
Processes and Threads
프로세스와 스레드
-
2.1 Processes
- Process = Job = Task = Sequential Process
- Process는 Program Execution의 기본단위이다.
- 프로그램 실행이 Abstraction된 형태를 Process라 한다.
- Thread는 CPU 할당의 기본단위이다.
- Program과 달리, Process는 수행되며 동적으로 상태가 변한다. (Dynamic Execution Context)

* Multiprocessing
- 다수의 Processor 시스템에서 다수의 Process를 구동하여 하나의 Job을 처리하는 형태를 의미한다.
* Pseudoparallelism
- 물리적으로 Parallelism이 구현된 것은 아니지만, 사용자로 하여금 Parallelism이 구현된 것처럼 느껴지게 하는 것이다.
- 여러 프로세스가 조금씩 번갈아가며 처리됨으로써 동시에 처리되는 것처럼 느껴지게 한다.
- 물리적인 Parallelism을 구현하기 위해서는 Process마다 하나의 Processor가 배정되어야 한다. (Multiprocessor 환경)
* Component of Process (프로세스의 구성요소)
- Address Space
- Program Code
- Program Data
- Execution Stack & Stack Pointer (SP) & Heap
- Program Counter (PC)
- Register (General Purpose & Status)
- System Resource
* Process Address Space

- Program이 Access할 수 있는(Process가 사용가능한) 메모리 영역을 의미한다.
(그림에서는 액세스 가능한 영역이 \(16^8\) = 4GB로 표현되어 있다.)
* Process in OS
- 각각의 Process에는 Unique한 ID, PID가 할당된다.
- OS에는 Process들을 관리하기 위한 Process Table(PT)이 정의되어 있다.
- PT의 Entry(=PCB)는 해당 Process의 정보들로 구성되며, 그 중 PID가 해당 Entry의 Index 역할을 한다.
- PT의 Entry는 Process Control Block(PCB)라고 부른다.
- Linux에서 PCB는 \(\texttt{task_struct}\)로 정의되어 있으며, 70개 이상의 Fields로 구성되어 있다.
- Windows XP에서 PCB는 \(\texttt{EPROCESS}\)로 정의되어 있으며, 약 60개의 Fields로 구성되어 있다.
* Component of PCB (Process의 구성요소와 일맥상통)
| Component of PCB | Description |
| Execution State | - Ready, Running, Blocked State |
| PC, SP, General Purpose Registers | - Process가 구동 중일 때의 State 정보를 저장할 H/W 정보 - 프로세스는 탄생부터 소멸까지 지속적으로 CPU를 점유하고 있지 않기 때문에 백업의 용도로써 State를 저장할 필요가 있다. |
| Memory Management Information | - Segments, Page Table, Stats 등 |
| Privilleges Information & Owner Information | |
| Scheduling Priority | - CPU 할당에 대한 우선순위 정보 |
| Resource Information | - OS에 관련된 Resource를 포함하여, Process와 관계된 H/W Resource 정보 |
| Accounting Information |
* PCB Structure (PCB 구조)

- User ID, Gruop ID: 해당 프로세스에 대한 권한에 관련된 정보이다.
* Process Creation (프로세스 생성)
- \(\texttt{init}\) 프로그램에 의해 시스템이 초기화되고, 프로세스를 생성하는 System Call(\(\texttt{fork}\))을 호출할 때, 프로세스가 새로 생성된다.
- 프로세스가 다른 프로세스를 Create할 수 있으며, 이 때 생성시킨 Process는 Parent Process라 하며,
생성된 Process는 Child Process라 한다. (UNIX System에서의 표현)
- Child가 생성됐을 때, Parent는 Child를 대기할 수도 있고, Child와 함께 병행처리될 수도 있다.
- UNIX 시스템에서는 \(\texttt{ps}\) 명령어 혹은 PPID Field를 확인하여 Process간 관계를 확인할 수 있다.
- UNIX 시스템에서는 Parent Process의 대부분의 정보들이 Child Process에게 Inherit된다.
- UNIX 시스템이 부팅될 때 생성되는 최초의 프로세스는 \(\texttt{init}\) Process이며, 모든 Process는 \(\texttt{init}\) Process로 부터 파생된다.
* \(\texttt{pid_t fork(void)}\) System Call
- UNIX System에서 프로세스를 생성할 때 호출하는 시스템 콜이다.
- Parent는 \(\texttt{fork()}\)를 계속해서 호출하여 다수의 Child를 생성할 수 있다.
- PT에 PCB 하나를 할당하고 초기화한다. 새로운 PCB는 Ready Queue에 위치된다.
(Ready Queue는 CPU를 쓸 수 있는 상태(=Ready State)의 프로세스들이 대기하는 공간이다.)
- 새로운 프로세스에 새로운 Address Space를 할당한다. (Page Table을 만든다.)
- Parent의 Address Space에 있는 데이터를 Child에 복사한다.
- OS가 Parent에게 할당했던 리소스 또한 Child에 할당한다.
※ \(\texttt{fork()}\)는 두 번의 리턴을 수행한다.
- Parent 측의 \(\texttt{fork()}\)는 Child의 PID를 리턴하며,
Child 측의 \(\texttt{fork()}\)는 무조건 0을 리턴한다.
- 새로 생성된 Child에서는 코드의 첫 부분이 아닌, \(\texttt{fork()}\)가 리턴하는 부분부터 실행된다.
- Child도 \(\texttt{fork()}\)를 호출하여 자신의 Child를 생성할 수 있다.
- Child측에서 \(\texttt{fork()}\) 명령 이후에 \(\texttt{exec()}\) 계열의 명령을 실행시켜서, Parent와 다른 프로그램을 실행시킬 수 있다.
Example.

- Parent측에서 \(\texttt{fork()}\)를 통해 PID = 70인 Child를 정상적으로 생성했으므로,
Parent의 \(\texttt{global}\) 변수는 110으로 업데이트 된다.
(즉, \(\texttt{else}\) 구문이 실행되어 기존의 \(\texttt{global}\) 변수에 100이 더해진다.)
- 생성된 Child에서는 코드의 맨 처음부터 실행되는 것이 아닌, \(\texttt{fork()}\)의 리턴부부터 실행된다.
(Child에서 \(\texttt{fork()}\)가 "호출"되는 부분부터 실행되는 것이 아니라, \(\texttt{fork()}\)가 "0을 리턴"되는 부분부터 실행되는 것이다. \(\texttt{fork()}\)가 실행되는 것이 아니다.)
- Child측에서의 \(\texttt{fork()}\)는 무조건 0을 리턴하므로, \(\texttt{global}\) 변수는 20으로 업데이트 된다.
(즉, Child측에선 \(\texttt{if}\) 구문이 실행되어 기존의 \(\texttt{global}\) 변수에 10이 더해진다.)
- Child측의 코드에 \(\texttt{fork()}\)를 추가하여 Child의 Child를 생성하게 할 수 있다.
(두 번째 \(\texttt{fork()}\) 호출은 첫 번째 \(\texttt{fork()}\) 호출보다 반드시 뒤에 위치해야 할 것이다.
Child 프로그램은 맨 처음부터가 아닌, 첫 번째 \(\texttt{fork()}\) 호출부터 실행되기 때문이다.)
* \(\texttt{int exec(char *prog, char **argv)}\) System Call (URL)
- 프로세스가 처리중이었던 프로그램을 멈추고, \(\texttt{prog}\) 프로그램을 새로 로딩하는 시스템 콜이다.
(새로운 프로세스를 생성하는 것이 아니고, 기존의 프로세스를 실행하는 것이다.)
- 프로세스 자체는 유지되므로, PID는 바뀌지 않는다.
- 새로운 프로그램이 로딩되기 때문에, Address Space가 바뀌게 되며, 바뀐 프로그램의 첫 부분부터 실행된다.
(H/W Context, Arguments 등이 전부 바뀐다. 또한, \(\texttt{fork()}\)처럼 마지막 부분부터 재개되는 것이 아니라, 처음부터 시작된다.)
- \(\texttt{prog}\) 프로그램에 해당되는 프로세스가 CPU를 사용할 수 있도록 Ready Queue에 삽입한다.
- \(\texttt{exec()}\)는 에러가 발생되면 -1을 리턴한다.
- \(\texttt{exec()}\) 호출이 성공하면 수행할 프로그램 내용이 바뀌므로, 호출 성공시의 리턴값이 의미가 없다.
(\(\texttt{exec()}\) 호출에 성공하면, 이후의 명령들은 수행되지 않는다.)
- \(\texttt{exec()}\)가 호출되어도 PCB의 Privileges and Owner Information, 스케쥴링 우선순위, 리소스 정보, 어카운팅 정보는 그대로 유지된다.
※ \(\texttt{exec()}\) 계열 시스템 콜이 여러 형태로 존재하는 이유 (편의성을 위함)
- Argument를 List형태로 Passing하기도 하고, Vector형태로 Passing하기도 한다.
- 또한, Vector형태의 Environment Variable를 Passing할 수도 있다.
- 수행할 프로그램 파일의 절대경로를 명시할 수도 있고, 상대경로(\(\texttt{path}\) 환경변수)를 명시할 수도 있다.
- 기본이 되는 시스템 콜은 \(\texttt{execve()}\) 하나이다. 다른 \(\texttt{exec()}\) 계열 시스템 콜들은 \(\texttt{execve()}\)를 기반으로 다시 작성된 형태이다.
Example.

* \(\texttt{pid_t wait(int *wstatus)}\) System Call
- Parent측에서 \(\texttt{wait()}\)을 호출하면, Child가 Terminate될 때까지, Parent의 처리를 일시정지시킨다.
- OS Kernel은 PT를 참고하여, Child가 Terminate되면 Parent의 \(\texttt{wait()}\)을 리턴시킨다. (Parent 프로세스를 재개한다.)
Example. A Simple Shell
#define TRUE 1
while (TRUE) {
type_prompt();
read_command(command, parameters);
if (fork() != 0) {
/* Parent Code */
waitid(-1, &status, 0);
}
else {
/* Child Code */
execve(command, parameters, 0); // 프로세스가 읽어들인 명령어(command)를 실행하게한다.
}
}* Process Termination (프로세스 종료)
1) Normal exit (Voluntary)
- \(\texttt{main()}\)에 \(\texttt{exit(0)}\)이 호출되어 프로세스를 정상적으로 종료시키는 형태이다.
+ Abnormal Termination: \(\texttt{abort()}\)
- 비정상적인 종료를 수행하는 System Call로, SIGABRT 신호를 생성한다.
2) Error exit (Voluntary)
- 오류가 발생한 경우로, \(\texttt{main()}\)에서 \(\texttt{exit(1)}\)이 호출되어 비정상적인 종료를 수행하는 형태이다.
- \(\texttt{exit()}\)의 Argument(= Exit Status Value)로 0이 아닌 숫자를 넘기면, Kernel은 오류로 인한 종료로 간주한다.
- Exit Status Value는 해당 프로세스의 Parent가 받아볼 수 있다. 이 값을 통해 오류의 종류를 구분한다.
3) Fatal error (Voluntary)
- Illegal Instructions: 잘못된 명령어 사용이 감지되면 발생하는 경우이다.
- Referencing Nonexistent Memory: 포인터 값 설정에서 오류(=Fault)가 발생한 경우이다.
- Dividing by Zero: 0으로 값을 나누는 오류가 발생한 경우이다.
4) Killed by another process (Involuntary)
- 다른 프로세스의 \(\texttt{kill()}\) 호출로 인해 프로세스가 종료되는 경우이다.
* \(\texttt{void exit(int status)}\) System Call
- \(\texttt{atexit()}\)에 의해 등록된 모든 Exit Handler를 호출한다.
- 모든 표준 I/O Stream들을 닫는다.
- \(\texttt{_exit()}\)은 \(\texttt{exit()}\)을 호출하고 UNIX-Specific 세부사항을 제어하는 System Call이다.
※ Parent가 Terminate되면, 그 Child들의 PPID값은 \(\texttt{init}\) 프로세스의 PID값으로 설정된다.
- Terminate된 Parent의 Child 프로세스들을 Orphan Process(고아 프로세스)라 부른다.
- 이미 Terminate된 프로세스의 PID를 고아 프로세스들이 PPID로 계속 유지할 경우,
PID를 Recycle하는 과정에서 새로운 프로세스가 고아 프로세스의 Parent가 아님에도 Parent로 인식하는 문제가
발생할 수 있기 때문에, 고아 프로세스들의 PPID를 \(\texttt{init}\)의 PID로 대체하는 것이다.
* Process Hierarchy (프로세스 계층구조)
- UNIX System에서 Process들은 Parent와 Child의 관계로 구성되어 계층구조(Process Gruop)를 형성한다.
- Windows에는 프로세스 계층구조 개념이 없다. Windows에서 모든 프로세스들은 동등하다.
* Process States (프로세스 상태)

- 프로세스는 크게 Ready, Running, Block 상태로 존재한다.
- 프로그램은 아래 3가지 상태 사이에서 전환되며 수행된다.
- UNIX System에서는 \(\texttt{ps}\) 명령어를 통해 Process의 상태를 확인할 수 있다.
1) Ready State
- 프로세스들이 Ready Queue 내에 위치하여, CPU를 할당받기를 기다리는 상태이다.
2) Running State
- 프로세스가 CPU를 할당받아(Schedule), 프로세스의 Instruction들이 Fetch되어 수행중인 상태이다.
- CPU Core 개수만큼의 Process가 H/W적으로 동시에 수행될 수 있다.
3) Block State (Waiting State)
- 프로세스가 어떠한 원인에 의해, CPU가 할당된다해도 더 이상 진행되지 못하는 상태이다.
- 또한, 한 프로세스에 대해 CPU 점유가 일정시간 이상 이루어졌다면,
다른 프로세스에도 CPU를 할당하기 위해 해당 프로세스를 Block되기도 한다. (Unschedule)
- 주로 I/O Request, Page Fault 등으로 인해 발생되는 상태이다.
* Context Switch
- CPU가 처리하던 프로세스를 다른 프로세스로 바꾸는 것을 의미한다.
- 즉, 수행중이던 Execution Context가 바뀌는 것이므로 이에 대한 Overhead가 존재한다.
| Context Switch Steps |
| 1. PC와 Register에 저장된 데이터들을 지정된 Stack 위치에 저장한다. (백업한다.) |
| 2. Interrupt Vector가 가리키고 있는 주소에 위치한 Interrupt Handler Routine을 실행한다. |
| 3. Step 1에서 저장하지 못했던 Register 값들을 저장한다. (백업한다.) - 이 과정은 CPU에 직접적인 관련이 있는 부분이어서, C 언어가 아닌, Assembly 언어로 작성된다. |
| 4. 새로운 Stack을 Set up한다. |
| 5. C 언어로 작성된 Interrupt Service Routine을 실행한다. - 이 때, 새롭게 Set up한 Stack을 이용한다. |
| 6. CPU Scheduler Routine이 실행된다. Ready Queue 내에 있는 프로세스 중 하나를 선택한다. |
| 7. 처리할 프로세스의 PCB로 부터 CPU를 Loading하는데, 이 과정에서 Assembly Code가 실행된다. |
| 8. PCB에 저장되어 있던 CPU State들을 모두 Reload시킨다. |
※ 처리할 프로세스를 변경하면 Context Switching이 무조건 수행된다.
하지만, User Mode에서 Kernel Mode로의 Mode Switching이 발생되었을 경우에는
CPU Architecture마다 Context Swtiching(Register Saving)을 수행하는 경우가 있고, 그렇지 않은 경우가 있다.
Example.

1) read() System Call이 호출되어 Kernel Mode로의 Switch가 발생한다.
2) read()에 해당되는 System Call Dispatch Routine이 수행된다. (즉, read()가 수행된다.)
3) read()가 I/O를 요청하고, I/O Device가 이를 처리한다.
이 때, Program 1을 수행하는 Process는 Block 상태가 된다. (이하, Program 1이 Block 상태가 되었다 표현한다.)
4) Program 1이 Block 상태가 되어, CPU를 더 이상 사용하지 못하게 되었기 때문에,
schedule()이 수행되고, Program 2에게 CPU를 할당하기로 Scheduling한다.
5) Program 1에서 Program 2에게 CPU를 할당하기 위해, Context Switch가 발생한다.
6) Program 2가 처리되던 중, I/O Device가 Program 1이 요청한 작업을 완료하여 I/O Done Interrupt Signal을 발생한다.
(이 때, Program 2는 다시 Ready 상태가 된다.)
7) Kernel이 Interrupt Signal를 감지하여 어떤 프로세스의 요청이 완료됐는지를 확인한다.
8) Interrupt가 발생했으므로, 다시 schedule()이 수행되어 CPU를 할당받을 적절한 프로세스를 선정한다.
(이 때, Program 1에게 CPU를 할당하기로 선정했다 가정하자.)
9) Program 1에게 다시 CPU를 할당하기 위해, Context Switch가 발생한다.
(Program 2의 State는 Save되고, Program 1의 State는 Restore된다.)
10) Program 1이 다시 CPU를 할당받아, 명령을 수행한다.
※ Scheduler는 Monolithic Kernel에서는 단순히 Function의 형태로 구현되고,
Microkernel에서는 하나의 Process로 구현될 수도 있다.
(위 예시에서는 함수의 형태로 구현되어 있으므로, Monolithic Kernel Approach라 볼 수 있다.)
2.2 Threads
Parallel Program
- 하나의 Job을 여러 부분으로 나눠 동시에 처리하는 방식의 프로그램이다.
- Parallel Processing을 위해, 다수의 프로세스가 필요하며, 프로세스 간 데이터를 공유할 수 있어야 한다.
- 프로세스 간 데이터 공유는 \(\texttt{shmget()}\) System Call*을 이용한다.
- PCB, Page Table 등을 생성해야 하기 때문에 Memory 측면에서 비효율적이고,
OS Structure 생성, Address Space 복사 및 생성 등의 이유로 시간 측면에서도 비효율적이다.
* \(\texttt{shmget()}\) System Call (URL)
- 프로세스들 간에 데이터를 공유할 수 있게 하는 수단이 되는 시스템 콜이다.
(본래, 프로세스들은 서로 다른 Address Space를 갖기 때문에 데이터를 공유할 수 없다.)
- 오버헤드가 비교적 크다.
Thread (=Lightweight Process)
- 스레드는 CPU를 할당할 수 있는 가장 작은 단위이다.
- 하나의 프로세스 내에는 동시에 여러 스레드가 구동될 수 있으며,
각 스레드들은 서로 공유가 가능한 부분은 공유하며 효율적으로 프로세스 내에서 존재한다.
- 스레드들은 같은 Address Space(Code, Data), 같은 Privilege, 같은 Resource(File, Socket 등)들을 공유하는 형태로 존재한다.
(그래서 스레드 간 정보 공유의 Cost는 저렴하다.)
- 한 프로세스의 PCB에서 공유 가능한 부분들은 공유하며,
공유가 불가능한 레지스터, PC, SP, Program Status Word와 같이 스레드가 개별적으로 가져야 하는 부분은
각 스레드들이 개별적으로 가져가며 존재한다.
(스레드에는 CPU H/W Execution Context와 Stack만 따로 할당하면 된다. 나머지 부분은 프로세스의 것을 그대로 가져온다.)
- 다수의 Sequential Execution으로 구성된 프로그램 내에서 스레드는 하나의 Sequential Execution을 담당하여 처리한다.
- 스레드 또한, 프로세스와 마찬가지로 각자의 State Transition을 갖는다.
※ Process = Resource Group + Thread of Execution
* Address Space with Thread
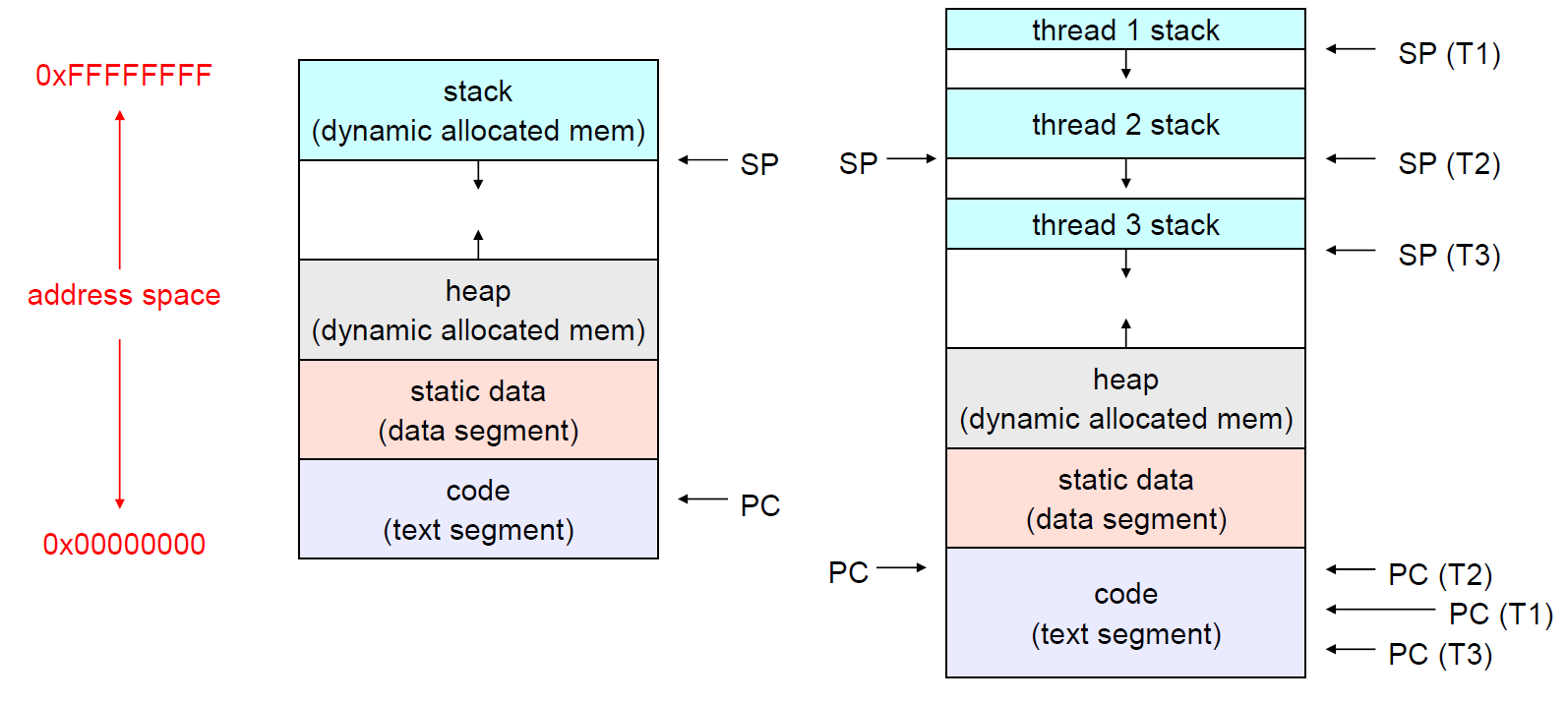
- 한 프로세스 내에 다수의 스레드가 존재하면, 각각의 스레드는 하나의 Address Space내에서 개별적인 Stack 영역을 갖는다.
- 위 구조에서 볼 수 있다시피, 각각의 스레드는 하나의 프로세스 메모리 영역 내에 존재하므로,
Global Variable(static data에 있는)값과 같은 값들을 쉽게 공유할 수 있다.
* Kernel Level Thread
- OS Kernel이 관리하는 스레드이다.
- 프로세스와 거의 유사하다.
* User Level Thread
- User의 Library Function들이 관리하는 스레드이다.
Thread 구조의 장점
1) 많은 Application들이 여러 부분이 동시에 처리될 수 있는 구조이기 때문에 Thread 구조는 이들에게 효율적이다.
2) Thread Programming Model은 단순하다.
3) Thread들은 Address Space를 공유하므로, 데이터 교환이 단순하게 이루어진다.
4) Thread는 Process보다 생성, 소멸 등의 관리적인 측면에서 훨씬 용이하다.
(시간, 메모리 측면에서 프로세스보다 효율적이다.)
* Interprocess Communication : 프로세스 간 정보 교환 메커니즘이다. (Cost가 높다.)
5) Thread도 Process처럼, I/O 연산과 CPU 연산 사이를 Overlapping할 수 있고, Blocking System Call이 제공된다.
Threads and Processes
| Process당 할당되는 자원들 | Thread당 할당되는 자원들 |
| Address Space Global Variables Open Files Child Processes Pending Alarms Signals and Signal Handlers Accounting Information |
Program Counter (H/W Execution Context) Registers (H/W Execution Context) Stack State |
- 각 스레드들은 독자적인 Function Call을 수행하기 때문에, 스레드끼리 Stack을 공유하면 Overwrite이 발생될
가능성이 높으므로, 스레드는 고유의 Stack을 할당받아야 한다.
- 스레드는 한 프로그램의 메모리 영역내에 존재하기 때문에 버그가 생겨 스레드가 죽으면 해당 프로세스 전체가 죽어버리게 된다.
(반대로, 프로세스는 다른 프로세스가 죽는다 해서 영향을 받지 않는다.)
POSIX Thread System Call
| Thread Call | Description |
| Pthread_create | 새로운 스레드를 생성한다. |
| Pthread_exit | 스레드를 Terminate한다. |
| Pthread_join | 특정 스레드가 exit되기까지 대기한다. |
| Pthread_yield | 다른 스레드가 CPU를 할당받도록 양보한다. |
| Pthread_attr_init | 스레드의 Attribute Structure를 생성하고 초기화한다. |
| Pthread_attr_destroy | 스레드의 Attribute Structure를 제거한다. |
Example. Pthread Creation and Termination
#include <pthread.h>
#include <stdio.h>
void *PrintHello(void *id) {
printf("Thread%d: Hellow World!\n", id);
pthread_exit((void) *id); // process에서의 exit()와 유사
}
int main(int argc, char *argv[]) {
void *status;
pthread_t thread0, thread1;
pthread_create(&thread0, NULL, PrintHello, (void *) 0); // process에서의 fork()와 유사
pthread_create(&thread1, NULL, PrintHello, (void *) 1);
pthread_join(thread0, &status); // 스레드 thread0이 끝나길 기다린다.
printf("status %x\n", status);
pthread_join(thread1, &status); // 스레드 thread1이 끝나길 기다린다.
printf("status %x\n", status);
}- 위 POSIX Function Mechanism에서는 하나의 함수를 Thread로 만들어 독립적으로 구동되는 Entity로 만든다.
(근본적으로, 함수와 스레드는 같은 개념이 아니다.)
- pthread_join함수는 pthread_exit의 Argument *id를 넘겨받는다.
Output:
Thread0: Hello World!
Thread1: Hello World!
status 0
status 1
Kernel Level Thread
- System Call을 통해 Creation되고 Management되는 스레드이다.
(System Call을 호출한다는 것은 곧 OS Kernel을 불러낸다는 것과 같다.)
- Kernel Level Thread의 모든 Operation은 System Call을 통해 수행된다.
- Kernel Level Thread는 OS의 System Call에 의해 관리되기 때문에 처리속도가 느리다.
(매번, OS가 호출되어야 하고, 잦은 Mode Switching에 따른 Context Switching에 따른 Overhead가 큰 편이다.)
- 한 프로세스에 특정 Thread가 Block되어도, 다른 Thread들은 Block되지 않고, OS에 의해 다시 Scheduling된다.
- 다수의 CPU(Core)로 구성된 시스템에서는 Kernel Level Thread를 운용하는 것이 유리하다.
User Level Thread
- OS와 무관하게, Library가 스레드를 내부적으로 Creation하고 Management한다.
- Library(Run-time system)는 하나의 프로세스내에 Thread table을 통해 스레드를 관리한다.
- Kernel에게는 Process table만 보이기 때문에, Kernel은 User Level Thread의 존재를 모른다.
- User Level Thread는 오로지 Library Function들에 의해 관리되기 때문에 Kernel Level Thread보다 처리속도가 빠르다.
(Trap으로 인한 Mode Switching에 따른 Overhead가 없다.)
- User Level Thread들은 하나의 CPU를 공유할 수 밖에 없다.
(Kernel은 User Level Thread의 존재를 모르기 때문에, 하나의 프로세스에 최대 하나의 CPU만 할당하기 때문이다.)
- Kernel은 프로세스에 CPU를 할당하고, Library가 User Level Thread에 CPU를 할당한다.
- OS의 관여가 필요없으므로, Scheduling Algorithm이 보다 Customizable하다.
- Kernel Level Thread보다 더 큰 Scale로 운용이 가능하다. (많이 생성할 수 있다.)
* User Level Thread의 한계
- User Level Thread는 Cost가 적은 대신, 여러 제한들이 존재한다.
1) Blocking System Call
- OS는 User Level Thread의 존재를 모르기 때문에, 하나의 User Level Thread가 Block되면 전체 Thread가 Block될 수 있다.
- Non-Blocking System Call은 Block이 예상되면, Asynchronous Call들을 호출하거나,
곧바로 return하여 어떻게든 Block되는 것을 방지한다.
- 즉, Non-Blocking System Call을 통해 IO를 요청한 Thread는 Block 되지 않고,
주기적으로 Library에게 IO요청 완료여부를 확인받게 된다.
(이런 형태의 IO를 Asynchronous IO라 한다.)
2) Page Fault
- Memory Access시에 Page Fault가 발생되면, OS는 해당 프로세스를 Block시키기 때문에,
Page Fault에 무관한 Thread들까지 전부 Block된다.
3) Infinite Loop
- CPU를 할당받은 한 Thread가 무한루프에 진입하게 되면, Scheduler는 CPU 제어 권한을 다시 회수하기 힘들어진다.
- User Level Thread는 Signal Mechanism과 같이, Thread가 무한루프에 진입할 것이 예상되면
자발적으로 CPU를 다른 Thread에게 양보하는 메커니즘에 의존하고 있는 실정이다.
(Signal Mechanism은 코드의 복잡도를 증가시킨다.)
Hybrid Implementation

- 하나의 Kernel Level Thread에 다수의 User Level Thread를 Mapping해놓은 형태이다.
- 하나의 Kernel Level Thread에 연결된 User Level Thread들이 Block되어도,
다른 Kernel Level Thread에 연결된 User Level Thread들은 Block되지 않는다.
- User Level Thread의 제한들을 보완한 형태이다.
2.3 Interprocess Communication (IPC, Synchronization)
- 구동되는 다수의 Entity들을 수행에 문제가 없게끔 맞춰주는 작업을 Synchronization이라 한다.
(여기서 Entity는 프로세스와 스레드 등 모두를 아우르는 개념이다.)
- 여러 Thread가 하나의 자원을 공유하는 형태인 Multithreaded Program에서는 Synchronization이 필수적이다.
(Synchronization은 Multithreaded 시스템 뿐만 아니라, Parallel 개념이 적용된 모든 시스템에 필수적인 개념이다.)
2.3.1 Race Condition (경합 조건)
- Mlutiprogramming 시스템에서 Timing에 따라, 결과가 Non-Deterministic해지는 상황을 의미한다.
- OS가 해결해야 하는 주요한 문제점 중 하나이다.
Example. Race Condition in withdraw() Function

- 두 스레드가 각자의 withdraw() 함수를 수행한다 가정하자.
- account는 Global Structure이다. (이 구조체는 멤버로 Balance를 갖는다.)
- balance는 withdraw() 함수 내의 Local Variable이다.
- 초기에 account = 100에 있는 balance 값은 10,000이라 가정하자.
- Thread 1은 왼쪽 withdraw() 함수(초록색)를 수행하며, account = 100, amount = 1000 으로 Argument를 넘겨받았다.
- Thread 2는 오른쪽 withdraw() 함수(빨간색)를 수행하며, account = 100, amount = 2000 으로 Argument를 넘겨받았다.
(즉, 100번 계좌에 대해, Thread 1은 1000을 인출(withdraw)하고, Thread 2는 2000을 인출하는 연산을 동시에 진행하는 것이다.)
- 두 스레드가 Sequential하게 수행되면 문제가 없지만, Parallel하게 수행되는 순간, Race Condition 문제가 발생하게 된다.

- Thread 2가 \(\texttt{balance -= amount;}\)까지 수행하고, Context Switch가 발생하여,
Thread 1이 자신의 \(\texttt{withdraw()}\) 함수를 수행하고, Thread1는 \(\texttt{withdraw()}\) 함수 전체를 완수한다 가정하자.
(즉, \(\texttt{account[100].Balance}\)에 9000이 저장된다.)
- Thread 2에 CPU가 다시 할당되면, Thread 2은 \(\texttt{put_balance(account, balance);}\)부터 수행하게 되는데,
이 구문이 수행되면, \(\texttt{account[100].Balance}\)에 8000이 저장된다.
- 따라서, 총 3000원을 withdraw(인출)했지만, \(\texttt{account[100].Balance}\)에 8000이 저장되는 상황이 발생된다.
※ 두 개의 Concurrent Thread들이 Shared Resource*에 어떠한 Synchronization없이 접근할 경우,
Race Condition이 발생될 수 있다.
* Shared Resource : Global Variables, Dynamic Objects
2.3.2 Critical Regions (Critical Section)
- 프로그램 코드 중, Shared Resource에 접근하는 부분을 Critical Region(Critical Section)이라한다.
* Mutex (Mutual Exclusion)

- Shared Resource에 Synchronized하게 접근하는 메커니즘 중 하나이다.
- 한 Entity가 Critical Region을 수행중일 때, 다른 Entity가 Critical Region에 접근을 시도하면,
해당 Entity를 일단 Block시키고, Critical region에 접근 가능해질 때, Block 상태를 해제하고
Critical Region에 대한 접근을 허용하는 방법이다.
- 즉, Critical Region에 대한 접근을 Serialization하는 것이다.
* CSP Requirements (CSP : Critical Section Problem)
- Critical Section이 Serial하게 수행되기 위해서는 아래 조건들을 만족해야 한다.
1) Mutual Exclusion
- Critical Section이 상호 배제적으로 수행되어야 한다.
2) Bounded Waiting (No Starvation)
- Critical Section에 진입하기 위해 대기하는 Entity에 대한 Starvation 문제가 없어야 한다.
3) Progress
- Critical Section이 비어있음에도 진입하지 못하는 문제가 없어야 한다.
4) No Assumption made regarding speed, number of CPUs
- CPU 스펙에 의존적인 방법이어서는 안된다.
- 즉, CPU Core의 개수가 몇 개이든, 처리속도가 빠르건 느리건, 모든 경우에서 수행할 수 있는 방법이어야 한다.
* Mechanisms for Solving the CSP
- CSP를 해결하기 위한 메커니즘들은 아래와 같다.
(Locks, Semaphores, Monitors, Messages)
- Locks, Semaphores, Monitors 방법은 Shared Memory 환경에서 사용하는 방법이고,
Messages 방법은 Non-Shared Memory 환경에서 사용하는 방법이다.
2.3.3 Mutual Exclusion with Busy Waiting
1) Interrupt를 Disable하는 방법
- Critical Section을 수행하는 동안, Interrupt가 발생하면 무시함으로써
Critical Section을 처음부터 끝까지 한 번에 완수할 수 있게 한다.
- 즉, Critical Section을 수행하는 동안에는 Context Switch를 일어나지 않게 하는 방법이다.
- Interrupt를 무시하는 방법
= Context Switch를 일어나지 않게 하는 방법
= OS를 부르지 않는 방법
= 다른 Process가 해당 Critical Section을 수행하지 못하게 하는 방법
※ Interrupt를 Disable하는 방법은 환경에 제약적이고 위험한 방법이다.
- Multi-Processor 환경에서는 다른 CPU에 의해 다른 프로세스가 Critical Section을 수행할 수 있기 때문에,
Multi-Processor 환경에서는 사용될 수 없는 방법이다.
(즉, Single-Processor 환경에서만 사용될 수 있다.)
- Interrupt를 Enable/Disable하는 명령어는 Privilege Instruction이고,
Privilege Instruction을 User-Mode에서 사용할 수 있게 허용해야 하기 때문에 위험하다.
2) Lock Variables를 사용하는 방법
// Lock Variable 'lock'
// lock == 0 -> Critical Region empty
// lock == 1 -> Critical Region occupied
while ( lock == 1 ); // Waiting
lock = 1;
Critical_Region();
lock = 0;- 여러 프로세스가 접근 가능한 Global 변수인 Lock Variable을 통해
각 프로세스들은 Critical Region의 Availability를 확인할 수 있다.
- 특정 타이밍(lock값이 0일 때)에 다수의 프로세스가 Critical Region에 동시에 진입하는 문제가 생길 수 있다.
(즉, 완전한 Mutex를 구현할 수 없다.)
3) Strict Alteration

- Critical Region에 진입하고자 하는 두 개의 Process가 있을 때, Process a는 Code (a)를 수행하고,
Process b는 Code (b)를 수행하게 된다.
- turn값이 0이면, Process a가 Critical Region을 수행하고,
turn값이 1이면, Process b가 Critical Region을 수행한다.
- turn값이 동시에 0 혹은 1일 수는 없으므로, Critical Region에 하나의 프로세스만 진입할 것이 보장된다.
(즉, Mutex Condition은 만족시킨다.)
- Process a와 Process b가 반드시 번갈아가며 수행해야 하므로,
Critical Region이 비어있다 할지라도, 두 번 이상 연속적으로 Critical Region에 접근하지 못한다.
(즉, Progress Condition을 만족시키지 못한다.)
* Busy Waiting
- 위 (a), (b) 코드의 while Loop에서와 같이, 특정 변수값을 계속 Testing하며 기다리는 동작을 의미한다.
- 실질적인 일은 수행하지 않지만, CPU는 계속 사용하고 있는 상태이다.
- Busy Waiting 방식은 추가적인 방법이 도입되지 않는 한, Starvation 문제는 해결되지 못한다.
* Spin Lock
- Lock Variable에 대한 Busy Waiting을 특정짓는 용어이다.
- Loop를 계속해서 돌며 Lock값을 확인하기 때문에 CPU가 낭비된다.
* Priority Inversion Problem
- leave_region을 수행하여 Lock값을 Release해야하는 프로세스 B의 우선순위가
enter_region을 수행하여 Lock값을 얻고자 하는 프로세스 A의 우선순위보다 낮아서,
A는 무한루프를 돌며 Lock값을 계속 Checking하고, B는 Lock값을 해제하지 못하는 상황을 의미한다.
4) Peterson's Solution (S/W Solution)
#define FALSE 0
#define TRUE 1
#define N 2 // number of processes
int turn; // whose turn is it?
int interested[N]; // all values initially 0 (FALSE)
void enter_region(int process) // process 0 or 1
{
int other; // number of the other process
other = 1 - process; // the opposite of process
interested[process] = TRUE; // show that you are interested
turn = process; // set flag
while(turn == process && interested[other] == TRUE); // stanby loop
}
void leave_region(int process) // process: who is leaving
{
interested[process] = FALSE; // indicate departure from critical region
}
...
enter_region(proc);
critical_region();
leave_region(proc);- CSP를 해결하기 위한 4가지 요구사항을 모두 충족하는 S/W적인 방법이다.
- 코드 자체의 복잡성이 크고, Overhead가 작지 않다.
5) TSL Instruction (H/W Solution)
// Semantics of TSL
bool TSL(bool *flag)
{
bool old = *flag;
*flag = true;
return old;
}
TSL(lock);
// lock Variable 값을 1로 세팅하되 lock Variable의 기존값을 리턴한다.
// 전 과정을 Atomic하게 진행한다.- TSL은 CPU가 제공하는 Low-Level 명령어이다. (S/W적 방법이 아닌, H/W적 방법이다.)
- TSL(Test and Set Lock)은 Atomic Instruction*이기 때문에, 여러 프로세스에 의해 동시에 실행되지 않고,
한 번에 하나의 프로세스에서만 수행된다. (Interrupt의 방해를 받지 않는다.)
- 즉, TSL을 통한 Critical Region 접근은 Mutex를 보장한다.
- TSL은 Memory BUS를 통해 메인 메모리를 read하여 Lock 변수 값을 메모리로부터 읽어오고,
Lock 변수에 true값을 write하는데, 이러한 전 과정이 Interrupt의 방해를 받지 않는다.
(즉, TSL이 수행되는 동안, 다른 프로세스들이 Lock 변수가 저장된 메인 메모리에 접근하지 못한다.)
- 여러 CPU 중, TSL을 수행할 CPU를 선정하는 일은 Memory BUS를 제어하는 H/W가 수행한다.
- TSL은 Microscopic, Primitive한 개념이고, Synchronization을 구현하기 위한 프로그래밍 시에는
더욱 High-Level 개념을 사용한다.
* Atomic Instruction
- 명령어가 수행되기 시작하고 완수될 때 까지 Interrupt를 받지 않는 명령어이다.
- H/W가 지원하는 Atomic 명령어로는 TSL, Swap, Compare & Swap 등이 있다.
* Example using TSL
lock - false;
repeat
while TSL(lock) do no-op;
critical_region();
lock = false;
remainder_section();
until false
* TSL을 이용한 Peterson's Solution 구현
enter_region:
TSL REGISTER, LOCK ! LOCK : Lock Variable이 저장된 메모리 주소
! Lock Variable 값을 REGISTER을 가져옴과 동시에, Lock 값을 1로 세팅한다.
CMP REGISTER, #0 ! REGISTER 값과 0(Zero)을 비교한다.
JNE enter_region ! Lock Variable 값이 0이 아니면, Loop를 돌며 Busy Waiting을 수행한다.
RET ! Lock Variable 값이 0이면, enter_region을 빠져나와 Critical Region을 수행한다.
CRITICAL_REGION:
...
leave_region:
MOVE LOCK, #0 ! Lock Variable 값을 0으로 설정하고 leave_region을 빠져나온다.
RET- enter_region과 leave_region 사이에 Critical Region을 수행하는 코드가 삽입돼있는 구조이다.
* XCHG를 이용한 Peterson's Solution 구현
enter_region:
MOVE REGISTER, #1 ! REGISTER에 1(One)을 저장한다.
XCHG REGISTER, LOCK ! REGISTER값(1)과 Lock값을 Atomic하게 Swapping한다.
CMP REGISTER, #0 ! REGISTER값(Lock값)을 0과 비교한다.
JNE enter_region ! REGISTER값(Lock값)이 0이 아니면, Loop를 반복하며 Busy Waiting을 수행한다.
RET
CRITICAL_REGION:
...
leave_region:
MOVE LOCK, #0 ! Lock Variable 값을 0으로 설정하고 leave_region을 빠져나온다.
RET- XCHG 또한 Atomic Instruction이다.
- XCHG를 이용하면, TSL과 달리, Lock Variable에 0/1 이외에 사용자가 원하는 값을 넣을 수 있다.
- 반면, TSL을 이용한 방법보다 하나의 Instruction을 더 수행해야 한다.
2.3.4 Sleep and Wakeup
- Spinlock의 문제점을 해결하기 위해 대두된 방법 중 하나이다.
(Spinlock은 CPU를 낭비한다는 문제점이 있다.)
- OS는 Busy Waiting을 대체하기 위해 sleep()과 wakeup()을 제공한다.
* sleep() System Call
- Lock값이 1인 경우, sleep()을 호출하여 프로세스 자기 자신을 Block시킨다.
- 즉, 무한루프를 돌지 않고, Lock값이 Release되길 기다린다. (CPU를 낭비하지 않는다.)
* wakeup() System Call
- leave_region을 수행한 프로세스가 sleep()으로 인해 Block된 프로세스를 wakeup()을 호출하여 깨운다.
* Producer-Consumer Problem
- Producer는 Item을 생성하여 Buffer에 삽입하고, Consumer는 Buffer에서 Item을 꺼내서 사용하는 구조이다.
- Producer는 Buffer가 꽉차면, Consumer는 Buffer가 비어있으면 작업을 멈춰야 한다. (Synchronization Condition)
- Producer는 빈 Buffer에 Item이 삽입되면 Consumer를 깨워야 하고,
Consumer는 꽉찼던 Buffer에 빈자리가 생기면 Producer에게 알려야 한다. (Synchronization Condition)
* Bounded Buffer Problem with sleep() and wakeup() (FAILED)
#define N 100
int count = 0; // Buffer에 존재하는 Item의 개수
void producer(void)
{
int item;
while(TRUE) {
item = produce_item(); // item을 생성
if (count == N) // Buffer가 꽉 차면, producer는 sleep
sleep(); // 누군가 wakeup()을 호출할 때 까지 Blocked 됨
insert_item(item); // Buffer에 생성한 item을 Insert
count = count + 1; // Load -> Inc(++) -> Store (Assembly Level)
if (count == 1)
wakeup(consumer); // 비어있던 Buffer에 item이 삽입되면, consumer를 깨움
}
}
void consumer(void)
{
int item;
while(TRUE) {
if (count == 0) // Buffer가 비면, consumer는 sleep
sleep();
item = remove_item(); // item을 소비
count = count - 1; // Load -> Dec(--) -> Store (Assembly Level)
if(count == N - 1)
wakeup(producer); // 꽉 차있던 Buffer에서 item을 하나 소비하면, producer를 깨움
consume_item(item); // consume_item()의 수행시간을 예측할 수 없기 때문에,
// producer에 대한 wakeup을 먼저 수행한다.
}
}- 위 코드에서 여러 프로세스가 동시에 접근 가능한 Global Data에는 \(\texttt{count}\)와 Buffer가 있다.
- 위 코드의 문제점은 아래와 같다.
1) Producer와 Consumer는 Atomic하게 동작하지 않기 때문에(Mutex가 구현되지 않았기 때문에) \(\texttt{count}\)값이 틀어질 가능성이 있다.
- \(\texttt{count}\)값을 업데이트 하는 부분(\(\texttt{count = count + 1;}\) 혹은 \(\texttt{count = count - 1;}\))은
어셈블리어 레벨에서 각각 \(\texttt{ld → inc, dec → st}\) 명령으로 구성되는데,
이 부분에 Mutex가 보장되지 않아, 이 어셈블리 명령어들이 Serialize하지 않게(= 교차되어) 실행될 수 있다.
2) 명확하진 않지만, Buffer에 접근하여 연산을 수행하는 \(\texttt{insert_item()}\)과 \(\texttt{remove_item()}\)에서도
Mutex가 구현되어 있지 않을 가능성이 높다.
- \(\texttt{count}\) 조차도 Mutex가 구현되어 있지 않으므로...
3) \(\texttt{producer()}\)에서 \(\texttt{count}\)값이 \(\texttt{N}\)인 것을 확인하고 \(\texttt{sleep()}\)을 호출하려던 찰나에
(즉, \(\texttt{producer()}\) Code의 \(\texttt{if (count == N)}\) 과 \(\texttt{sleep();}\) 사이)
Context-Switch가 발생하여 \(\texttt{consumer()}\)가 수행된다면,
\(\texttt{consumer()}\)측 코드에서는 \(\texttt{count}\) 값이 \(\texttt{N}\)이라서 \(\texttt{wakeup()}\)을 호출했지만, sleep중인 프로세스가 없으므로,
\(\texttt{producer()}\)에 아무런 영향을 못주고 \(\texttt{wakeup()}\)은 리턴된다.
그 이후, \(\texttt{consumer()}\)는 계속 수행되어 \(\texttt{count}\)값을 0으로 만들고 \(\texttt{sleep()}\)을 호출하게 된다.
이 상태에서 만약, \(\texttt{producer()}\)에게 Context-Switch가 일어나게 되면, \(\texttt{producer()}\) 또한 곧바로 \(\texttt{sleep()}\)을 호출하게 된다. 즉, 두 프로세스를 \(\texttt{wakeup()}\) 시킬 주체가 없어 영원히 sleep하게 된다.
- 위 코드는 Atomic하게 수행되지 않으므로, 코드의 어느 부분에서나 Context-Switch가 발생될 수 있다.
2.3.5 Semaphores
- Semaphore는 Non-Negative Integer Type의 변수이며, Lock Variable보다 High-Level 개념이다.
- 세마포어는 커널에 저장되어 있고, System Call을 통해 접근이 가능하다.
- UNIX에 System Call로 구현되어 있어 사용이 편리하다.
- 세마포어 연산 P()와 V()는 Atomic하게 동작한다.
※ 세마포어는 Shared Data로서, 프로세스 간 공유가 가능하도록 아래와 같은 방법들로 구현된다.
1) 세마포어를 Kernel에 저장해놓고, System Call을 통해 접근할 수 있게 한다. (가장 보편적인 방법이다.)
2) 세마포어가 저장된 일부 Memory Address를 공유가 가능하도록 구현한다.
3) 기본적으로 프로세스 간 공유가 가능한 File에 세마포어를 저장한다.
(세마포어에 접근할 때마다 I/O가 발생하므로 Performance가 현저히 저하된다.)
Down Operation (P() Operation)
- 세마포어 값이 0보다 크면, 1만큼 감소시키고 리턴한다.
- 세마포어 값이 0이면, wait를 수행한다. (CPU를 사용하지 않고, Block시킨다.)
Up Operation (V() Operation)
- 세마포어 값을 1만큼 증가시키고 리턴한다.
- wait()을 수행중인 스레드가 있다면, 하나를 골라서 wakeup시킨다.
- wakeup된 스레드는 Down 연산을 다시 수행한다.
Binary Semaphore (Mutex Semaphore)
- 세마포어 값으로 0 혹은 1만 허용된 세마포어를 의미한다.
- Mutex를 구현할 때 용이하게 이용된다.
Counting Semaphore
- 세마포어 값이 0부터 N까지 허용된 세마포어를 의미한다.
- Synchronization을 구현할 때 용이하게 이용된다.
* Bounded Buffer Problem with Binary Semaphores
var mutex: semaphore = 1 ; Shared Data에 Mutex하게 접근하기 위한 semaphore 타입 변수 "mutex"
empty: semaphore = n ; Buffer의 빈 공간을 Count하기 위한 semaphore 타입 변수 "empty"
full : semaphore = 0 ; Buffer의 차 있는 공간을 Count하기 위한 semaphore 타입 변수 "full"
; 즉, empty + full == N
producer:
<produce item> ; Global Data를 일체 건드리지 않는 Local Operation
down(empty)
down(mutex)
<add item to buffer>
up(mutex)
up(full)
consumer:
down(full)
down(mutex)
<remove item from buffer>
up(mutex)
up(empty)
<use item> ; Global Data를 일체 건드리지 않는 Local OperationFor Mutual Exclusion
- item을 add하거나 remove하기 전에 mutex 세마포어를 검사하기 때문에 Mutex하게,
한 번에 하나의 프로세스만 Buffer에 접근하도록 보장된다.
For Synchronization
- full == N (empty == 0)이 되면, producer를 수행한 프로세스가 sleep되고,
empty == N (ful == 0)이 되면, consumer를 수행한 프로세스가 sleep된다.
- full == N-1 (empty == 1)이 되면, sleep중인 producer가 wakeup되고,
empty값이 N-1 (full == 1)이 되면, sleep중인 consumer가 wakeup된다.
- 즉, Semaphore방식에서는 Busy Waiting을 하지 않는다.
Problem with Semaphore
- 세마포어 변수값을 업데이트하는 순서를 착각하고 코딩하기 쉬워, 버그가 있을 가능성이 높다.
ex) down(mutex)와 down(empty)의 순서를 바꾸면 Deadlock이 발생할 수 있다.
* 보다 체계적이고, 쉽게 Synchronization을 구현하여 Parallel 프로그램을 개발하는 방법 중 하나로 Monitor가 등장했다.
2.3.6 Mutexes
- Mutexes란, Mutex 구현에 이용되는, 단순한 버전의 Binary Semaphore를 의미한다.
- 0일 때, Unlock되고, 0이 아닐 때 Lock된다.
* Usage for Mutexes
mutex_lock
critical_region
mutex_unlock2.3.7 Monitors (URL)
- Monitor는 Shared Data에 대한 Mutex 위반을 막는다.
- Monitor Module 내에는 Shared Data 구조, Data에 Access 하는 Procedure(Critical Section), Synchronization Mechanism으로 구성된다.
- Monitor는 대개 프로그래밍 언어의 Constructor로 제공된다.
Example. Monitor
monitor example
integer i; // Global Data
condition c; // Synchronization Mechanism
procedure producer(); // Procedure (Critical Section)
...
end;
procedure consumer(); // Procedure (Critical Section)
...
end;
end monitor;
Monitor Facilities
1) Mutex
- 한 번에 하나의 프로세스(스레드)만 Monitor의 Procedure을 수행할 수 있기 때문에, Mutex가 자동으로 보장된다.
- Monitor에서 insert가 실행중이면, remove가 실행될 수 없고, remove가 실행중이면, insert가 실행될 수 없다.
(한 쪽이 끝날 때 까지 Block된다.)
- 또한, count 변수는 Monitor 내에서만 사용할 수 있고, Monitor 내의 함수들은 Mutex하게 수행되므로
Race Condition이 발생하지 않는다.
2) Condition Variable
- Condition Variable을 통해, wait(c)과 signal(c)을 사용하여 Sleep & Wake up Mechanism을 구현한다.
Example. Producer/Condumer with Monitors
monitor ProducerConsumer
condition full, empty;
integer count;
procedure insert(item: integer);
begin
if count = N then wait(full); // full 상태라면, 해당 프로세스를 Sleep 시킨다.
insert_item(item);
count := count + 1;
if count = 1 then signal(empty) // empty 상태에서 대기중인 프로세스 중 하나를 Wake-up 시킨다.
end;
function remove: integer;
begin
if count = 0 then wait(empty); // empty 상태라면, 해당 프로세스를 Sleep 시킨다.
remove = remove_item; // remove에 값을 대입함으로써 리턴한다.
count := count - 1;
if count = N - 1 then signal(full) // full 상태에서 대기중인 프로세스 중 하나를 Wake-Up 시킨다.
end;
count := 0;
end monitor;
procedure producer;
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item) // Monitor를 통해 item을 삽입한다.
end
end;
procedure consumer;
begin
while true do
begin
item = ProducerConsumer.remove; // Monitor를 통해 item을 제거한다.
consume_item(item)
end
end;- Mutex가 완벽히 보장되기 때문에, Sleep & Wake-Up 구조와 비슷하지만, Race Condition은 발생되지 않는다.
(즉, Global Data를 Update하는 명령어가 절대 방해받지 않는다. Monitor에는 하나의 프로세스만 접근 가능하기 때문이다.)
* Release Monitor Lock
- wait()를 호출한 프로세스는 해당 Monitor를 빠져나와 wait Queue에 Push되어,
다른 프로세스가 Monitor를 사용할 수 있게 한다.
※ signal()을 통해 현재 Monitor에 있는 프로세스가 wait Queue에 있는 한 프로세스를 Wake-Up 시켜서 진행시키면
Monitor에 두 프로세스가 공존하게 되므로, 두 프로세스 중 어떤 프로세스를 먼저 진행시키느냐에 따라
Monitor의 종류가 아래와 같이 나뉜다. (Hoare Monitors, Hansen Monitors, Mesa Monitors)
- Signaler : signal()을 호출하여, wait Queue에 있는 프로세스 중 하나를 Wake-Up 시키는 프로세스이다.
(즉, Signaler는 기존에 Monitor를 수행하고 있던 프로세스이다.)
- Waiter : Monitor에 진입하지 못하고, wait Queue에 삽입되어 Sleep중이던 프로세스이다.
1) Hoare Monitors
- signal()을 호출한, Monitor에 있던 기존의 프로세스(Signaler)는 Block되고,
새로 Wake-Up된 프로세스(Waiter)가 Monitor에 입장한다.
- Waiter가 진행될 경우, Buffer의 상태를 바꿀 여지가 없으므로, Buffer의 Condition이 바뀌지 않음이 보장된다.
2) Hansen Monitors
- signal()을 호출하는 부분을 Monitor의 마지막 부분에 배치한 형태이다.
- Signaler는 signal()을 호출한다 해도, signal()이 마지막 문장이기 때문에 호출 후 Monitor를 바로 빠져나오게 된다.
- 즉, Hansen Monitor에서는 signal()을 호출한 후 바로 Monitor를 빠져 나온다.
- 개념적으로 단순하고, 구현하기에 쉽다.
3) Mesa Monitors
- signal()을 호출한 Signaler가 Monitor를 계속해서 진행하고, Wake-Up된 Waiter는 Ready 상태에 놓인다.
- Signaler가 계속해서 진행하면서, Buffer의 상태를 다시금 바꿀 여지가 있기 때문에,
Waiter는 Signaler가 Monitor를 빠져나간 후에, Buffer의 Condition을 다시 파악해서 본인의 진행여부를 결정해야 한다.
(만약, Signaler에 의해 다시 Buffer가 full 상태가 되었다면, Waiter는 다시 wait Queue에 들어가야 한다.)
(이 부분은 프로그래머가 구현해야 한다.)
Problem with Monitors
- Monitor는 프로그래밍 언어 레벨에서 Constructor로 제공되기 때문에 C/C++에서와 같이 구현이 되어 있지 않으면, 사용할 수가 없다.
- Distributed Environment*에서 사용할 수 없다.
* Distributed Environment (분산 환경)
- 여러 프로세스가 Memory에 Network를 통해 접근하는 환경을 의미한다.
- TSL, Semaphore, Monitor들은 전부 여러 프로세스가 메모리에 동시에 접근할 수 있는
Shared Memory Model에서 구현된 메커니즘들이다.
- 분산 환경에서는 Message Passing 방법으로 구현된다.
2.3.8 Message Passing
- 프로세스(스레드)간 메모리를 직접적으로 공유할 수 없는 환경(= Distributed Environment)에서
Interprocess Communication을 구현하기 위한 수단 중 하나이다.
- 기본적으로 send(), receive() System Call을 통해 Message를 주고받으며 Shared Resource에 접근하는 방식으로 구현된다.
- Producer와 Consumer가 각각 독립적인 Machine에서 각자의 Memory를 이용하여 수행되기 때문에
공유되는 리소스가 없고, 따라서 Critical Region 자체가 존재하지 않는다.
- Message를 receive할 때 까지 Blocked되므로, Synchronization이 보장된다.
- 단, Network를 통해 send()와 receive()가 이루어지므로 이로 인한 Overhead가 크다.
send(destination, *message)
- destination으로 message를 전송한다.
receive(source, &message)
- source로 부터 message를 받는다.
- message를 수신할 때 까지 Block된다.
Example. Message Passing
#define N 100 // # of slots in the Buffer
void producer(void)
{
int item;
message m; // Message Buffer
while (TRUE) {
item = produce_item(); // Generate something to put in Buffer
receive(consumer, &m); // BLOCKED until wait for an empty to arrive
build_message(&m, item); // Construct a message to send
send(consumer, &m); // Send item to consumer
}
}
void consumer(void)
{
int item, i;
message m;
for (i = 0; i < N; i++)
send(producer, &m); // Send N empties
while (TURE) {
receive(producer, &m); // BLOCKED until get message containing item
item = extract_item(&m); // Extract item from message
send(producer, &m); // Send back empty reply
consume_item(item); // Do something with the item (Local Operationg)
}
}
Problem with Message Passing
- Shared Memory 환경에서와 달리, 크기가 큰 Shared Object에 대한 공유가 힘들다.
(Overhead가 크기 때문이다.)
- 프로그래밍 난이도가 높다.
2.3.9 Barriers Synchronization

- 각각의 프로세스들이 프로그램의 특정 지점에 모두 도달할 때 까지 대기한 후, 다음 Step을 진행시킨다.
- 프로세스들을 Parallel하게 진행시키며, 특정 지점에서 다 같이 시작해야 하는 경우에 이용되는 방법이다.
2.4 Scheduling (CPU Scheduling)
* Scheduling (스케줄링) (URL)
[Operating Systems] Scheduling | 스케줄링
Scheduling 스케줄링 - Ready State에 있는 프로세스들 중 어떤 프로세스에 CPU를 할당할지에 대한 방법론이다. - Batch 환경이냐, Timesharing 환경이냐에 따라 스케줄링의 목적이 서로 다르다. - 프로세스에
dad-rock.tistory.com
2.5 Classical IPC Problems
* IPC : Interprocess Communication Problem = Synchronization Problem
2.5.1 The Dining Philosophers Problem

- 철학자들이 저녁을 먹는데, 포크를 양손에 들어야지만 파스타를 먹을 수 있다.
- 5명의 철학자가 모두 파스타를 먹는데 어떻게 프로그래밍해야 할지에 대한 문제이다.
Example. FAILED Solution
#define N 5 // 저녁을 먹는 철학자의 수
void philosopher(int i)
{
while(TRUE) {
think();
take_fork(i); // 왼손에 포크를 든다.
take_fork( (i+1) % N ); // 오른손에 포크를 든다. (Modulo 연산은, 테이블이 원형이기 때문이다.)
eat();
put_fork(i); // 왼손에 든 포크를 내려둔다.
put_fork( (i+1) % N ); // 오른손에 든 포크를 내려둔다.
}
}- take_fork()와 put_fork()는 Critical Region에 해당되는 연산이다.
(Shared Resource인 포크에 접근하는 연산이기 때문이다.)
- 5개의 프로세스가 모두 왼쪽 포크를 들게 되면, Deadlock이 발생한다.
- 이에 대한 해결책으로, 왼쪽 포크를 들고, 오른쪽 포크를 드는데 성공하지 못하면 왼쪽 포크를 다시 내려놓게 하는 방법이 있다.
(이 방법은 타이밍이 맞지 않으면 Starvation이 발생될 가능성이 있다.)
2.5.2 The Reader/Writers Problem
- 여러 프로세스 사이에서 공유되는 Object를 몇몇은 read하고 몇몇은 write하는 경우에 발생하는 문제이다.
- 모두가 read하는 경우라면, Race Condition이 발생하지 않지만,
한 프로세스라도 write하는 경우 Race Condition이 발생할 수 있다.
- 이 경우, Mutex가 보장되어야 한다.
Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)