여 유효한 값임을 표시한다.
- 메모리의 28 Offset에 해당되는 데이터가 Cache Miss된 이후, Cache에 저장되는 절차이다.
- 베이스 주소($0)으로 부터 60번째 데이터가 먼저 Cache에 저장되어 있는가를 확인하는 절차이다.
- 60은 001 111 00이며, Tag = 001, Cache Line = 111, Byte-Address = 00이다.
- 검색 결과, Valid Bit가 1이지만, Tag가 일치하지 않아, Cache Miss인 상황이다.
- 검색 결과, Valid Bit가 1이긴 하지만, Tag가 일치하지 않아, Cache Miss인 상황이다.
- Cache Miss가 발생한 이후, c에 해당되는 데이터가 Cache에 덮어쓰여지게 된다.
(Write-Allocation Policy 하에 이루어지는 동작이다.)
- Cache에는 3번 레지스터의 값으로 새로 바뀌었다. (sw명령어임을 상기하자)
- 이제 Cache의 값을 메인 메모리에다 써야한다.
- 아직까진, 메인 메모리에는 c 값이 위치하고 있다.
- 즉, Cache의 값과 메인 메모리 값이 다른 상황이다.
- 이렇게 값이 다른 상황에서 메인 메모리의 값을 Update하는 것을 미루는 것을 Write-Back이라 표현한다.
- Write-Back Cache 구조에서는 Dirty Bit 구조를 필요로 한다.
- Dirty Bit는 Cache값은 Update 되었으나, 메인 메모리에는 아직 쓰지 않은 상태인 경우 1로 설정된다.
- 새로운 명령어 (188 Offset에 저장하는 sw명령어)를 실행하는 과정이다.
- 마찬가지로, 111(7)에 해당되는 Cache Line의 Valid bit는 1이나, Tag가 서로 다르므로 Cache Miss가 일어난 상황이다.
- 단, 해당 Cache Line의 Dirty Bit가 1이므로, 기존의 데이터를 올바른 메인 메모리 주소(60)에 저장하고 나서 188 Offset에 해당되는 값을 Cache에 저장하게 된다. (Write-Allocation 방법)
- Write-Allocation, Write-Back에 관한 내용이다.
- Cache Hit중, CPU가 읽고자하는 데이터가 Cache에 존재하는 상황을 Read-Hit이라 하고, CPU가 메인 메모리에 쓰고자 하는 데이터가 이미 Cache로 옮겨와 있는 상황을 Write_Hit라 한다.
(Read-Miss, Write_Miss또한 위와 같은 맥락으로 해석할 수 있다.)
- CPU가 Cache에서 데이터를 읽을 때, Read-Hit 혹은 Read-Miss가 발생하게 된다.
- Read-Hit의 경우, CPU가 Cache에서 데이터를 읽어오게 된다.
- Read-Miss의 경우, CPU가 원하는 데이터가 Cache에 없는 상황이므로, 메인 메모리에서 원하는 데이터가 포함되어있는 Cache Line을 Cache에게 저장한 후, Cache에서 CPU에 데이터가 전달된다.
- Write-Miss의 경우, Write-Allocation을 진행할 수도 있고, Write No Allocation을 진행할 수도 있다.
1. Write Allocation
- 메인 메모리에서 원하는 데이터가 속한 Cache Line을 Cache로 옮기고. CPU가 Cache에 접근하여 데이터를 가져가는 작업이다.
2. Write No Allocation
- CPU가 메인 메모리에 원하는 데이터를 직접 요청하는 작업이다.
- Cache에 데이터를 쓰는 경우, Write-Back을 진행할 수도 있고, Write-Through를 진행할 수도 있다.
1. Write-Back
- Cache에는 값을 쓰지만, 하위 레벨 Cache나 메인 메모리에는 당장 값을 쓰지 않는 형태의 작업이다.
- Cache에 쓴 값이 추후에 하위 레벨 Cache나 메인 메모리에 저장해야 될 때 비로소 값을 옮기게 된다.
2. Write-Through
- Cache에 Update하는 동시에 메인 메모리에도 값을 쓰는 형태의 작업이다.
※ 일반적으로, Write-Allocation은 Write-Back과 함께 쓰인다.
※ 일반적으로, Write No-Allocation은 Write-Through와 함께 쓰인다.
- Write-Allocation과 Write-Back 방식으로 진행되는 예시이다.
- 즉, 원하는 데이터를 메인 메모리에서 Cache로 가져오고난 후에 CPU가 Cache에 접근하여 데이터를 처리하는 방식이다.
- 또한, Cache에 데이터를 쓴 후, 해당 데이터를 옮겨야 할 상황이 발생하면 하위 레벨 Cache나 메인 메모리에 데이터를 쓰는 방식이다. (Cache가 Update되는 즉시, 하위 메모리에 옮기지 않는다.)
1. Cache Hit 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_1208이다.
- 즉, 메인 메모리의 7777 7777값 대신 새로운 값을 쓰고자 하는 것이다.
- 해당 위치에 CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니 Tag와 Index가 일치하여 Cache Hit가 발생했다.
(즉, 새로 쓸 위치에 해당되는 기존의 데이터(7777_7777)가 이미 Cache에 저장되어 있었다.)
- Write-Back Policy로 진행되기 때문에, CPU는 Cache에만 데이터를 새로 쓴 상태(Cache에는 7777_7777대신 1234_5678이 저장된 상태)이며, 메인 메모리에는 여전히 7777_7777이 저장되어 있는 상황이다.
- 메인 메모리에는 아직 옮기지 않았으므로, 해당 데이터가 속한 Cache Line의 Dirty Bit값은 1로 설정된다.
2. Cache Miss 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_0004이다.
- 즉, 메인 메모리의 2222 2222값 대신 새로운 값을 쓰고자 하는 것이다.
- CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니, 2222_2222 데이터에 해당되는 Tag와 Index가 존재하지 않아 Cache Miss가 발생했다.
- Write Allocation 방법을 통해 메인 메모리로부터 Cache로 데이터를 먼저 옮기고 난 후에 CPU가 Cache에서 해당 데이터를 가져가게 된다.
- 즉, 2222_2222 데이터가 속한 Cache Line(1111_1111부터 4444_4444까지의 데이터들)이 모두 Cache에 저장된다.
- CPU는 Cache의 2222_2222가 위치한 곳에 2222_2222 대신 dddd_dddd를 저장한다.
- 그러나 Write_Back 정책에 의해, 메인 메모리에는 반영하지 않고, Dirty Bit를 1로 설정하는 것으로 마무리한다.
- 즉, dddd_dddd가 Replacement되기 전까지는(Dirty Bit가 1로 설정된 시간동안에는) Cache가 메인 메모리에서 같은 주소에 저장하고 있는 값이 다르다.
- 35페이지와 동일한 쓰기 동작을 Write No-Allocation과 Write-Through 방식으로 진행하는 예시이다.
1. Cache Hit 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_1208이다.
- 즉, 메인 메모리의 7777 7777값 대신 새로운 값을 쓰고자 하는 것이다.
- 해당 위치에 CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니 Tag와 Index가 일치하여 Cache Hit가 발생했다.
(즉, 새로 쓸 위치에 해당되는 기존의 데이터(7777_7777)가 이미 Cache에 저장되어 있었다.)
- Write-Through Policy로 진행되기 때문에, CPU는 Cache에 데이터를 새로 쓰는 동시에, 해당 메모리 위치에도 값을 저장하여 동기화시키는 상황이다.
- Cache에 값을 저장함과 동시에 메인 메모리에도 저장하므로 Dirty Bit를 필요로하지 않는다.
- Cache와 함께 메인 메모리도 동시에 Update하는 방식을 Write-Through라고 한다.
2. Cache Miss 시나리오
- 위 그림과 같이, Cache에 하나의 Cache Line이 저장되어 있는 상황에서, CPU Core가 메모리 쓰기 연산을 요청했다 가정하자.
- 데이터를 저장할 메모리의 주솟값은 0x0000_0004이다.
- 즉, 메인 메모리의 2222 2222값 대신 새로운 값을 쓰고자 하는 것이다.
- CPU가 값을 쓰기위해 Cache에 우선적으로 접근했더니, 2222_2222 데이터에 해당되는 Tag와 Index가 존재하지 않아 Cache Miss가 발생했다.
- Write No-Allocation 방법을 통해 데이터를 Cache를 거치지 않고, 곧바로 메인 메모리에까지 데이터를 저장한다., 굳이 Cache에까지 데이터를 할당(저장)하지 않는다.(No-Allocation)
- 즉, 데이터 dddd_dddd가 메모리의 0x0000_0004 위치에 곧바로 저장된다.
※ Write No-Allocation & Write-Through 방식에서는 Cache와 메인 메모리의 값들이 서로 동기화되어 있다. (다르지 않다.)
- Cache에는 읽기/쓰기 동작이 수행될 수 있다.
- CPU가 다루고자 하는 값이 Cache에 존재하면 Hit, 그렇지 않으면 Miss이다.
1. Read Hit
- CPU가 읽고자하는 값이 Cache에 이미 저장되어 있는 상황이다.
2. Read Miss
- CPU가 읽고자하는 값이 Cache에 있지 않는 상황이다.
- 메인 메모리로부터 데이터를 읽어오기 위해 CPU Core를 잠시 중단한다.
- 원하는 데이터가 속한 Cache Line을 메인 메모리로부터 Cache로 가져온다.
- 그 이후, CPU가 원하는 데이터 (Cache Line을 구성하는 데이터 중 하나)를 Cache에서 CPU로 넘기고 나서야 CPU Core가 다시 가동된다.
- 즉, 메인 메모리에서 Cache로 데이터를 옮기면서, CPU Core가 중단되는 성능 저하가 일어나게 된다.
3. Write Hit
- CPU가 쓰고자하는 값이 Cache에 이미 저장되어 있는 상황이다.
1) Write-Through 방식: 데이터 쓰기 동작을 Cache에도 진행하며, 메인 메모리에도 진행하는 방식이다.
- Cache와 메인 메모리가 항상 Synchronization되어 있는 형태라 관리하기에 용이하다.
- 그러나, 항상 Cache와 메인 메모리에 동시에 쓰기 연산을 수행하므로, 에너지/성능 측면에서의 손실이 발생한다.
2) Write-Back 방식: 데이터 쓰기 동작을 Cache에만 진행하며, Replacement가 발생하기 전까지 데이터를 메인 메모리에 옮기지 않는다.
4. Write Miss
- CPU가 쓰고자하는 값이(메모리 주소가) Cache에 없는 상황이다.
1) Write-Allocate with Write-Back
- CPU가 쓰고자하는 값(메모리 주소)을 메인 메모리로부터 Cache로 불러온다. (Write-Allocate 방식)
- CPU가 Cache에 값을 쓴 후, 곧바로 메인 메모리에 반영하지 않고, Replacement가 발생하면 그제서야 메인 메모리에 반영시킨다. (Write-Back)
2) Write No-Allocate with Write-Through
- CPU가 쓰고자하는 값(메모리 주소)을 메인 메모리에서 바로 불러온다. (Write No-Allocate 방식)
- 즉, 데이터가 메인 메모리에만 반영되며, 이 과정에서 Cache는 개입되지 않는다.
- CPU가 Cache에 값을 쓴 후, 곧바로 Cache에서 메인 메모리에 반영한다. (Write-Through 방식)
- 4-Word Block : 하나의 Cache Block(Cache Line)이 4 Word로 구성되어 있는 형태를 의미한다.
- 또한, 전체 Cache 크기는 4KB라 가정한다.
- 32bits 메모리 주소 중, 상위 28bits는 Cache Block을 구분짓게 하는 Block Address가 된다.
(Tag[31:12] 20bits, Index[11:4] 8bits)
- 즉, 4 Word(16 Bytes)를 구분짓기 위해 4 bits(\(2^4=16\))가 필요한 것이다.
- Cache Line의 수(엔트리 개수)는 256개로 구성된다. (16Bytes * 256 = 4,096Bytes = 4KB)
- 즉, Index[11:4] 8bits로 엔트리를 구분지을 수 있다.
- Tag[31:12] 20bits는 주소의 역할을 한다. (Cache의 주소인 동시에, 메인 메모리 주소)
(Hit, Miss 여부는 Tag Comparison과 Valid Bit Check를 통해 알아낼 수 있는 것이다.)
- 하나의 Cache Line에 위치한 4개의 Word중, CPU가 원하는 4Bytes 데이터를 구분짓기 위해 Block Offset[3:2] 2bits를 사용하여, 4개의 Word 중 하나를 선정한다.
- 위와 같은 과정을 통해 선정된 하나의 Word 데이터가 CPU로 향하게 된다.
- 선정된 하나의 Word 중 하나의 Byte를 선정하기 위해 Byte Offset[1:0] 2bits를 사용할 수도 있다.
(Byte Addressable한 접근이 필요한 경우)
※ 위 그림의 Direct Mapped Cache는 Temporal Locality와 Spatial Locality를 모두 활용하고 있다.
- 요청한 Word를 Cache에 보관한다는 측면에서 Temporal Locality를 활용한다고 볼 수 있다.
- 요청한 Word뿐만 아니라, 주변의 3개의 Word 또한 가져오게 되므로 Spatial Locality를 활용한다고도 볼 수 있다.
- Block의 크기가 클 수록 Spatial Locality를 극대화하기 유리하다. (더 많은 주변 데이터를 가져올 수 있기 때문이다.)
- Block Size에 따른 Miss Rate 변화 그래프이다.
- Legend에서의 8KB ~ 256KB는 Cache의 전체 크기를 의미한다.
- 8KB 수준의 작은 Cache에서는 Block의 크기가 증가함에 따라 Miss Rate이 상승됨을 볼 수 있다.
- Block 크기가 커질수록 Cache Line의 개수는 줄어들게 되어 다른 Cache Line을 가져올 기회를 뺏는 것이기 때문이다.
- 그러므로, Block Size를 적절히 설정하는 것이 중요하다.
- 근래에 빅 데이터를 다루게 되면서 Locality가 저하됨이 발견되어 Block Size를 줄이는 것도 고려중에 있다.
- 16KB Direct Mapped Data Cache를 설계한다 가정하자.
- 하나의 Cache Line(Data)은 4 Words로 구성되어 있으며, MIPS와 같은 32bits 주소 체계를 갖고 있다.
- Cache의 총 크기는 16KB이며, 한 Cache Line의 크기는 16Bytes이므로, Cache Line(엔트리)의 개수는 1,024개 이다.
- 4개의 Word를 구분하기 위해 Block Offset[3:2] 2bits를 이용한다.
- 1,024개의 Cache Line을 구분하기 위해 Index[13:4] 10bits를 이용한다.
- Tag는 18bits로, Dirty Bit는 1 bit, Valid Bit는1bit로 구성된다.
- 즉, 하나의 Cache Line에는 Data를 위한 4 Word 이외에 20bits가 추가적으로 필요하다.
- 즉, 하나의 Cache Line에는 Data(16Bytes = 128bits) + Tag(18bits) + Dirty(1bit) + Valid(1bit) = 148bits로 구성된다.
- 즉, 전체 Cache의 크기는 148 bits * 1,024 = 18.5KB로 구성된다.
- 즉, 15.6%의 오버헤드가 존재함을 확인할 수 있다. (\({16KB \over 18.5KB} = 0.156\))