
Basic Conepts of Database
데이터베이스의 기본 개념
- Database System은 데이터베이스와 관리 시스템, 관리자, 사용자, 데이터 언어를 총칭하는 개념이다.
- OS에 의해 관리되는 File System과 대비되는 개념이다.
File System (파일 시스템)

- OS의 관리하에 운용되는 시스템이다.
- 파일 시스템 또한, 데이터베이스 시스템과 같이 데이터를 관리하는 시스템이다.
- 파일 시스템에서의 데이터들은, 데이터를 이용하는 Application들에 종속적이다.
(즉, Application과 Data가 독립적이지 않다.)
- 또한, 파일 시스템에서는 데이터 파일 간 데이터의 중복 여부를 확인할 방법이 없다.
(즉, 같은 데이터가 여러 곳에 산재해있을 가능성이 있다.)
※ 파일 시스템에선, Data Dependency(데이터 종속성)*과 Data Redundancy(데이터 중복성)**이 존재한다.
* Data Dependency (데이터 종속성)
- Application과 Data간에 상호적 의존 관계가 있는 경우를 "데이터 종속성이 있다"라 표현한다.
- 데이터 종속성이 있는 경우, Data의 구성 방법, 구성 형식, 접근 방법이 변경되면
이 Data를 사용하는 Application의 구조 또한 변경되어야 한다.
- DB 시스템에서는 데이터와 응용 프로그램은 서로 독립적이어야 한다.
** Data Redundancy (데이터 중복성)
- DB 설계 시, 가장 먼저 제거해야하는 요인이다.
- 한 시스템 내에 같은 데이터가 다수의 파일에 중복되어 저장되어 있게 되면,
해당 데이터 수정 시, 산재되어 있는 같은 데이터를 모두 수정해야 하는 번거로움이 발생한다.
- 중복된 데이터의 일부분만 수정할 경우, 데이터 불일치가 발생되어 데이터가 일관성을 잃게 된다.
- 또한, 크기가 큰 데이터가 중복되어 저장되면 메모리 효율성을 크게 저해한다.
Database System (DBS; 데이터베이스 시스템)

- 데이터베이스를 이용해 데이터를 저장, 관리하기 위한 목적으로 사용되는 일체의 시스템을 일컫는다.
(DBS = DB + H/W + S/W + User)
- Application이 DBMS를 거쳐 Data에 접근할 수 있는 구조이다.
- 데이터를 오로지 DBMS가 Meta Data(구조화된 데이터)로써 관리하기 때문에
데이터 종속성과 중복성이 없다. (혹은 최소화되어 있다.)
DBS의 구성요소

DBMS (Database Mamagement Software)
- DB를 관리하는 S/W를 의미한다.
- 데이터만을 관리하는 OS라 할 수 있다.
(일반적으로 OS는 컴퓨터 H/W 리소스와 데이터를 운용하는 시스템 프로그램을 의미한다.)
ex) Oracle, MySQL, DB2 등
DBM (Database Machine)
- 데이터베이스를 H/W적으로 처리하는 장치이다.
- 병렬 처리 및 스피드업과 같은 특수 목적용으로 사용하며, 일반적인 경우에는 거의 사용되지 않는다.
DB (Database; 데이터베이스)
- 공동업무에 사용하기 위해, 구조화되고 비중복화된 데이터가 저장된 곳이다.
(데이터의 구조화를 위해선, 우선적으로 모델링이 이루어져야 한다.)
- Entity(개체)와 Relationship(개체들간의 관계)으로 구성된다.
SQL (Structured Query Language; 데이터 언어)
- 사용자와 DB 사이를 연결시켜 주는 역할을 하는 언어이다.
- 사용자가 원하는 정보를 요청하고 제공하는데 이용한다.
DBA (Database Administrator; 데이터베이스 관리자)
- DB를 총괄적으로 관리하는 프로그래머를 의미한다.
- DB에 데이터가 저장, 관리되는 방식을 결정하여 DB의 I/O 시간을 개선하는 역할을 한다.
(DB의 유지보수, 개발, 테스트를 수행한다.)
- DB에서 발생될 장애에 대비하여, 자료복구나 백업, 데이터 보전을 위한 작업을 한다.
- 또한, DB의 접근제어와 관련된 권한 부여와 같은 보안정책을 관리한다.
* 일반적으로 기업에서 DBA는 CIO(Chief Information Officer)의 대우를 받는다.
User (Application Programmer & General User; 사용자)
- 응용 프로그래머는 High-Level Language를 사용하여 프로그래밍하며 DB를 이용하는 사용자를 의미한다.
- 일반 사용자는 SQL을 이용하여 DB를 이용하는 사용자를 의미한다.
Database (DB; 데이터베이스)
- 조직체의 Application System들이 공유해서 사용하는 Data들이 구조적으로 통합된 형태로 저장되어 있는 공간이다.
- DB의 Structure는 사용되는 데이터 모델에 의해 결정된다.
| * DB에서의 Data의 종류 | |
| Integrated Data (통합된 데이터) |
- 데이터는 산재되어 있지 않고, 한 곳에만 위치해야 한다. - 모든 데이터가 Normalization(정규화)을 통해 중복을 최소화하면서 통합되어야 한다. |
| Stored Data (저장 데이터) |
- 데이터는 컴퓨터에서 처리가 가능하도록 전자적 형태로 저장되어야 한다. - 데이터는 디스크 등의 컴퓨터가 접근 가능한 Storage에 저장된다. |
| Operational Data (운영 데이터) |
- 고유 기능을 수행하기 위해 반드시 유지되어야 하는 데이터를 의미한다. |
| Shared Data (공용 데이터) |
- 한 조직의 여러 Apllication들이 공동으로 소유, 유지, 이용하는 데이터를 의미한다. |
| * DB의 특징 | |
| Integrated Stored Operational Data : 통합 저장된 운영 데이터 |
- 데이터는 어느 한 조직의 Application들이 공유해서 사용 가능하도록 구조화되어 있다. |
| Real-Time Accessibilities : 실시간 접근 가능 |
- 수시로 비정형적인 질의(SQL, Query)에 대해 실시간으로 처리가 가능하다. |
| Continuous Evolution : 계속적인 변화 |
- 새로운 데이터의 삽입, 삭제, 업데이트로 항상 변하고, 그 속에서 현재의 정확한 데이터를 유지할 수 있다. |
| Concurrent Sharing : 동시 공유 가능 |
- 여러 사용자가 동시에 원하는 데이터에 접근 가능하다. |
| Content Reference : 내용에 의한 참조 가능 |
- 데이터의 위치, 주소가 아닌, 사용자가 요구하는 데이터의 "내용", 즉 데이터의 값에 따라 참조가 가능하다. - 모든 레코드들은 물리적 위치와 관계없이 하나의 논리적 단위로 취급되고 접근할 수 있다. |
Database Mamagement Software (DBMS; 데이터베이스 관리 시스템)
- 많은 데이터를 편리하게 저장, 관리, 검색할 수 있는 환경을 제공하는 시스템 S/W이다.
| * DBMS의 필수 기능 | |
| Manipulation (조작 기능) |
- 사용자와 DB간의 Interface를 제공해야 한다. - 사용하기 쉽고, 자연스러워야 한다. - Data간의 관계를 명확하게 명세할 수 있어야 한다. - 원하는 Data Operation은 무엇이든 명세할 수 있도록 완전해야 한다. - Data 접근, 처리가 효율적으로 이루어져야 한다. |
| Control ( 제어 기능) |
- DB의 Data들에 대한 무결성을 해치지 않으며, 정확성과 안정성을 유지해야 한다. |
| * DBMS의 장단점 (OS의 File System에 비교한 장단점) | |
| 장점 | 단점 |
| - File System에 비해 데이터의 중복이 적다. - 여러 사용자와 Application들이 Data를 공유할 수 있다. - Data의 일관성이 유지된다. - 모든 Data에 대해 보안이 보장된다. - DB에 일관성있는 접근이 가능하다. - Data를 유연하게 관리할 수 있다. |
- 높은 운영비용이 요구된다. - 백업, 복구와 같은 전문적인 기술과 지식이 요구된다. |
* ERP (Enterprise Resource Planning)와 MRP (Management Resource Planning)
- DBMS 위에 응용 중심의 기능들로 이루어진 주요한 Layer를 추가하는 패키지들이다.
- 많은 기업 및 조직에서 공통 업무를 파악하고 처리하는데 필요한 Application Layer를 제공한다.
- 여기에 필요한 데이터는 보통 RDBMS에 저장되고, APP Layer는 각 조직에 알맞게 Customized되어 공급된다.
SQL (Structured Query Language; 질의어, 데이터베이스 언어)

- High-Level Language와 달리, 비절차적이며 Declarative(선언적)이다.
- DB에 저장된 데이터를 조회, 입력, 수정, 삭제하는 연산이나,
테이블을 비롯한 다양한 객체(Sequence, Index 등)를 생성, 제어하는 역할을 하는 언어이다.
| SQL의 종류 | |
| DDL (Data Definition Language; 데이터 정의어) |
- DB Schema를 정의(구축)하거나, 수정할 목적으로 사용하는 언어이다. |
| DML (Data Manipulation Language; 데이터 조작어) |
- 테이블*에 새로운 데이터에 대해 조회, 수정, 삭제, 삽입 등의 작업을 하기 위해 사용하는 언어이다. |
| DCL (Data Control Language; 데이터 제어어) |
- DB의 테이블, 뷰, 저장 프로시저 등의 객체에 대한 유저의 권한에 관련된 언어이다. |
* Table(테이블): 모든 데이터가 실제로 저장되는 DB 객체를 의미한다.
| * 대표적인 DDL | * 대표적인 DML | * 대표적인 DCL | |||
| CREATE | DB 생성 | SELECT | 레코드 검색 | GRANT | |
| ALTER | DB 수정 | INSERT | 레코드 삽입 | REVOKE | |
| DROP | DB 삭제 | UPDATE | 레코드 갱신 | DENY | |
| RENAME | DB 객체이름 변경 | DELETE | 레코드 제거 | ||
| TRUNCATE | DB데이터 삭제 | ||||
* Realtional Calculus (관계해석)
- 수학적 논리에 바탕을 둔 일종의 정형 질의어이다.
* Relational Algebra (관계대수)
- 릴레이션을 조작하기 위한 연산자들이 정의된 정형 질의어이다.
Data Modeling (데이터 모델링)


- DB에는 구조화된 데이터가 필요하고, 구조화된 데이터는 모델링을 통해 만들어진다.
- 현실 세계에서의 정리되지 않은 방대한 양의 정보들 중 의미있는 것들을 추려서(추상화해서) DB에 데이터로써 저장하는 것을 모델링이라 한다.
- 데이터에 대한 모델링과 구조화가 이루어져야 DBMS를 통해 관리가 가능하고, 데이터의 종속성과 중복성을 제거할 수 있다.
* Relation Data Model (관계 데이터 모델) : Table로 구현된다.
* Object-Oriented Data Model (객체지향 데이터 모델) : 객체로 구현된다.
* Hierarchy Data Model (계층 데이터 모델) : Tree로 구현된다. (사용되지 않는다.)
* Network Data Model (네트워크 데이터 모델) : Graph로 구현된다. (사용되지 않는다.)
Ex. Conceptional Data Model by ER Diagram (ER 다이어그램으로 표현한 개념적 데이터 모델)

* ER Diagram (ER 다이어그램)
- Entity 집합과 그것의 속성 혹은 다른 Entity 집합과의 관계를 도형으로 표현하는 방법이다.
- 직사각형: Entity 집합
- 타원: 속성
- 마름모: 관계 집합
- 화살표: Mapping 형태
- 실선: 속성을 연결
Advantages of DBMS (DBMS의 장점)
1. Data Independence (데이터 독립성)
- APP(응용 프로그램)은 Data에 직접 접근하지 않고, DBMS를 통해 접근함으로써,
데이터의 저장 형식과 같은 Details의 변화에 영향을 받지 않는다.
- DBMS는 데이터에 관한 세부사항을 Encapsulation하여 APP에 Abstraction을 제공한다.
- 데이터의 세부사항이 변경되었다해서, APP 프로그램의 구조를 변경할 필요가 없다.
- DBMS는 논리적 혹은 물리적으로* 데이터 독립성을 보장한다.
* Logical Data Independence (논리적 데이터 독립성)
- 데이터의 논리적인 구조의 변경으로 부터 데이터의 독립성을 제공하는 특성이다.
- 데이터의 논리적 구조를 변경하여 데이터를 보호하거나 접근 제어를 부여하는 특성이다.
Ex. 대학 DB에서 교수에 관련된 정보 중, 개인 정보와 공개되어야할 정보를 서로 다른 릴레이션에 배치하는 방식
* Physical Data Independence (물리적 데이터 독립성)
- 개념 스키마와 물리적 스키마를 독립시켜, 데이터의 물리적 구조의 변화로부터 데이터의 독립성을 제공하는 특성이다.
- 개념 스키마는 데이터가 실제로 Storage에 저장되는 방식, 파일 구조, Index 선택 방법과 같은 Details를 사용자에게 감춘다.
- 개념 스키마가 그대로 유지되는 한, 데이터 구조가 변경되어도 사용자는 APP 개발에 있어서 아무런 영향을 받지 않는다.
2. Efficient Data Access (효율적 데이터 접근)
- DBMS는 데이터를 효율적으로 저장/검색할 수 있다.
- 메인 메모리가 아닌, Storage에 저장되어 있는 데이터의 경우, 효율적 접근이 정말 중요하다.
3. Data Integrity & Security (데이터 무결성과 보안성)
- DBMS를 통해서만 관리되는 데이터들은 무결성이 보장될 수 있다.
- 또한, DBMS는 사용자에게 데이터에 대한 접근 제어 권한을 선택적으로 부여할 수 있다. (보안성을 제고시킨다.)
4. Uniform Data Administration (단일화된 데이터 관리)
- 다수의 사용자들에게 공유되는 데이터는 Centralizing(중앙 집중화)되면 효율성이 크게 증대될 수 있다.
- DBA는 Redundancy(데이터 중복성)를 최소화하고 효율적 검색을 위해 데이터 표현방식을 세밀히 조직한다.
5. Concurrent Access & Crash Recovery (동시접근 및 손상복구)
- 사용자가 오직 자신만 데이터에 접근하고 있는 것처럼 느끼게끔, DBMS는 자연스러운 데이터 동시접근을 제공한다.
- 다수의 사용자들에 의한 Interleave(동시 접근)는 Data Inconsistency(데이터 불일치성)를 초래할 수 있기 때문에,
DBMS는 이를 잘 제어해야 한다.
- 또한, DBMS는 시스템 붕괴로 인한 Data Crash에 대한 Recovery(복구작업)를 수행할 수 있다.
- 반면, OS File System에서는 일정 시간동안, 하나의 파일에 대한 접근은 하나의 사용자에게만 허용된다.
6. Reduced APP Development Time (응용 프로그램 개발 시간 감축)
- DBMS는 데이터에 대한 High-Level Interface를 사용자에게 제공함으로써 신속한 응용 개발을 가능하게 한다.
- DBMS가 제공하는 Query Language는 데이터를 제어하는데 최적화되어 있다.
(특정 프로그래밍 언어를 이용하여 데이터를 제어하는 경우, 효율성은 프로그래머의 역량에 달렸다.)
※ DBMS의 사용이 부적합한 경우
- 엄격한 Real-Time Restriction이 요구되는 APP
- 효율적으로 Customized된 구조의 프로그램
- Query Language로 표현할 수 없는 방식으로 데이터를 조작해야 하는 경우
Describing and Storing Data in a DBMS (DBMS에서의 데이터 기술과 저장)
- DBMS는 데이터를 일정한 형태의 Data Model*로 DB에 저장한다.
* Data Model (데이터 모델)
- 데이터를 구성하는 부분들 중, Low-Level의 내용들은 은닉하고 High-Level의 내용들을 관리에 용이한 형태로 정리한 것이다.
- DBMS는 사용자로 하여금 저장될 데이터를 데이터 모델에 맞게 정의하게 한다.
- 특히, Semantic Data Model은 보다 더 추상적이고, 고수준의 데이터 모델로서 데이터의 초기 명세를 더 쉽게 작성할 수 있게 하는 모델이다.
- 널리 사용되는 E-R Model 또한, Semantic Data Model에 속한다.
The Relational Model (관계모델)
- 관계모델에서의 중요한 데이터 기술 구성은 Relation(릴레이션)이다.
* Relation (릴레이션)
- Record의 집합이다.
* Schema (스키마)
- 어떤 데이터 모델에 의거한 데이터의 기술 형식을 의미한다.
- 관계모델에서, 한 릴레이션의 스키마는 릴레이션의 이름과 각 Attribute(=Field, Column)의 이름과 타입으로 구성된다.
Ex. 대학교 DB에서의 Students 릴레이션
Students (sid: string, name: string, login: string, age: integer, gpa: real)
* Integrity Constraint (무결성 제약조건)
- 한 릴레이션에 있는 레코드들이 반드시 만족해야 하는 조건이다.
Ex. Students DB에서, 각 학생은 유일한 sid값을 갖는다.
※ 기타 데이터 모델
- Hierarchical Model (계층 모델)
- Network Model (네트워크 모델)
- Object-Oriented Model (객체지향 모델)
- Object-Relational Model (객체-관계 모델)
Levels of Abstraction in a DBMS (DBMS의 추상화 단계)

※ System Catalog (시스템 카탈로그)
- 개념 스키마, 외부 스키마, 물리적 스키마에 대한 정보가 저장되는 위치이다.
※ SQL중, DDL은 외부 스키마, 개념 스키마를 정의하기 위한 언어이다.
Conceptual Schema (=Logical Schema; 개념 스키마 = 논리적 스키마)
- DBMS의 관점에서 보는 DB이다.
- DBMS의 데이터 모델에 의해 저장되는 데이터들이 기술된다.
- RDBMS에서, 개념 스키마에는 DB에 저장되는 모든 릴레이션들에 대한 정보가 기술된다.
- 개념 스키마를 정의하는 과정을 Conceptual Database Design(개념적 데이터베이스 설계)이라 한다.
Ex. 대학 DB의 개념 스키마
Students (sid: string, name: string, login: string, age: integer, gpa: real)
Faculty (fid: string, fname: string, sal: real)
Courses (cid: string, cname: string, credits: integer)
Physical Schema (물리적 스키마)
- H/W의 관점에서 보는 DB이다.
- 추가적인 세부사항들이 명시된다.
- 개념 스키마로 기술되어 있는 릴레이션들이 Storage에 실제로 저장되는 형태가 정의된다.
- 릴레이션의 효율적인 저장과 검색을 위해 보조 데이터 구조인 Index를 사용한다.
- 물리적 스키마를 정의하는 과정을 Physical Database Design(물리적 데이터베이스 설계)이라 한다.
※ DBMS는 개념 스키마와 물리적 스키마를 분리함으로써 Data Independence(데이터 독립성)을 제공할 수 있다.
External Schema (=View; 외부 스키마 = 뷰)
- 사용자(사람)의 관점에서 보는 DB이다.
- 외부 스키마는 개념 스키마로부터 파생된, 특정 사용자 그룹의 목적에 맞도록 Customize된 하나의 릴레이션이다.
- View 개념적으로 하나의 릴레이션이지만, View 내에 있는 레코드들은 Disk에 저장되지는 않는다.
(View는 이미 릴레이션에 저장되 있는 데이터들을 재구성한 것기 때문이다.
View를 다시 저장한다면, 데이터의 중복이 발생하고 데이터 불일치를 초래할 수 있다.)
- 일반적으로, 외부 스키마는 DBMS의 데이터 모델에 의해 표현된다.
- 개념 스키마, 물리적 스키마와 달리, 외부 스키마는 1개 이상으로 존재할 수 있다.
- 사용자에게는 릴레이션과 View가 동일하게 취급된다.
- 일반적으로, View 릴레이션은 질의 요청이 들어온 즉시 계산되지만,
경우에 따라 질의의 속도를 향상시키기 위해 미리 계산하여 저장해놓는 경우도 있다.
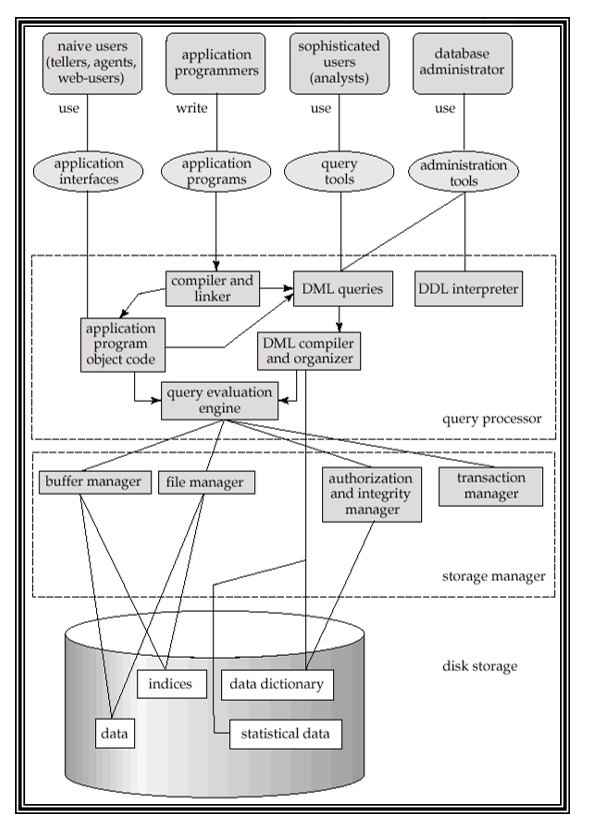
Structure of DBMS (DBMS의 구조)

| Query Evaluation Engine (질의 처리기) | - 사용자로부터 오는 SQL 질의를 분석(처리)한다. |
| Files and Access Methods | - 질의 처리기가 SQL을 분석하여 데이터에 접근하는 최적의 방법을 계산해낸다. |
| Buffer Manager | - Disk의 Data들은 I/O시에 메인 메모리에 직접 들어가는 것이 아니라, Buffer를 거쳐서 들어가게 된다. - 이러한 메인 메모리의 Buffer에 있는 데이터를 관리하는 S/W가 Buffer Manager이다. - LRU, MRU, Round-Robin과 같은 Replacement Policy를 기반으로 버퍼를 관리한다. - 즉, Main Memory Space를 효율적으로 관리하기 위한 부분이다. |
| Disk Space Manager | - Disk Space를 효율적으로 관리하기 위한 부분이다. - 새로운 데이터에는 Disk Page를 Allocate하고, 필요없는 데이터(Table)가 삭제되면 그 파일에 해당되는 Page를 Deallocate한다. |
| ※ Buffer Management와 Disk Space Management를 통해 Disk I/O 시간을 최소화시킬 수 있다. | |
| Concurrency Control | - 트랜잭션과 Locking을 구현 및 제어하는 부분이 이에 해당된다. |
| Recovery Manager | - Log를 통해, Crash가 발생했을 때 대처하는 부분이다. |
| Database | - DB에는 아래와 같은 정보들이 논리적으로, Table 형태로 저장된다. (물리적으로는, Disk File 형태로 저장된다. |
| 1) Data Files - DB의 데이터(테이블)들은 Data File 형태로 저장된다. 2) Index Files - Data File을 효율적으로 검색하기 위한 Search Key와 Record의 주소가 저장되어 있는 파일이다. - 인덱스 파일의 크기는 데이터 파일보다 작기 때문에, 데이터 파일을 직접 검색하는 것보다, 인덱스 파일을 검색하여 데이터에 접근하는 것이 더욱 효율적이다. - 일반적으로, Hash 구조 혹은 B+ Tree를 이용하여 효율적인 Indexing을 수행한다. 3) Data Dictionary - Meta Data*가 들어있는 파일이다. |
|
* Meta Data (메타 데이터)
- 메타 데이터는 DB의 데이터를 기술하는 데이터이다.
- DB 테이블의 이름, 사용자 권한, Attribute의 개수, Attribute의 이름, Attribute의 Data Type과 같은
Logical Schema에 대한 정보를 의미한다.
Ex. DBMS Structure
Application Architecture (응용 프로그램 구조)

Two-Tier Architecture
- 클라이언트가 통신망에 연결된 애플리케이션을 이용해 데이터베이스를 이용하는 구조이다.
Three-Tier Architecture
- 클라이언트가 웹 브라우저를 이용해 데이터베이스를 이용하는 웹 서버에 접근하는 구조이다.
Transaction Management (트랜잭션 관리)
- 트랜잭션은 DB 시스템에서 DB 프로그램이 실행하는 작업의 논리적 단위이다.
- 트랜잭션은 DBMS가 보는 "변경"의 기본 단위이다.
- 트랜잭션은 Atomic한 성격을 갖는다.
- DBMS는 동시에 발생되는 트랜잭션들을 Locking Protocol(잠금 프로토콜)*에 입각하여 처리해서,
사용자들이 DB 시스템을 본인만 이용하는 것처럼 느끼게 한다.
※ DBMS는 트랜잭션이 Atomicity를 갖게한다.
- 즉, 하나의 트랜잭션과 그에 연관된 모든 작업들은 다함께 성공적으로 수행되어야만 한다.
- All-or-Nothing Property : 전부 정상적으로 실행되거나, 도중에 실패하여 Roll Back되거나
Ex. 은행 계좌이체 작업에서, 10만원만큼 인출된 것은 DB에 기록되었으나,
어떤 장애가 발생하여 10만원이 입금된 것은 DB에 기록되지 않는 상황은 절대 허용되지 않는다.
- 위 예시와 같이, 도중에 장애가 발생되면 연관된 모든 작업들이 Roll Back되어 관련된 모든 작업을 취소시킨다.
* Locking Protocol (잠금 프로토콜)
- Interleave(동시에 액세스)되는 여러 트랜잭션들을 일련의 순서로 처리하기 위해 트랜잭션이 준수해야 하는 프로토콜이다.
- 여기서, Locking(잠금)이란, DB 객체에 대한 접근 제어를 의미한다.
- 트랜잭션에게 엄격한 잠금 프로토콜을 준수하게 하여 Data Inconsistency를 방지할 수 있다.
- 잠금 프로토콜은 2PL(2 Phase Locking; Shared Lock(공용 잠금)과 Exclusive Lock(전용 잠금))으로 구분된다.
1. Shared Lock (공용 잠금) = Read Lock
- 한 DB 객체에 두 개의 서로다른 트랜잭션이 동시에 소유할 수 있게하는 형태이다.
2. Exclusive Lock (전용 잠금) = Write Lock
- 한 트랜잭션이 해당 DB 객체를 독점해서 소유하게 하는 형태이다.
Ex. DB의 A라는 객체에 대해, T1 트랜잭션은 A에 데이터를 쓰고자 하고, T2 트랜잭션은 A를 읽고자 한다.
DBMS는 T1, T2에게 A에 대한 Shared Lock을 공통으로 허용할 것이다.
여기서, DBMS가 T1에게 Exclusive Lock을 허용한 순간,
T2는 T1이 A에 데이터를 다 입력할 때 까지, 하고자 하는 읽기 연산을 진행할 수 없다.
※ 2PL에서는 Deadlock(교착상태)이 발생될 수 있다.
- 트랜잭션 T1은 A에 대한 Read Lock을 확보하고 있으며, B에 대한 Write Lock을 요청중이다.
- 트랜잭션 T2는 A에 대한 Write Lock을 확보하고 있으며, B에 대한 Read Lock을 요청중이다.
- 위와 같은 상황에서는 Deadlock이 발생될 수 있다.
- Deadlock이 발생되고, 일정 시간동안 아무런 트랜잭션이 수행되지 않으면, 두 트랜잭션 중 하나를 Abort시키는 방식으로 문제를 해결한다.
- Deadlock이 발생될 수 있다는 단점에도 불구하고, 2PL 알고리즘이 사용되는 이유는, 구현이 매우 간단하기 때문이다.
* Log (로그)
- DB의 데이터에 수행한 모든 작업들에 대한 기록이다.
- 모든 작업들은 Log에 기록된 다음, 실질적인 작업이 수행된다. 기록은 절대 미뤄지지 않는다.
(이 특성을 WAL(Write-Ahead; 로그 우선 기록)이라 한다.)
- 일반적으로, 로그에는 Write Action이 기록된다.
- 로그는 예상치 못한 상황에서 트랜잭션이 중단되었을 때, 완료되지 못한 트랜잭션들에 의해 수행된 변경사항들이
DB에 남아있지 않도록 Roll Back하기 위해 사용된다.
(즉, Recovery를 구현하기 위한 수단이다.)
- 또한, 로그는 성공적으로 수행된 트랜잭션에 의해 수행된 변경사항들이 시스템 붕괴 등으로 인해 손실되지 않도록 한다.
- DBMS는 Checkpoint마다 주기적으로 데이터를 Storage에 백업한다.
- 즉, 트랜잭션이 성공하면 New Value로 Commit하고, 실패하면 Abort하고 Old Value를 다시 써놓는다.
Reference: Database Management Systems 3E (Raghu Ramakrishnan, Johannes Gehrke 저, McGrawHill, 2003)
Reference: 홍익대학교 김경창 교수님 강의록