
AI-Based Security
인공지능 기반 보안
- AI를 이용하여 보안적 위협을 찾고 예방하는데 사람의 개입을 최소화하는 보안기법을 의미한다.
* Artificial Intelligence Overview (인공지능 개요) (URL)
[Artificial Intelligence] Artificial Intelligence Overview | 인공지능 개요
Artificial Intelligence Overview 인공지능 개요 - 인간 수준의 지능을 구사하고, 인간의 지능적 행위를 대신할 수 있는 컴퓨터 시스템을 의미한다. - 즉, 인공지능은 사람에 의해 만들어진 지능적 시스템
dad-rock.tistory.com
Topics of AI-Based Security
- End Point Security
- Mobile Device가 보급화됨에 따라
End Point의 위치와 사용패턴이 다양화되면서 보안 환경과 정책이 수시로 바뀌게 되는데,
이렇게 변화하는 상황을 AI가 감지하여 End Point Device를 안전히 지키게 하는 것이 가장 Hot한 Topic이다.
- AI vs AI
- 학습 모델을 교란시키는 등의 Adversary Attack을 행하는 AI들에 대한 분야이다.
- End User's Control of Data Sharing & Privacy Data
- 사용자의 Private한 Data에 대한 제어 및 공유를 AI를 통해 안전히 보호하는 분야이다.
- End User Authentication
- 사용자 인증을 보다 더 정확히 수행하기 위한 AI 기술에 대한 분야이다.
- Automated Security Operation Process
- 보안 솔루션 수립을 위한 데이터 수집·정제·적용·배포를 AI를 통해 자동화하는 기술에 대한 분야이다.
Example. Recent Trend of AI
- Perception (Good)
- 얼굴인식, 의료 진단 등의 기술들은 인간에 필적할 만큼 발전되어 있다.
- Judgement (Fine)
- 컨텐츠 추천, 스팸메일 필터링 기술들을 몇몇 경우에 대해서는 오작동하기에 사람에 의한 보정이 필요하다.
- Social Prediction (Still a Long Way to go)
- 날씨 예측, 주가 예측, 직원 성과 예측 등은 아직 기존의 기법들에 의존하고 있는 실정이다.
Applications in AI-Based Security
- AI in Threat Detection
- 수집한 Traffic을 통해 실시간으로 공격을 탐지하고 우선순위를 스스로 지정하여 대응하는데 AI가 응용되고 있다.
- Modeling Behavior for Monitoring Anomalies
- Device 혹은 Network에 Normal Behavior들에 대한 Pattern을 학습시켜
Anomalies들을 자동으로 감지할 수 있게 하는데 AI가 응용되고 있다. - Security Screening
- 거짓말, Deep Fake 등의 진위여부를 탐지하는데 AI가 응용되고 있다.
- AI-Based Malware Detection
- 지속적으로 Signature를 변화시키는 Polymorphic/Metamorphic Marware들을 감지할 수 있도록
변종 패턴을 학습한 AI가 응용되고 있다.
- Ai-Based Fraud Detection System (FDS)
- 사용자의 비정상적인 Transaction 및 금융 사기에 대한 패턴을 학습하여
사용자의 기존 행동에 이질적인 행동들을 탐지하는데 AI가 응용되고 있다. - AI-Based Mobile Security
- Mobile APP에서 행해지는 Anomalies를 탐지하고,
전력이 제한된 환경에서 보안 프로그램을 선택적으로 구동하는 전략을 수립하는데 AI가 응용되고 있다. - AI-Based Fingerprint Anti-Spoofing
- AI를 이용하여 위조 지문 타입을 딥러닝으로 학습시켜 사람의 다양한 지문에 대응하는 솔루션이다.
AI-Powered Attacks
- Adversary Attack
- 학습 모델을 교란시키는 공격이다.
- Data Poisoning
- 학습 과정을 교란시키고, 잘못된 학습의 결과를 야기하게 하는 오염된 데이터를 주입하는 공격이다.
- Deepfakes
- 위조된 사진, 동영상, 음성으로 상대의 사실을 조작하는 공격이다.
AI-Based Anomaly Detection
- Anomaly Detection이란, 비정상적인 사용자의 행동 혹은 침입자를 감지하는 것이다.
Statistics, Expery System, Neural Network, Data Mining 등의 방법이 동원된다.
- Observation을 통해 수집된 Time Series Data 사이의 Deviation를 Monitoring하여
Anomaly를 탐지하는 Time Series Analysis가 많이 사용된다. (RNN, LSTM 등)
- Anomaly Detection은 아래와 같이 구분된다:
- Heuristic-Based Anomaly Detection
- Data-Driven Anomaly Detection
Heuristic-Based Anomaly Detection
- 전문가의 경험에 기반하여 Anomaly를 탐지하는 방법으로
사전에 정의해놓은 Threshold를 초과하거나 Statistical Profile을 벗어나는 경우를 Anomaly로 판정한다.
(Threshold, Statistical Profile는 경험에 기반하여 설정된다.)
- 구현이 쉽지만, 특정 전문가에 의존적이다.
- AI가 개선됨에 따라 학습 기반의 Anomaly Detection 기술(Data-Driven Anomaly Detection)이 각광받기 시작했다.
Data-Driven Anomaly Detection
- Normal과 Anomaly에 대한 데이터를 학습시켜 Anomaly를 탐지하는 방법이다.
- Data-Driven Anomaly Detection의 지향점은 아래와 같다:
- False Alarm의 최소화
- System Parameter 최적화
- Data Trend 반영
- Data Generalization (특정 데이터에 대해서만 성능이 튀는 현상을 방지)
- Processing Performance 제고
- Explainable Distinction (결과에 대한 설명이 가능한 NN 모델은 추후 수정에 용이)
- 학습에 적합한 Domain에 대한 Data를 추출하는것을 Feature Extraction라 하며,
모델을 생성하는데 굉장히 중요한 요소 중 하나이다.
Example. Feature Extraction in Host Intrusion Detection
- Host는 Server, Desktop, Laptop, Embedded System등이 해당될 수 있다.
- 수집해야할 Data(Signal)에는
Running Process 정보, Active User Account 정보, System Scheduling 정보, Temporary File Directory 정보,
OS Registry 정보, DB 정보, Network Connection 정보들이 해당된다.
(위와 같은 OS Metric들은 osquery를 통해 추출할 수 있다.)
- 감지하고자 하는 Anomaly에 따라 추출할 데이터들의 그룹을 알맞게 편성해야 할 것이다.
Example. Feature Extraction in Network Intrusion Detection
- Host에 침입하여 외부에 공격을 가하는 행위를 Network Intrusion이라 하며,
Botnet, Adware가 대표적이다.
- 수집해야할 Data(Signal)에는 IP 정보, 위치 정보, Network Traffic 정보들이 해당된다.
- 수신된 Packet들의 Header를 검사해 Network Traffic Metadata와 같은 Feature를 추출할 수 있다.
(Stateful Packet Inspection; 상태 보존형 패킷 검사)
- Packet에 Encapsulation된 세부적인 Network Traffic Content를 Inspection할 수 있다.
(Deep Packet Inspection)
Data-Driven Algorithms
- Supervised Learning-Based ML
- RNN의 일종인 LSTM(Long Short-Term Memory) Network를 통해 구현된다.
- Time Series를 입력받아 Classification과 Prediction을 수행한다.
- Unsupervised Learning-Based ML
- One-Class SVM(Support Vector Machine)을 통해
이상이 없는 데이터들을 학습하여 Classification Boundary를 생성하고,
입력되는 Feature가 Boundary내에 위치하는지 아닌지의 여부를 판단하여 Anomaly를 탐지한다.
- Random Forest에서는 Tree Structure를 이용하여 고차원 데이터에 대한 Anomaly를 탐지한다.
- Statistical Metrics
- 통계적 측정값들을 이용하여 입력값과 기존 데이터들 간의 유사도를 검사하는 방식이다.
- Conformance Testing
- 입력 데이터의 분포와 Distribution Function과의 일치성을 검사하는 방식이다.
- Density-Based Method
- Anomaly의 Density가 Normality의 Density보다 낮음을 이용하여 Anomaly를 탐지하는 방식이다.
Problem in ML Application
- Cost of Error
- 한 번의 Misclassification은 큰 Failure를 초래할 수 있다.
- Opacity of ML Algorithm
- ML 알고리즘의 불투명성으로 인해 분류 결과를 설명하고 평가하기 어렵다. (즉, 업데이트하기 어렵다.)
- Possibility of Adversary Technology Use
- ML을 이용한 적대적 공격에 방어하기 어렵다.
ML-Based Anomaly Detection
- Anomaly Detection Alert
- 인간이 이해하기 쉽고, 위험에 대한 경각심을 일깨워줄 수 있는 알림이어야 한다.
- Incident Response
- Anomaly가 발생되었을 때, 적절히 대응할 수 있어야 한다.
- Passive Response는 Intrusion이 감지되었을 때, 관리자에게 알린 후 관리자의 의사에 따라 대응여부를 결정하는 것이다.
- Active Response는 Intrusion이 감지되었을 때, 선제적으로 대응하는 것이다.
- Threat Mitigation
- Intrusion이 발생되었을 때, 바로 탐지해내지 않고 의도적으로 침입자의 행동을 monitoring하여
활동 정보를 수집하고 추후 Intrusion에 대비한다.
- Securing Explainability
- AI의 Opacity한 특성으로 인해 결과의 해석이 어려운데, Classier에 의한 결정 이유를 사람이 이해할 수 있어야 한다.
- Securing Maintainability
- Detection에 사용되는 Sysetm Paramter를 유연히 변경할 수 있어야 한다.
AI-Based Malware Detection
Malware Analysis
- Malware의 Function, Purpose, Origin, Potential Impact를 분석하는 것을 의미한다.
- S/W Analysis와 Reverse Engineering에 대한 지식을 통해 Software를 분해하고,
Feature Engineering을 통해 분해한 S/W와 Data로부터 Feature를 추출한다.
ML-Based Malware Detection의 특징은 아래와 같다:
- Fuzzy Matching
- 단순히, 정확히(100%) 일치하는가 아닌가를 판별하는 것을 넘어
패턴이 특정 Threshold 범위 내에서 유사성을 보이는지를 분석한다. - Feature Selection Automation
- Malware Sample로부터 예상치 못한, 잠재적인 Feature들도 추출한다.
- Adaptability
- 끊임없이 변화하는 Malware에 대해서도 빠르게 대응할 수 있다.
- 성공적인 ML 알고리즘은 데이터의 품질에 달려있고,
체계적인 데이터 수집과 정제과정이 필요하다.
Feature Extraction: Data Collection
- Domain Knowledge
- 보안 분야의 전문지식이 필요하다. - Data Collection Process
- 데이터 수집과정의 Automation과 Scalability가 필요하다. - Validation and Bias
- Malware의 전반적 특징이 고르게 수집되었는지를 분석한다. - Repeated Testing
- 체계적인 결과 분석에 따라 부족한 영역의 데이터를 재수집하여 모델을 업데이트한다.
Feature Extraction: Feature Analysis
Static Analysi
- Application Code를 실행하지 않고 분석하는 방법으로, Smali Code Analysis 와 같은 방법이 있다.
Example. Features of Android Marware Can be Derived through Static Analysis
- Hides Malware using Obfuscation Techniques
- Hardcoded String Referencing the System Binary
- Hardcoded IP Address or Hostname
- Checks whether it is Running in an Emulator Environment
- Excessive Permission Requirements
- Leaves Traces of Files in Unusual Places on the Device
- Includes ARM-Specific Library to Prevent Execution in the X86 Emulator
Example. Features of Android Marware Can be Derived through Dynamic Analysis
- Real-Time Monitoring of Application Access and Control of User Inforamtion
- Sandbox Execution (Emulator)
- Android Studio, Xposed 등 - Action Generation and Log Collection Tools
- Monkey, TCPdump 등
Example. Features of Android Marware Can be Derived through Debugging
- Execution Status
- Execution Time
Example. Features of Android Marware Can be Derived through Dynamic Measurement
- Modification of Environment and Runtime
- Application과 Running Process에 특정 Logic을 주입하여 환경이나 실행시간의 변경 여부를 확인한다. - Modification of Runtime
- 추출된 모든 Feature를 사용하는 것은 오히려 Noise를 증가시켜 정확성과 성능을 저해하는 요인이 된다.
- 중요하고 연관성 높은 Feature를 선택하는 방법은 아래와 같다:
- Manual Selection
- Domain Expertise, Data Insight - Automatic Selection
- Statistics and Algorithms - No Selection
- Unsupervised Learning-Based Learning
Example. ML Application Example: Permission-Based Android Malware Detection using ML (URL)
- ML을 이용한 권한 기반 안드로이드 악성코드 탐지에 대한 기술을 살펴본다.
- 탐지한 Malware의 종류를 분별하는 것을 목표로 한다.
- Permission Feature들을 Static Analysis를 통해 추출하고 ML(SVM)을 통해 이들을 학습시켜
Normal APP과 Malware를 가려낸다.
Example. ML Application Example (URL)
- 디바이스 상에서 동작하는 딥러닝 기반 안드로이드 악성코드 분석 솔루션이다.
- 설치된 앱을 Reverse Engineering을 통해 Android Manifest File들을 분석하고 Malware를 Scanning한다.
Example. Malware Samples (Dataset)
- Virus Total
- Malware_Trafc_analysis.net
- VirusShare.com
- Vx Heaven
- Malware Classification Challenge (Kaggle & Microsoft)
- Information Security Industry Promotion Portal
AI-Based Network Security
Network Threats
- Passive Attack
- Information Gathering
- Reconnaissance Activity - Active Attack
- Intrusion (SQL Injection, XSS)
- Spoofing (DNS Spoofing)
- Pivoting (Proxy Pivoting)
Network Defense Mechanism
- Access Control and Authentication (Firewall, Multi-Factor Authentication)
- Intrusion Detection (Real-Time Intrusion Prevention System)
- Attacker Detection within Network (Micro-Segmentation)
- Data-Centric Security (Data Encryption)
- Honeypot (Honeynet)
- 다른 Security Feature들과 달리, Network에서는 표준화된 Protocol을 따르기 때문에
수집할수 있는 데이터들이 정형화되어 있다는 특징이 있다.
- Packet Analyzer(TCPdump, Wireshark 등)를 통해 Network Traffic을 Capture하기 쉽다.
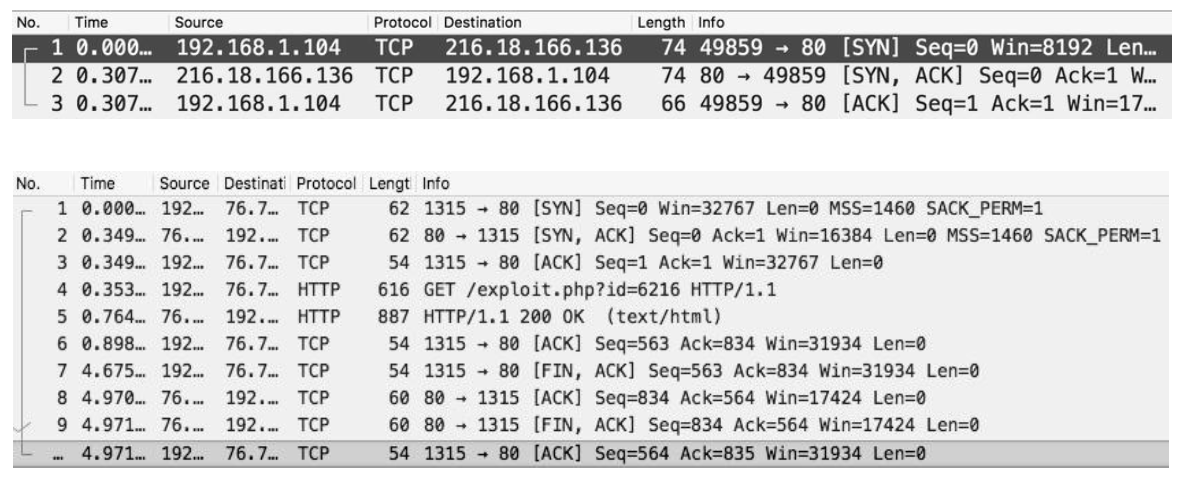
Extractable Network Features
- Application Protocol (HTTP, Telnet, FTP 등)
- Encryption
- Number of Login Failures
- Number of Successful Logins
- Root Access Attempts
- Whether the Root Access is Gained
- Guest Login
- Execution of File Creation
- 어떤 Packet이 Malicious한지 아닌지에 대한 Labeling이 되어있어야 Learning이 가능한데, 이는 숙련된 네트워크 전문가만이 수행할 수 있다.
- 이에대한 유명한 Dataset으로, NSL-KDD Dataset이 있다.
* NSL-KDD Dataset
- MIT Lincoln Lab. 에서 침입탐지 평가를 위해 만들어진 Dataset이다.
- 24개의 네트워크 공격 유형을 포함하고 있다. (DoS, R2L, U2R, Probe 등)
Example. ML Application Example
1. Data Exploration


2. Data Preprocessing

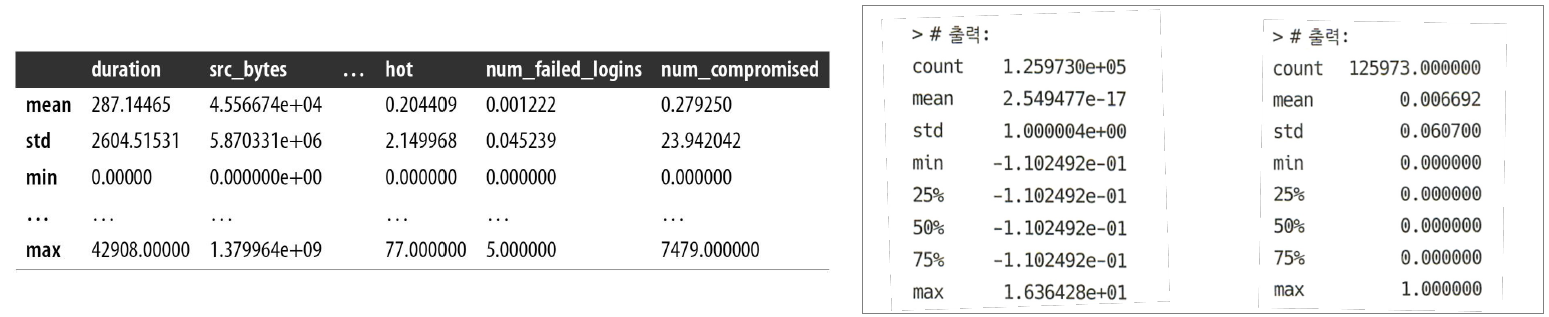
- Standardization and Normalization of Feature Values
- Application of Consistent Transformation to Learning and Testing Datasets
3. Classification Algorithm Selection
- 분류 알고리즘을 선택한다.
- 분류 알고리즘을 선택할 때 고려사항은 아래와 같다:
- Training Dataset Size
- Prediction Type (Category or Numeric Value)
- Labeled Data Amount
- Number of Result Categories
- Time and Resources given to Training
- Time and Resources given for Prediction
4. Training
- .학습을 진행한다.
- Supervised Learning
- Labeled Training Data Retained - Semi-Supervised Learning
- A small number of labeled training data and a large number of unlabeled training data - Unsupervised Learning
- Unlabeled training data
Example. ML Application Example: IoT 환경에서의 오토인코더 기반 특징 추출을 이용한 네트워크 침입 탐지 시스템 (URL)
Example. ML Application Example: MICANS Infotech (URL)
- KDD Dataset을 학습하고 분류하는 도구이다.
Reference: Information Security: Principles and Practice 2nd Edition
(Mark Stamp 저, Pearson, 2011)
Reference: Computer Security: Principles and Practice 3rd Edition
(William Stallings, Lawrie Brown, Pearson, 2014)
Reference: 2022학년도 1학기 홍익대학교 네트워크 보안 강의, 이윤규 교수님
AI-Based Security
인공지능 기반 보안
- AI를 이용하여 보안적 위협을 찾고 예방하는데 사람의 개입을 최소화하는 보안기법을 의미한다.
* Artificial Intelligence Overview (인공지능 개요) (URL)
[Artificial Intelligence] Artificial Intelligence Overview | 인공지능 개요
Artificial Intelligence Overview 인공지능 개요 - 인간 수준의 지능을 구사하고, 인간의 지능적 행위를 대신할 수 있는 컴퓨터 시스템을 의미한다. - 즉, 인공지능은 사람에 의해 만들어진 지능적 시스템
dad-rock.tistory.com
Topics of AI-Based Security
- End Point Security
- Mobile Device가 보급화됨에 따라
End Point의 위치와 사용패턴이 다양화되면서 보안 환경과 정책이 수시로 바뀌게 되는데,
이렇게 변화하는 상황을 AI가 감지하여 End Point Device를 안전히 지키게 하는 것이 가장 Hot한 Topic이다.
- AI vs AI
- 학습 모델을 교란시키는 등의 Adversary Attack을 행하는 AI들에 대한 분야이다.
- End User's Control of Data Sharing & Privacy Data
- 사용자의 Private한 Data에 대한 제어 및 공유를 AI를 통해 안전히 보호하는 분야이다.
- End User Authentication
- 사용자 인증을 보다 더 정확히 수행하기 위한 AI 기술에 대한 분야이다.
- Automated Security Operation Process
- 보안 솔루션 수립을 위한 데이터 수집·정제·적용·배포를 AI를 통해 자동화하는 기술에 대한 분야이다.
Example. Recent Trend of AI
- Perception (Good)
- 얼굴인식, 의료 진단 등의 기술들은 인간에 필적할 만큼 발전되어 있다.
- Judgement (Fine)
- 컨텐츠 추천, 스팸메일 필터링 기술들을 몇몇 경우에 대해서는 오작동하기에 사람에 의한 보정이 필요하다.
- Social Prediction (Still a Long Way to go)
- 날씨 예측, 주가 예측, 직원 성과 예측 등은 아직 기존의 기법들에 의존하고 있는 실정이다.
Applications in AI-Based Security
- AI in Threat Detection
- 수집한 Traffic을 통해 실시간으로 공격을 탐지하고 우선순위를 스스로 지정하여 대응하는데 AI가 응용되고 있다.
- Modeling Behavior for Monitoring Anomalies
- Device 혹은 Network에 Normal Behavior들에 대한 Pattern을 학습시켜
Anomalies들을 자동으로 감지할 수 있게 하는데 AI가 응용되고 있다. - Security Screening
- 거짓말, Deep Fake 등의 진위여부를 탐지하는데 AI가 응용되고 있다.
- AI-Based Malware Detection
- 지속적으로 Signature를 변화시키는 Polymorphic/Metamorphic Marware들을 감지할 수 있도록
변종 패턴을 학습한 AI가 응용되고 있다.
- Ai-Based Fraud Detection System (FDS)
- 사용자의 비정상적인 Transaction 및 금융 사기에 대한 패턴을 학습하여
사용자의 기존 행동에 이질적인 행동들을 탐지하는데 AI가 응용되고 있다. - AI-Based Mobile Security
- Mobile APP에서 행해지는 Anomalies를 탐지하고,
전력이 제한된 환경에서 보안 프로그램을 선택적으로 구동하는 전략을 수립하는데 AI가 응용되고 있다. - AI-Based Fingerprint Anti-Spoofing
- AI를 이용하여 위조 지문 타입을 딥러닝으로 학습시켜 사람의 다양한 지문에 대응하는 솔루션이다.
AI-Powered Attacks
- Adversary Attack
- 학습 모델을 교란시키는 공격이다.
- Data Poisoning
- 학습 과정을 교란시키고, 잘못된 학습의 결과를 야기하게 하는 오염된 데이터를 주입하는 공격이다.
- Deepfakes
- 위조된 사진, 동영상, 음성으로 상대의 사실을 조작하는 공격이다.
AI-Based Anomaly Detection
- Anomaly Detection이란, 비정상적인 사용자의 행동 혹은 침입자를 감지하는 것이다.
Statistics, Expery System, Neural Network, Data Mining 등의 방법이 동원된다.
- Observation을 통해 수집된 Time Series Data 사이의 Deviation를 Monitoring하여
Anomaly를 탐지하는 Time Series Analysis가 많이 사용된다. (RNN, LSTM 등)
- Anomaly Detection은 아래와 같이 구분된다:
- Heuristic-Based Anomaly Detection
- Data-Driven Anomaly Detection
Heuristic-Based Anomaly Detection
- 전문가의 경험에 기반하여 Anomaly를 탐지하는 방법으로
사전에 정의해놓은 Threshold를 초과하거나 Statistical Profile을 벗어나는 경우를 Anomaly로 판정한다.
(Threshold, Statistical Profile는 경험에 기반하여 설정된다.)
- 구현이 쉽지만, 특정 전문가에 의존적이다.
- AI가 개선됨에 따라 학습 기반의 Anomaly Detection 기술(Data-Driven Anomaly Detection)이 각광받기 시작했다.
Data-Driven Anomaly Detection
- Normal과 Anomaly에 대한 데이터를 학습시켜 Anomaly를 탐지하는 방법이다.
- Data-Driven Anomaly Detection의 지향점은 아래와 같다:
- False Alarm의 최소화
- System Parameter 최적화
- Data Trend 반영
- Data Generalization (특정 데이터에 대해서만 성능이 튀는 현상을 방지)
- Processing Performance 제고
- Explainable Distinction (결과에 대한 설명이 가능한 NN 모델은 추후 수정에 용이)
- 학습에 적합한 Domain에 대한 Data를 추출하는것을 Feature Extraction라 하며,
모델을 생성하는데 굉장히 중요한 요소 중 하나이다.
Example. Feature Extraction in Host Intrusion Detection
- Host는 Server, Desktop, Laptop, Embedded System등이 해당될 수 있다.
- 수집해야할 Data(Signal)에는
Running Process 정보, Active User Account 정보, System Scheduling 정보, Temporary File Directory 정보,
OS Registry 정보, DB 정보, Network Connection 정보들이 해당된다.
(위와 같은 OS Metric들은 osquery를 통해 추출할 수 있다.)
- 감지하고자 하는 Anomaly에 따라 추출할 데이터들의 그룹을 알맞게 편성해야 할 것이다.
Example. Feature Extraction in Network Intrusion Detection
- Host에 침입하여 외부에 공격을 가하는 행위를 Network Intrusion이라 하며,
Botnet, Adware가 대표적이다.
- 수집해야할 Data(Signal)에는 IP 정보, 위치 정보, Network Traffic 정보들이 해당된다.
- 수신된 Packet들의 Header를 검사해 Network Traffic Metadata와 같은 Feature를 추출할 수 있다.
(Stateful Packet Inspection; 상태 보존형 패킷 검사)
- Packet에 Encapsulation된 세부적인 Network Traffic Content를 Inspection할 수 있다.
(Deep Packet Inspection)
Data-Driven Algorithms
- Supervised Learning-Based ML
- RNN의 일종인 LSTM(Long Short-Term Memory) Network를 통해 구현된다.
- Time Series를 입력받아 Classification과 Prediction을 수행한다.
- Unsupervised Learning-Based ML
- One-Class SVM(Support Vector Machine)을 통해
이상이 없는 데이터들을 학습하여 Classification Boundary를 생성하고,
입력되는 Feature가 Boundary내에 위치하는지 아닌지의 여부를 판단하여 Anomaly를 탐지한다.
- Random Forest에서는 Tree Structure를 이용하여 고차원 데이터에 대한 Anomaly를 탐지한다.
- Statistical Metrics
- 통계적 측정값들을 이용하여 입력값과 기존 데이터들 간의 유사도를 검사하는 방식이다.
- Conformance Testing
- 입력 데이터의 분포와 Distribution Function과의 일치성을 검사하는 방식이다.
- Density-Based Method
- Anomaly의 Density가 Normality의 Density보다 낮음을 이용하여 Anomaly를 탐지하는 방식이다.
Problem in ML Application
- Cost of Error
- 한 번의 Misclassification은 큰 Failure를 초래할 수 있다.
- Opacity of ML Algorithm
- ML 알고리즘의 불투명성으로 인해 분류 결과를 설명하고 평가하기 어렵다. (즉, 업데이트하기 어렵다.)
- Possibility of Adversary Technology Use
- ML을 이용한 적대적 공격에 방어하기 어렵다.
ML-Based Anomaly Detection
- Anomaly Detection Alert
- 인간이 이해하기 쉽고, 위험에 대한 경각심을 일깨워줄 수 있는 알림이어야 한다.
- Incident Response
- Anomaly가 발생되었을 때, 적절히 대응할 수 있어야 한다.
- Passive Response는 Intrusion이 감지되었을 때, 관리자에게 알린 후 관리자의 의사에 따라 대응여부를 결정하는 것이다.
- Active Response는 Intrusion이 감지되었을 때, 선제적으로 대응하는 것이다.
- Threat Mitigation
- Intrusion이 발생되었을 때, 바로 탐지해내지 않고 의도적으로 침입자의 행동을 monitoring하여
활동 정보를 수집하고 추후 Intrusion에 대비한다.
- Securing Explainability
- AI의 Opacity한 특성으로 인해 결과의 해석이 어려운데, Classier에 의한 결정 이유를 사람이 이해할 수 있어야 한다.
- Securing Maintainability
- Detection에 사용되는 Sysetm Paramter를 유연히 변경할 수 있어야 한다.
AI-Based Malware Detection
Malware Analysis
- Malware의 Function, Purpose, Origin, Potential Impact를 분석하는 것을 의미한다.
- S/W Analysis와 Reverse Engineering에 대한 지식을 통해 Software를 분해하고,
Feature Engineering을 통해 분해한 S/W와 Data로부터 Feature를 추출한다.
ML-Based Malware Detection의 특징은 아래와 같다:
- Fuzzy Matching
- 단순히, 정확히(100%) 일치하는가 아닌가를 판별하는 것을 넘어
패턴이 특정 Threshold 범위 내에서 유사성을 보이는지를 분석한다. - Feature Selection Automation
- Malware Sample로부터 예상치 못한, 잠재적인 Feature들도 추출한다.
- Adaptability
- 끊임없이 변화하는 Malware에 대해서도 빠르게 대응할 수 있다.
- 성공적인 ML 알고리즘은 데이터의 품질에 달려있고,
체계적인 데이터 수집과 정제과정이 필요하다.
Feature Extraction: Data Collection
- Domain Knowledge
- 보안 분야의 전문지식이 필요하다. - Data Collection Process
- 데이터 수집과정의 Automation과 Scalability가 필요하다. - Validation and Bias
- Malware의 전반적 특징이 고르게 수집되었는지를 분석한다. - Repeated Testing
- 체계적인 결과 분석에 따라 부족한 영역의 데이터를 재수집하여 모델을 업데이트한다.
Feature Extraction: Feature Analysis
Static Analysi
- Application Code를 실행하지 않고 분석하는 방법으로, Smali Code Analysis 와 같은 방법이 있다.
Example. Features of Android Marware Can be Derived through Static Analysis
- Hides Malware using Obfuscation Techniques
- Hardcoded String Referencing the System Binary
- Hardcoded IP Address or Hostname
- Checks whether it is Running in an Emulator Environment
- Excessive Permission Requirements
- Leaves Traces of Files in Unusual Places on the Device
- Includes ARM-Specific Library to Prevent Execution in the X86 Emulator
Example. Features of Android Marware Can be Derived through Dynamic Analysis
- Real-Time Monitoring of Application Access and Control of User Inforamtion
- Sandbox Execution (Emulator)
- Android Studio, Xposed 등 - Action Generation and Log Collection Tools
- Monkey, TCPdump 등
Example. Features of Android Marware Can be Derived through Debugging
- Execution Status
- Execution Time
Example. Features of Android Marware Can be Derived through Dynamic Measurement
- Modification of Environment and Runtime
- Application과 Running Process에 특정 Logic을 주입하여 환경이나 실행시간의 변경 여부를 확인한다. - Modification of Runtime
- 추출된 모든 Feature를 사용하는 것은 오히려 Noise를 증가시켜 정확성과 성능을 저해하는 요인이 된다.
- 중요하고 연관성 높은 Feature를 선택하는 방법은 아래와 같다:
- Manual Selection
- Domain Expertise, Data Insight - Automatic Selection
- Statistics and Algorithms - No Selection
- Unsupervised Learning-Based Learning
Example. ML Application Example: Permission-Based Android Malware Detection using ML (URL)
- ML을 이용한 권한 기반 안드로이드 악성코드 탐지에 대한 기술을 살펴본다.
- 탐지한 Malware의 종류를 분별하는 것을 목표로 한다.
- Permission Feature들을 Static Analysis를 통해 추출하고 ML(SVM)을 통해 이들을 학습시켜
Normal APP과 Malware를 가려낸다.
Example. ML Application Example (URL)
- 디바이스 상에서 동작하는 딥러닝 기반 안드로이드 악성코드 분석 솔루션이다.
- 설치된 앱을 Reverse Engineering을 통해 Android Manifest File들을 분석하고 Malware를 Scanning한다.
Example. Malware Samples (Dataset)
- Virus Total
- Malware_Trafc_analysis.net
- VirusShare.com
- Vx Heaven
- Malware Classification Challenge (Kaggle & Microsoft)
- Information Security Industry Promotion Portal
AI-Based Network Security
Network Threats
- Passive Attack
- Information Gathering
- Reconnaissance Activity - Active Attack
- Intrusion (SQL Injection, XSS)
- Spoofing (DNS Spoofing)
- Pivoting (Proxy Pivoting)
Network Defense Mechanism
- Access Control and Authentication (Firewall, Multi-Factor Authentication)
- Intrusion Detection (Real-Time Intrusion Prevention System)
- Attacker Detection within Network (Micro-Segmentation)
- Data-Centric Security (Data Encryption)
- Honeypot (Honeynet)
- 다른 Security Feature들과 달리, Network에서는 표준화된 Protocol을 따르기 때문에
수집할수 있는 데이터들이 정형화되어 있다는 특징이 있다.
- Packet Analyzer(TCPdump, Wireshark 등)를 통해 Network Traffic을 Capture하기 쉽다.
Extractable Network Features
- Application Protocol (HTTP, Telnet, FTP 등)
- Encryption
- Number of Login Failures
- Number of Successful Logins
- Root Access Attempts
- Whether the Root Access is Gained
- Guest Login
- Execution of File Creation
- 어떤 Packet이 Malicious한지 아닌지에 대한 Labeling이 되어있어야 Learning이 가능한데, 이는 숙련된 네트워크 전문가만이 수행할 수 있다.
- 이에대한 유명한 Dataset으로, NSL-KDD Dataset이 있다.
* NSL-KDD Dataset
- MIT Lincoln Lab. 에서 침입탐지 평가를 위해 만들어진 Dataset이다.
- 24개의 네트워크 공격 유형을 포함하고 있다. (DoS, R2L, U2R, Probe 등)
Example. ML Application Example
1. Data Exploration
2. Data Preprocessing
- Standardization and Normalization of Feature Values
- Application of Consistent Transformation to Learning and Testing Datasets
3. Classification Algorithm Selection
- 분류 알고리즘을 선택한다.
- 분류 알고리즘을 선택할 때 고려사항은 아래와 같다:
- Training Dataset Size
- Prediction Type (Category or Numeric Value)
- Labeled Data Amount
- Number of Result Categories
- Time and Resources given to Training
- Time and Resources given for Prediction
4. Training
- .학습을 진행한다.
- Supervised Learning
- Labeled Training Data Retained - Semi-Supervised Learning
- A small number of labeled training data and a large number of unlabeled training data - Unsupervised Learning
- Unlabeled training data
Example. ML Application Example: IoT 환경에서의 오토인코더 기반 특징 추출을 이용한 네트워크 침입 탐지 시스템 (URL)
Example. ML Application Example: MICANS Infotech (URL)
- KDD Dataset을 학습하고 분류하는 도구이다.
Reference: Information Security: Principles and Practice 2nd Edition
(Mark Stamp 저, Pearson, 2011)
Reference: Computer Security: Principles and Practice 3rd Edition
(William Stallings, Lawrie Brown, Pearson, 2014)
Reference: 2022학년도 1학기 홍익대학교 네트워크 보안 강의, 이윤규 교수님