
ER Model
ER 모델
- 실세계 조직체에 대한 데이터를 객체들과 그들간의 관계를 통해 Abstraction하여 묘사하는 모델이다.
- E-R 모델을 이용하여 View(External Schema)를 만드는 것이 DB를 구축하기 위한 첫 번째 과정이다.
- E-R 모델을 이용하여 표현된 Schema는 그림으로 표현이 가능하기 때문에, E-R 모델을 E-R Diagram이라 부르기도 한다.
- E-R 다이어그램은 Logical Schema Design 과정에서 용이하게 사용되고, Relational Schema로 대응이 가능하다.
DB Design Process (DB 설계 절차)
1. Requirement Analysis (요구분석)
- DB에 무슨 정보를 저장할지, 어떤 Application을 구축할지, 빈번히 사용될 연산은 무엇인지, 요구 성능은 어느 정도인지를 파악하는 단계이다.
- 즉, 사용자들이 DB로부터 원하는 바를 찾아내는 단계이다.
2. Conceptual DB Design (개념적 DB 설계)
- 이 단계에서는 DBMS가 필요하지 않다. 이 단계에서는 E-R Model을 사용한다.
- 실세계의 개념을 추상화하여 표현하는 단계이다.
- 여러 개체, 관계 중에서 어떤 정보를 DB로 구성할 지를 정하는 단계이다.
- Integrity Constraint(무결성 제약), Business Rule을 정하는 단계이다.
3. Logicla DB Design (논리적 DB 설계)
- 설계한 DB를 구현하기 위해 DBMS를 선정하는 단계이다.
- 또한, 선정한 DBMS의 데이터 모델에 맞춰서, 개념적 DB 설계를 DB Schema로 변환한다.
4. Schema Refinement (스키마 정제)
- 관계형 DB의 릴레이션들을 분석하여 잠재적인 문제점을 파악하고, 정제하는 과정이다.
5. Physical DB Design (물리적 DB 설계)
- DB에게 요구되는 성능기준을 충족하기 위해 더욱 정제하는 과정이다.
- 몇 개의 테이블에 인덱스를 구축하고, 몇 개의 테이블을 클러스터링할 지를 선택하는 등의 결정이 이 단계에 해당될 수 있다.
6. Application and Security Design (응용 및 보안설계)
- 각 역할별로, 접근되어야 하는 DB 영역과 접근이 제한되어야 하는 DB 영역을 파악하고,
이러한 Access Rule들이 지켜지기 위한 환경을 구축하는 단계이다.
E-R Model Basics (E-R 모델의 기본개념)
Entity (개체)
- 실세계에 존재하는 것이다.
- 개체는 다른 개체와 구별이 가능해야 한다.
- DB내에서 각각의 Entity는 Attribute의 집합으로 구성된다.
- Attribute는 E-R Diagram에서 원으로 표현된다.
- 각각의 Attributte는 Domain이 정의되어 있다.
(Domain = Data Type)
Entity Set (개체집합)
- E-R Diagram에서 직사각형으로 표현된다.
- 개체들로 구성된 집합이다.
- Key 역할을 하는 Attribute는 밑줄을 그어 표시한다.
- Key 역할을 할 수 있는 Attribute들을 Candidate라 부르고,
다수의 Candidate가 존재할 경우, 그 중 하나를 Primary Key로 지정한다.
- 개체집합 내에 모든 개체들은 같은 Attribute Set을 갖고 있다.
Attribute (속성)
| 범 주 | ||
| 의미상에서의 분류 | * 기본 속성 - 개체를 실제로 구성하는 속성이다. |
* 설계 속성 - 데이터 모델링 혹은 규칙의 구현을 위해 설계자가 인위적으로 개체에 부여한 속성이다. (시리얼번호 등) |
| 세분화 여부에 따른 분류 | * 단순 속성 - 의미상으로 더 이상 쪼갤 수 없는 속성이다. (나이 등) |
* 복합 속성 - 더욱 세부적으로 나눌 수 있는 속성이다. (주소, 생년월일 등) |
| 속성 값의 개수에 따른 분류 | * 단일 속성 - 한 개체에 대해, 속성 값이 단 하나로 존재하는 속성이다. (주민등록번호 등) |
* 다중 속성 - 한 개체에 대해, 속성 값이 동시에 다수로 존재할 수 있는 속성이다. (전화번호 등) |
| * 유도 속성 - 다른 속성을 통해 계산되는 속성이다. - 다른 속성에 의존적이므로, 설계 시 지양한다. |
Relationship (관계)
- 둘 이상의 개체들 간의 관련성이다.
- Entity Set간의 관계를 나타낸다.
- 관계에도 Attribute가 존재할 수 있으며, 이를 Relationship Attribute라 한다.
- 하나의 Entity Set 내에서의 Relationship을 Unary Relationship이라 부른다.
- 두 개의 Entity Set 사이의 Relationship을 Binary Relationship이라 부른다.
- 세 개의 Entity Set 사이의 Relationship을 Ternary Relationship이라 부른다.
Relationship Set (관계집합)
- E-R Diagram에서 마름모로 표현된다.
- 관계집합은 개체와, 개체가 속한 개체집합 쌍으로 구성된 n개의 Tuple로 구성된다.
- 관계집합은 Descriptive Attribute*를 가질 수 있다.
* Descriptive Attribute
- 한 개체에 관한 정보보다는, 관계에 관한 정보를 기술하는 속성이다.
Types of Relationship (관계의 형태)

- 특히, 1 to 1 관계는 E-R Diagram에서 실선이 아닌, 화살표로 표현된다.
Example

- "Departments" 개체집합에서 "Manages" 관계집합으로의 관계가 화살표로 표현되어 있다.
(즉, 부서에서 직원들을 관리하는 사람은 한 명이라는 의미이다.)
- 즉, 전체적으로 1 to Many 관계임을 화살표를 통해 알 수 있다.
("Employees" 개체 집합에서는 다수의 "Departments" 개체를 선택할 수 있으나,
"Departments" 개체 집합에서는 단 하나의 "Employees" 개체만 선택할 수 있기 때문이다.)
Example. 관계의 형태에 따른 테이블 구조
1) 1 to 1 Relationship

2) 1 to Many Relationship

3) M to N Relationship

- 특히, M : N 관계 테이블에서 별도로 생성되는 Relation을 교차 릴레이션 혹은 교차 엔티티라고 부른다.
4) ERD - Table

Role Indicator (역할 지시자)
- Unary Relationship에서 한 개체 집합이 여러 역할을 수행할 때, 역할 지시자는 관계집합의 속성과 해당 개체집합의 속성을 결합하여 관계집합의 애트리뷰트를 유일한 상태로 유지시킨다.
Example.

- 역할 지시자인 "supervisor"와 "subordinate"는 개체집합 "Employees"의 Key인 "ssn"과 결합되어,
각각, "supervisor_ssn"과 "subordinate_ssn"의 형태로 관계집합 "Reports_To"의 속성으로 구성된다.
Additional Features of the E-R Model (E-R 모델의 특별 기능)
Key Constraints (키 제약조건)
- E-R Diagram에서 키 제약조건은 화살표로 표시된다.
- Key로 지정된 Attribute에 중복된 값을 불허하는 조건이다.
- 즉, 1 to 1 관계를 나타내는 조건이다.
Participation Constraints (참여 제약조건)
- E-R Diagram 상에서, 굵은 실선은 Total Participation(완전 참여)을 의미하고,
얇은 실선은 Partial Participation(부분 참여)를 의미한다.
- 완전 참여는 해당 개체집합에 속한 모든 개체가 관계를 맺고 있음을 의미한다.
- 부분 참여는 해당 개체집합의 개체 중 일부만 관계를 맺고 있음을 의미한다.
Example.

- 모든 직원은 부서에 근무한다. (굵은 실선)
- 모든 부서는 직원이 있다. (굵은 실선)
- 일부 직원은 부서를 관리한다. (얇은 실선 )
- 모든 부서는 반드시 1명의 관리자를 갖는다. (굵은 실선, 화살표)
Weak Entity (약개체)
- E-R Diagram에서 약개체는 굵은 실선(혹은, 이중 실선)으로 표현된다.
- 다른 개체와 관계되어야 존재할 수 있는, 불완전한 개체를 의미한다.
(개체의 조건 중 하나는 실세계에 존재해야 한다는 것이다.)
- 약개체의 Key는 단독적인 Key로 인정되지 않으며, 이를 Partial Key(부분키)라 부르고,
약개체를 소유한 강개체의 Key와 함께 조합되어 사용된다.
(DB에서 인정받는 약개체의 Key = 강개체의 Key + 약개체의 Partial Key)
- Partial Key는 E-R Diagram 상에서파선밑줄이 그어져 표현된다.
- 약개체의 반대 개념인, Strong Entity(강개체)는 일반적인 개체를 의미하며, 자체적으로 존재할 수 있는 개체이다.
- 강개체(소유자 객체)와 약개체 사이는 1 to Many 관계를 이룬다.
- 약개체는 강개체에 대해 반드시 완전참여의 형태로 관계되어야 한다.
- 강개체와 약개체를 잇는 관계집합을 Identifying Relation Set(식별 관계집합)이라 한다.
- 식별 관계집합 또한, E-R Diagram 상에서 굵은 실선(혹은, 이중 실선)으로 표현된다.
Example.
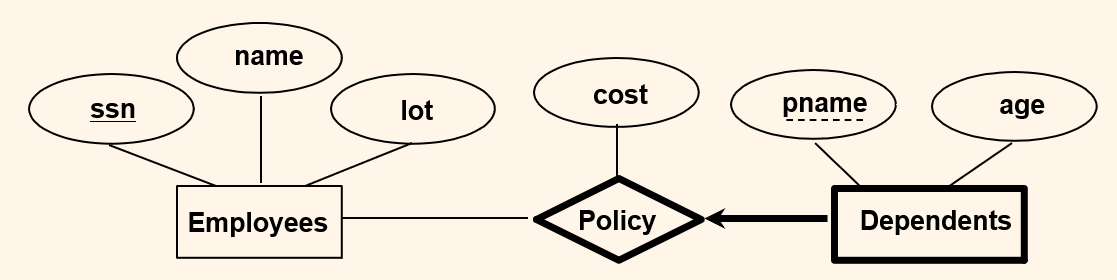
- "Dependents"(부양가족) 개체집합은 "Employees" 개체집합 없이는 의미를 갖지 못한다.
- "Dependents"는 약개체이므로, "Employees"의 Key인 "ssn"과 "pname" Attribute(Partial Key)를 조합하여 Key로 사용한다.
- 각각의 부양가족의 보험(Policy)은 반드시 한 명의 직원에 의해 계약된다. (굵은 실선, 화살표)
- 반대로, 직원은 다수의 부양가족을 가질 수 있으며, 아예 가지지 않았을 수도 있다. (얇은 실선)
Class Hierarchy (클래스 계층)
- ISA 관계를 E-R Diagram상에서 표현할 때 이용한다.
- Subclass(Sub-Node)가 Supeclass(Super-Node)의 Attribute를 Inheritance 받는 형태를 E-R Diagram상에서 표현할 수 있다.
- 한 개체집합과, 그 개체집합의 모든 Attribute를 그대로 정의하면서,
자신만의 Attribute를 구성해야 하는 개체집합이 있는 경우, 이를 Multi-Level의 Subclass로 구현하는것이 바람직하다.
- "Employee" 개체집합을 상속받는 "Hourly_Emps" 개체집합 사이의 관계를
"Hourly_Emps ISA Employee"라 표현한다.
- Superclass는 다수의 Subclass로 Specialization(특수화)*된다.
- 하나의 Subclass는 하나의 Superclass로 Generalization(일반화)*된다.
- ISA Hierarchy에는 Overlap Constraints(중첩 제약조건)*와 Covering Constraints(포괄 제약조건)*를 정의할 수 있다.
* Specialization (특수화)
- 어떤 Superclass 개체집합의 모든 Attribute를 Inherit(상속)받고, 여기에 몇 개의 Attribute를 추가하는 과정을 의미한다.
- 일반적으로, Superclass가 먼저 정의되고, Subclass가 다음으로 정의되며,
Subclass 고유의 Attribute들과 관계집합들이 그 다음으로 정의된다.
* Generalization (일반화)
- 여러 개체집합들 사이에서 공통되는 Attribute를 찾고, 공통된 Attribute만으로 구성된 개체집합을 생성하는 과정을 의미한다.
- 일반적으로, Subclass가 먼저 정의되고, Superclass가 다음으로 정의되며,
Superclass를 포함하는 관계집합이 있다면, 그 다음에 정의된다.
* Overlap Constraints (중첩 제약조건)
- 두 subclass가 같은 개체를 포함하는 것을 허용할지에 대한 조건이다.
- 바꿔 말하면, 한 객체가 두 개 이상의 Subclass에 속할 수 있는지에 대한 조건이다.
- 중첩이 허용됐다 할지라도, 한 객체는 한 시에 하나의 Subclass에 속하는 것이며, "동시에" 여러 Subclass에 속하는 것은 아니다.
- 중첩 제약조건이 따로 명시되지 않은 경우, 기본적으로 각각의 개체집합들에 대한 중첩이 허용되지 않는다고 간주한다.
ex) "Hourly_Emps" 개체이면서, 동시에 "Contract_Emps" 개체일 수는 없다.
ex) "Contract_Emps" 개체이면서, 동시에 "Senior_Emsp" 개체일 수 있을 것이다.
이를 "Contract_Emps OVERLAPS Senior_Emps" 라 표현한다.
* Covering Constraints (포괄 제약조건)
- Superclass에 속하는 개체가 꼭 Subclass에도 속해야 하는지에 대한 조건이다.
- 바꿔 말하면, 모든 Subclass가 Superclass 개체들을 전부 Cover해야 하는지에 대한 조건이다.
- 포괄 제약조건이 따로 명시되지 않은 경우, 기본적으로 어느 Subclass에도 속하지 않는 Superclass의 개체가 존재할 수 있다고 간주한다.
ex) "Employee" 개체들 중, "Contract_Emps", "Hourly_Emps", "Senior_Emps" 어디에도 속하지 않는 개체가 있을 수 있다.
ex) Superclass인 "Motor_Vehicle" 개체는 반드시 Subclass인 "Motorboats" 개체에 속하거나, "Cars" 개체에 속해야 한다.
이를 "Motorboats AND Cars COVER Motor_Vehicle" 이라 표현한다.
Example.

- "Hourly_Emps ISA Employee"
- "Contract_Emps ISA Employee"
- Superclass는 "Employees"이고 , Subclass는 "Hourly_Emps"와 "Contract_Emps"이다.
- "Hourly_Emps"와 "Contract_Emps"는 "Employees"의 Attribute도 직접적으로 갖고 있는 형태이다.
- 만약 Overlap이 허용된다면, 해당 객체의 속성의 개수는 4개 혹은 5개일 것이다.
(동시에 포함될 수는 없다. 6개가 아니다!)
Aggregation (집단화)
- 어떤 관계집합과 개체집합들을 "하나의 큰 개체집합(집계된 개체집합)"으로 간주하여
E-R Diagram에 나타낼 수 있게하는 표현방법이다.
- 중복되는 관계를 단순한 관계로 표현할 수 있게 한다.
- 즉, Aggregation된 개체집합은 상위 레벨의 복합 개체집합이라 볼 수 있다.
- IS-PART-OF 관계를 E-R Diagram상에서 표현할 때 이용한다.
- E-R Diagram에서 "큰 개체집합"은 점선 사각형으로 표현된다.
Example.

- 파선 직사각형은 그 자체로 하나의 개체집합으로 볼 수 있고,
그 내부는 그림과 같이 또 하나의 관계집합과 여러 개체집합으로 구성되어 있다.
- Aggregation이 필요한 경우에서, Ternary Relationship으로 구현할 경우, 논리적 오류가 생길 수 있다.
1) Inner(Aggregated) Relationship Set
- 하나의 "Projects"는 여러 "Departments"의 "Sponsors"를 받을 수 있다. (실선, 화살표가 아님 = 1 to Many)
- 하나의 "Departments"는 여러 "Projects"를 "Sponsors"할 수 있다. (실선, 화살표가 아님 = 1 to Many)
- 모든 "Departments"는 반드시 "Sponsor"에 참여해야 한다. (굵은 실선 = 완전 참여)
- 일부 "Projects"만 "Departments"의 "Sponsors"를 받을 수 있다. (얇은 실선 = 부분 참여)
2) Outside Relationship Set
- "Employees"는 ("Departments"가 "Sponsors"하는 "Projects")를 "Monitors" 한다. (전체 구조)=
Conceptual DB Design with E-R Model (E-R 모델을 이용한 개념적 DB 설계)
* Main Issues
- 해당 Concept가 Entity, Attribute 중 어느 것으로 모델링되어야 하는가
- 해당 Concept가 Entity, Relationship 중 어느 것으로 모델링되어야 하는가
- Relationship Set들과 이에 참여하는Entity Set들은 어느것인가, Relationship는 Binary, Ternary 중 어느 형태를 선택해야 하는가
- Aggregation이 필요한가
Entity vs Attribute (개체와 속성 중의 선택)
- 실세계의 개념을 개체로 모델링할지, 속성으로 모델링할지에 대한 결정이다.
- 속성에 속성을 부여한 다중값 속성을 이용한 표현도 하나의 방법이나, 권장되지 않는다.
- 대체로, 개체집합으로 표현하는 방식이 Flexibility가 더 우수한 편이다.
Example.
"Students"(학생들)의 "Address"(주소) 개념을 모델링한다 가정하자.
1) "Address"를 Attribute로 모델링하는 경우
- 주소를 하나의 String으로 모델링하는 경우이다.
- "홍길동"의 "주소"는? 과 같이, 주소 자체에 대한 질의는 가능하다.
- "마포구"에 거주하는 "학생들"은? 과 같은 주소의 세부적인 정보를 묻는 질의는 불가능하다.
2) "Address"를 Entity Set으로 모델링하는 경우
- 주소를 다시 여러개의 Attribute로 구성될 수 있게 모델링하는 경우이다.
("주소" 개체집합에 "시", "구", "동" Attribute를 부여하여 세분화할 수 있다.)
- 이 때, "Address" 개체집합은 "Students" 개체집합과 "Has" 관계집합을 통해 연결될 수 있을 것이다.
- "상수동"에 거주하는 "학생들"은? 과 같은 질의가 가능하다.
Example.
"Work_In4" 관계집합에서 "근무기간" 개념을 모델링한다 가정하자.
1) "form"과 "to"를 "Work_In4" 관계집합의 Descriptive Attribute로 모델링하는 경우

- "Employees"가 "Departments"에서 근무한 기간에 대한 정보를 얻을 수 있다.
- 하지만, 한 직원이 여러 부서를 옮겨다녔을 경우에도, 가장 최근에 근무했던 부서에서의 기간 밖에 알 수가 없다.
(개체집합이 아닌, 속성으로 구현되었기 때문에, 근무 기간에 대한 정보를 단일값으로 저장할 수 밖에 없기 때문이다.)
2) "form"과 "to"를 "Duration" 개체집합의 Attribute로 하고, "Duration"을 "Work_In4" 관계집합에 연결하여 모델링하는 경우

- 한 "Employees"이 여러 "Departments"를 옮겨다녔을 경우에도, 특정 "Departments"에서 근무했던 기간까지도 조회할 수 있다.
(이 경우, 한 "Employees"에 대해 여러 "Duration" 개체집합이 Mapping되어 있을 것이다.)
Entity vs Relationship (개체와 관계 중의 선택)
Example.
"dbudget"(판공비) 속성을 관계집합에 연결하는 경우와, 개체집합에 연결하는 경우를 생각해보자.
1) "Manages2" 관계집합에 Descriptive Attribute로써 "dbudget"을 연결하는 경우

- 하나의 "Employees"가 여러 "Departments"를 관리할 수 있는 형태이다.
("Employees"에서 " Manages2"로의 1 to Many 관계)
- 한 "Departments"에는 한 명의 관리자 직원만 존재하는 형태이다.
("Departments"에서 "Manages2"로의 1 to 1 관계)
- 여러 "Departments"를 "Manages2"하는 한 명의"Employees"는 각 부서마다의 "dbudget"을 모두 받게된다.
- 회사 입장에서 여러 부서를 관리하는 직원에게 판공비를 한꺼번에 지급하고자하는 의도를 만족시키지 못한다.
2) "Managers" 개체집합에 Attribute로써 "dbudget"을 연결하는 경우

- 여러 부서를 관리하는 한 명의 직원에게, 판공비를 한꺼번에 지급할 수 있는 구조이다.
Binary Relationship vs Ternary Relationship (이진관계와 삼진관계 중의 선택)
Example.
- 회사의 "Employees"(사원)과 "Dependents"(부양가족)과 "Policies"(보험) 사이의 관계를 생각해보자.
1) Ternary Relationship (Bad Design)

- 한 명의"Dependents"가 여러 "Employees" 혹은 여러 "Policies"에 대응될 수 있는, 다소 상식적이지 못한 설계이다.
2) Binary Relationship (Better Design)

- 하나의 Ternary Relationship을 두 개의 Binary Relationship으로 분할한 형태이다.
- 한 "Employees"는 여러 "Policies"를 "Purchase"할 수 있다.
- 특정 "Policies"에 대한 "Purchaser"는 한 명이다. (화살표 = 1 to 1)
- "Beneficiary" 식별 관계집합은 강개체 "Policies"와 약개체 "Dependents"를 잇는 관계집합이다.
- "Dependents"는 반드시 가입된 "Policies"에 "Beneficiary"한다.
Example.
- "부품" 개체집합과 "부서" 개체집합, "공급자" 개체집합 사이의 관계집합들을 생각해보자.
- 어떤 "부서"가 어떤 "공급자"로부터, 어떤 "부품"을 계약하였는지에 대한 DB를 구축하고자 하는 경우, Ternary Relationship 형태가 적절하다.
1) Ternary Relationship
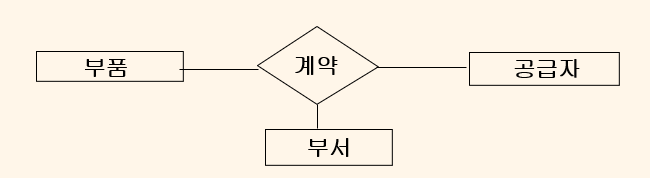
2) Binary Relationship (Incorrect Design)

- "부서", "공급자", "부품" 이 세 가지 개체 집합 사이의 관계를 파악할 수 없어서 요구사항을 충족할 수 없다.
※ 즉, 경우에 따라 Ternary Relationship 형태가 적절한 때가 있고, Binary Realtinship이 적절한 때가 있다.
Ternary Relationship vs Aggregation (삼진관계와 집단화 중의 선택)
Reference: Database Management Systems 3E (Raghu Ramakrishnan, Johannes Gehrke 저, McGrawHill, 2003)