
7장 자료형
7.1 자료형과 형 선언
자료형
- Object(객체)의 집합과 이 객체들의 Instance(실체)들에 대한 연산들의 집합이다.
- 연산의 종류로는 Create(생성), Build-Up(작성), Destroy(소멸), Modify(수정), Pick Apart(분해)와 같은 것들이 있다.
ex) Lisp에서 주요 데이터 형은 "S-Expression"이라 불리는 Binary Tree이며, 기본 연산으로는 CAR, CDR, CONS를 제공한다.
- 명령형 PL의 Built-In 데이터 형으로는 정수형, 실수형, 문자형, 논리형과 이들에 대한 연산이 제공된다.
ex) Fortran 77, C, Java, Ada의 기본 데이터 형
| Fortran 77 | C | Java | Ada |
| INTEGER | int | int | integer |
| REAL | short | short | float |
| LOGICAL | long | byte | boolean |
| CHARACTER | float | long | character |
| DOUBLE | double | float | natural (자연수) |
| COMPLEX | char | double | duration (시간값) |
| char | priority (우선순위) | ||
| boolean |
- 변수들의 많은 특성들은 선언문에서 확정된다.
- 어떤 데이터 형 변수를 선언한다는 것은 변수 값에 관한 추상적인 개념만을 주는 것이며, 실제 구현의 자세한 사항에 대해서는 데이터 형 정의로 미루는 것이다.
- 데이터 형 선언의 다른 특징은 명세부를 실질적인 구현 부분으로부터 분리되도록 지원한다는 점이다.
- 데이터 형 시스템은 서로 다른 특성을 가진 객체들을 구별함으로써 신뢰성과 가독성을 제고한다.
Typing Mechanism (데이터 형 기법)
- 데이터 형을 정의하고, 변수를 특정 데이터형으로 선언하는 설비를 의미한다.
- Fortran, Cobol과 같은 구형 PL에서는 빈약하게 제공되었고, 근래의 PL에서는 다양한 형태로 제공되고 있다.
변수, 데이터 형 선언
- 컴파일러에 의한 정적 데이터 형 검사가 수행된다.
- 명세부와 구현부가 분리하여 추상 데이터 형 구현이 가능하다.
- 프로그램의 신뢰성과 판독성이 증가한다.
데이터 형에 관련된 쟁점 사항
- 데이터 형 정보와 바인딩 시점 (번역 시간에 바인딩 할 것인가, 실행 시간에 바인딩 할 것인가)
- 강 데이터 형인가
- 데이터 형의 Compatibility(적법성)와 동치 관계
- 데이터 형의 매개변수와 매개변수의 평가 시점
Strong Type (강 데이터 형)
- 데이터 형에 관한 모든 특성들이 컴파일 시간에 확정되는 데이터 형을 의미한다.
- 사용되는 모든 변수들의 선언과 변수들의 모든 데이터 형 정보를 미리 정해야 한다.
- 프로그램의 신뢰성, 유지 보수성, 판독성을 제고한다.
Data Type Member (데이터 형 구성원)
- Object(객체), Element(요소), Value(값)와 같은 개념들이 여기에 해당된다.
- 데이터 형 구성원들은 데이터 형의 Domain(영역)을 구성한다.
Literal (리터럴)
- 프로그램에서 사용자가 작성한 데이터 형 구성원을 의미한다.
- Symbol들이 나열된 순서로 값이 정의된 상수이다.
ex) 논리 자료형에 대한 리터럴은 {true, false}이다.
Scalar Type (스칼라 형) = Simple Type (단순형)
- 데이터 형의 영역이 단순한 상수 값들로만 구성되어 있는 데이터 형을 의미한다.
- 대부분의 PL에 Built-In된 정수형, 실수형, 논리형, 문자형 등이 대표적인 스칼라 형이다.
Structured Type (구조형)
- 데이터들의 집합을 구성원으로 갖는 데이터 형을 의미한다.
- 구조형은 필드들의 집합으로 되어있으며, 필드들은 자신의 데이터형을 따로 갖는다.
ex) 배열, 레코드는 주요한 구조형 중 하나이다.
ex) Pascal의 데이터 형 구조
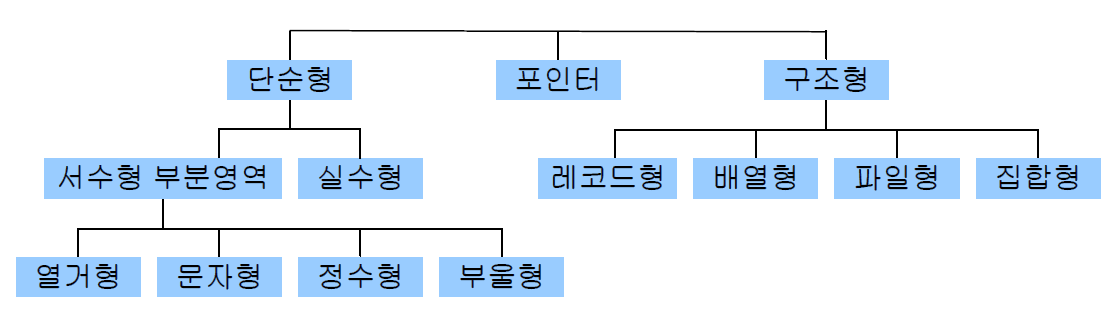
ex) Ada의 데이터 형 구조
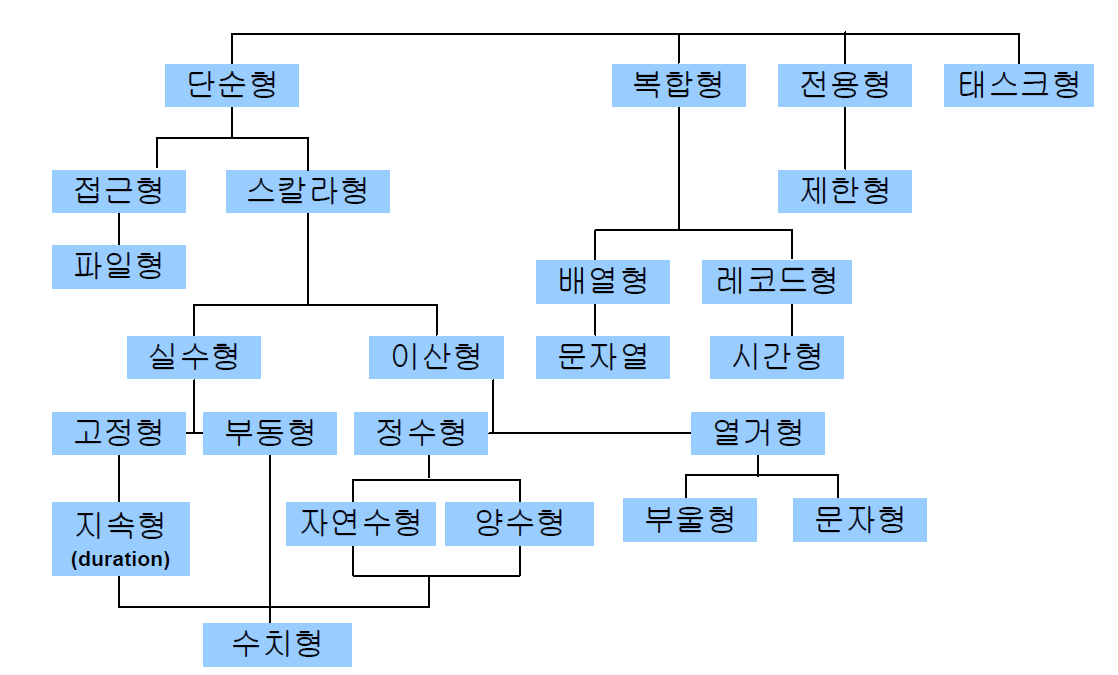
ex) Java의 데이터 형 구조
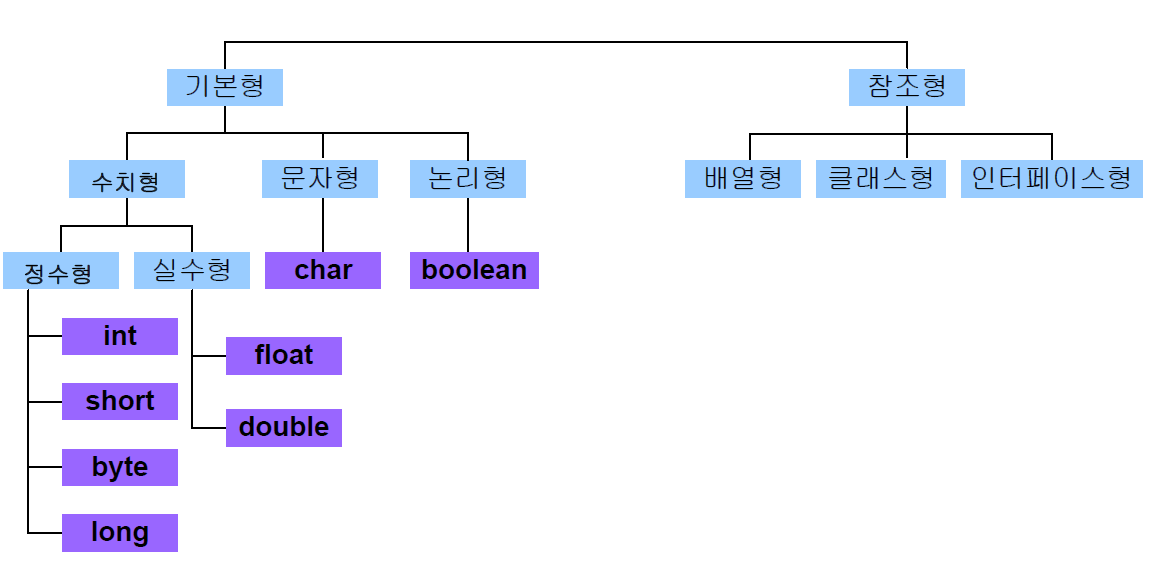
7.2 단순형
- 모든 PL은 Built-In 데이터 형을 갖고 있으며, 수치 자료형, 논리형, 문자형과 같은 단순형들이 이에 해당된다.
- 미리 정의되지 않은 단순 데이터 형 또한 존재할 수 있는데 열거형, 부분 영역 데이터 형이 이에 속한다.
- 단순 데이터형 객체들은 서수형(이산형), 실수형으로 나누어진다.
- 서수형(이산형): 객체들을 순서대로 나열할 수 있는 데이터 형
- 실수형: 객체들의 순서를 정의할 수 없는 데이터 형
Number (수치형)
- 기본적인 스칼라 형으로, 각 데이터 객체가 정수 혹은 실수의 근사 값을 표현한다.
- Built-In 수치형에서 산술적인 부분들은 기계에 의존하여 구현된다.
- 고급 PL로 기술된 정수, 실수의 연산이 그대로 기계에 내장된 코드로 변환되므로 연산 속도가 매우 빠르나, 이 때문에 프로그램 이식성이 떨어진다.
- Precision(정밀도)와 수치 표현이 기계에 따라 다르다는 것은 동일한 계산을 수행하는 프로그램이라도 기계에 따라 다른 결과를 내는 것을 의미한다.
ex) Ada, Java는 수치들의 이러한 기계 의존성을 극복했다.
Ada는 MAX_INT, MIN_INT를 도입하고, short integer, long integer의 허용 범위, 사양, 실수의 유효 숫자 자릿수, 사용 영역, 실수들 사이의 폭을 프로그래머가 선언부에서 선언 가능하도록 하였다.
type COEF is digits 10 range -1.0..1.0;
! COEF: -1.0 ~ 1.0 범위를 갖는 10자리의 유효숫자를 가진 값
type MONEY is delta 0.01 range 0.0..100.0;
! MONEY: 0.0 ~ 100.0 범위를 가지며, 0.01 단위로 증감되는 값
또한, 표현 가능한 수치 데이터 형 T의 개수(T'DIGIT), 최솟값(T'SMALL), 최댓값(T'LARGE)와 같은 속성을 사용 가능하도록 했다.
ex) Java는 수치 데이터 형 표현에 사용되는 비트수와 방법을 정의하여 기계 구현 바인딩을 언어 정의 바인딩으로 이전시켜 기계 독립성을 확보했다.
Polymorphism (다형성)
- 동일 속성의 연산자가 피연산자의 데이터형에 따라 다른 것으로 간주되는 개념이다.
- Ada, C++등에서 제공된다.
ex) + 연산자: 정수형 덧셈 연산자, 실수형 덧셈 연산자, 행렬 덧셈 연산자 등 여러가지로 해석된다.
혼합형 연산 해결 방법
1. 피연산자와 연산 결과에 대한 데이터 형을 표로 제공하는 방법
2. 연산 결과의 데이터 형을 미리 결정하여 연산을 수행하는 방법
- 피연산자가 연산 결과의 데이터 형과 다르면 결과형으로 변환하여 연산한다.
ex) P = Q + I / J
방법 1: P = Q + REAL(I / J)
방법 2: P = Q + REAL(I) / REAL(J)
ex) Algol 68에서 혼합형 연산을 처리하기 위해 제공한 연산 결과에 대한 데이터 형 표 (Widening을 기본으로 하는 규칙)
| + 연산자 | integer | real | double |
| integer | interger | real** | double*** |
| real | real** | real | double* |
| double | double*** | double* | double |
*: real -> double 변환 후 연산
**: integer -> real 변환 후 연산
***: **, * 변환 후 연산
Boolean (논리형)
- 값의 영역이 True, False 단 두가지로 제한되는 데이터 형이다.
- and, or, not, implies(imp), equivalence(equiv)등의 연산이 제공된다.
1) x and y = if x then y else false
2) x or y = if x then true else y
3) not x = if x then false else true
4) x imp y = if x then y else true
5) x equiv y = if x then y else not y
ex) Algol 60에서 논리형은 true, false로 제공되며, 숫자와의 혼합 연산을 허용하지 않는다.
ex) Ada, Pascal에서는 논리형을 미리 정의된 열거형 {FALSE, TRUE}으로 제공하며, 프로그래머에 의해 논리형이 수정될 수 있다.
ex) PL/I에서는 값이 0이 아닌 비트를 하나이상 포함하면 True로 간주하고, 모든 비트가 0인 비트열 혹은 공비트열을 False로 간주한다.
ex) PL/I에서 9 < 8 < 7의 값은 아이러니하게도 True이다. (9 < 8) < 7 = 0(False) < 7 = True
ex) Java에서는 논리형 상수로 true, false만 제공하며, and(&&), or(||), not(!) 연산 외에는 어떤 연산도 수행할 수 없다.
문자형
- 1960년대 중반, 범용성 고급 PL에 문자열 조작을 위한 특성들에 요구되기 시작했다.
- 변수들이 문자열을 값으로 가질 수 있도록 문자열을 데이터 형으로 허용하고,
문자들의 정합 순서를 정의하여 관계 연산자를 문자열에 사용할 수 있도록 요구되었다.
- 연산 결과로써 발생되는 문자열의 길이는 컴파일 시간에 결정될 수 없으므로 문자열 데이터에 대한 기억 장치는 동적으로 배당/회수 되어야 한다는 점이 주요 쟁점이었다.
* Hollerith 문자열
- 출력을 위한 문자열이다.
- 문자열을 정수 변수에 배정하여 사용한다.
- 초창지 수치중심 PL(Fortran, Algol 60)에서 주로 사용되었다.
ex) PL/I에서는 위와 같은 문자열에 대한 요구들을 모두 제공한 최초의 PL이었다.
PL/I에서 문자열 변수들은 논리값 생성을 위한 관계 연산자를 사용할 수 있으며, 배정문의 왼쪽, 오른쪽 모두 위치할 수 있다. (L-Value, R-Value의 성질을 모두 갖는다.)
DCL A CHAR(10);
! 길이가 10인 문자열 A
DCL B CHAR(80) VARYING;
! 최대 길이가 80인 문자열 B
DCL C PIC 'AAXX99'
! 영문자 2개, 임의의 문자 2개, 숫자 2개로 이루어져야 하는 문자열 C
! 즉, 문자열의 조건을 명시하는 방식
PL/I에서는 문자열 조작을 위해 아래 6가지 연산을 제공한다.
1. A | B
- 연결 연산자이다.
- 두 개의 피연산자를 요구하는 Infix Operator(중위 연산자)이다.
2. INDEX (A, B)
- 문자열 B가 A의 부분 문자열이라면, A에서 B가 나타난 첫 번째 인덱스를 리턴한다.
3. LENGTH (A)
- 문자열 A의 길이를 리턴한다.
4. SUBSTR (A, n1, n2)
- 문자열 A에서 n1번째 인덱스부터 시작하여 n2개의 문자인 A의 부분 문자열을 값으로 리턴한다. (부분 문자열 연산)
- SUBSTR()은 L-Value를 가져 SUBSTR()가 지칭하는 부분 문자열을 곧바로 수정 가능하다.
5. TRANSLATE (A, B, C)
- 문자열 A에 포함된 C 문자들을 모두 B 문자로 바꾼다.
6. VERIFY (A, B)
- 문자열 A에는 있으나, 문자열 B에는 없는 첫 번째 문자의 인덱스를 리턴한다.
ex) PL/I 문자열 설비들은 구현의 어려움, 실행 시간의 비효율 등의 고 비용을 치뤘다.
ex) Pascal은 한 문자만을 값으로 하는 문자형(char)만 존재하며, 문자열은 1차원 배열로 정의된다.
문자열에 대한 연산은 아래와 같은 두 가지로 제공한다.
1. ord(C) : 정합 순서에서 문자 C의 순서값을 리턴한다.
2. chr(X) : ord() 함수의 역함수이다. 정합 순서상에서 X번째 문자를 리턴한다.
ex) C언어에서 문자열은 문자 배열로써 구현되며, 문자열에 대한 연산은 따로 없으며, 시스템에서 제공하는 I/O 정도만 정의되어 있다.
ex) Java에서 문자 코드는 16bits Unicode를 원칙으로 하며, 정수형과의 데이터 형 변환이 가능하다. 문자열을 객체로 간주하여 Java,long,static 클래스의 Instance로 선언하여 사용 가능하다. 물론, 문자열을 문자 배열로 정의하는 것 또한 가능하다.
7.3 Enumerated Data Types (열거형)
- 열거형 객체들의 영역은 리스트로 정해지며, 열거형 객체에 대한 연산으로는 동등, 순서 관계와 배정 연산이 있다.
- 열거형에 제공되지 않으면 Literal 값에 정수값을 일일히 대응시켜 표현해야 하는데, 이는 프로그램 판독성을 저해한다.
- 프로그래머가 나열한 순서가 곧 해당 열거형 원소들의 순서이다.
ex) Pascal은 프로그래머가 열거형 데이터를 정의할 수 있게 허용한 초기 PL중 하나이다.
Pascal에서 열거형 변수의 선언과 활용은 아래 코드와 같다.
또한, pred(), succ()를 통해 특정 열거형 원소의 전후에 데이터를 삽입할 수 있다.
(pred: predecessor, succ: successor)
type months = (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec);
var x, y, z : months;
x := Jan;
y := jun;
if x = y then z := Nov else z := Dec
pred(Jun) = May
succ(Jun) = Jul
! pred(Jan), succ(Dec)는 연산 결과가 정의되지 않는다.
열거형의 문제점
ex) Pascal에서는 동일한 상수 이름을 다수의 열거형의 Literal 값으로 사용 가능하게 하는 Multiple Definition(다중 정의)을 허용하지 않는다.
ex) Ada에서는 열거형의 모든 Literal 식별자들의 사용을 제한하지 않는다. 즉, Multiple Definition을 허용한다.
그러므로, 다중 정의된 Literal은 문맥에 따라 결정되거나, 열거형 이름을 통해 제한해서 사용하게 한다.
type months = (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec);
type summermonths is (Jun, Jul, Aug);
x : months; y : summermonths;
months'ORD(Jul) ! months 열거형의 Jul을 의미
summermonths'ORD(Jul) ! summermonths 열거형의 Jul을 의미Multiple Definition 해결책
ex) Pascal에서는 기존의 열거형 혹은 정수의 부분 집합과 같은 Subrange(부분 영역) 데이터 형을 제공한다.
본래 데이터 형이 허용하는 값들 중 상한과 하한을 지정하여 범위를 축소 시키며,
본래 데이터 형이 지원하는 모든 연산을 그대로 사용할 수 있다.
부분 영역형 변수의 값들에 대한 영역 검사는 실행 시간에 수행된다.
본래 데이터 형과 부분 영역형 사이의 혼합 연산이 가능하긴 하나, 구현 의존적이어서 매번 완전한 결과를 기대할 수 없다.
type summermonths = Jun..Aug;
! months 열거형의 부분 영역형 summermonths 열거형
! 하한: Jun, 상한 Aug
ex) C/C++에서는 정수형 상수에 이름을 부여하는 의미로써 열거형을 제공한다.
열거형 원소에 따로 값을 지정하지 않으면, 먼저 포함된 원소부터 0, 1, 2, ...로 부여된다.
다수의 원소에 같은 값을 지정할 수 있고, 값을 오름차순 혹은 내림차순으로 지정할 필요도 없다.
또한, 열거형에 식별자를 함께 선언하여 별도의 데이터 형으로 만들 수도 있다.
열거형은 int형으로의 변환을 허용하며, int형에서 열거형으로의 변환은 명시적 캐스트를 통해 이루어져야 한다.
그리고 switch문의 case문에 열거형 변수를 위치시킬 수 있다.
snum {small, meidum, large};
snum size {small, medium, large};
size k = small;
int i = medium;
k = i; // Error!
k = size(i); // Explicit Type Casting
7.4 배열
- 근래의 PL들에서는 여러 데이터를 묶어서 하나의 단위로 처리할 수 있는 Structured Data Types(구조형)*으로써 Array와 Record를 제공하고 있다.
* Structured Types(구조형) = Aggregate(집합체) = Composite Type(복합형)
- Array는 집합체에서 Index를 통해 원소를 식별하는 Homogeneous Data(동질형 데이터)의 집합체이다.
- Record는 원소를 식별자로 구분짓는 Heterogeneous Data(이질형 데이터)의 집합체이다.
Array (배열)
- 이름, 차원, 원소의 데이터 형, 인덱스 집합의 데이터 형과 범위 등으로 정의된다.
- 배열에서 선택 연산은 배열이름, 인덱스 값 집합에서 한 원소에 대한 Mapping이다.
ex) Fortran, PL/I, Ada에서는 배열 인덱스를 소괄호로 표현한다.
Ada에서는 번역시간에 함수인지, 배열 원소인지를 정적으로 구분한다.
ex) Pascal, C/C++, Modula-2, Java등의 최근 PL에서는 배열 인덱스를 대괄호로 표현한다.
- 배열의 인덱스들의 집합은 일반적으로 연속적인 정수 집합을 사용하지만 반드시 정수형으로 제한되지는 않는다.
ex) Pascal, Modula-2, Ada에서는 부울형, 문자형, 열거형 등 서수형이 인덱스로 사용되는 것을 허용한다.
- 인덱스 집합이 정수형으로 이루어진 경우, Dimension(차원)별로 하한(Lb), 상한(Ub)이 존재하며, 차원 별 크기는 Ub - Lb + 1로 계산한다.
ex) C/C++, Fortran에서는 인덱스의 범위 검사를 명세할 수 없으나, Pascal, Ada, Java에서는 인덱스의 범위 검사를 명세할 수 있다.
ex) Pascal에서는 배열 인덱스 집합으로 정수가 사용될 경우, 인덱스는 반드시 한정된 영역 내의 수치를 사용해야 한다.
- 배열 인덱스의 바인딩은 보통 정적으로 이루어지지만, 동적 바인딩이 이루어지기도 하며, 일부 PL에서 인덱스 범위의 하한은 묵시적으로 고정되기도 한다.
ex) C/C++, Java에서는 모든 인덱스 범위의 하한은 0으로 고정되며, Fortran에서는 1로 고정된다.
ex) Fortran 77, Fortran 90에서는 인덱스 범위 하한의 Default는 1이다.
ex) 다른 대부분의 PL에서 인덱스 범위는 프로그래머의 의해 명세된다.
- 배열은 인덱스 범위 바인딩 방식과 기억장소 바인딩 방식에 따라 4가지 부류로 나누어진다.
| 첨자 범위 바인딩 | 기억 장소 할당 | 장점 | |
| 정적 배열 | 정적 | 정적 | 효율성 |
| 고정 스택-동적 배열 | 정적 | 동적 | 기억 장소 공간의 효율성 |
| 스택-동적 배열 | 동적 | 동적 | 고정 후 변경 불가 유연성 |
| 힙-동적 배열 | 동적 | 동적 | 고정 후 변경 가능 유연성 |
1. Static Array (정적 배열)
- 인덱스 범위는 정적 바인딩, 기억 장소도 정적으로 배당(실행시간 이전에 배당)되는 배열이다.
- 동적 기억장소 배당 및 회수가 필요하지 않아 실행시간 측면에서 효율적이다.
- 정적 배열은 정적 변수에 속한다.
2. Fixed Stack-Dynamic Array (고정 스택-동적 배열)
- 인덱스 범위는 정적 바인딩, 기억 장소는 동적으로 배당(실행시간 중 배당)되는 배열이다.
- 두 프로시저가 동시에 활성화되지 않는 상황에서, 스택에 배당되기 때문에 한 프로시저에 속한 대형 배열이 다른 프로시저에 속한 대형 배열과 동일한 기억장소 공간을 공유할 수 있어 메모리 측면에서 효율적이다.
- 고정 스택-동적 배열은 준정적 변수에 속한다.
3. Stack-Dynamic Array (스택-동적 배열)
- 인덱스 범위의 바인딩과 기억 장소 배당이 모두 동적으로 이루어지는 배열이다.
- 인덱스 범위가 바인딩되고, 기억장소가 배당된 이후에는 해당 배열 변수의 존속기간 동안 바인딩, 배당은 고정된다.
- 배열의 크기는 배열이 사용되기 직전까지 알려질 필요가 없어 유연하다.
- 스택-동적 배여른 준동적 변수에 속한다.
4. Heap-Dynamic Array (힙-동적 배열)
- 인덱스 범위의 바인딩과 기억 장소 배당이 모두 동적으로 이루어지는 배열이다.
- 힙-동적 배열은 존속기간 동안 여러 번 수정될 수 있다. (유연성)
- 힙-동적 배열은 동적 변수(힙 변수라고도 한다.)에 속한다.
ex) Fortran 77에서는 인덱스는 언어 설계 시간에 바인딩 되므로 인덱스 범위는 정적으로 바인딩 되고, 모든 기억 장소 또한 정적으로 배당된다.
ex) Pascal 프로시저와 C 함수에서 선언된 배열은 고정 스택-동적 배열이다. (C에서 static 키워드가 없다는 가정 하에)
ex) Algol 68, Ada 배열은 스택-동적 배열이다.
ex) Fortran I에서는 동적 배열을 제공한다. 인덱스 범위는 save(저장), deallocate(회수), reallocate(재배당)될 수 있다.
ex) Ada, C/C++에서도 동적 배열을 제공한다. C에서는 malloc, free, C++에서는 new, delete를 통해 힙을 배당/회수할 수 있다.
ex) C/C++에서는 인덱스 범위 검사 기능을 제공하지 않아, 배열을 늘리거나 줄이는 것이 쉽다. 배열은 메모리 셀들의 집합체에 대한 포인터로 취급되어 이 포인터로 인덱싱을 할 수 있다.
ex) Pascal에서 배열의 인덱스 범위는 데이터 형의 일부로서, 상숫값만을 허용한다.
즉, 배열의 크기를 데이터 형 정의 부분으로 고려하기 때문에, 원소들의 데이터 형이 같아도, 배열의 크기가 다르면 다른 데이터 형으로 간주하게 된다.
type asize10 = array[1..10] of integer;
type asize20 = array[1..20] of integer;
! 즉, Pascal에서는 asize10과 asize20은 다른 데이터 형 배열이다.
ex) ISO 표준 Pascal에서는 배열의 데이터 형 정의를 포함하는 형식 매개변수인 Confromant Array(적응 배열)를 제공함으로써 기존의 Pascal에서의 문제를 개선했다.
procedure SORT(var list : array [lower..upper : integer] od person);
...
var student : array[100..200] of preson;
...
SORT(student);
ex) Fortran I에서는 배열 인덱스의 개수를 3개로 제한하였다.(3차원까지만 허용) Fortran I은 3차원 배열까지는 원소들에 매우 빠르게 접근할 수 있으나, 그 이상의 차원부터는 적용되지 않았기 때문이다.
ex) C의 배열은 대괄호 하나 당 한 개의 인덱스만 가질 수 있으나, 대괄호의 개수를 늘릴 수 있는 구조를 가져서 Orthogonality(직교성)을 확보했다.
ex) C/C++, Ada 등 힙-동적 배열을 허용하는 PL에서 크기가 변화되는 배열을 생성할 때, 새 배열을 생성하여 배열 포인터에 배정하는 식으로 행해진다.
아래와 같은 Ada 코드에서
type SEQUENCE is array(INTEGER range <>) of FLOAT;
type SEQREF is access SEQUENCE;
P : SEQREF;
...
p := new SEQUENCE(M..N); -- 포인터에 메모리 할당을 미룰 수 있음SEQUENCE는 정수형 인덱스에 실수형 원소들로 이루어진 크기가 정의되지 않은(range<>) 배열이다.
SEQREF는 SEQUENCE형에 대한 포인터 형의 이름이며, P는 SEQREF형 변수이다.
new를 통해 P에 N-M+1의 크기에 해당되는 SEQUENCE 배열을 할당하고 있다.
- 다차원 배열의 각 원소는 메모리의 적당한 위치에 Mapping 되는데, 이러한 Mapping을 구현하기 위해 배열의 정보를 가진 Descriptor(명세표)를 이용한다. 명세표에는 배열 이름, 원소의 데이터 형, 원소의 길이, 배열의 시작 주소, 각 차원의 상한값, 하한값이 포함된다.

Real A (-2 : 2)
- Real Type의 1차원 배열 A
- 인덱스 하한 값 = -2, 인덱스 상한 값 = 2
- 여기서, one location은 시스템에서 Real이 차지하는 메모리 공간의 크기를 의미이다.
- 원소들이 다차원 배열에 저장되는 순서에 따라 Row-Major(행 우선), Column-Major(열 우선)으로 나뉜다.
(행 우선, 열 우선 개념 참조)
ex) Algol 68에서는 각 Row마다 다른 개수의 Column을 갖는 배열을 만들 수 있다.
[1:a] real x
[1:b] real y
[1:c] real z
w[1] := x
w[2] := y
w[3] := z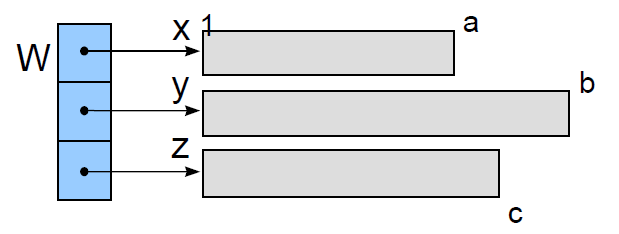
- w는 1차원 포인터 집합이다. w의 원소들은 Real Type Array들을 포인팅한다.
- 즉, W[2][3]은 Y[3]이다.
Slice (슬라이스)
- 배열에서 임의의 한 차원으로 연속적인 원소들로 구성된 부분을 의미한다.
ex) PL/I에서는 *(에스테리스크)를 이용하여 *가 위치한 인덱스의 모든 부분을 선택(Slice)할 수 있다.
w(1:3, 1:5)
w(3,*) ! w의 세 번째 행을 가리킨다.
w(*, %) ! w의 다섯 번째 열을 가리킨다.
ex) Algol 68에서는 w[3, ], w[ , 5]와 같이 빈 공간으로 Slice를 표현한다.
또한, Subarray(부분 배열)에 인덱스를 사용할 수 있어, w[3, 5]를 w[ , 5][3]으로 표현할 수 있다.
그리고, 슬라이스는 다시 배열로 간주되어 인덱스화 할 수 있다. (이 배열 Segment를 식별할 수 있는 특징을 Triiming이라 부른다.)
즉, w[3,2], w[3,3], w[3,4]를 w[3, 2 : 4]로 표현할 수 있다.
그리고, 사용자 정의 열거형이 허용되지 않으므로, 인덱스로 정수만을 허용한다.
ex) APL에서는 w[3 ; ], w[ ; 5]와 같이 세미 콜론을 통해 Slice를 표현한다.
ex) PL/I에서는 부분 배열에 대해 인덱스를 허용하지 않아, 배열 슬라이스를 값으로 가질 수는 있으나 슬라이스를 인덱스화 할 수는 없다.
ex) Fortran, Algol 60에서는 배열의 원소에 대한 연산만 허용하며, 배열 자체에 대한 연산을 허용하지 않는다.
ex) APL, PL/I, Algol 68에서는 A←B, A=B, A:=B와 같은 배열 배정 연산을 허용한다. (두 배열의 크기는 같아야 한다.)
- 몇몇 PL에서는 배열의 기억장소가 배당되는 시간에 해당 배열을 초기화할 수 있게 한다. 이는 컴파일러가 초깃값을 통해 배열의 크기를 설정할 수 있게한다. 편리하지만, 값을 빠뜨리는 실수로 인해 오류를 시스템이 탐지할 수 없게 한다.
ex) Fortran 77에서는 모든 데이터 기억장소는 정적으로 배당되므로, DATA문을 이용하여 적재시간 초기화를 허용한다.
INTEGER X (3)
DATA X /0, 2, 7/ex) C/C++에서는 문자열을 char 배열로 구현하며, 아래와 같이 선언과 동시에 초기화 할 수 있다.
모든 문자열은 널 문자로 끝나므로, 시스템은 문자열 상수에 널 문자를 묵시적으로 삽입한다.
char name[] = "Hong kildong";ex) Pascal, Modula-2는 프로그램 선언부에서 배열 초기화를 허용하지 않는다.
ex) Ada에서는 배열의 초기화에 여러 기능을 제공한다.
type MAT is array(INTEGER range 1..2, INTEGER range 1..2) of REAL;
A : MAT := ((10, 20), (30, 40));
! A에 Row-Major 방식으로 원소를 배정한다.
B : MAT := (1 ⇒ (1 ⇒ 10, 2 ⇒ 20), 2 ⇒ (1 ⇒ 30, 2 ⇒ 40));
! 인덱스를 사용하여 원소를 배정한다.
A : MAT := (1 ⇒ (1 ⇒ 1, others ⇒ 0), 2 ⇒ (2 ⇒ 1, others ⇒ 0));
! others를 통해 나머지 인덱스를 임의의 값으로 한꺼번에 배정한다.
배열 설계 시 고려사항
1) 배열 이름과 배열 원소에 대한 구문
2) 원소값에 대하여 어떤 데이터형이 사용되는가
3) 인덱스로 어떤 데이터 형을 사용할 수 있는가
4) 배열의 크기는 바인딩 되는가
5) 인덱스 범위는 언제 바인딩 되는가
6) 어떤 형태의 슬라이스를 제공하는가
7) 배열을 초기화시키기 위해 어떤 종류의 문장이 허용되는가
8) 배열에 대한 내장된 연산은 어떤 종류가 허용되는가
9) 원소 참조를 표현하는 인덱스 식의 범위를 검사할 수 있는가
7.5 Associative Array (연상배열)
- Index가 아닌, Key 값에 의해 접근되며, 순서를 갖지 않은 원소들의 집합체를 의미한다.
- 연상 배열의 원소들은 Key-Value 형식의 하나의 Pair로 저장된다.
- 연상 배열 설계 시 고려사항으로는 원소의 참조 형식, 연상 배열 크기의 바인딩 시간이 있다.
ex) Perl Hash에 대한 배정문
# Perl의 Hash 변수 이름은 "%"로 시작한다.
%salaries = ( "HONG" => 1200000, "Won" => 2000000,
"Kim" => 1500000, "Lee" => 2500000);
# Perl Hash에서 각 원소의 값을 참조할 경우, 변수 이름은 "$"으로 시작되고,
# Key 값은 중괄호로 표현되며,
# 나머지는 동일한 스칼라 변수 이름으로 치환된다.
$salaries {"Won"} = 2500000;
# delete 연산자를 통해 원소를 해시에서 삭제할 수 있다.
delete $salaries {"Lee"};
# Hash 전체에 Empty Literal을 배정하여 Empty Hash를 생성할 수 있다.
@salaries = ();
# exists 연산자를 통해 해당 Key가 Hash의 원소인지를 T/F로 리턴받을 수 있다.
if (exists $salaries {"Hong"})
- Perl에서의 연상 배열은 원소들이 해시 함수를 통해 저장/추출된다.
- Perl의 연상 배열을 Hash라 부르기도 한다.
- Perl Hash의 크기는 동적으로 관리되어, 새 원소가 추가되면 커지고, 원소가 삭제되면 크기가 줄어든다. (고비용)
- 묵시적 Hash 연산이 효율적이라, 원소들에 대한 탐색에서 Array보다 Hash 구조가 더 효율적이다.
- List의 모든 원소를 처리하는 경우, Hash보다 Array 구조가 더 효율적이다.
- keys 연산자: Hash에 포함된 Key들로 구성된 배열을 리턴한다.
- values 연산자: Hash에 포함된 Value들로 구성된 배열을 리턴한다.
- each 연산자: Hash의 원소 pairs들에 대한 Iteration을 수행한다.
7.6 Record Type (레코드)
- Heterogeneous Data(이질형 데이터)로 구성된 조직적 데이터 형이다.
ex) 보편적인 Record Type 정의 (Pseudo Code)
type stock =
record
name : array[1..30] of char;
price : array[1..365] of real;
dividend : real;
volume : array[1..365] of integer;
exchange : (nyse, amex, nasdaq) ! Enumerate Type
end;
var newstock, ibm : stock;
ex) Cobol에서의 Record Type을 structure라 부르며, 이는 최초의 Record Type이다.
ex) PL/1은 Cobol의 형태를 따른 Record Type을 정의해놓았다.
ex) Pascal은 Record Type을 record 부르며, record에 대한 EBNF 표기는 아래와 같다.
<record-type> ::= record <field-list> end
<field-list> ::= <fixed-part> [; <variant-part>] | <variant-part>
<fixed-part> ::= <record-section {; <record-section>}
<record-section> ::= {<identifier-list> : <type>}- 각 <record-section>은 식별자*와 그에 대한 데이터 형이 pair를 이루어 하나 이상의 List로 기술된다.
* Field Designator(필드 지정자)
- 위와 같이, 데이터 형과 대응되는 식별자를 의미한다.
- 필드 지정자의 Scope는 해당 레코드에 한정되므로, 각 필드는 서로 구분되어야 한다.
ex) Algol 68에서의 Record 선언 및 초기화
- Algol-W, Ada 또한 이러한 초기화 기능이 Built-In 되어있다.
var ibm, csc : stock; # stock record 형 변수 ibm, csc 선언 #
# ibm, csc에 대한 초기화 #
ibm := make-stock('IBM', 0..0, 5.25, 0..0, nyse);
csc := make-stock('Computer Science Corp.', 0..0, 0, 0..0, nyse);
ex) Ada에서는 Record의 원소들에 모든 데이터 형이 허용된다.
type FLIGHT; -- Forward Reference
type LISTOFFLIGHTS is access FLIGHT;
type FLIGHT is
record
FLIGHTNO : INTEGER range 0..100;
SOURCE : STRING;
DESTINATION : STRING;
RETURNFLIGHT : LISTOFFLIGHTS;
end record;
-- X, Y가 LISTOFFLIGHTS형 변수라면,
-- 아래와 같이 FLIGHT를 포인팅하는 포인터 멤버도 가질 수 있다.
X.RETURNFLIGHT := Y; Record에서 각 Field를 참조하는 두 가지 방법 (Functional, Dotted)
1. Functional Notation (Knuth가 제안한 방법)
- 각 필드를 Field(Record_Name)처럼 함수처럼 표기하는 방식을 의미한다.
ex) name(ibm), price(ibm)[25], dividend(ibm), volume(ibm)[25], exchange(ibm)
ex) Algol 68은 Functional Notation에 가까운 표기법을 사용한다.
mode stock = struct string name, int dividend, int exchange)
name of ibm # name(ibm)에 해당된다. #
exchange of ibm # exchange(ibm)에 해당된다. #
2. Dotted Notation
- "."(Dot; 온점)을 이용하여 변수 이름과 Field 이름을 분리하는 방식을 의미한다.
ex) ibm.name, ibm.price[25], ibm.dividend, ibm.volum[25], ibm.exchange
ex) Pascal, Ada는 Dotted Notation을 사용한다.
ex) Pascal의 with문
- 필드 이름 앞에 변수 이름을 생략할 수 있게 한다.
- Programmability를 제고한다.
// with문 없이, 필드 이름에 변수 이름을 계속 붙이는 형식
newstock.name := "dec";
newstock.dividend := 36;
newstock.exchange := amex;
// with문을 통해, 변수 이름을 한 번만 명시하는 형식
with newstock do
begin
name := "dec";
dividend := 36;
exchange := amex
end;Variant-Part(가변부)를 갖는 Record Type
- 가변 레코드는 데이터 형을 Union(합성)하기 위한 기법이다.
- Variant-Type을 가진 레코드 형에서는 데이터 형에 따른 택일 변환들이 기술된다.
- 각각의 변환은 Discriminant(판별자)의 특정값에 따라 하정된 구성 요소들로 이루어진다.
- 이러한 변환을 몇몇 PL에서는 case문을 사용하여 표현한다.
ex) Pascal에서의 가변 레코드에 대한 EBNF 표기
<variant-part> ::= case <tag-field> <type-identifier> of <variant> { ; <variant>}
<tag-field> ::= [ <identifier> :]
<variant> ::= [ <case-label-list> : (<field-list>) ]
ex) Ada에서의 가변 레코드에 대한 EBNF 표기
<variant-part> ::= case <discriminant-name> is {when <choice> { | <choice> | ⇒ <component-list> }
end case
<choice> ::= <simple-expression> | <discrete-range> | others
ex) Pascal에서의 가변 레코드 구성 예시
type option = (sixmonths, ninemonths);
case x : option of
sixmonths : (exprice : real)
ninemonths : (nuprice : integer)
end
// x값이 sixmonths -> stock의 exprice 필드에 접근 가능
// x값이 ninemonths -> stock의 nuprice 필드에 접근 가능
ex) Pascal에서의 일반화된 리스트 구성 예시
// 리스트의 원소들은 atoms이거나 sublist이다.
// 레코드에 대한 정의는 가변부를 포함하고 있는 형태이다.
type listptr = ↑listnode;
type listnode =
record
link : listptr;
case tag : boolean of // 가변부
false : (data, char); // 가변부
true : (downlink : listptr) // 가변부
end;
var p, q : listptr;
// p↑.tag = false이면, p↑.data가 존재하며, char 형을 띄게 된다.
p↑.tag := true;
p↑.downlink := q;
p↑.tag := false;
writeln (p↑.data);
// 위와 같이, 가변 레코드의 필드 값이 수시로 변할 수 있어,
// 컴파일 시간이 아닌, 실행 시간에 확정되어야 한다.
// Pascal과 같은 가변부의 사용은 심각한 오류를 발생시킬 수 있다.
ex) Euclid에서는 매개변수화딘 변수형을 허용하여 tag가 선언에서 형식 매개변수로 취급될 수 있다.
// 기존에 Euclid에서 데이터 형 값을 검색하는 방법
// Discriminant를 이용한 case 문장은 레커도의 어느 변환부가 사용되고 있는지를,
// 실행 시간에 검사하는 것이 가능하다.
case dixcriminating w = z on tag of
true ⇒ x := w; end
false ⇒ y := w; end
end case
var x : listnode (true)
var y : listnode (false)
var z : listnode (any)
// Euclid에서는 tag 필드가 일단 초기화 되면 어떠한 배정도 불가능하다.
// any 키워드를 통해 z가 true 혹은 false값 중 하나로 추후에 선택되도록 할 수 있다.ex) Ada에서도 Euclid와 유사한 방법으로 가변 레코드의 문제를 해결했다. (any 키워드를 사용하지는 않는다.)
7.7 Pointer Data Types (포인터 자료형)
- Pointer(포인터): 어떤 객체에 대한 참조를 의미한다.
- Pointer Variable(포인터 변수): 객체를 참조하기 위한 주소를 값으로 취하는 식별자를 의미한다.
포인터의 필요성
- 실행시까지 생성될 항목 개수가 정해지지 않는 문제를, 객체에 명시적인 이름을 제공하지 않고,
많은 항목을 동적으로 연결하는 방법을 통해 해결하기 위해 포인터 개념이 필요하다.
- 포인터는 하나의 데이터가 다수의 리스트에 동시에 연결되는 것을 허용하여,
데이터 항목 간, Multiple Relationship(다중 관계)를 생성하기 용이하게 한다.
- 포인터 형은 배열, 레코드와 같은 구조형에 속하지 않으며,
데이터를 저장하는 것이 아닌 다른 객체를 참조하는 데이터 형이기 때문에 스칼라 형은 또한 아니다.
- 전반적으로, 포인터는 프로그램 작성력을 향상시킨다.
ex) FORTRAN 77에서는 포인터 개념이 없어, Binary Tree와 같은 동적 구조체를 표현하기가 까다롭다.
- Heap(힙): 동적으로 객체가 배당되는 기억장소 영역을 의미한다.
- Heap Variable(힙 변수): 힙 영역에 배당되는 변수를 의미한다.
- 특히, 힙에서 생성되어 식별자 없이 포인터, 참조형 변수에 의해 참조되어야 하는 변수를
Anonymous Variable(무명 변수)라 부른다.
- Pointer Type(포인터형)은 메모리 위치를 곧 바로 가리키는 데이터 형이며,
Reference Type(참조형)은 객체 자체를 가리키는 데이터 형을 의미한다.
- 포인터에는 일부 산술 연산이 가능한 경우가 있지만,
참조형에 대한 산술 연산은 의미가 없어 오류 발생 가능성을 줄인다.
- 대부분의 PL에서 포인터 값(주솟값)과 포인터가 가리키는 값에 대한 구분이 전적으로 프로그래머에게 달려있어
오류 발생의 소지가 있으나, 참조형에는 이러한 위험성이 없다.
ex) C/C++에서의 포인터 형 연산자: *
ex) Ada에서의 포인터 형 연산자: access
ex) Pascal에서의 포인터 형 연산자: ↑
ex) 레코드에 대한 포인터가 필드를 참조하는 방식
C/C++: P->age 혹은 (*P).age
Pascal: P↑.age
Ada: P.age
Pointer Type 제공 시, 발생할 수 있는 문제점
1. 다수의 포인터 변수가 동일한 객체를 가리키고 있을 때(이명), 이를 인지하지 못한 프로그래머가
해당 객체를 수정/소멸시켜 내용을 변경시키는 등의 논리적 오류를 초래할 수 있다.
2. 무명 객체가 포인터의 포인팅을 받지 못하면(Garbage) 해당 메모리에 접근할 방법이 없어, Memory Leak(메모리 누수)가 발생할 수 있다.
3. 일반적인 변수들은 L-Value, R-Value를 나타내는 데 반해,
포인터 변수는 L-Value, R-Value외에 가리키고 있는 객체의 값 까지 추가적으로 표현할 수 있어야 한다.
4. Dangling Reference(허상 참조) 문제
※ Dangling Reference(허상 참조)
- 포인터 변수가 의미없는 것을 가리키고 있는 현상을 의미한다.
- 포인터 변수의 Lifetime이 프로그래머의 동적 할당/반환에 귀속되어 있을 때, 허상 참조가 발생할 수 있다.
(즉, 제 때 반환하지 않으면, 허상 참조가 발생할 수 있는 것이다.)
ex) Algol 68에서는 포인터 변수의 Lifetime이 가리키는 객체와 일치되어 허상 참조가 발생할 수 없는 구조이다.
Pointer Type 설계 시, 고려사항
1. 포인터 변수의 Scope와 Duration은 얼마인가.
2. 힙 변수의 Duration은 얼마인가.
3. 포인터가 가리키고자 하는 객체의 데이터 형에 제한을 받는가.
4. 포인터가 동적 메모리 관리, 간접 주소 지정에 사용 가능한가.
5. PL이 포인터형, 참조형 둘 다 지원 하는가.
포인터 배정과 Dereferencing(역참조)
- 포인터형을 제공하는 PL은 일반적으로 포인터 배정 연산과 Dereferencing 기능을 제공한다.
- 포인터 배정: 포인터 변수의 값에 유효한 주소를 설정하는 연산이다.
- 역참조:
- 포인터 변수의 두 가지 해석방법
1. 포인터 변수를 해당 포인터가 바인딩 되어 있는 값에 대한 참조로 해석하는 방법
(일반 변수의 해석방법과 같다.)
2. 포인터 변수를 해당 포인터가 가리키는 메모리에 저장된 참조로 해석하는 방법
(해당 포인터를 역참조하는 것으로 해석하는 방법)
Pascal, Ada에서의 포인터
ex) 초기 Pascal에서의 포인터는 레코드형 객체만을 가리키는 것으로 제한되었다.
ex) Pascal에서의 포인터형 선언
type nodeptr = ↑node;
node = record
number : real;
net : nodeptr
end
// nodeptr의 정의에서 node가 정의되기도 전에 나타날 수 있는 것은
// Pascal의 원칙인 Forward Reference(전위 참조)의 몇 안되는 예외사항이기 때문이다.
var x, y : nodeptr
// 포인터 변수 x, y의 선언
x
// node형 객체를 가리키는 nodeptr 형의 포인터 변수
x↑
// node형 객체를 나타내며, new(x)로 생성된다.
x↑.number
// x가 가리키고 있는 노드의 실수 부분(필드값)
x↑.next
// x가 가리키고 있는 노드의 포인터 부분(필드값)
var P, Q : nodeptr;
...
new(P);
P↑.number := 3.54;
P↑.next := nil;
ex) Pascal에서 포인터 변수에 정의된 연산: Assignment(배정), Equality(동등 연산), Dereference(역참조)
ex) Pascal에서의 메모리 동적 할당/반환: new(x), dispose(x)
ex) Pascal에서 null은 nil로 표현된다.
ex) Ada에서의 포인터형 선언
type NODE
type NODEPTR is access NODE
type Node is
record
NUMBER : REAL;
NEXT : NODEPTR;
end record;
P, Q : NODEPTR := new NODE(3.54, null)
P.NEXT := Q.NEXT;
P.NUMBER = Q.NUMBER;
-- Q가 가리키는 객체를 P도 가리키게 일일히 대입하는 방법
P.all := Q.all;
-- all 지정자를 통해 모든 필드를 선택하는 방법
| PL | 포인터 배정 | 값 배정 | 필드 지정 | 생성 |
| Pascal | p := q | p↑ := q↑ | p↑. 필드명 | new(p); |
| Ada | p := q | p.all := q.all | p.필드명 | p := new 데이터 형 [:= 초기값] ; |
C와 C++에서의 포인터
- 주소가 어셈블리 언어에서 사용되는 것 처럼 사용된다. (유연성)
- 허상 참조, 분실된 동적-변수 문제가 발생할 수 있으며, 해결책이 제시되지 않고 있다.
- 포인터 산술 연산이 가능하다.
- 메모리에 있는 거의 모든 변수를 포인팅할 수 있다.
- "*"로 역참조 연산을 수행하고, "&"를 주소 연산자로 사용한다.
- C/C++에서 배열 이름은 그 자체로 상수 포인터이다. (즉, 배열 이름에 어떤 주솟값을 대입하기가 불가능하다.)
- void* 형을 통해 데이터 형이 중요하지 않고, 메모리 공간을 주고 받을 때 유용하게 사용할 수 있다.
7.8 Type Conversion (자료형 변환)
- 시스템에서 Type Specific Op(형 고정 연산)을 지원하는 경우에 generic Op(혼합형 연산)을 사용하고자 하는 경우,
식에 사용된 데이터 형의 Type Conversion(형 변환)이 필요하게 된다.
- 일반적인 PL에서는 스칼라형 사이의 형 변환을 제공하며,
구조 자료형이나, 사용자 정의형 사이에서의 형 변환은 지원하기 어렵다.
- 형변환은 Implicit Type Conversion(묵시적 형 변환)과 Explicit Type Conversion(명식적 형 변환)으로 나뉜다.
Implicit Type Conversion(묵시적 형 변환) = Automatic Conversion(자동변환) = Coercion(강요변환)
- 시스템에서 자동으로 수행하는 형 변환이다.
Explicit Type Conversion(명시적 형 변환) = Type Cast(타입 캐스트)
- 프로그래머가 명시하는 형 변환이다.
ex) PL/I에서는 Built-In 데이터형들 사이에 무조건적인 묵시적 형 변환을 제공한다.
문자형에서 실수형, 실수형에서 정수형, 비트형에서 문자형 변환 등이 가능하다.
Widening(확대 변환)
- Domain(정의역)에 있는 모든 값들이 Range(치역)에 그대로 대응되는 형 변환이다.
- 정의역이 치역보다 넓어 데이터의 손실이 발생되지 않는다.
ex) 정수형에서 실수형으로의 변환 시, 정수형의 범위가 실수형의 가수 범위 보다 클 때 확대 변환이 일어나는 것이다.
(그렇지 않으면, 정밀도를 잃어버리게 된다.)
Narrowing(축소 변환)
- 정의역에 있는 어떤 값이 치역의 한 값에 대응할 수 없는 형 변환이다.
- 데이터의 손실이 발생될 수 있다.
ex) PL/I에서는 실수형에서 정수형으로 변환할 경우, Truncation(버림)한다.
ex) Pascal에서는 정수형에서 실수형으로의 확대변환과 subrange(부분 영역)들 사이의 확대/축소 변환만을 지원한다.
ex) C/C++, Java에서는 확대 변환에는 자동 변환이 허용되며, 축소 변환은 캐스트 명령을 이용해야 한다.
7.9 자료형 동치
ex) Pascal 코드
type T = array[1..100] of integer;
var x, y : array[1..100] of integer;
z : array[1..100] of integer;
w : T;
v : T;- 위 코드에서 변수 v, w, x, y, z를 동일한 데이터 형으로 해석하는가 아닌가에 대한 두 가지 방법이 있다.
1. Name Equivalence (이름 동치)
- 두 변수를 함께 선언하거나 같은 데이터 형 식별자를 사용하여 선언했다면,
두 변수는 동일 데이터형으로 인식되며, 반대의 경우도 성립한다.
- 이름 동치는 Ada와 같은 언어가 따른다.
ex) 위 코드에서 x, y는 동치, v, w도 동치이나, w와 x와 z는 서로 다른 데이터 형으로 취급한다.
2. Structural Equivalence (구조적 동치)
- 데이터 형의 Component(구성요소)가 모든 측면에서 같다면,
두 변수는 동일 데이터형으로 인식되며, 반대의 경우도 성립한다.
- 구조적 동치는 Algol 60, Algol 68, Fortran, Cobol 등 대부분의 PL이 따른다.
ex) 위 코드에서 v, w, x, y, z는 모두 동일 데이터 형으로 취급한다.
ex) Pascal 선언 구문
type T1 = T2;
// T2는 미리 정의되었다 가정하자.
// 이름 동치를 따르면, T1과 T2를 서로 다른 데이터 형으로 간주한다.
// 구조적 동치를 따르면, T1과 T2를 동치인 것으로 간주한다.
// 또한, T1과 T2는 선언 동치이기도 하다.
array[1..100] of real;
array[1..10, 1..10] of real;
// 위 문장은 구조적 동치를 따르더라도 서로 다른 데이터 형으로 간주하게 된다.
3. Declaration Equivalence (선언 동치)
- 이름 동치 개념에 추가해서 재선언을 하여 원래의 구조를 그대로 사용하는 경우에도
원본 데이터 형과 동치로 간주하는 방법이다.
- 이름 동치와 구조적 동치의 중간 개념에 해당된다.
ex) Pascal 선언 구문
type T1 = array[1..100] of integer;
type T2 = array[1..100] of integer;
type T3 = T2;
// 이름 동치에서는 T1, T2, T3를 모두 다른 데이터형으로 간주한다.
// 구조적 동치에서는 T1, T2, T3를 모두 같은 데이터형으로 간주한다.
// 선언 동치에서는 T2, T3만 서로 같은 데이터형으로 간주한다.
* {구조 동치 동등 데이터 형} ⊃ {선언 동치 동등 데이터 형} ⊃ {이름 동치 동등 데이터 형}
Type Compatibility (데이터 형 적법성)
- 객체의 데이터 형이 특정 Context(문맥)에서 정당한 지를 결정하는 Semantic Rules(의미 규칙)을 의미한다.
- 사용된 구성자들의 데이터 형이 동치이어야 함을 완화시켜야 할 때 사용되는 개념이다.
ex) "if x = y then ..."의 동등 연산에서 적법성은 단순히 동일 데이터형으로 간주하여 만족시킬 수 있다.
ex) "v := e"에서 v와 e가 동일 데이터 형이라면 적법성은 만족시킨다.
(단 여기서, v는 L-Value이고, e는 R-Value이기 때문에 큰 차이를 갖는데, 이를 대부분의 PL에서는 Dereferencing을 통해 해결한다.)
ex) Pascal에서는 모든 부분 영역형을 새로운 데이터 형으로 간주하여, 이들의 모든 경계가 컴파일 시간에 정해진다.
ex) [1..100]과 [-10..10]은 서로 다른 데이터 형이며, [1..10]의 경우 두 영역형에 모두 포함되어
[1..10] 데이터 형이 Overlap(중첩)되었다 표현한다.
ex) Ada에서는 Pascal의 부분 영역형 선언을 subtype을 통해 표현하고, 부분 영역형을 새로운 데이터 형으로 간주하는 선언을 Derived Type(파생 데이터 형)이라한다.
subtype ainteger is INTEGER range 1..100; -- Subtype
type binteger is new INTEGER range 1..100; -- Derived Type7장 자료형
7.1 자료형과 형 선언
자료형
- Object(객체)의 집합과 이 객체들의 Instance(실체)들에 대한 연산들의 집합이다.
- 연산의 종류로는 Create(생성), Build-Up(작성), Destroy(소멸), Modify(수정), Pick Apart(분해)와 같은 것들이 있다.
ex) Lisp에서 주요 데이터 형은 "S-Expression"이라 불리는 Binary Tree이며, 기본 연산으로는 CAR, CDR, CONS를 제공한다.
- 명령형 PL의 Built-In 데이터 형으로는 정수형, 실수형, 문자형, 논리형과 이들에 대한 연산이 제공된다.
ex) Fortran 77, C, Java, Ada의 기본 데이터 형
| Fortran 77 | C | Java | Ada |
| INTEGER | int | int | integer |
| REAL | short | short | float |
| LOGICAL | long | byte | boolean |
| CHARACTER | float | long | character |
| DOUBLE | double | float | natural (자연수) |
| COMPLEX | char | double | duration (시간값) |
| char | priority (우선순위) | ||
| boolean |
- 변수들의 많은 특성들은 선언문에서 확정된다.
- 어떤 데이터 형 변수를 선언한다는 것은 변수 값에 관한 추상적인 개념만을 주는 것이며, 실제 구현의 자세한 사항에 대해서는 데이터 형 정의로 미루는 것이다.
- 데이터 형 선언의 다른 특징은 명세부를 실질적인 구현 부분으로부터 분리되도록 지원한다는 점이다.
- 데이터 형 시스템은 서로 다른 특성을 가진 객체들을 구별함으로써 신뢰성과 가독성을 제고한다.
Typing Mechanism (데이터 형 기법)
- 데이터 형을 정의하고, 변수를 특정 데이터형으로 선언하는 설비를 의미한다.
- Fortran, Cobol과 같은 구형 PL에서는 빈약하게 제공되었고, 근래의 PL에서는 다양한 형태로 제공되고 있다.
변수, 데이터 형 선언
- 컴파일러에 의한 정적 데이터 형 검사가 수행된다.
- 명세부와 구현부가 분리하여 추상 데이터 형 구현이 가능하다.
- 프로그램의 신뢰성과 판독성이 증가한다.
데이터 형에 관련된 쟁점 사항
- 데이터 형 정보와 바인딩 시점 (번역 시간에 바인딩 할 것인가, 실행 시간에 바인딩 할 것인가)
- 강 데이터 형인가
- 데이터 형의 Compatibility(적법성)와 동치 관계
- 데이터 형의 매개변수와 매개변수의 평가 시점
Strong Type (강 데이터 형)
- 데이터 형에 관한 모든 특성들이 컴파일 시간에 확정되는 데이터 형을 의미한다.
- 사용되는 모든 변수들의 선언과 변수들의 모든 데이터 형 정보를 미리 정해야 한다.
- 프로그램의 신뢰성, 유지 보수성, 판독성을 제고한다.
Data Type Member (데이터 형 구성원)
- Object(객체), Element(요소), Value(값)와 같은 개념들이 여기에 해당된다.
- 데이터 형 구성원들은 데이터 형의 Domain(영역)을 구성한다.
Literal (리터럴)
- 프로그램에서 사용자가 작성한 데이터 형 구성원을 의미한다.
- Symbol들이 나열된 순서로 값이 정의된 상수이다.
ex) 논리 자료형에 대한 리터럴은 {true, false}이다.
Scalar Type (스칼라 형) = Simple Type (단순형)
- 데이터 형의 영역이 단순한 상수 값들로만 구성되어 있는 데이터 형을 의미한다.
- 대부분의 PL에 Built-In된 정수형, 실수형, 논리형, 문자형 등이 대표적인 스칼라 형이다.
Structured Type (구조형)
- 데이터들의 집합을 구성원으로 갖는 데이터 형을 의미한다.
- 구조형은 필드들의 집합으로 되어있으며, 필드들은 자신의 데이터형을 따로 갖는다.
ex) 배열, 레코드는 주요한 구조형 중 하나이다.
ex) Pascal의 데이터 형 구조
ex) Ada의 데이터 형 구조
ex) Java의 데이터 형 구조
7.2 단순형
- 모든 PL은 Built-In 데이터 형을 갖고 있으며, 수치 자료형, 논리형, 문자형과 같은 단순형들이 이에 해당된다.
- 미리 정의되지 않은 단순 데이터 형 또한 존재할 수 있는데 열거형, 부분 영역 데이터 형이 이에 속한다.
- 단순 데이터형 객체들은 서수형(이산형), 실수형으로 나누어진다.
- 서수형(이산형): 객체들을 순서대로 나열할 수 있는 데이터 형
- 실수형: 객체들의 순서를 정의할 수 없는 데이터 형
Number (수치형)
- 기본적인 스칼라 형으로, 각 데이터 객체가 정수 혹은 실수의 근사 값을 표현한다.
- Built-In 수치형에서 산술적인 부분들은 기계에 의존하여 구현된다.
- 고급 PL로 기술된 정수, 실수의 연산이 그대로 기계에 내장된 코드로 변환되므로 연산 속도가 매우 빠르나, 이 때문에 프로그램 이식성이 떨어진다.
- Precision(정밀도)와 수치 표현이 기계에 따라 다르다는 것은 동일한 계산을 수행하는 프로그램이라도 기계에 따라 다른 결과를 내는 것을 의미한다.
ex) Ada, Java는 수치들의 이러한 기계 의존성을 극복했다.
Ada는 MAX_INT, MIN_INT를 도입하고, short integer, long integer의 허용 범위, 사양, 실수의 유효 숫자 자릿수, 사용 영역, 실수들 사이의 폭을 프로그래머가 선언부에서 선언 가능하도록 하였다.
type COEF is digits 10 range -1.0..1.0;
! COEF: -1.0 ~ 1.0 범위를 갖는 10자리의 유효숫자를 가진 값
type MONEY is delta 0.01 range 0.0..100.0;
! MONEY: 0.0 ~ 100.0 범위를 가지며, 0.01 단위로 증감되는 값
또한, 표현 가능한 수치 데이터 형 T의 개수(T'DIGIT), 최솟값(T'SMALL), 최댓값(T'LARGE)와 같은 속성을 사용 가능하도록 했다.
ex) Java는 수치 데이터 형 표현에 사용되는 비트수와 방법을 정의하여 기계 구현 바인딩을 언어 정의 바인딩으로 이전시켜 기계 독립성을 확보했다.
Polymorphism (다형성)
- 동일 속성의 연산자가 피연산자의 데이터형에 따라 다른 것으로 간주되는 개념이다.
- Ada, C++등에서 제공된다.
ex) + 연산자: 정수형 덧셈 연산자, 실수형 덧셈 연산자, 행렬 덧셈 연산자 등 여러가지로 해석된다.
혼합형 연산 해결 방법
1. 피연산자와 연산 결과에 대한 데이터 형을 표로 제공하는 방법
2. 연산 결과의 데이터 형을 미리 결정하여 연산을 수행하는 방법
- 피연산자가 연산 결과의 데이터 형과 다르면 결과형으로 변환하여 연산한다.
ex) P = Q + I / J
방법 1: P = Q + REAL(I / J)
방법 2: P = Q + REAL(I) / REAL(J)
ex) Algol 68에서 혼합형 연산을 처리하기 위해 제공한 연산 결과에 대한 데이터 형 표 (Widening을 기본으로 하는 규칙)
| + 연산자 | integer | real | double |
| integer | interger | real** | double*** |
| real | real** | real | double* |
| double | double*** | double* | double |
*: real -> double 변환 후 연산
**: integer -> real 변환 후 연산
***: **, * 변환 후 연산
Boolean (논리형)
- 값의 영역이 True, False 단 두가지로 제한되는 데이터 형이다.
- and, or, not, implies(imp), equivalence(equiv)등의 연산이 제공된다.
1) x and y = if x then y else false
2) x or y = if x then true else y
3) not x = if x then false else true
4) x imp y = if x then y else true
5) x equiv y = if x then y else not y
ex) Algol 60에서 논리형은 true, false로 제공되며, 숫자와의 혼합 연산을 허용하지 않는다.
ex) Ada, Pascal에서는 논리형을 미리 정의된 열거형 {FALSE, TRUE}으로 제공하며, 프로그래머에 의해 논리형이 수정될 수 있다.
ex) PL/I에서는 값이 0이 아닌 비트를 하나이상 포함하면 True로 간주하고, 모든 비트가 0인 비트열 혹은 공비트열을 False로 간주한다.
ex) PL/I에서 9 < 8 < 7의 값은 아이러니하게도 True이다. (9 < 8) < 7 = 0(False) < 7 = True
ex) Java에서는 논리형 상수로 true, false만 제공하며, and(&&), or(||), not(!) 연산 외에는 어떤 연산도 수행할 수 없다.
문자형
- 1960년대 중반, 범용성 고급 PL에 문자열 조작을 위한 특성들에 요구되기 시작했다.
- 변수들이 문자열을 값으로 가질 수 있도록 문자열을 데이터 형으로 허용하고,
문자들의 정합 순서를 정의하여 관계 연산자를 문자열에 사용할 수 있도록 요구되었다.
- 연산 결과로써 발생되는 문자열의 길이는 컴파일 시간에 결정될 수 없으므로 문자열 데이터에 대한 기억 장치는 동적으로 배당/회수 되어야 한다는 점이 주요 쟁점이었다.
* Hollerith 문자열
- 출력을 위한 문자열이다.
- 문자열을 정수 변수에 배정하여 사용한다.
- 초창지 수치중심 PL(Fortran, Algol 60)에서 주로 사용되었다.
ex) PL/I에서는 위와 같은 문자열에 대한 요구들을 모두 제공한 최초의 PL이었다.
PL/I에서 문자열 변수들은 논리값 생성을 위한 관계 연산자를 사용할 수 있으며, 배정문의 왼쪽, 오른쪽 모두 위치할 수 있다. (L-Value, R-Value의 성질을 모두 갖는다.)
DCL A CHAR(10);
! 길이가 10인 문자열 A
DCL B CHAR(80) VARYING;
! 최대 길이가 80인 문자열 B
DCL C PIC 'AAXX99'
! 영문자 2개, 임의의 문자 2개, 숫자 2개로 이루어져야 하는 문자열 C
! 즉, 문자열의 조건을 명시하는 방식
PL/I에서는 문자열 조작을 위해 아래 6가지 연산을 제공한다.
1. A | B
- 연결 연산자이다.
- 두 개의 피연산자를 요구하는 Infix Operator(중위 연산자)이다.
2. INDEX (A, B)
- 문자열 B가 A의 부분 문자열이라면, A에서 B가 나타난 첫 번째 인덱스를 리턴한다.
3. LENGTH (A)
- 문자열 A의 길이를 리턴한다.
4. SUBSTR (A, n1, n2)
- 문자열 A에서 n1번째 인덱스부터 시작하여 n2개의 문자인 A의 부분 문자열을 값으로 리턴한다. (부분 문자열 연산)
- SUBSTR()은 L-Value를 가져 SUBSTR()가 지칭하는 부분 문자열을 곧바로 수정 가능하다.
5. TRANSLATE (A, B, C)
- 문자열 A에 포함된 C 문자들을 모두 B 문자로 바꾼다.
6. VERIFY (A, B)
- 문자열 A에는 있으나, 문자열 B에는 없는 첫 번째 문자의 인덱스를 리턴한다.
ex) PL/I 문자열 설비들은 구현의 어려움, 실행 시간의 비효율 등의 고 비용을 치뤘다.
ex) Pascal은 한 문자만을 값으로 하는 문자형(char)만 존재하며, 문자열은 1차원 배열로 정의된다.
문자열에 대한 연산은 아래와 같은 두 가지로 제공한다.
1. ord(C) : 정합 순서에서 문자 C의 순서값을 리턴한다.
2. chr(X) : ord() 함수의 역함수이다. 정합 순서상에서 X번째 문자를 리턴한다.
ex) C언어에서 문자열은 문자 배열로써 구현되며, 문자열에 대한 연산은 따로 없으며, 시스템에서 제공하는 I/O 정도만 정의되어 있다.
ex) Java에서 문자 코드는 16bits Unicode를 원칙으로 하며, 정수형과의 데이터 형 변환이 가능하다. 문자열을 객체로 간주하여 Java,long,static 클래스의 Instance로 선언하여 사용 가능하다. 물론, 문자열을 문자 배열로 정의하는 것 또한 가능하다.
7.3 Enumerated Data Types (열거형)
- 열거형 객체들의 영역은 리스트로 정해지며, 열거형 객체에 대한 연산으로는 동등, 순서 관계와 배정 연산이 있다.
- 열거형에 제공되지 않으면 Literal 값에 정수값을 일일히 대응시켜 표현해야 하는데, 이는 프로그램 판독성을 저해한다.
- 프로그래머가 나열한 순서가 곧 해당 열거형 원소들의 순서이다.
ex) Pascal은 프로그래머가 열거형 데이터를 정의할 수 있게 허용한 초기 PL중 하나이다.
Pascal에서 열거형 변수의 선언과 활용은 아래 코드와 같다.
또한, pred(), succ()를 통해 특정 열거형 원소의 전후에 데이터를 삽입할 수 있다.
(pred: predecessor, succ: successor)
type months = (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec);
var x, y, z : months;
x := Jan;
y := jun;
if x = y then z := Nov else z := Dec
pred(Jun) = May
succ(Jun) = Jul
! pred(Jan), succ(Dec)는 연산 결과가 정의되지 않는다.
열거형의 문제점
ex) Pascal에서는 동일한 상수 이름을 다수의 열거형의 Literal 값으로 사용 가능하게 하는 Multiple Definition(다중 정의)을 허용하지 않는다.
ex) Ada에서는 열거형의 모든 Literal 식별자들의 사용을 제한하지 않는다. 즉, Multiple Definition을 허용한다.
그러므로, 다중 정의된 Literal은 문맥에 따라 결정되거나, 열거형 이름을 통해 제한해서 사용하게 한다.
type months = (Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec);
type summermonths is (Jun, Jul, Aug);
x : months; y : summermonths;
months'ORD(Jul) ! months 열거형의 Jul을 의미
summermonths'ORD(Jul) ! summermonths 열거형의 Jul을 의미Multiple Definition 해결책
ex) Pascal에서는 기존의 열거형 혹은 정수의 부분 집합과 같은 Subrange(부분 영역) 데이터 형을 제공한다.
본래 데이터 형이 허용하는 값들 중 상한과 하한을 지정하여 범위를 축소 시키며,
본래 데이터 형이 지원하는 모든 연산을 그대로 사용할 수 있다.
부분 영역형 변수의 값들에 대한 영역 검사는 실행 시간에 수행된다.
본래 데이터 형과 부분 영역형 사이의 혼합 연산이 가능하긴 하나, 구현 의존적이어서 매번 완전한 결과를 기대할 수 없다.
type summermonths = Jun..Aug;
! months 열거형의 부분 영역형 summermonths 열거형
! 하한: Jun, 상한 Aug
ex) C/C++에서는 정수형 상수에 이름을 부여하는 의미로써 열거형을 제공한다.
열거형 원소에 따로 값을 지정하지 않으면, 먼저 포함된 원소부터 0, 1, 2, ...로 부여된다.
다수의 원소에 같은 값을 지정할 수 있고, 값을 오름차순 혹은 내림차순으로 지정할 필요도 없다.
또한, 열거형에 식별자를 함께 선언하여 별도의 데이터 형으로 만들 수도 있다.
열거형은 int형으로의 변환을 허용하며, int형에서 열거형으로의 변환은 명시적 캐스트를 통해 이루어져야 한다.
그리고 switch문의 case문에 열거형 변수를 위치시킬 수 있다.
snum {small, meidum, large};
snum size {small, medium, large};
size k = small;
int i = medium;
k = i; // Error!
k = size(i); // Explicit Type Casting
7.4 배열
- 근래의 PL들에서는 여러 데이터를 묶어서 하나의 단위로 처리할 수 있는 Structured Data Types(구조형)*으로써 Array와 Record를 제공하고 있다.
* Structured Types(구조형) = Aggregate(집합체) = Composite Type(복합형)
- Array는 집합체에서 Index를 통해 원소를 식별하는 Homogeneous Data(동질형 데이터)의 집합체이다.
- Record는 원소를 식별자로 구분짓는 Heterogeneous Data(이질형 데이터)의 집합체이다.
Array (배열)
- 이름, 차원, 원소의 데이터 형, 인덱스 집합의 데이터 형과 범위 등으로 정의된다.
- 배열에서 선택 연산은 배열이름, 인덱스 값 집합에서 한 원소에 대한 Mapping이다.
ex) Fortran, PL/I, Ada에서는 배열 인덱스를 소괄호로 표현한다.
Ada에서는 번역시간에 함수인지, 배열 원소인지를 정적으로 구분한다.
ex) Pascal, C/C++, Modula-2, Java등의 최근 PL에서는 배열 인덱스를 대괄호로 표현한다.
- 배열의 인덱스들의 집합은 일반적으로 연속적인 정수 집합을 사용하지만 반드시 정수형으로 제한되지는 않는다.
ex) Pascal, Modula-2, Ada에서는 부울형, 문자형, 열거형 등 서수형이 인덱스로 사용되는 것을 허용한다.
- 인덱스 집합이 정수형으로 이루어진 경우, Dimension(차원)별로 하한(Lb), 상한(Ub)이 존재하며, 차원 별 크기는 Ub - Lb + 1로 계산한다.
ex) C/C++, Fortran에서는 인덱스의 범위 검사를 명세할 수 없으나, Pascal, Ada, Java에서는 인덱스의 범위 검사를 명세할 수 있다.
ex) Pascal에서는 배열 인덱스 집합으로 정수가 사용될 경우, 인덱스는 반드시 한정된 영역 내의 수치를 사용해야 한다.
- 배열 인덱스의 바인딩은 보통 정적으로 이루어지지만, 동적 바인딩이 이루어지기도 하며, 일부 PL에서 인덱스 범위의 하한은 묵시적으로 고정되기도 한다.
ex) C/C++, Java에서는 모든 인덱스 범위의 하한은 0으로 고정되며, Fortran에서는 1로 고정된다.
ex) Fortran 77, Fortran 90에서는 인덱스 범위 하한의 Default는 1이다.
ex) 다른 대부분의 PL에서 인덱스 범위는 프로그래머의 의해 명세된다.
- 배열은 인덱스 범위 바인딩 방식과 기억장소 바인딩 방식에 따라 4가지 부류로 나누어진다.
| 첨자 범위 바인딩 | 기억 장소 할당 | 장점 | |
| 정적 배열 | 정적 | 정적 | 효율성 |
| 고정 스택-동적 배열 | 정적 | 동적 | 기억 장소 공간의 효율성 |
| 스택-동적 배열 | 동적 | 동적 | 고정 후 변경 불가 유연성 |
| 힙-동적 배열 | 동적 | 동적 | 고정 후 변경 가능 유연성 |
1. Static Array (정적 배열)
- 인덱스 범위는 정적 바인딩, 기억 장소도 정적으로 배당(실행시간 이전에 배당)되는 배열이다.
- 동적 기억장소 배당 및 회수가 필요하지 않아 실행시간 측면에서 효율적이다.
- 정적 배열은 정적 변수에 속한다.
2. Fixed Stack-Dynamic Array (고정 스택-동적 배열)
- 인덱스 범위는 정적 바인딩, 기억 장소는 동적으로 배당(실행시간 중 배당)되는 배열이다.
- 두 프로시저가 동시에 활성화되지 않는 상황에서, 스택에 배당되기 때문에 한 프로시저에 속한 대형 배열이 다른 프로시저에 속한 대형 배열과 동일한 기억장소 공간을 공유할 수 있어 메모리 측면에서 효율적이다.
- 고정 스택-동적 배열은 준정적 변수에 속한다.
3. Stack-Dynamic Array (스택-동적 배열)
- 인덱스 범위의 바인딩과 기억 장소 배당이 모두 동적으로 이루어지는 배열이다.
- 인덱스 범위가 바인딩되고, 기억장소가 배당된 이후에는 해당 배열 변수의 존속기간 동안 바인딩, 배당은 고정된다.
- 배열의 크기는 배열이 사용되기 직전까지 알려질 필요가 없어 유연하다.
- 스택-동적 배여른 준동적 변수에 속한다.
4. Heap-Dynamic Array (힙-동적 배열)
- 인덱스 범위의 바인딩과 기억 장소 배당이 모두 동적으로 이루어지는 배열이다.
- 힙-동적 배열은 존속기간 동안 여러 번 수정될 수 있다. (유연성)
- 힙-동적 배열은 동적 변수(힙 변수라고도 한다.)에 속한다.
ex) Fortran 77에서는 인덱스는 언어 설계 시간에 바인딩 되므로 인덱스 범위는 정적으로 바인딩 되고, 모든 기억 장소 또한 정적으로 배당된다.
ex) Pascal 프로시저와 C 함수에서 선언된 배열은 고정 스택-동적 배열이다. (C에서 static 키워드가 없다는 가정 하에)
ex) Algol 68, Ada 배열은 스택-동적 배열이다.
ex) Fortran I에서는 동적 배열을 제공한다. 인덱스 범위는 save(저장), deallocate(회수), reallocate(재배당)될 수 있다.
ex) Ada, C/C++에서도 동적 배열을 제공한다. C에서는 malloc, free, C++에서는 new, delete를 통해 힙을 배당/회수할 수 있다.
ex) C/C++에서는 인덱스 범위 검사 기능을 제공하지 않아, 배열을 늘리거나 줄이는 것이 쉽다. 배열은 메모리 셀들의 집합체에 대한 포인터로 취급되어 이 포인터로 인덱싱을 할 수 있다.
ex) Pascal에서 배열의 인덱스 범위는 데이터 형의 일부로서, 상숫값만을 허용한다.
즉, 배열의 크기를 데이터 형 정의 부분으로 고려하기 때문에, 원소들의 데이터 형이 같아도, 배열의 크기가 다르면 다른 데이터 형으로 간주하게 된다.
type asize10 = array[1..10] of integer;
type asize20 = array[1..20] of integer;
! 즉, Pascal에서는 asize10과 asize20은 다른 데이터 형 배열이다.
ex) ISO 표준 Pascal에서는 배열의 데이터 형 정의를 포함하는 형식 매개변수인 Confromant Array(적응 배열)를 제공함으로써 기존의 Pascal에서의 문제를 개선했다.
procedure SORT(var list : array [lower..upper : integer] od person);
...
var student : array[100..200] of preson;
...
SORT(student);
ex) Fortran I에서는 배열 인덱스의 개수를 3개로 제한하였다.(3차원까지만 허용) Fortran I은 3차원 배열까지는 원소들에 매우 빠르게 접근할 수 있으나, 그 이상의 차원부터는 적용되지 않았기 때문이다.
ex) C의 배열은 대괄호 하나 당 한 개의 인덱스만 가질 수 있으나, 대괄호의 개수를 늘릴 수 있는 구조를 가져서 Orthogonality(직교성)을 확보했다.
ex) C/C++, Ada 등 힙-동적 배열을 허용하는 PL에서 크기가 변화되는 배열을 생성할 때, 새 배열을 생성하여 배열 포인터에 배정하는 식으로 행해진다.
아래와 같은 Ada 코드에서
type SEQUENCE is array(INTEGER range <>) of FLOAT;
type SEQREF is access SEQUENCE;
P : SEQREF;
...
p := new SEQUENCE(M..N); -- 포인터에 메모리 할당을 미룰 수 있음SEQUENCE는 정수형 인덱스에 실수형 원소들로 이루어진 크기가 정의되지 않은(range<>) 배열이다.
SEQREF는 SEQUENCE형에 대한 포인터 형의 이름이며, P는 SEQREF형 변수이다.
new를 통해 P에 N-M+1의 크기에 해당되는 SEQUENCE 배열을 할당하고 있다.
- 다차원 배열의 각 원소는 메모리의 적당한 위치에 Mapping 되는데, 이러한 Mapping을 구현하기 위해 배열의 정보를 가진 Descriptor(명세표)를 이용한다. 명세표에는 배열 이름, 원소의 데이터 형, 원소의 길이, 배열의 시작 주소, 각 차원의 상한값, 하한값이 포함된다.
Real A (-2 : 2)
- Real Type의 1차원 배열 A
- 인덱스 하한 값 = -2, 인덱스 상한 값 = 2
- 여기서, one location은 시스템에서 Real이 차지하는 메모리 공간의 크기를 의미이다.
- 원소들이 다차원 배열에 저장되는 순서에 따라 Row-Major(행 우선), Column-Major(열 우선)으로 나뉜다.
(행 우선, 열 우선 개념 참조)
ex) Algol 68에서는 각 Row마다 다른 개수의 Column을 갖는 배열을 만들 수 있다.
[1:a] real x
[1:b] real y
[1:c] real z
w[1] := x
w[2] := y
w[3] := z- w는 1차원 포인터 집합이다. w의 원소들은 Real Type Array들을 포인팅한다.
- 즉, W[2][3]은 Y[3]이다.
Slice (슬라이스)
- 배열에서 임의의 한 차원으로 연속적인 원소들로 구성된 부분을 의미한다.
ex) PL/I에서는 *(에스테리스크)를 이용하여 *가 위치한 인덱스의 모든 부분을 선택(Slice)할 수 있다.
w(1:3, 1:5)
w(3,*) ! w의 세 번째 행을 가리킨다.
w(*, %) ! w의 다섯 번째 열을 가리킨다.
ex) Algol 68에서는 w[3, ], w[ , 5]와 같이 빈 공간으로 Slice를 표현한다.
또한, Subarray(부분 배열)에 인덱스를 사용할 수 있어, w[3, 5]를 w[ , 5][3]으로 표현할 수 있다.
그리고, 슬라이스는 다시 배열로 간주되어 인덱스화 할 수 있다. (이 배열 Segment를 식별할 수 있는 특징을 Triiming이라 부른다.)
즉, w[3,2], w[3,3], w[3,4]를 w[3, 2 : 4]로 표현할 수 있다.
그리고, 사용자 정의 열거형이 허용되지 않으므로, 인덱스로 정수만을 허용한다.
ex) APL에서는 w[3 ; ], w[ ; 5]와 같이 세미 콜론을 통해 Slice를 표현한다.
ex) PL/I에서는 부분 배열에 대해 인덱스를 허용하지 않아, 배열 슬라이스를 값으로 가질 수는 있으나 슬라이스를 인덱스화 할 수는 없다.
ex) Fortran, Algol 60에서는 배열의 원소에 대한 연산만 허용하며, 배열 자체에 대한 연산을 허용하지 않는다.
ex) APL, PL/I, Algol 68에서는 A←B, A=B, A:=B와 같은 배열 배정 연산을 허용한다. (두 배열의 크기는 같아야 한다.)
- 몇몇 PL에서는 배열의 기억장소가 배당되는 시간에 해당 배열을 초기화할 수 있게 한다. 이는 컴파일러가 초깃값을 통해 배열의 크기를 설정할 수 있게한다. 편리하지만, 값을 빠뜨리는 실수로 인해 오류를 시스템이 탐지할 수 없게 한다.
ex) Fortran 77에서는 모든 데이터 기억장소는 정적으로 배당되므로, DATA문을 이용하여 적재시간 초기화를 허용한다.
INTEGER X (3)
DATA X /0, 2, 7/ex) C/C++에서는 문자열을 char 배열로 구현하며, 아래와 같이 선언과 동시에 초기화 할 수 있다.
모든 문자열은 널 문자로 끝나므로, 시스템은 문자열 상수에 널 문자를 묵시적으로 삽입한다.
char name[] = "Hong kildong";ex) Pascal, Modula-2는 프로그램 선언부에서 배열 초기화를 허용하지 않는다.
ex) Ada에서는 배열의 초기화에 여러 기능을 제공한다.
type MAT is array(INTEGER range 1..2, INTEGER range 1..2) of REAL;
A : MAT := ((10, 20), (30, 40));
! A에 Row-Major 방식으로 원소를 배정한다.
B : MAT := (1 ⇒ (1 ⇒ 10, 2 ⇒ 20), 2 ⇒ (1 ⇒ 30, 2 ⇒ 40));
! 인덱스를 사용하여 원소를 배정한다.
A : MAT := (1 ⇒ (1 ⇒ 1, others ⇒ 0), 2 ⇒ (2 ⇒ 1, others ⇒ 0));
! others를 통해 나머지 인덱스를 임의의 값으로 한꺼번에 배정한다.
배열 설계 시 고려사항
1) 배열 이름과 배열 원소에 대한 구문
2) 원소값에 대하여 어떤 데이터형이 사용되는가
3) 인덱스로 어떤 데이터 형을 사용할 수 있는가
4) 배열의 크기는 바인딩 되는가
5) 인덱스 범위는 언제 바인딩 되는가
6) 어떤 형태의 슬라이스를 제공하는가
7) 배열을 초기화시키기 위해 어떤 종류의 문장이 허용되는가
8) 배열에 대한 내장된 연산은 어떤 종류가 허용되는가
9) 원소 참조를 표현하는 인덱스 식의 범위를 검사할 수 있는가
7.5 Associative Array (연상배열)
- Index가 아닌, Key 값에 의해 접근되며, 순서를 갖지 않은 원소들의 집합체를 의미한다.
- 연상 배열의 원소들은 Key-Value 형식의 하나의 Pair로 저장된다.
- 연상 배열 설계 시 고려사항으로는 원소의 참조 형식, 연상 배열 크기의 바인딩 시간이 있다.
ex) Perl Hash에 대한 배정문
# Perl의 Hash 변수 이름은 "%"로 시작한다.
%salaries = ( "HONG" => 1200000, "Won" => 2000000,
"Kim" => 1500000, "Lee" => 2500000);
# Perl Hash에서 각 원소의 값을 참조할 경우, 변수 이름은 "$"으로 시작되고,
# Key 값은 중괄호로 표현되며,
# 나머지는 동일한 스칼라 변수 이름으로 치환된다.
$salaries {"Won"} = 2500000;
# delete 연산자를 통해 원소를 해시에서 삭제할 수 있다.
delete $salaries {"Lee"};
# Hash 전체에 Empty Literal을 배정하여 Empty Hash를 생성할 수 있다.
@salaries = ();
# exists 연산자를 통해 해당 Key가 Hash의 원소인지를 T/F로 리턴받을 수 있다.
if (exists $salaries {"Hong"})
- Perl에서의 연상 배열은 원소들이 해시 함수를 통해 저장/추출된다.
- Perl의 연상 배열을 Hash라 부르기도 한다.
- Perl Hash의 크기는 동적으로 관리되어, 새 원소가 추가되면 커지고, 원소가 삭제되면 크기가 줄어든다. (고비용)
- 묵시적 Hash 연산이 효율적이라, 원소들에 대한 탐색에서 Array보다 Hash 구조가 더 효율적이다.
- List의 모든 원소를 처리하는 경우, Hash보다 Array 구조가 더 효율적이다.
- keys 연산자: Hash에 포함된 Key들로 구성된 배열을 리턴한다.
- values 연산자: Hash에 포함된 Value들로 구성된 배열을 리턴한다.
- each 연산자: Hash의 원소 pairs들에 대한 Iteration을 수행한다.
7.6 Record Type (레코드)
- Heterogeneous Data(이질형 데이터)로 구성된 조직적 데이터 형이다.
ex) 보편적인 Record Type 정의 (Pseudo Code)
type stock =
record
name : array[1..30] of char;
price : array[1..365] of real;
dividend : real;
volume : array[1..365] of integer;
exchange : (nyse, amex, nasdaq) ! Enumerate Type
end;
var newstock, ibm : stock;
ex) Cobol에서의 Record Type을 structure라 부르며, 이는 최초의 Record Type이다.
ex) PL/1은 Cobol의 형태를 따른 Record Type을 정의해놓았다.
ex) Pascal은 Record Type을 record 부르며, record에 대한 EBNF 표기는 아래와 같다.
<record-type> ::= record <field-list> end
<field-list> ::= <fixed-part> [; <variant-part>] | <variant-part>
<fixed-part> ::= <record-section {; <record-section>}
<record-section> ::= {<identifier-list> : <type>}- 각 <record-section>은 식별자*와 그에 대한 데이터 형이 pair를 이루어 하나 이상의 List로 기술된다.
* Field Designator(필드 지정자)
- 위와 같이, 데이터 형과 대응되는 식별자를 의미한다.
- 필드 지정자의 Scope는 해당 레코드에 한정되므로, 각 필드는 서로 구분되어야 한다.
ex) Algol 68에서의 Record 선언 및 초기화
- Algol-W, Ada 또한 이러한 초기화 기능이 Built-In 되어있다.
var ibm, csc : stock; # stock record 형 변수 ibm, csc 선언 #
# ibm, csc에 대한 초기화 #
ibm := make-stock('IBM', 0..0, 5.25, 0..0, nyse);
csc := make-stock('Computer Science Corp.', 0..0, 0, 0..0, nyse);
ex) Ada에서는 Record의 원소들에 모든 데이터 형이 허용된다.
type FLIGHT; -- Forward Reference
type LISTOFFLIGHTS is access FLIGHT;
type FLIGHT is
record
FLIGHTNO : INTEGER range 0..100;
SOURCE : STRING;
DESTINATION : STRING;
RETURNFLIGHT : LISTOFFLIGHTS;
end record;
-- X, Y가 LISTOFFLIGHTS형 변수라면,
-- 아래와 같이 FLIGHT를 포인팅하는 포인터 멤버도 가질 수 있다.
X.RETURNFLIGHT := Y; Record에서 각 Field를 참조하는 두 가지 방법 (Functional, Dotted)
1. Functional Notation (Knuth가 제안한 방법)
- 각 필드를 Field(Record_Name)처럼 함수처럼 표기하는 방식을 의미한다.
ex) name(ibm), price(ibm)[25], dividend(ibm), volume(ibm)[25], exchange(ibm)
ex) Algol 68은 Functional Notation에 가까운 표기법을 사용한다.
mode stock = struct string name, int dividend, int exchange)
name of ibm # name(ibm)에 해당된다. #
exchange of ibm # exchange(ibm)에 해당된다. #
2. Dotted Notation
- "."(Dot; 온점)을 이용하여 변수 이름과 Field 이름을 분리하는 방식을 의미한다.
ex) ibm.name, ibm.price[25], ibm.dividend, ibm.volum[25], ibm.exchange
ex) Pascal, Ada는 Dotted Notation을 사용한다.
ex) Pascal의 with문
- 필드 이름 앞에 변수 이름을 생략할 수 있게 한다.
- Programmability를 제고한다.
// with문 없이, 필드 이름에 변수 이름을 계속 붙이는 형식
newstock.name := "dec";
newstock.dividend := 36;
newstock.exchange := amex;
// with문을 통해, 변수 이름을 한 번만 명시하는 형식
with newstock do
begin
name := "dec";
dividend := 36;
exchange := amex
end;Variant-Part(가변부)를 갖는 Record Type
- 가변 레코드는 데이터 형을 Union(합성)하기 위한 기법이다.
- Variant-Type을 가진 레코드 형에서는 데이터 형에 따른 택일 변환들이 기술된다.
- 각각의 변환은 Discriminant(판별자)의 특정값에 따라 하정된 구성 요소들로 이루어진다.
- 이러한 변환을 몇몇 PL에서는 case문을 사용하여 표현한다.
ex) Pascal에서의 가변 레코드에 대한 EBNF 표기
<variant-part> ::= case <tag-field> <type-identifier> of <variant> { ; <variant>}
<tag-field> ::= [ <identifier> :]
<variant> ::= [ <case-label-list> : (<field-list>) ]
ex) Ada에서의 가변 레코드에 대한 EBNF 표기
<variant-part> ::= case <discriminant-name> is {when <choice> { | <choice> | ⇒ <component-list> }
end case
<choice> ::= <simple-expression> | <discrete-range> | others
ex) Pascal에서의 가변 레코드 구성 예시
type option = (sixmonths, ninemonths);
case x : option of
sixmonths : (exprice : real)
ninemonths : (nuprice : integer)
end
// x값이 sixmonths -> stock의 exprice 필드에 접근 가능
// x값이 ninemonths -> stock의 nuprice 필드에 접근 가능
ex) Pascal에서의 일반화된 리스트 구성 예시
// 리스트의 원소들은 atoms이거나 sublist이다.
// 레코드에 대한 정의는 가변부를 포함하고 있는 형태이다.
type listptr = ↑listnode;
type listnode =
record
link : listptr;
case tag : boolean of // 가변부
false : (data, char); // 가변부
true : (downlink : listptr) // 가변부
end;
var p, q : listptr;
// p↑.tag = false이면, p↑.data가 존재하며, char 형을 띄게 된다.
p↑.tag := true;
p↑.downlink := q;
p↑.tag := false;
writeln (p↑.data);
// 위와 같이, 가변 레코드의 필드 값이 수시로 변할 수 있어,
// 컴파일 시간이 아닌, 실행 시간에 확정되어야 한다.
// Pascal과 같은 가변부의 사용은 심각한 오류를 발생시킬 수 있다.
ex) Euclid에서는 매개변수화딘 변수형을 허용하여 tag가 선언에서 형식 매개변수로 취급될 수 있다.
// 기존에 Euclid에서 데이터 형 값을 검색하는 방법
// Discriminant를 이용한 case 문장은 레커도의 어느 변환부가 사용되고 있는지를,
// 실행 시간에 검사하는 것이 가능하다.
case dixcriminating w = z on tag of
true ⇒ x := w; end
false ⇒ y := w; end
end case
var x : listnode (true)
var y : listnode (false)
var z : listnode (any)
// Euclid에서는 tag 필드가 일단 초기화 되면 어떠한 배정도 불가능하다.
// any 키워드를 통해 z가 true 혹은 false값 중 하나로 추후에 선택되도록 할 수 있다.ex) Ada에서도 Euclid와 유사한 방법으로 가변 레코드의 문제를 해결했다. (any 키워드를 사용하지는 않는다.)
7.7 Pointer Data Types (포인터 자료형)
- Pointer(포인터): 어떤 객체에 대한 참조를 의미한다.
- Pointer Variable(포인터 변수): 객체를 참조하기 위한 주소를 값으로 취하는 식별자를 의미한다.
포인터의 필요성
- 실행시까지 생성될 항목 개수가 정해지지 않는 문제를, 객체에 명시적인 이름을 제공하지 않고,
많은 항목을 동적으로 연결하는 방법을 통해 해결하기 위해 포인터 개념이 필요하다.
- 포인터는 하나의 데이터가 다수의 리스트에 동시에 연결되는 것을 허용하여,
데이터 항목 간, Multiple Relationship(다중 관계)를 생성하기 용이하게 한다.
- 포인터 형은 배열, 레코드와 같은 구조형에 속하지 않으며,
데이터를 저장하는 것이 아닌 다른 객체를 참조하는 데이터 형이기 때문에 스칼라 형은 또한 아니다.
- 전반적으로, 포인터는 프로그램 작성력을 향상시킨다.
ex) FORTRAN 77에서는 포인터 개념이 없어, Binary Tree와 같은 동적 구조체를 표현하기가 까다롭다.
- Heap(힙): 동적으로 객체가 배당되는 기억장소 영역을 의미한다.
- Heap Variable(힙 변수): 힙 영역에 배당되는 변수를 의미한다.
- 특히, 힙에서 생성되어 식별자 없이 포인터, 참조형 변수에 의해 참조되어야 하는 변수를
Anonymous Variable(무명 변수)라 부른다.
- Pointer Type(포인터형)은 메모리 위치를 곧 바로 가리키는 데이터 형이며,
Reference Type(참조형)은 객체 자체를 가리키는 데이터 형을 의미한다.
- 포인터에는 일부 산술 연산이 가능한 경우가 있지만,
참조형에 대한 산술 연산은 의미가 없어 오류 발생 가능성을 줄인다.
- 대부분의 PL에서 포인터 값(주솟값)과 포인터가 가리키는 값에 대한 구분이 전적으로 프로그래머에게 달려있어
오류 발생의 소지가 있으나, 참조형에는 이러한 위험성이 없다.
ex) C/C++에서의 포인터 형 연산자: *
ex) Ada에서의 포인터 형 연산자: access
ex) Pascal에서의 포인터 형 연산자: ↑
ex) 레코드에 대한 포인터가 필드를 참조하는 방식
C/C++: P->age 혹은 (*P).age
Pascal: P↑.age
Ada: P.age
Pointer Type 제공 시, 발생할 수 있는 문제점
1. 다수의 포인터 변수가 동일한 객체를 가리키고 있을 때(이명), 이를 인지하지 못한 프로그래머가
해당 객체를 수정/소멸시켜 내용을 변경시키는 등의 논리적 오류를 초래할 수 있다.
2. 무명 객체가 포인터의 포인팅을 받지 못하면(Garbage) 해당 메모리에 접근할 방법이 없어, Memory Leak(메모리 누수)가 발생할 수 있다.
3. 일반적인 변수들은 L-Value, R-Value를 나타내는 데 반해,
포인터 변수는 L-Value, R-Value외에 가리키고 있는 객체의 값 까지 추가적으로 표현할 수 있어야 한다.
4. Dangling Reference(허상 참조) 문제
※ Dangling Reference(허상 참조)
- 포인터 변수가 의미없는 것을 가리키고 있는 현상을 의미한다.
- 포인터 변수의 Lifetime이 프로그래머의 동적 할당/반환에 귀속되어 있을 때, 허상 참조가 발생할 수 있다.
(즉, 제 때 반환하지 않으면, 허상 참조가 발생할 수 있는 것이다.)
ex) Algol 68에서는 포인터 변수의 Lifetime이 가리키는 객체와 일치되어 허상 참조가 발생할 수 없는 구조이다.
Pointer Type 설계 시, 고려사항
1. 포인터 변수의 Scope와 Duration은 얼마인가.
2. 힙 변수의 Duration은 얼마인가.
3. 포인터가 가리키고자 하는 객체의 데이터 형에 제한을 받는가.
4. 포인터가 동적 메모리 관리, 간접 주소 지정에 사용 가능한가.
5. PL이 포인터형, 참조형 둘 다 지원 하는가.
포인터 배정과 Dereferencing(역참조)
- 포인터형을 제공하는 PL은 일반적으로 포인터 배정 연산과 Dereferencing 기능을 제공한다.
- 포인터 배정: 포인터 변수의 값에 유효한 주소를 설정하는 연산이다.
- 역참조:
- 포인터 변수의 두 가지 해석방법
1. 포인터 변수를 해당 포인터가 바인딩 되어 있는 값에 대한 참조로 해석하는 방법
(일반 변수의 해석방법과 같다.)
2. 포인터 변수를 해당 포인터가 가리키는 메모리에 저장된 참조로 해석하는 방법
(해당 포인터를 역참조하는 것으로 해석하는 방법)
Pascal, Ada에서의 포인터
ex) 초기 Pascal에서의 포인터는 레코드형 객체만을 가리키는 것으로 제한되었다.
ex) Pascal에서의 포인터형 선언
type nodeptr = ↑node;
node = record
number : real;
net : nodeptr
end
// nodeptr의 정의에서 node가 정의되기도 전에 나타날 수 있는 것은
// Pascal의 원칙인 Forward Reference(전위 참조)의 몇 안되는 예외사항이기 때문이다.
var x, y : nodeptr
// 포인터 변수 x, y의 선언
x
// node형 객체를 가리키는 nodeptr 형의 포인터 변수
x↑
// node형 객체를 나타내며, new(x)로 생성된다.
x↑.number
// x가 가리키고 있는 노드의 실수 부분(필드값)
x↑.next
// x가 가리키고 있는 노드의 포인터 부분(필드값)
var P, Q : nodeptr;
...
new(P);
P↑.number := 3.54;
P↑.next := nil;
ex) Pascal에서 포인터 변수에 정의된 연산: Assignment(배정), Equality(동등 연산), Dereference(역참조)
ex) Pascal에서의 메모리 동적 할당/반환: new(x), dispose(x)
ex) Pascal에서 null은 nil로 표현된다.
ex) Ada에서의 포인터형 선언
type NODE
type NODEPTR is access NODE
type Node is
record
NUMBER : REAL;
NEXT : NODEPTR;
end record;
P, Q : NODEPTR := new NODE(3.54, null)
P.NEXT := Q.NEXT;
P.NUMBER = Q.NUMBER;
-- Q가 가리키는 객체를 P도 가리키게 일일히 대입하는 방법
P.all := Q.all;
-- all 지정자를 통해 모든 필드를 선택하는 방법
| PL | 포인터 배정 | 값 배정 | 필드 지정 | 생성 |
| Pascal | p := q | p↑ := q↑ | p↑. 필드명 | new(p); |
| Ada | p := q | p.all := q.all | p.필드명 | p := new 데이터 형 [:= 초기값] ; |
C와 C++에서의 포인터
- 주소가 어셈블리 언어에서 사용되는 것 처럼 사용된다. (유연성)
- 허상 참조, 분실된 동적-변수 문제가 발생할 수 있으며, 해결책이 제시되지 않고 있다.
- 포인터 산술 연산이 가능하다.
- 메모리에 있는 거의 모든 변수를 포인팅할 수 있다.
- "*"로 역참조 연산을 수행하고, "&"를 주소 연산자로 사용한다.
- C/C++에서 배열 이름은 그 자체로 상수 포인터이다. (즉, 배열 이름에 어떤 주솟값을 대입하기가 불가능하다.)
- void* 형을 통해 데이터 형이 중요하지 않고, 메모리 공간을 주고 받을 때 유용하게 사용할 수 있다.
7.8 Type Conversion (자료형 변환)
- 시스템에서 Type Specific Op(형 고정 연산)을 지원하는 경우에 generic Op(혼합형 연산)을 사용하고자 하는 경우,
식에 사용된 데이터 형의 Type Conversion(형 변환)이 필요하게 된다.
- 일반적인 PL에서는 스칼라형 사이의 형 변환을 제공하며,
구조 자료형이나, 사용자 정의형 사이에서의 형 변환은 지원하기 어렵다.
- 형변환은 Implicit Type Conversion(묵시적 형 변환)과 Explicit Type Conversion(명식적 형 변환)으로 나뉜다.
Implicit Type Conversion(묵시적 형 변환) = Automatic Conversion(자동변환) = Coercion(강요변환)
- 시스템에서 자동으로 수행하는 형 변환이다.
Explicit Type Conversion(명시적 형 변환) = Type Cast(타입 캐스트)
- 프로그래머가 명시하는 형 변환이다.
ex) PL/I에서는 Built-In 데이터형들 사이에 무조건적인 묵시적 형 변환을 제공한다.
문자형에서 실수형, 실수형에서 정수형, 비트형에서 문자형 변환 등이 가능하다.
Widening(확대 변환)
- Domain(정의역)에 있는 모든 값들이 Range(치역)에 그대로 대응되는 형 변환이다.
- 정의역이 치역보다 넓어 데이터의 손실이 발생되지 않는다.
ex) 정수형에서 실수형으로의 변환 시, 정수형의 범위가 실수형의 가수 범위 보다 클 때 확대 변환이 일어나는 것이다.
(그렇지 않으면, 정밀도를 잃어버리게 된다.)
Narrowing(축소 변환)
- 정의역에 있는 어떤 값이 치역의 한 값에 대응할 수 없는 형 변환이다.
- 데이터의 손실이 발생될 수 있다.
ex) PL/I에서는 실수형에서 정수형으로 변환할 경우, Truncation(버림)한다.
ex) Pascal에서는 정수형에서 실수형으로의 확대변환과 subrange(부분 영역)들 사이의 확대/축소 변환만을 지원한다.
ex) C/C++, Java에서는 확대 변환에는 자동 변환이 허용되며, 축소 변환은 캐스트 명령을 이용해야 한다.
7.9 자료형 동치
ex) Pascal 코드
type T = array[1..100] of integer;
var x, y : array[1..100] of integer;
z : array[1..100] of integer;
w : T;
v : T;- 위 코드에서 변수 v, w, x, y, z를 동일한 데이터 형으로 해석하는가 아닌가에 대한 두 가지 방법이 있다.
1. Name Equivalence (이름 동치)
- 두 변수를 함께 선언하거나 같은 데이터 형 식별자를 사용하여 선언했다면,
두 변수는 동일 데이터형으로 인식되며, 반대의 경우도 성립한다.
- 이름 동치는 Ada와 같은 언어가 따른다.
ex) 위 코드에서 x, y는 동치, v, w도 동치이나, w와 x와 z는 서로 다른 데이터 형으로 취급한다.
2. Structural Equivalence (구조적 동치)
- 데이터 형의 Component(구성요소)가 모든 측면에서 같다면,
두 변수는 동일 데이터형으로 인식되며, 반대의 경우도 성립한다.
- 구조적 동치는 Algol 60, Algol 68, Fortran, Cobol 등 대부분의 PL이 따른다.
ex) 위 코드에서 v, w, x, y, z는 모두 동일 데이터 형으로 취급한다.
ex) Pascal 선언 구문
type T1 = T2;
// T2는 미리 정의되었다 가정하자.
// 이름 동치를 따르면, T1과 T2를 서로 다른 데이터 형으로 간주한다.
// 구조적 동치를 따르면, T1과 T2를 동치인 것으로 간주한다.
// 또한, T1과 T2는 선언 동치이기도 하다.
array[1..100] of real;
array[1..10, 1..10] of real;
// 위 문장은 구조적 동치를 따르더라도 서로 다른 데이터 형으로 간주하게 된다.
3. Declaration Equivalence (선언 동치)
- 이름 동치 개념에 추가해서 재선언을 하여 원래의 구조를 그대로 사용하는 경우에도
원본 데이터 형과 동치로 간주하는 방법이다.
- 이름 동치와 구조적 동치의 중간 개념에 해당된다.
ex) Pascal 선언 구문
type T1 = array[1..100] of integer;
type T2 = array[1..100] of integer;
type T3 = T2;
// 이름 동치에서는 T1, T2, T3를 모두 다른 데이터형으로 간주한다.
// 구조적 동치에서는 T1, T2, T3를 모두 같은 데이터형으로 간주한다.
// 선언 동치에서는 T2, T3만 서로 같은 데이터형으로 간주한다.
* {구조 동치 동등 데이터 형} ⊃ {선언 동치 동등 데이터 형} ⊃ {이름 동치 동등 데이터 형}
Type Compatibility (데이터 형 적법성)
- 객체의 데이터 형이 특정 Context(문맥)에서 정당한 지를 결정하는 Semantic Rules(의미 규칙)을 의미한다.
- 사용된 구성자들의 데이터 형이 동치이어야 함을 완화시켜야 할 때 사용되는 개념이다.
ex) "if x = y then ..."의 동등 연산에서 적법성은 단순히 동일 데이터형으로 간주하여 만족시킬 수 있다.
ex) "v := e"에서 v와 e가 동일 데이터 형이라면 적법성은 만족시킨다.
(단 여기서, v는 L-Value이고, e는 R-Value이기 때문에 큰 차이를 갖는데, 이를 대부분의 PL에서는 Dereferencing을 통해 해결한다.)
ex) Pascal에서는 모든 부분 영역형을 새로운 데이터 형으로 간주하여, 이들의 모든 경계가 컴파일 시간에 정해진다.
ex) [1..100]과 [-10..10]은 서로 다른 데이터 형이며, [1..10]의 경우 두 영역형에 모두 포함되어
[1..10] 데이터 형이 Overlap(중첩)되었다 표현한다.
ex) Ada에서는 Pascal의 부분 영역형 선언을 subtype을 통해 표현하고, 부분 영역형을 새로운 데이터 형으로 간주하는 선언을 Derived Type(파생 데이터 형)이라한다.
subtype ainteger is INTEGER range 1..100; -- Subtype
type binteger is new INTEGER range 1..100; -- Derived Type