
Chapter 3. Memory Management
※ Memory는 통상 D-RAM을 의미한다.
* Goal of Memory Management
- 메모리는 Scarce한 자원이기 때문에 여러 프로세스들이 메모리를 요청하는데,
이 때 Performance는 최대화하고, Overhead는 최소화 하면서 Memory를 Allocation하는 방법을 찾는다.
- 프로그래밍에서 효율적인 Abstraction을 제공한다.
- 프로그래머는 메모리가 0에서 N까지의 주솟값을 가진 Linear한 구조라 생각하고,
메모리 구조에 대한 상세한 지식 없이 프로그래밍할 수 있다.
* Mechanisms for Memory Management
- Physical Address Space, Virtual Address Space
- Page Table Management, Segmentation Policy
- Page Replacement Policy
* Memory Hierarchy

- 각각의 Layer는 Lower Level의 Cache 역할을 수행한다.
- CPU registers, L1 & L2 cache는 CPU가 관리하고,
Primary ~ Tertiary Storage는 OS가 관리한다.
3.1 No Memory Abstraction

- 메모리에 대한 Abstraction이 일절 없이, Physical Memory를 그대로 사용하는 시스템이다.
- 시스템은 위와 같이 구성될 수 있다.
Multiple Programs without Memory Abstraction
- Memory Abstraction이 없는 시스템에서의 문제점은 아래와 같다.
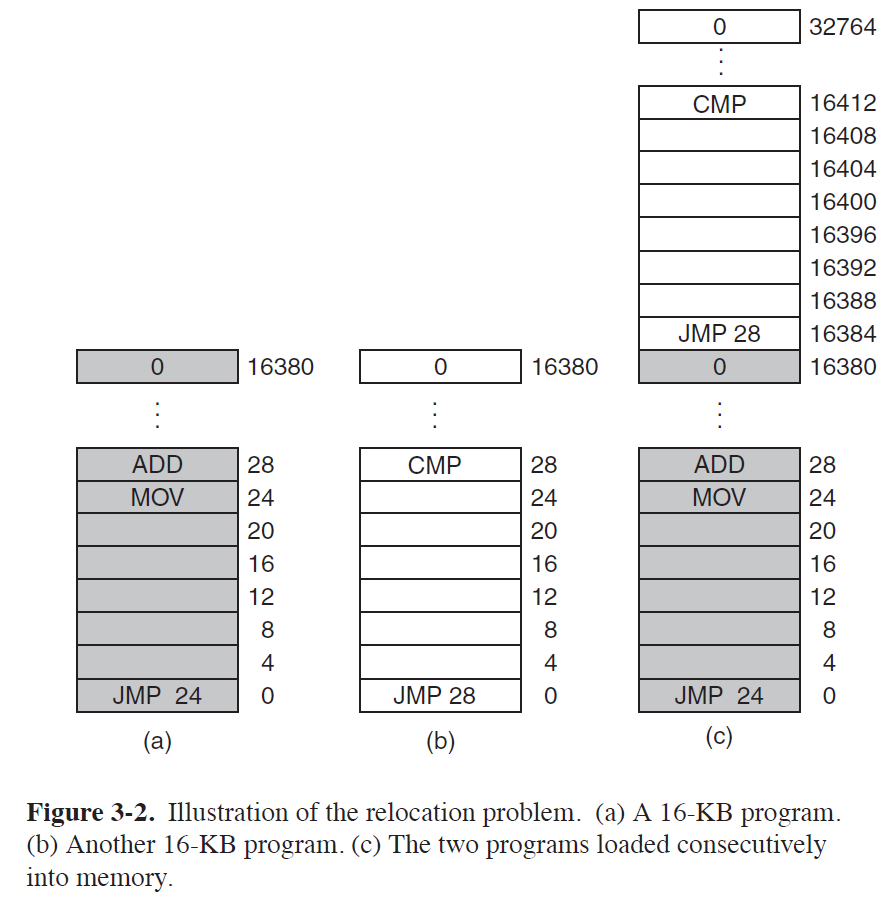
- 위 그림은 16KB 프로그램 (a), (b)가 32KB의 메인 메모리에 로딩되는 상황을 묘사한 그림이다.
- 만약, Physical D-RAM의 용량이 16KB에 못 미친다면, 프로그램(a) 혹은 (b)는 구동되지 못한다.
- (c)에서는 한 프로그램(b)이 다른 프로그램(a)의 메모리 영역을 침범하는 예시를 보여준다.
- 또한, 프로그램을 메인 메모리에 로딩시킬 때, 주솟값들을 일일히 상황에 맞게 수정해야 한다.
(이를 Memory Relocation이라 한다.)
※ Memory Abstraction이 없는 경우의 문제점
- Memory Resource가 부족할 경우, 프로그램을 아예 구동하지 못한다.
- 프로세스 간 Memory Protection이 보장되지 않는다.
- 프로그램을 Memory에 Loading할 때 마다, Memory Relocation이 필요하다.
3.2 A Memory Abtraction: Address Spaces
* Address Space
- 프로세스가 사용가능한 Memory Address의 집합(영역)을 의미한다.
* Physical Address
- D-RAM에 접근하기 위한 Address를 의미한다.
- D-RAM의 실질적인 주솟값이다.
- 즉, D-RAM의 메모리 영역이다.
* Logical Address (= Virtual Address, Linear Address)
- 프로그램 입장에서 접근하는 Memory Address를 의미한다.
- D-RAM의 Physical Address가 MMU(Memory Management Unit)를 통해 변환된 형태이다. (즉, D-RAM의 실제 주솟값과 독립적이다.)
- 대부분의 시스템에서는, Logical Address Space가 Physical Address Space보다 크다.
- CPU의 Instruction이 Encode/Decode되어 도출되는 메모리 주솟값은 Virtual Address이다.
(즉, 프로그래밍 영역에서는 Logical Address를 사용한다.)
- Physical Address와 Virtual Address 사이의 Mapping은 OS의 제어하에, H/W 레벨에서 자동적으로 이루어진다.
- Physical Address와 Virtual Address 사이의 Mapping의 대표적인 메커니즘들로는 아래와 같은 것들이 있다.
1) Base and Limit Registers
2) Paging System
3) Segmentation System
1) Base and Limit Registers
- 프로그램(b)의 경우, 메인 메모리에 Load되며 16,384만큼 메모리 주솟값이 Shift된다.
ex) 실제로, 프로그램(b)의 JMP 28 명령어는 메인 메모리에 Load되면서 JMP 16412로 변환되어야 한다.
즉, '28'은 Virtual Address이고, '16412'는 Physical Address이다.

Base register
- Shift될 메모리 주솟의 Offset값이 저장된다.
- 즉, 프로그램(b)가 메인 메모리에 Load될 때,
자동적으로 모든 명령어들의 주솟값에 Base register에 저장된 Offset값이 더해져서 Load된다.
Limit Register
- 메인 메모리에 Load될 프로그램의 메모리 크기이다.
- 프로그램의 명령어들은 Limit register값을 초과하는 메모리 주소를 참조할 수 없다.
(즉, 프로그램 간 Protection을 제공한다.)
- 명령어가 Limit Register 값을 초과한 주솟값을 참조하게 되면 Fault가 발생한다.
- Base register값과 Limit register값은 관련이 없다.
(위 그림에서 Base register값과 Limit register값이 같은 건 순전히 우연이다.)
- 프로그램의 크기가 Limit Register에 저장된 값을 초과하면 메인 메모리에 Load되지 못한다.
(Base Register 방식에서는 프로그램이 메인 메모리에 Continuous하게 Load되어야 하기 때문이다. 분산되어 Load되지 못한다.)

Conversion Process

- 위 과정은 Context Switch가 발생할 때 마다 메모리를 참조하는 모든 명령어에 대해 수행된다.
1. Logical Address값이 Limit Register 값을 초과하지 않는지 검사한다.
2. Logical Address에 Base Register에 저장된 값을 더한다.
3. 도출해낸 Physical Address를 통해 메인 메모리에 접근한다.
Swapping

(위 그림에서 빗금이 쳐진 부분은 현재 사용되지 않는 메모리 영역을 의미한다.)
- Swapping은 Base and Limit Registers 방식에서 메모리를 할당하는 방식이다.
- D-RAM의 크기가 전체 프로세스들을 모두 Load할 수 없을 때,
구동할 프로세스는 D-RAM에 Load하고, 나머지 프로세스는 Disk에 저장한다.
- Swapping 방식은 구동할 프로세스의 전체 Virtual Address Space를 D-RAM에 Load하고,
구동이 끝나면 다시 프로세스 전체를 Disk에 저장한다.
(즉, D-RAM의 크기가 작아 한 프로세스 전체를 Load할 수 없으면, 해당 프로세스를 수행할 방법이 없다.)
- Paging System과 대비되는 개념이다.
* Fragmentation
- 위 그림의 Step (e)에서 프로세스 A가 Load되고자 하고,
메인 메모리의 빈 공간이 프로세스 A가 Load되기에 충분하지만,
빈 공간이 두 영역으로 조각(Fragmentation)나 있어 Load되지 못하는 상황을 의미한다.
Memory Compaction
- Fragmentation이 일어난 메인 메모리에서 프로세스들을 한 쪽 방향으로 밀어내서 여러 조각들을 하나로 뭉치는 작업이다. (조각 모음)
- Load되어 있는 프로세스들을 다시 Read하고 Write해야 하므로 시간이 오래 걸린다.

- 실제로, Swapping 방식에서는 프로세스의 크기가 Dynamic하게 커질 것을 대비하여, (malloc() 함수 사용과 같은)
실제 프로세스 크기보다 큰 영역의 메모리를 프로세스에게 제공한다.
- 메모리의 Waste를 감수하는 방식이다. (배정한 메모리를 다 사용한다는 보장이 없기 때문이다.)
Memory Management in Swapping

- Swapping 방식하에서 메모리를 관리하는 방법으로는 Bit Map 방식과 Linked List 방식이 있다.
1) Bit Map Representation (그림의 (b) 방법)
- 메모리를 가상적으로, Allocation Unit으로 나누어서 할당하는 방법이다.
- 해당 Allocation Unit이 어떤 프로세스에 할당되어 있으면 1, 비어있으면 0으로, Bit Map으로 표시해둔다.
- 프로세스를 메모리에 Load할 때, Bit Map의 일련의 0들 중 프로세스의 크기가 맞는 곳에 할당한다.
ex) 100KB 메모리의 Allocation Unit을 2KB로 설정하면 Bit Map은 50bits로 구성할 수 있다.
- 즉, Allocation Unit이 클 수록, Internal Fragmentation의 크기가 커질 수 있다. (Trade-Off 관계에 있다.)
(Allocation Unit 안에서의 Fragmentation을 Internal Fragmentation이라 한다.)
- 극단적으로, Allocation Unit을 1Byte로 하면, Internal Fragmentation을 완전히 제거할 수 있다.
그러나, Bit Map Overhead가 커진다.
(메인 메모리는 Byte-Order이므로, 1Byte 단위로 할당되기 때문이다.)
- Allocation Unit 외부에서의 Fragmentation을 External Fragmentation이라 한다.
* Bit Map Overhead
- Allocation Unit에서 Bit Map을 표현하기 위한 메모리 공간 크기의 비율이다.
- Bit Map 또한 D-RAM에 저장되므로 Overhead가 발생된다.
ex) Allocation Unit = 1KB인 경우, 1,024 * 8 bits를 1 bit의 Bit Map으로 표현하는 것이기 때문에
Overhead Ratio = 1 / (1,024 * 8) 이 된다.
ex) Allocation Unit = 1B인 경우, 8 bits를 1 bit의 Bit Map으로 표현하는 것이기 때문에
Overhead Ratio = 1 / 8 이 된다.
(오버헤드 비율이 0.125이므로 매우 크다 할 수 있다. Allocation Unit의 12.5%가 Bit Map 표현에 사용된다는 뜻이다.)
2) Linked List Representation (그림의 (c) 방법)
- Allocation Unit 내에서 프로세스(P)는 얼만큼을 차지하고 있는지,
빈 공간(H ; Hole)은 얼만큼을 차지하고 있는지에 대한 정보를 담고 있는 Node들을 연결시켜 놓은 형태이다.
- Linked List 또한 D-RAM에 저장되므로 Overhead가 발생된다.
- 일반적으로, 주솟값을 기준으로 정렬된 상태로 List가 유지된다.
* Linked List Overhead
- Overhead는 Node의 개수가 되며, Allocation Unit의 크기와 Overhead는 큰 관련이 없다.
(즉, Linked List Representation에서는 Allocation Unit을 1Byte로 하여 Internal Fragmentation을 완전히 제거시키는 편이 좋다.)
- External Fragmentation의 개수가 많을수록, 노드의 개수가 많아져 Overhead가 커진다.

- 빗금친 영역은 External Fragmentation이고, X 표시된 영역은 Internal Fragmentation이다.
- Linked List Representation에서는 Internal Fragmentation을 제거하여(Allocation Unit을 1Byte로 하여)
Overhead를 줄일 수 있다.(노드의 개수를 줄일 수 있다.)
Algorithm for Allocating Memory
1) First Fit
- 메모리의 앞 부분부터 탐색해나가며, 프로세스가 진입 가능한 부분이 보이면 바로 할당한다.
- 메모리의 맨 앞 부분부터 채워나가므로, 점차적으로 Search Time이 증가할 수 있다.
2) Next Fit
- 이전에 메모리를 할당한 지점부터 탐색을 시작하는 방법이다.
(메모리의 맨 앞부터 탐색하는 것이 아니다.)
3) Best Fit
- 할당 가능한 메모리 영역들 중, 프로세스가 진입했을 때 Hole의 크기가 가장 작게 형성되는 위치에 할당하는 방법이다.
- Hole의 크기가 작게 형성되므로, 추후 다른 프로세스가 Hole에 할당될 가능성이 적다.
- 전체 메모리 영역을 전부 탐색해야 하므로 그에 따른 Overhead가 크다.
4) Worst Fit
- Best Fit과 정반대의 방법으로,
할당 가능한 메모리 영역들 중, 프로세스가 진입했을 때 Hole의 크기가 가장 큰 형성되는 위치에 할당하는 방법이다.
- Hole의 크기가 크면, 추후에 다른 프로세스가 그 위치에 할당될 것을 기대하여 의도적으로 Hole을 크게 유지하는 것이다.
- 전체 메모리 영역을 전부 탐색해야 하므로 그에 따른 Overhead가 크다.
5) Quick Fit
- 자주 사용되는 메모리 Size(Common Size)들을 따로 구분시켜 놓아서, 그 Size가 요청될 경우, 빠르게 탐색하여 할당한다.
- Common Size가 아닌, 다른 크기의 메모리를 요청한 경우, 전체 메모리 영역을 전부 탐색해야 한다.
6) Etc
- 프로세스가 차지한 부분들에 대한 List와 Hole들에 대한 List를 구분지어 유지하는 방법
- Linked List 방식에서, Hole들에 대한 노드를 따로 만들지 않고, Memory Hole 영역에 Hole에 대한 정보를 저장하는 방법
(Hole에 대한 노드를 따로 저장하지 않고, 사용되지 않는 Memory Hole 영역에 정보를 저장하므로 메모리 효율성이 향상된다.)
Fragmentation Problems
1) External Fragmentation이 발생할 수 있다.
2) Allocation Unit에 따른 Internal Fragmentation이 발생할 수 있다.
3) 경우에 따라, Memory Compaction이 필요하다.
4) 최적의 Partition Size(Allocation Unit Size)를 구하기 어렵다.
3.3 Virtual Memory
- Virtual Memory 방식은 Overlay 방식과 더불어, D-RAM의 크기보다 큰 프로그램을 수행시킬 수 있게하는 방법 중 하나이다.
- Virtual Memory의 구현 방법으로는 Paging System과 Sementation System이 있다.
- Physical Memory에는 실질적으로 사용되는 Virtual Memory Space만 Loading된다.
ex) 32Bits Address System에서는 한 프로세스가 \(2^32\)=4GB의 가상 메모리에서 OS가 허가한 부분을 사용할 수 있다.
이 때, 허가되지 않은 가상 메모리 영역에 접근했을 때 발생하는 오류가 Segmentation Fault이다.
* Overlay
- 한 프로그램에서 당장 사용할 영역만 D-RAM에 Load하고,
당장 사용하지 않는 프로그램 영역은 Disk에 저장해놓는 방식이다.
- 프로그래밍 복잡도가 높다.
3.3.1 Paging
- Virtual Address Space를 Page로 나누고, D-RAM도 Page와 같은 Size의 Frame으로 나눈다.
- Virtual Address와 Physical Address 사이의 Mapping 정보는 Page Table에 저장되어 있다.
- Page의 크기가 크면 Page Table의 Size가 감소하는 대신 Internal Fragmentation의 발생 가능성이 올라가며,
Page의 크기가 작으면 Page Table의 Size가 증가하는 대신 Internal Fragmentation의 발생 가능성이 줄어든다.
(Page의 크기와 Page Table의 크기는 Trade-Off 관계에 있다.)
Example. Page and Frame

- Figure 3-9.에서, Page와 Frame의 단위는 4KB이다.
※ Virtual Memory System에서는 Page와 Frame의 크기가 반드시 같아야 한다.
- 즉, Virtual Address Space는 16개의 Page로, Physical Memory Space는 8개의 Frame으로 구성된다.
- 16개의 Page들 중, 8개는 Frame에 Mapping되어 있고, 나머지 8개는 그렇지 않은 상황이다.
ex) MOV REG 8196 명령어의 경우, 아래에서 3번째 Page(8K-12K)에 존재하는 명령어일 것이고,
이는 6번 Frame에 Mapping 되어 있으므로, 8196을 Physical Address로 변환하면
16K(16,384)가 더해져 24580이 될 것이다.
- 즉, (Virtual) MOV REG 8196 \(\to\) (Physical) MOV REG 24580
Page Table

- 하나의 Entry에는 하나의 Page에 대한 정보가 기술되어 있다.
- Page Table의 크기는 Virtual Address Space의 크기와 Page의 단위로 결정된다.
(Page Table의 Entry 개수 = Virtual Address의 크기 / 한 Page의 크기)
- Page의 크기는 CPU 혹은 OS에 의해 결정되며, User가 설정할 수도 있다.
- Page Table은 D-RAM에 구현된다.
(Page Table의 각각의 Entry를 저장하는 Register를 구성하여 구현하는 방법도 있으나, 현실적이지 못하다.)
- 각각의 프로세스는 자신만의 Page Table를 가지며, Page Table의 시작 주솟값(Page table Ptr)은 PCB에 저장되어 있다.
- 즉, CPU Instruction 중, 메모리에 접근하는 명령어들의 경우,
Virtual Address를 Physical Address로 변환하기 위해 D-RAM에 있는 Page Table에 한 번 접근하고,
실질적인 명령을 수행하기 위해 다시 한 번 D-RAM에 접근하게 된다.
(즉, 메인 메모리에 두 번 접근한다.)
Page Table Input bits (Virtual Address)
- 위 그림의 하단부에 위치한 16bits Sequence이다.
(Address의 1bit는 1Byte의 D-RAM에 Mapping된다. D-RAM은 Byte Order이다.)
- CPU의 Spec에 의해 결정된다.*
- 16bit System CPU에서 Page의 단위가 4KB(=\(2^{12}\))라서 16(=\(2^4\))개의Page Table Entry 로 구성된 경우,
하위 12bits로 Offset을 표현하고, 상위 4bits로 Page Table의 Entry를 구분짓는다.
- Offset의 경우, Page Table Output에 그대로 출력된다.
* n-bit System CPU
- 여기서 n의 값은 CPU가 지원하는 Data Register의 크기와, CPU가 지원하는 Address Space의 크기를 의미한다.
Page Table Output bits (Physical Address)
- 위 그림의 상단부에 위치한 15bits Sequence이다.
- Main Memory의 용량에 의해 결정된다.
- 위 예시에서는, Frame의 개수가 8개이므로, Page Table에서 3bits로 VPN*을 구분지을 수 있다.
* VPN (Virtual Page Number)
- Page가 대응된 Frame의 번호이다.
ex) 위 그림에서 0번 Page의 VPN은 010이다.
※ 즉, Page Table은 VPN은 Physical Address로 변환한다.
- Offset은 그대로 유지되므로, VPN만 Physical Address로 변환된다.
Example. Paging
32bit Address System에서 Page Size가 4KB(= \(2^{12}\))라 가정하자.
이 때, Page Table Entry의 개수는 \({2^{32} bits \over 2^{12}bits} = 2^{20}\) 개 이며,
Offset은 12bits로 구성된다.
즉, Page Table Input의 상위 20bits로 Page Table Entry를 구분짓고,
하위 12bits로 Offset을 표현한다.
Virtual Address 0x13325328을 Physical Address로 변환한다 가정하자.
Offset은 0x328이고,
Page Table[0x13325]에 Frame Number 0x03004가 저장되어 있다.
따라서, Physical Address는 0x03004328이다.
(Physical Address는 Frame에 Offset을 Concatenation한 값이기 때문이다.)
Translating Virtual Addressses
- 아래 그림은 MMU 내부에서 Virtual Adress가 Physical Address로 변환되는 과정을 그린 그림이다.

- Virtual Address는 Virtual Page Number(VPN)와 Offset으로 구성된다.
- Index 역할을 하는 VPN을 이용하여 Page Table에 Access하여 Page Table Entry를 Load하고,
Page Table Entry의 구성요소 중 하나인 Page Frame Number(PFN)를 추출한다.
- Frame값과 Offset값을 Concatenation하여 Physical Address를 구한다.
(Physical Address = PFN::Offset)
- 그림에서 표현된 것과 달리, Page Table 또한 D-RAM(Physical Memory)에 저장되어 있다.
* Page table Ptr
- Page Table 또한, Array로 구현되어 있고 Page table Ptr은 이 Array의 시작 주소이다.
- 즉, Page table Ptr은 Array의 시작주소, virtual page #은 Index 값이므로,
이들을 통해 page table의 특정 인덱스에 접근할 수 있다.
- Page table Ptr은 Physical Address 형태이기 때문에, vartial page #과 Concatenation되어
곧바로 page table에 접근에 사용될 수 있다.
(만약, Page table Ptr이 Virtual Address였다면, D-RAM에 위치해있는 Page Table에 Access하기 위해
또 다른 변환과정을 거쳐야 할 것이고, 이는 매우 비효율적인 방법이다.)
- Intel Architecture의 경우, Page table Ptr은 Special Register인 CR3에 저장되어 있다.
(Special Register이므로, User Mode에서 접근할 수 없다.)
Page Fault

- Virtual Address를 이용하여 Page Table에 Access했지만, 해당 인덱스에 Page Table Entry가 Invalid한 경우이다.
- 이 경우, 해당 Virtual Address에 대응되는 Physical Address가 Page Frame으로 Main Memory에 저장되어 있는것이 아닌,
Disk에 저장되어 있는 상황이다.
- Page Fault가 발생한 경우, OS가 발동된다.
(OS가 발동되는 경우: System Call, External Interrupt, Internal Fault)
ex) 위 그림에서 Virtual Address 32780을 Physical Address로 변환하고자 하는 경우,
32780에 해당되는 Physical Address가 Page Table에 Mapping되어 있지 않고, Disk에 있는 상황이므로,
OS는 32780에 해당되는 Physical Address를 File System의 Swap Area에서 검색하여 찾아낸 다음,
Page Table Entry중 하나를 선정하여 바꿔놓는다. (이 예시에서는 Page table Ptr[2]가 Replacement 대상으로 선정되었다.)
(즉, 기존에 Page Table에 Frame값을 보유하고 있던 Virtual Page Entry의 Vaild Bit가 0(False)로 바뀌고,
방금 요청한 Virtual Address의 Frame Number로 해당 Page Table Entry가 Replacement된다.)
- 이와 같이, Replacement하는 방법에는 여러 알고리즘이 존재한다. (Page Replacement Algorithms)
Page Table Entry (PTE)

- 하나의 Page Table Entry(PTE)에는 여러 정보가 포함되어 있다.
1) Valid Bit (Present/Absent)
- 해당 Entry의 정보가 유효한지 아닌지에 대한 여부이다.
2) Reference Bit
- 해당 Page가 참조되었는지에 대한 여부이다.
- 해당 Page에 대해 Load 혹은 Store 명령이 수행되었는지에 대한 여부이다.
3) Modify Bit (Dirty Bit)
- Disk에서 Page Table로 Load한 이후, 데이터에 대한 (Store 명령을 통한)수정사항이 생겼는지에 대한 여부이다.
- 이 때, Disk에 있는 데이터는 Old Ver.이 되고, 현재 Page Table에 있는 데이터는 New Ver.이 되며,
Modify Bit는 True로 설정된다.
- 즉, Store 명령이 수행되면, Modify Bit은 True로 설정되며, 다른 Page로 대체될 때, Disk에 백업하게 된다.
- 반대로, Modify Bit이 False로 설정되어 있으면, 다른 Page로 대체될 때, 단순히 Overwrite된다.
4) Protection Bit
- 해당 Page를 Read, Write, Execution이 가능한지에 대한 여부이다.
5) Page Frame Number
- 해당 Page가 Loading된 PFN 값이다.
6) Caching Disabled
- 해당 Page가 Cache를 사용할 수 있는지에 대한 여부이다.
Paging Advantage
- 아래는, Paging System으로부터 오는 장점들이다.
1) Physical Memory의 Allocate/Free가 쉽다. (관리가 쉽다)
- Swapping 방법에 대비하여, 메모리의 빈 공간들이 모두 Frame으로, 일정한 크기로 단순하게 관리되기 때문이다.
2) External Fragmentation 문제가 없다.
- 한 프로세스가 Page 단위로 메모리를 사용하기 때문이다.
3) 프로세스가 구동될 때, 프로세스의 Virtual Address Space의 모든 정보가 D-RAM에 Load될 필요가 없다.
- 즉, 프로세스의 Virtual Address Space의 크기가 Physical Address Space보다 커도 관계없다.
- Swapping 방법에 대비하여, Paging System의 가장 큰 장점이다.
(Swapping 방법에서는 프로세스의 Virtual Address Space의 크기가 Physical Address Space보다 크면, 대처할 방법이 없다.)
Paging Disadvantage
- 아래는, Paging System으로부터 오는 단점들이다.
1) Internal Fragmentation 문제가 존재한다.
- 단, 하나의 Frame을 두 개 이상의 프로세스가 사용할 수는 없으므로, Internal Fragmentation 문제는 여전히 존재한다.
- 하나의 프로세스가 한 Frame을 전부 사용하지 못하면, 곧 Internal Fragmentation이 존재하게 되는 것이다.
- 그러나, 다른 System에서도 존재하는 단점이라 Paging System만의 단점이라 할 수 없다.
2) Cache Miss의 경우, Memory Access에 대한 Overhead가 100% 더 증가한다.
- 실질적인 명령을 수행하기 전에, Virtual Address를 Physical Address로 변환하기 위해 D-RAM의
Page Table에 미리 한 번 접근해야 하기 때문이다.
- 즉, Memory에 Access하는 Instruction의 경우, Memory에 두 번 접근해야 한다.
- 이에 대한 Solution으로 TLB(Translation Lookaside Buffer)를 사용하는 방법이 있다.
3) 각각의 프로세스들에 대한 각각의 Page Table을 저장하기 위해 D-RAM의 많은 용량을 필요로 한다.
- 이에 대한 Solution으로 Multilevel Page Table을 사용하는 방법이 있다.
ex) 32Bit Address Space에 대해 하나의 PTE는 4Byte(=12bits)를 차지할 경우,
이러한 PTE가 \(2^{20}\)개로 구성된다.
즉, 하나의 Page Table이 4Byte * \(2^{20}\) = 4MB씩 차지하게 되고,
25개의 프로세스가 구동될 경우, 25개의 Page Table이 필요하게 되어,
약 4MB * 25 = 100MB의 공간을 Page Table들을 구성하기 위해 마련되어야 한다.
ex) 64Bit Address Space에 대해 하나의 PTE는 4Byte(\(=12bits)를 차지할 경우,
이러한 PTE가 \(2^{52}\)개로 구성된다.
즉, 하나의 Page Table이 \(4Byte * 2^{52} = 2^{54} Byte\)씩 차지하게 되고,
25개의 프로세스가 구동될 경우, 25개의 Page Table이 필요하게 되어,
약 \(25 * 2^{54}\) Byte의 공간을 Page Table들을 구성하기 위해 마련되어야 한다.
현실적으로, 이러한 크기의 D-RAM을 구현할 수 없어, Page Table의 전체가 아닌, 일부만 D-RAM에 Load한다.
TLB (Translation Lookaside Buffer)
- CPU와 Page Table 사이를 Caching해주는 H/W Unit이다.
(TLB에 수정사항이 생기면, Page Table에 반영되고,
Page Table에 수정사항이 생기면, TLB의 해당 부분이 Flush된다.)
- 한 Cycle에 Virtual Page Number를 PTE로 변환해주는 H/W이다.
(D-RAM에 두 번 Access하여 생기는 Delay를 절감하는 역할을 한다.)
- Fully Associated Cache이므로, Index로 Entry를 찾지 않고, Contents로 찾는다. (Contents Addressible Memory)
- Cache Tag로써 Virtual Page Number를 사용한다.
- Cache Value(Output)로 PTE가 출력된다.
(출력된 PTE에 Offset을 붙여 Physical Address를 계산해낸다.)
- Page Table에 실제로 Mapping된 일부가 TLB에 저장되어 Reference Locality를 만족시킨다.
(즉, TLB Miss가 발생되어 Page Table까지 접근하여 PTE를 리턴받았다면, 해당 PTE를 TLB에 저장시킨다.)
(방금 사용한 PTE는 곧 다시 사용할 가능성이 높기 때문이다.)
- 즉, TLB는 Page Table의 Cache이다.
- OS는 TLB와 Page Table을 Consistent하게 유지시킨다.
* TLB Structure

- Vaild Bit가 존재하여, 0인 경우 해당 Entry가 무효함을 의미한다.
- TLB의 각 Entry에는 Virtual Page Number가 있고, 그에 해당되는 PTE(Modified, Protection, Page Frame 등)가 존재한다.
(그림에는 생략되었지만, PTE의 다른 정보들도 TLB에 저장될 수 있다.)
- Virtual Page Number는 TLB의 Cache Tag로 사용되어 Search에 사용된다.
(TLB는 Contents Addressible Memory임을 상기하자.)
- TLB에 있는 Entry 중 Modified Bit이 1로 설정되어 있는 Entry의 경우, (TLB에 Load된 이후, 데이터가 수정된 경우)
Replacement될 때 Page Table에 반드시 값을 Update 한 후에 TLB에서 삭제되어야 한다.
(TLB에 있는 값이 최신 정보이고, Page Table에 있는 값은 Old Ver.이기 때문이다.)
* MMU with TLB

p : Page Table Number
d : Displacement (= Offset)
f : Frame
- p를 이용하여 TLB를 Search하고,
TLB Hit가 발생할 경우, TLB로부터 f를 리턴받아 Physical Address를 계산해내고,
TLB Miss가 발생할 경우, 그제서야 Page Table에 접근하여 f를 리턴받아 Physical Address를 계산해낸다.
- TLB Hit/TLB Miss의 경우, 해당 프로세스가 CPU 점유를 계속하지만,
Page Fault가 발생한 경우, 해당 프로세스는 Blocked되고, OS가 Disk(I/O Unit)에 해당 PTE를 찾을 것을 명령한다.
(Disk에서 해당 PTE가 Load되면, Blocked되었던 프로세스가 우선적으로 CPU를 다시 할당받아 명령어를 수행한다.)
- 이 때, Disk에서 찾은 PTE는 Page Table에도 Loading되고, TLB에도 Loading된다.
- Intel x86 시스템에서는, TLB는 MMU 내부에 위치하여, TLB Hit/Miss에 대한 대처사항들은 MMU가 처리한다.
(이 경우, MMU가 Page Table의 위치와 Format을 알고 있어야 한다.)
- TLB Hit/Miss를 OS가 처리하는 경우도 있다.
(이 경우, MMU가 간단해져 속도가 빨라지고, Page Table의 Format을 OS가 자유로이 정할 수 있지만,
OS는 명령어를 수행시켜 TLB Hit/Miss를 처리하는데
이 과정에서 또 TLB Miss가 발생할 수 있기 때문에 이에 유의하여 구현해야 한다.)
- Context Switch가 발생된 경우, TLB는 Flush된다. (TLB의 Vaild Bit가 모두 0으로 설정된다.)
Multilevel Page Table

- 기존의 방식은 Virtual Address의 20Bits에 대한 \(2^{20}\)개의 Entry를 구성하는 방식이었다.
- Multilevel Paging에서는 20Bits의 주솟값을 10Bits씩 나누고, (PT1, PT2로 나눈다.)
PT1을 통해 Top-Level Page Table에 접근하고, PT2를 통해 Second-Level Page Table에 접근한다.
- Two-Level Paging에서는 모든 Page Table들을 미리 다 만들어놓지 않아도 된다.
(특히, Secondary Page Table은 필요할 때 마다 생성된다.)
ex) 위 그림에서, 12MB의 Address Space를 위해 3개의 Secondary Paga Table과 1개의 Master Page Table만을 필요로한다.
(한 Page Table이 4MB의 크기를 차지한다 가정했을 때)

- Page table Ptr과 master page #을 더하여 master page table의 Entry 중 하나를 선택한다.
- master page table에는 다음 레벨 Page Table의 시작 주솟값이 Physical Address로 저장되어 있다.
- master page table로부터 얻은 Secondary page table #(시작 주솟값, Physical Address)과 secondary page #을 더하여
page frame #를 얻어내고, 이를 offset과 Concatenation시켜 Physical Address를 산출해낸다.
- master page table의 Entry 혹은 secondary page table의 Entry의 Vaild Bit가 0이면 Page Fault가 발생한 것이다.
* Overhead for Two-Level Paging
- Two-Level Paging에서는 Space Overhead는 절감될 수 있으나, Time Overhead는 더 증가된다.
- Two-Level Paging에서는 총 3번의 Memory Access가 이루어져야 한다.
(master page table에 대한 Access, secondary page table에 대한 Access, 최종적인 Physical Memory에 대한 Access)
- Two-Level Paging에서 Secondary Page Table은 Valid Bit가 1인 Master Page의 Entry가 대응되어야만 생성된다.
- 즉, 필요없는 Secondary Page Table은 굳이 미리 생성해놓지 않고,
Secondary Page Table이 필요해질 때마다 추가적으로 동적으로 생성하여 사용함으로써 Space Overhead를 절감한다.
(물론, Master Page Table은 미리 만들어져 있어야 한다.)
- Page는 OS Code의 일부분이므로, Secondary Page Table의 개수의 증가는 곧 OS Code의 크기가 증가를 의미한다.
- Master Page Table의 Entry중 Valid Bit = 0인 Entry에 Access할 경우, Page Fault를 발생시켜,
해당 Entry에 대응되는 Secondary Page Table을 생성하고, 적절한 Frame을 할당한다.
ex) Master Page Table에 단 4개의 Entry만 유효하고, 각 Entry는 각각의 Secondary Page Table에 대응된다고 가정하면,
총 5개의 Page Table만을 요구한다. (Master Page Table 1개, Secondary Page Table 4개)
(즉, 무조건적으로 \(2^{10} + 1\)개의 Page Table을 구성해놓지 않는다.)
Two-Level Paging Design Example
- 4KB 크기의 Master Page에서 한 PTE의 크기가 4Bytes인 경우, 해당 Page Table은 \(2^{10}\)개의 Entry를 갖는다.
(즉, 이 Master Page Table에 접근하기 위한 Offset의 크기는 12Bits이다. 전체 Page의 크기가 4KB이기 때문이다.)
(또한, Master Page Table의 Indexing을 위해 10Bits가 필요하다. \(2^{10}\)개의 Entry가 존재하기 때문이다.)
- 즉, Secondary Page Table에 접근하기 위한 주소로 10Bits가 남는다.
(전체 32Bits - Offset 12Bits - Master Page Table Indexing 10Bits = 10Bits)
Inverted Page Table

p : Virtual Page Number
i : Frame Number
d: Displacement (Offset)
※ 본질적으로, Mapping 정보는
Frame의 개수만큼만 필요하기 때문에,
Frame Number로 Page Number를 찾는
Inverted Page Table 개념이 고안되었다.
- 64Bits시스템과 같은 대규모 시스템에서 Page Table을 운용하는 방법이다.
(64Bits시스템에서는 PTE의 크기가 4KB라 할 때, \(2^{52}\)개의 PTE가 생성된다.)
- 기존의 Page Table과 달리, Frame Number를 Page Number로 변환하는 역할을 한다.
(즉, Frame Number를 Index로 사용한다.)
- 즉, Page Number에 대한 Frame Number를 Inverted Page Table에서 찾고자 하는 경우,
Indexing이 아닌, Contents로 찾아야한다.
- Physical Memory Space는 여러 프로세스들이 동시에 사용중일 수 있으므로,
Inverted Page Table에서 Frame Number를 Page Number로 변환할 때에는
해당 Frame Number와 더불어 해당 프로세스의 pid값까지 필요로한다.
(다른 프로세스가 같은 Page Number를 다른 Frame에 저장해놓으면,
추후 Page Number를 Inverted Paga Table을 통해 Frame Number로 변환할 때 충돌 문제가 발생할 수 있다.)
- 즉, Virtual Page Number와 pid가 일치하는 Inverted Page Table Entry의 Index값이 곧 Frame Number이다.
- Inverted Page Table에 대한 참조는 Contents를 대조하여 이루어지기 때문에
평균적으로 \({n \over 2}\) 만큼의 적지않은 시간이 소요된다. (\(n\) : Inverted Page Table의 크기)
그러므로, Inverted Page Table을 사용하는 시스템에서는 TLB의 성능이 아주 중요하다.
(TLB Miss가 발생하게 되면 \(\Theta({n \over 2})\) 만큼의 시간을 소모하며 Inverted Page Table을 Search해야하기 때문이다.)
- 이와 같이, Inverted Page Table의 Search 시간을 최적화하기 위해, Hash Table Mechanism을 이용한다.
* Hash Table Mechanism for Inverted Page Table

- \(2^{64}\) Bits Virtual Page에, 각 PTE의 크기는 4KB(=\(2^{12}\)) 이고,
Physical Memory는 1GB(\(=2^{30}\)) 크기로, 각 PTE의 크기는 4KB(=\(2^{12}\)) 이고, 이러한 PTE가 \(2^{18}\)개 존재한다.
- Virtual Page와 Page Frame 사이의 Mapping 관계를 Hash Table에 정의하고,
Hash Function은 pid와 Virtual Page Number를 인자로 받아 Page Frame을 리턴한다.
- Hash Table의 각 Entry에는 Mapping 정보들이 List로 연결되어 있다.
(Entry에 2개 이상의 List가 연결되어 있는 것은 Hashing시에 Collision이 발생했음을 의미하므로, 이를 최소화해야한다.)
- Collision이 발생되지 않아, Hash Table의 각 Entry마다 하나의 리스트만 연결되어 있는 경우, Memory Access는 총 3번 발생된다.
(Hash Table에 대한 Access, Hash Table의 Entry에 있는 Node에 대한 Access, 최종적인 D-RAM에 대한 Access)
- 여기서, Collision이 발생되어 같은 Entry에 Node가 추가되면,
그 리스트에서 노드를 검색하는 횟수만큼 Memory Access 횟수가 증가된다.
(즉, Hash Table을 이용한 방법에서 Memory Access 횟수는 Two-Level Paging 방식에서의 Memory Access 횟수보다 작을수는 없다. Two-Level Paging 방식에서는 기껏해야 3번의 Memory Access만 수행되기 때문이다.)
\(\texttt{hash_func(pid, vpn)} \to \; \mathrm{index}\) (Inverted Page Table에서 index는 곧 Page Frame이다.)
3.4 Page Replacement Algorithms
- Page Replacement Algorithm의 목적은 Fault Rate을 낮추기 위해, 최적의 Victim Page를 찾아 D-RAM에서 제거하는 것이다.
(최적의 Victim Page는 긴 시간동안 접근할 일이 없는 Page가 될 것이다.)
* Demand Paging
- Page Fault가 발생해야만, 해당 Page만 Disk에서 찾아 Frame에 Loading하는 방식을 의미한다.
- 전체 프로세스가 메인 메모리에 Loading되는 Swapping과 대비되는 개념이다.
- Demand Paging 방식에서 이미 모든 Frame이 사용중인 상태에서 Page Fault가 발생해
새로운 Page가 Frame으로 Loading되어야 하는 경우, 기존의 Page들 중 하나를 새로운 Frame이 Replacement하게 된다.
(이 때, Evicted Page(대체될 Page)를 선정하는 작업을 Page Replacement라 부른다.)
- Evicted Page가 대체될 때, Disk에 있는 백업본과 데이터가 상이하면(Disk에 있는 데이터가 Old Ver.이면) Disk에 저장한 다음 대체되어야 한다.
- 반대로, Evicted Page가 대체될 때, Disk에 있는 백업본과 차이가 없으면, 새로운 Page로 바로 Overwrite되어도 된다.
- 즉, Modify Bit을 통해 Evicted Page의 Disk 백업 여부를 결정한다.
* Thrashing
- Paging Replacement Algorithm에 결함이 있거나,
Physical Page를 담을 Frame의 크기(즉, D-RAM의 크기)가 작아서
Page Fault가 비정상적으로 자주 발생되는 현상이다.
- Page Fault가 발생할 때 마다, 프로세스가 멈추게 되어 많은 시간을 낭비하게 된다.
(실제로, OS Time의 대부분은 Page를 Disk에서 옮겨오는 시간이 차지하고 있다.)
- 이를 해결하는 방법으로는 SWAP 혹은 D-RAM 증설이 있다.
* Belady's Proof
- 가장 오랜시간 동안 사용되지 않을 Page를 Evicting하면, Page Fault Rate가 최소화 됨을 입증한 증명이다.
Page Replacement Algorithms #1 : Belady's Algorithm (Optimal Algorithm)
- 이론적으로, 항상 Fault Rate이 가장 낮게 유지되는 알고리즘이다.
- 가장 오랫동안 사용되지 않을 Page를 Replacement한다.
- Access될 Page들의 순서를 미리 알고있어야 한다는 제약이 있어, 현실적으로 구현하기 어렵다.
- Paging Algorithm의 성능을 가늠할 때, Belady's 알고리즘의 성능과 유사할수록 높게 평가된다.
- 반대로, Random하게 Page를 Replacement하는 알고리즘의 성능이 Paging Algorithm 성능의 하한선이 된다.
(Random 알고리즘은 Overhead가 가장 적다. 따라서, Overhead는 Random 알고리즘보다 크고,
성능은 Random알고리즘보다 안 좋은 알고리즘은 사용할 이유가 없다)
Page Replacement Algorithms #2 : NRU (Not Recently Used Page Replacement Algorithm)
- NRU 알고리즘에서 각 Page Table의 Entry들은 R bit와 M bit를 가진다.
- M bit과 R bit에 대한 설정은 오로지 H/W(MMU)에 의해 이루어진다.
Referenced Bit (R Bit)
- 해당 Page에 대한 Reference(Read/Write)가 이루어졌는지에 대한 여부이다.
- R bit은 주기적으로 Clear되며, 이는 S/W적으로 구현되어 있다.
(Clock Interrupt가 발생될 때 마다(=주기적으로) Clear된다.)
Modified Bit (M Bit)
- Frame에 옮겨온 이래로, 데이터에 대한 Modify가 이루어졌는지에 대한 여부이다.
- M bit이 설정된 경우, Disk의 Swap Area에 있던 기존의 정보는 Old Ver.이 된다.
- 즉, M Bit = 1인 Frame이 Replacement될 경우, Disk에 반드시 백업한 후 삭제되어야 한다.
(M Bit = 0인 경우, Replacement할 때 해당 Frame을 Overwrite해도 문제가 없다.)
- 또한, M bit은 한 번 설정되면 Disk에 백업될 때 까지 바뀌지 않는다.
- 즉, M bit이 설정되면, R bit도 자동으로 설정된다.
(그러나, R bit은 주기적으로 Reset되므로, M Bit = 1이고, R Bit = 0인 상태도 가능하다.)
* NRU Class
- NRU에서는 Page의 상태에 따라 Class로 구분짓는다.
- NRU에서는 Class 0에 가까울수록, Replacement가 될 확률이 높은 Frame임을 의미한다.
| R Bit | M Bit | Description | |
| Class 0 | 0 | 0 | Not Referenced Not Modified |
| Class 1 | 0 | 1 | Not Referenced Modified * R bit은 주기적으로 Clear 되기 때문에 이러한 상태가 가능하다. |
| Class 2 | 1 | 0 | Referenced Not Modified |
| Class 3 | 1 | 1 | Referenced Modified |
- R Bit은 주기적으로 Clear된다. 즉, R Bit = 1인 경우,
이전에 Clear된 이후로 한 번 이상 Reference를 수행했음을 의미한다.
(즉, 최근에 접근했던 Frame이므로, Reference Locality가 있다.)
Page Replacement Algorithms #3 : FIFO (First In First Out Replacement Algorithm)
- 가장 오래전에 Frame에 Load된 Page를 Replacement하는 알고리즘이다.
- Locality를 전혀 고려하지 않는 알고리즘이다.
Example. Optimal vs FIFO

- 3개의 Frame으로 구성된 시스템에서, 위와 같은 Stream을 각각 Optimal 알고리즘과 FIFO 알고리즘을 적용시켜 보자.
1) Optimal 알고리즘
- 처음, Cold Miss로 인한 3번의 Fault가 발생되고, D에 Access해야할 때 Fault가 발생되어 C를 Replacement한다.
(Frame의 A, B, C 중, C가 가장 나중에 Access되기 때문이다.)
- 그 이후, C에 Access해야 할 때 Fault가 발생되어, A와 D 중 하나를 선정하여 Replacement한다.
(Frame의 A, B, D 중 A와 D는 이후에 Access할 일이 없기 때문이다.)
- 총 5번의 Fault가 발생한다.
2) FIFO 알고리즘
- 처음, Cold Miss로 인한 3번의 Fault가 발생되고, D에 Access해야할 때 Fault가 발생되어 A를 Replacement한다.
(Frame의 A, B, C 중, A가 Frame에 가장 오래전에 Load된 Page이기 때문이다.)
- 직후, A에 Access해야할 때 Fault가 발생되어 B를 Replacement한다.
(Frame의 B, C, D 중, B가 Frame에 가장 오래전에 Load된 Page이기 때문이다.)
- 그 이후, B에 Access해야할 때 Fault가 발생되어 C를 Replacement한다.
(Frame의 C, D, A 중, B가 Frame에 가장 오래전에 Load된 Page이기 때문이다.)
- 직후, C에 Access해야할 때 Fault가 발생되어 D를 Replacement한다.
(Frame의 D, A, B 중, D가 Frame에 가장 오래전에 Load된 Page이기 때문이다.)
- 총 7번의 Fault가 발생한다.
* Belady's Anomaly
- FIFO 알고리즘에서는 Frame의 수가 증가된다해서(D-RAM의 용량이 증가된다 해서)
Page Fault Rate의 감소가 보장되지 않음을 의미하는 용어이다.
(심지어, Page Fault Rate이 증가되는 경우도 있다.)
- FIFO를 제외하고, LRU를 비롯한 대부분의 Replacement 알고리즘에서는
Frame의 수가 증가됨에 따라 Page Fault Rate이 증가되지 않음이 증명되어 있다.
Page Replacement Algorithms #4 : Second-Chance Page Replacement Algorithm
- Page들을 FIFO 형태로 정렬하되, R Bit의 상태를 고려하여 Replacement하는 알고리즘이다.
- 가장 오래전에 Load된 Page의 R Bit이 1이면, R Bit을 0으로 설정한 후, FIFO Queue의 맨 뒤로 옮겨준다.
(이와 같은 과정을 R Bit이 0인 Page를 찾아 Replacement할 때 까지 반복한다.)
- 가장 오래전에 Load된 Page들부터 R Bit이 0인 Page를 찾아 Replacement한다.
- Replacement할 때, M Bit = 1이면, Swap Ared에 데이터를 백업한 후 Replacement해야 하며,
M Bit = 0이면, 그대로 Overwrite해도 문제없다.
- Linked List를 잘라서 이어붙이는 과정이 반복되므로, 비효율적이다.
이러한 비효율성을 보완한 알고리즘이 Clock Page Replacement 알고리즘이다.
※ Second-Chance Page Replacement 알고리즘은 Locality를 고려한 FIFO 알고리즘이라 볼 수 있다.
- R Bit이 설정되어있음은 최근에 참조된 적이 있었음을 의미하고, 또 다시 참조될 가능성이 높다. (Locality 개념)
- FIFO 알고리즘은 Locality를 전혀 고려하지 않은 알고리즘임을 상기하자.
Example. Second Page Replacement Algorithm

- Time = 20에 Page Fault가 발생되었고, A의 R Bit = 1이라 가정하자.
- 가장 오래전에 Load된 Page인 A는 R Bit = 1이므로, R Bit = 0으로 설정되고, FIFO Queue의 맨 뒤로 옮겨진다.
(Load Time값도 20으로 수정된다.)
Page Replacement Algorithms #5 : The Clock Page Replacement Algorithm

- Second-Chance Page Replacement 알고리즘과 전체적인 틀은 동일하다.
- 중앙의 시침은 가장 오래된 Frame을 가리키고 있다.
- Page Fault가 발생했을 때, 시침이 가리키는 Frame의 R Bit = 0이면, 해당 Frame을 Replacement하고,
시침은 다음 Frame을 가리키게 된다.
(위 그림에서 Page Fault가 발생되고, C의 R Bit = 0이면, C가 Replacement되고, 시침은 D를 가리키게 된다.)
- Page Fault가 발생했을 때, 시침이 가리키는 Frame의 R Bit = 1이면, 해당 Frame의 R Bit = 0으로 바꾸고,
시침은 다음 Frame을 가리키게 된다.
위 과정을 반복하며, R Bit = 0인 Frame을 찾아내어 Replacement한다.
- 새로 Frame에 Loading된 Page의 R Bit은 1로 설정된다.
(가장 최근에 접근된 Page이므로, 높은 Locality를 갖기 때문이다.)
Page Replacement Algorithms #6 : Least Recently Used Algorithm (LRU)
- 가장 오랫동안 사용되지 않은 Frame에 Load된 Page를 Replacement하는 알고리즘이다.
- 일반적으로, LRU는 우수한 성능을 내지만,
Circular하게 Frame들을 Access하는 경우,
오랫동안 사용하지 않았더라도 언젠가는 사용하게 되는 경우에는 LRU가 좋은 성능을 내지 못한다.
- LRU의 구현은 Page에 Access할 때마다 Timestamp(시간정보)를 기록해놓고,
Fault가 발생되면, 가장 오래전에 Access된 Frame을 Timestamp로 가려내는 방식으로 구현한다.
(Overhead가 큰 탓에 실질적으로 구현이 어렵다.)
* LRU Implementation
1) Linked List를 이용한 방법
- Frame에 Loading된 Page들로 구성된 Linked List로 구현한다.
(즉, Frame을 Linked List로 구현한다.)
- Memory Reference(Memory Access)마다 해당 Page를 Linked List의 맨 앞으로 이동시킨다.
(즉, List의 맨 뒤에 있는 Page가 가장 오랫동안 사용되지 않은 Frame인 것이다.)
- Page Fault가 발생되면, List의 맨 뒤에 있는 Frame을 Replacement한다.
- Memory Reference가 일어날 때 마다, Linked List를 회전시켜서 발생되는 Overhead가 존재한다.
2) Counter를 이용한 방법
- 명령어가 수행될 때 마다 Counter값을 증가시키고, Memory Reference가 발생되면,
Counter값을 해당 Page의 Entry에 기록한다.
(즉, 시간 정보를 기록하는 방식이다.)
- Frame에 위치한 Page들 중, Counter 값이 가장 작은 Frame을 Replacement한다.
(즉, Counter 값 정보를 Page가 아닌, Frame에 저장해도 무관하다.)
3) n by n Bits H/W Matrix를 이용한 방법
- H/W적으로 구현하기에 난이도가 높아, 아주 작은 시스템에서만 사용할 수 있는 방법이다.
- 현실적이지 못한 방법이다.
* Simulating LRU in S/W (Approximatino LRU)
- 매번 일어나는 Memory Reference마다 LRU를 적용하기엔 비효율적이라서,
아래와 같은 LRU Approximation들을 이용한다. (Approximation = LRU를 정확히 구현한 형태는 아니다.)
- 이러한 Approximation들에서는 R Bit을 이용한다. (최근에 참조되었는지에 대한 정보를 R Bit이 담고 있기 때문이다.)
* NFU (Not Frequently Used) = LFU (Least Frequently Used)
- Page들은 저마다의 S/W Counter를 갖고, 주기적으로(매 Clock Interrupt마다) 해당 Page의 R Bit 값을 Counter에 가산한다.
(즉, 해당 Interval 동안 Reference가 발생했다면, Counter에 1이 더해질 것이고, 그렇지 않았다면 0이 더해질 것이다.)
- 즉, Counter 값은 해당 Page가 "얼마나 많이" Reference가 되었는지를 의미하는 값이 된다.
("최근"에 Reference되었는지에 대한 정보는 담고있지 않다.)
- NFU는 LRU보다는 Simple하지만,
과거에만 많이 Reference된 Page가 Replacement되지 못하는 등의 문제가 있어,
Reference Locality를 적절히 구현하지는 못한다.
- 이에 대한 해결책으로 Aging 방법이 있다.
* Aging
- NFU의 Counter 대신, Shift Register를 이용한 방법이다.
- Interval마다(Clock Interrupt마다), 해당 Page의 R Bit 값이 Shift Register의 MSB에 삽입되고,
기존에 Shift Register에 있던 값들은 오른쪽으로 1Bit씩 Shift된다.
- 즉, 최근에 Reference가 일어나서, R Bit = 1이었다면, 해당 Shift Register의 값이 가장 큰 값으로 됨을 의미한다.
- Aging 방법에서는 Page Fault가 발생되면, 각 프로세스의 Shift Register 값들을 비교하여,
값이 가장 작은 Page를 Replacement한다.
- Aging 방법에서는 Shift Register의 크기(Bit수)에 따라, 오래전 과거에 Reference가 이루어졌는지는 판별할 수 없는 구조라는 점에서 LRU와는 차이가 있다.
ex) 만약, Shift Register가 8Bits인 경우, 9번 이전의 Cycle(Interval)에서의 Reference 여부는 알 수가 없다.
- 또한, 한 Interval 내에서는 정확히 언제 Reference가 이루어졌는지를 판별할 수 없는 구조이다.
(즉, Aging 방법은 Granularity가 떨어지는 방법이다.)

- Page 0 ~ Page 5들은 저마다의 Shift Register를 갖고있으며,
매 Interval마다의 R Bit값은 그림의 상단에 보여지는바와 같다.
- 즉, tick 0 (그림의 (a))에서는 Page 0~5의 R Bit이 각각 1, 0, 1, 0, 1, 1인 것이다.
R Bit들은 각각의 Page들이 보유한 Shift Register의 MSB에 삽입된다.
- (a), (b)에서 Page 2와 Page 5는 같은 Register값을 가졌음을 볼 수 있다.
하지만 두 Page가 동시에 Reference되었을리는 만무하다.
즉, Aging 방법에서는 "한 Interval" 내에서 어떤 Page가 먼저 Reference되었는지 까지는 확인할 수 없다.
The Working Set Page Replacement Algorithm
* Temrs
| Term | Description |
| Demand Paging | - Page Fault가 발생하고 나서야, Page를 Frame에 Loading하는 방식을 의미한다. |
| Locality of Reference | - 프로세스들은 메모리 전체 영역을 고루 참조하는 것이 아닌, 전체 영역에서 극히 일부분만을 반복적으로 참조하는 성질을 의미한다. |
| Working Set | - 단위시간동안, 프로세스가 실제로 사용하고 있는 Page들의 집합이다. - 즉, Working Set이 전부 Frame에 Loading되어 있다면, 단위시간동안에는 Page Fault가 발생하지 않을 것이다. |
| Thrashing | - 부족한 Main Memory 용량으로 인해, Working Set이 Load되지 못해 Page Fault가 비정상적으로 빈번히 발생되는 현상을 의미한다. |
| Working Set Model | - Process의 Working Set이 Main Memory에 Load되어 있도록 유지하는 모델이다. - 시간에 따라 변화되는 Working Set을 면밀히 추적해야 한다. |
| Prepaginig | - Page Fault가 발생하기 이전에, Access할 가능성이 높은 Page를 미리 Frame에 Loading하는 방식이다. - Demand Paging과 반대되는 개념이다. |
※ Demand Paging이 정상적으로 동작하는 이유는 Locality 때문이다.
1) Temporal Locality
- Reference가 발생된 메모리 영역은 빠른 시간내에 다시 Reference될 가능성이 높음을 의미한다.
2) Spatial Locality
- Reference가 발생된 메모리 영역 인근의 메모리들에 대한 Reference가 발생될 가능성이 높음을 의미한다.
Example. Typical Workload Characteristic

- 가로축은 시간, 세로축은 메모리 영역을 의미한다.
- 즉, 가로선에 해당되는 메모리 영역(Reference가 지속적으로 이루어지는 메모리 영역)은 Working Set임을 의미한다.
Formal Definition of Working Set

- Working Set Window \(w(k, t)\) : 시간 \(t\)가 흐를 동안, \(k\)회의 Memory Reference에 대응되는 Page들의 집합
(이 때, \(k\)를 Working Set Window라 한다.)
- 즉, \(k\)를 무한대로 증가시키는 것은, 프로그램의 시작 부분부터 Reference된 모든 Memory들에 대한 Page들을
Working Set으로 간주하는 것을 의미한다.
- 즉, \(k\)값을 적절히 설정하는 것이 Working Set을 정의하는데 가장 중요한 요인이다.
- Replacement가 필요한 경우, Working Set에 해당되지 않는 Page들 중 하나를 선정하여 Replacement한다.
- Working Set에 해당되는 Page들은 반드시 Main Memory에 Load되어 있어야 한다.
그렇지 않은 경우, Thrashing(Heavy Faulting)이 야기된다.
Example. \(w(k, t)\)

Working Set Approximation
- Working Set의 정의상, Memory Reference가 발생될 때 마다, 이를 Counting해야하는데, 이는 현실적이지 못하다.
- Working Set Window의 메모리 참조 횟수(\(k\))를 시간값(\(\tau\))으로 대체하여 Approximation한다.
- 즉, 시간 \(t\) 직전까지 이루어진 \(k\)회의 메모리 참조에 해당되는 Page들이 아닌,
\(t - \tau\) 부터 \(t\)까지의 구간에 해당되는 Page들을 Working Set으로 정의하는 방법이다.
- 이 때, Page별로 Memory에 Access할 때의 시간값을 기록해야 한다.
* Working Set Approximation Algorithm
- Page Fault가 발생되면, 해당 Process의 Page Table을 Scan한다.
- 특정 주기(Clock Interrupt)마다, R Bit은 Clear된다.
(R Bit = 1임은 현재 주기 내에 Memory Access가 수행되었음을 의미한다.)
- R Bit = 1이면, 현재 시각은 Page의 Time of Last Use 필드에 기록한다.
- R Bit = 0이면, 해당 Page의 Time of Last Use 필드에 기록되어 있는 시간값을 확인하여
현재 시각과 \(\tau\)의 범위내에 들어오는지를 확인한다.
이 범위에 들어오면 해당 Page는 Working Set으로 간주된다.
- Working Set에 속하지 못한 Page를 Replacement 대상으로 선정하고,
Scan되지 못한 Page들에 대한 Update를 계속한다.
- 만약, 모든 Page가 R Bit = 0이면서, Working Set으로 포함되어 있다 판정되면,
Time of Last Use 필드값이 제일 오래된 Page를 Replacement의 대상으로 선정한다.
- 만약, 모든 Page가 Working Set에 포함되어 있고, 모든 Page의 R Bit = 1인 경우,
Replacement의 대상을 랜덤하게 선정한다.
(모든 Page들의 Time of Last Use 필드값이 같을 것이기 때문이다.)
Example. Working Set Approximation

- Fault가 발생한 현재 시각은 2204이다.
- 즉 위 그림에서 R Bit = 1인 Page들은 바로 이전 Clock Cycle에서 현재 시각 2204 사이에
한 번 이상의 Memory Reference가 발생된 Page들이다.
- 각 Page Table의 Field들에는 R Bit = 1이자,
Clock Interrupt 혹은 Fault가 발생했을 때의 시간값(Time of last use)들이 기록되어 있다.
- Page Table을 Scan하며, R Bit = 1인 Page들의 Time of last use 값에 2204을 저장하고, R Bit = 0으로 설정한다.
- Page Table을 Scan하며, R Bit = 0인 Page들의 Time of last use 값이 2204와 \(\tau\) 값의 범위 내에 들어오는지를 판별한다.
- 범위 내에 들어온다면, Working Set에 있는 Page이므로, Replacement하지 않고,
범위 내에 들어오지 못한 경우, Replacement 대상으로 간주한다.
- 새롭게 Replacement가 된 Frame에는 현재시간 2204가 기록되고, R Bit = 1로 설정될 것이다.
ex) \(\tau = 700\)인 경우, Time of last use 값이 1213인 4번째 Page는 tau의 범위내에 들어오지 못해,
Working Set이 아니라 간주하고, Replacement 대상으로 삼는다.
ex) \(\tau = 700\)인 경우, Time of last use 값이 1620인 마지막 Page는 tau의 범위내에 들어오므로,
Working Set이라 간주한다.
* Working Set Clock Page Replacement Algorithm

- Page Frame에 대한 Circular List를 구성하고, Fault가 발생하면, Clock Hand가 가리키는 Page를 확인한다.
- 이 때, 지목당한 Page의 R Bit을 검사한다.
i) R Bit = 1이면, R Bit을 0으로 설정하고, Time of Last Use를 기록하고, 다음 Page로 Clock Hand를 이동시킨다.
ii_ R Bit = 0이고 Time of Last Use가 \(\tau\)의 범위에 들어오면, Working Set이라 간주하고, 다음 Page로 Clock Hand를 이동시킨다.
iii) R Bit = 0이고 Time of Last Use가 \(\tau\)의 범위에 들어오지 못하고, M = 0 이면 (Clean Page이면)
해당 Page를 Replacement하고,
iv) R Bit = 0이고 Time of Last Use가 \(\tau\)의 범위에 들어오지 못하고, M = 1 이면 (Dirty Page이면)
Disk에 해당 Page의 내용을 백업할 것을 명령하고, 다음 Page로 Clock Hand를 이동시킨다.
- Clock Hand가 Replacement할 대상을 찾지 못하고, Starting Point로 다시 되돌아왔을 경우, 아래와 같은 경우로 해석이 가능하다.
i) 하나 이상의 Dirty Page가 Disk에 백업 연산(Write Op)을 진행중인 경우,
백업 연산이 끝날 때 까지(Clean Page가 생길 때 까지) 계속 진행하여, 새로 생긴 Clean Page를 Replacement한다.
ii) 모든 Page가 Working Set에 포함되어 있는 경우, Clean Page 중 하나를 Replacement한다.
만약, Clean Page가 없다면, 현재 Clock Hand가 가리키고 있는 Page를 Replacement한다.
3.5 Design Issues For Paging Systems

Local Allocation Policy (Fixed Space Algorithm)
- 프로세스마다 일정량의 Frame을 분배하고, 각 프로세스는 할당량 만큼의 Frame만 사용하는 형태를 의미한다.
(즉, 프로세스가 보유하고 있는 Frame의 양이 고정적이다.)
- Algorithm을 진행하던 도중, Page Fault가 발생되면,
프로세스는 자신이 가진 Frame 중 하나를 선정하여 Replacement한다. (Local Replacement)
- Frame을 충분히 할당받지 못한 프로세스는 적절한 조치가 필요하다.
- Working Set Algorithm은 기본적으로 Local Allocation Policy하에 운용되는 알고리즘이다.
Global Allocation Policy (Variable Space Algorithm)
- 프로세스가 전체 Frame 영역을 모두 사용 가능한 형태를 의미한다.
(즉, 프로세스가 보유하고 있는 Frame의 양이 가변적이다.)
- 특정 프로세스의 Working Set의 크기가 커짐에 따라,
다른 프로세스들에 Frame이 충분히 할당되지 못하는 경우에 대한 적절한 조치가 필요하다.
(이에 대한 Solution로, PFF를 이용하는 방법이 있다.)
- 일반적으로, Local 방식보다는 Global 방식이 효율적이다.
※ FIFO, LRU 알고리즘은 Local 혹은 Global 방식 중 하나를 선택할 수 있고,
Working Set 알고리즘은 Local 방식에 기반하고 있다.
Page Fault Frequency (PFF) = Fault Rate

- Fault Frequency에 대한 두 Threshold 값 A, B를 설정하여,
Fault Frequency이 상한선(A)보다 높으면, 해당 프로세스에 Frame을 더 할당한다.
이 때, Frame은 Fault Frequency가 하한선(B)보다 낮은 프로세스로부터 조달한다.
- Fault Frequency이 하한선(B)보다 낮으면, 다른 프로세스에 Frame을 양도하는 것을 허용한다.
- Page Replacement Algorithm은 Local Policy를 적용한다.
※ FIFO에서는 Frame을 더 할당한다 해도, Fault Frequency가 낮아진다는 보장이 없다. (By Belady's Anomaly)
* Load Control
- 모든 프로세스의 PFF가 상한선(A)을 초과한 경우(절대적인 Main Memory의 크기가 부족한 경우),
현재 Ready중인 프로세스와 Running중인 프로세스를 모두 구동하기가 힘든 상황이므로,
Main Memory에 Load된 Process를 다시 Disk에 저장하는 조치이다.
Trade Off of Page Size
i) 작은 Page Size
- Internal Fragmentation이 감소한다.
- Paga Table의 크기가 커진다.
- 하나의 Page가 커버하는 메모리 영역이 작아서, Page Fault의 발생 빈도가 증가한다.
- TLB의 Coverage가 작다. (Coverage = Page Size * # of Entries)
ii) 큰 Page Size
- Internal Fragmentation이 증가한다.
- Page Table의 크기가 작아진다.
- 하나의 Page가 넓은 영역을 커버하므로, Page Fault의 발생 빈도가 줄어든다.
- TLB의 Coverage가 크다. (Coverage = Page Size * # of Entries)
※ 또한, Page Size는 I/O 연산시, 최적의 Bandwidth에 맞춰주는 것이 필요하다.
(무조건 큰 Page Size가 I/O에 유리하지 않다.)
Separate Instruction and Data Spaces

- Instruction이 위치되는 Virtual Address 영역(I Space)과
Data가 Access되는 Virtual Address 영역(D Space)을 분리시키면,
Virtual Address Space가 두 배로 커지는 효과를 볼 수 있다.
Shared Pages

- 프로세스는 각자의 Address Space를 갖기 때문에 기본적으로 다른 프로세스의 Address Space에 접근할 수 없다.
- 스레드들은 한 프로세스내에서 Address Space를 공유하기 때문에 다른 스레드의 Address Space에 접근할 수 있다.
- Shared Page는 프로세스가 다른 프로세스의 Address Space에 접근하여 공유하게 하는 방법 중 하나이다.
Memory Mapped Files

- 프로세스의 Virtual Address Space를 File과 Mapping하는 형태이다.
Cleaning Policy
- Dirty Page들을 미리 Cleaning하는 방법이다.
3.6 Implementation Issues
4 Times when OS invloved with Paging (OS가 Paging에 관여되는 부분들)
1) Process Creation
- 프로그램의 크기를 결정짓고, Page Table을 생성하고 초기화한다.
- Swap Space또한 할당하고, 초기화한다.
2) Process Execution
- 새로운 프로레스를 위해 MMU를 Reset한다.
- TLB를 Flush한다. (프로세스가 구동되기 시작한 직후, TLB Miss가 많이 발생되는 이유)
- Special Register(Intel CR3 등)에 Paga Table의 시작 주소를 저장한다.
3) Page Fault Time
- Page Fault가 발생되면 Fault를 발생시킨 Virtual Address를 Special Register에 저장하고, Replacement한다.
- PC에 Fault를 발생시킨 Instruction의 주솟값을 저장한다.
4) Process Termination Time
- 할당된 Page Table과 Page들, Swap Area에 저장된 Virtual Image들을 Release한다.
Page Fault Handling
* Page Fault가 발생되면 이루어지는 일들
- Trap 명령을 통해 Kernel Mode로 Switching된다.
- General Register에 저장된 값들이 백업된다.
- Fault를 발생시킨 Virtual Page를 OS가 확인하고, Special Register에 저장시킨다.
- Address와 Protection의 Validity를 OS가 확인하고, Replacement Algorithm을 수행한다.
(이 때, 선정된 Frame이 Dirty하면, Disk에 Write하여 백업시킨 후, Frame을 반환시키고,
Disk로부터 새로운 Page를 Load하여 Frame에 할당한다.)
- PC에 Fault를 발생시킨 명령어의 주솟값을 저장한다.
- Fault를 발생시킨 프로세스가 Scheduled되면, Register 값들을 복원하고 CPU 점유를 시작한다.
Backing Store
* Swap Space
- 프로세스가 생성되고, 프로세스의 Image가 저장되는 Disk 영역을 Swap Space(Swap Area)라 한다.
- Page Fault가 발생하면, 해당 Page가 저장된 Disk의 Swap Space로부터 Frame으로 Loading한다.
- 이 때, 전체 Virtual Space 크기에 해당하는 Swap Space를 할당하지 않고,
Swap Space를 Text, Data, Stack로 나누어서 저장할 수도 있다.
- 32Bit 시스템의 경우, 전체 Virtual Space의 크기는 4GB이다. 4GB 전체를 사용하는 프로세스는 극히 드물다.
특히, Head에서 Stack 사이에는 많은 빈 공간이 존재한다.
- Page를 Disk에 저장할 때, 아래와 같이 Static하게 저장하는 방법과 Dynamic하게 저장하는 방법이 있다.

(a) Paging to a static swap area
- Swap Area의 시작 주소만 알고있으면, Swap Area에 대한 접근이 매우 쉽다. (Indexing 연산)
- 즉, 각각의 Frame들이 본인이 백업될 Swap Area 주소를 몰라도 된다.
- Frame에 Loading된 Swap area 부분을 Free시키지 못해, Disk의 공간이 낭비된다는 단점이 있다.
- 또한, 프로세스의 전체 Image가 모두 Swap Area에 Load되어야 한다.
(b) Backing up pages dynamically
- Frame에 Loading된 Page는 Disk의 Swap Area에서 Free시켜, Disk의 공간을 효율적으로 사용하는 방법이다.
- Dynamic하게 Disk에 백업하는 경우, 위 그림처럼 연속적으로 배치되어야할 이유가 없다.
(즉, Disk를 효율적으로 사용할 수 있다.)
- Disk map은 각각의 Frame들의 Swap Area 주소를 알고 있어야 한다.
- Page Fault가 발생했을 때, 해당 Page가 위치한 Disk의 Swap Area를 확인하기 위해 Disk map에 접근해야만 한다.
즉, Main Memory에 한 번 더 접근해야 한다.
(비교적, Disk 접근 연산에 소요되는 시간이 매우크기 때문에 실질적인 문제점이 되진 않는다.)
- 또한, Main Memory내에 Disk map을 위한 공간이 추가적으로 확보되어야 한다. (실질적인 문제점)
- 또한, Disk map을 구성하기 위해, 각 Page의 Disk Addess를 모두 저장되어 있어야 한다.
※ 프로세스가 Terminate되면, Page Table, Swap Area, Disk Map 모두가 Deallcation된다.
3.7 Segmentation

- Segmentation은 Paging과 유사한 Technique으로, 메모리를 Logical Unit으로 분할한다.
(이 때, Logical Unit은 Stack, Code, Heap 등이 있다.)
- Segmentation은 하나의 프로세스가 다수의 Virtual Space를 운영하는 구조이다.
- Segmentation은 위 그림과 같은 Logical Unit 각각에 하나의 Virtual Space를 할당한다.

- Virtual Space가 할당된 Logical Unit(=Object)들 또한 Main Memory에 Loading된다.
- 각각의 Obejct에 접근하기 위해서는 Segment의 번호와 Offset이 필요하다.
- Segmented Machine에서의 Virtual Address = <Segment #, Offset>
(즉, Virtual Address로부터 해당 Segment의 시작 주소를 알아내는 것이 중요하다.)
※ Paging System과 달리, Segmentation에서 각각의 Segment들은 크기가 다르다.
- Segmentation에서는 Swapping에서와 같이, 각각의 Segment에 Base/Limit Pair를 이용하여 구분지어지고,
Base/Limit Pair를 Table 구조로 저장해놓는다.
- Base Register에는 해당 Segment의 시작 주솟값이 저장되어 있고,
Limit Register에는 해당 Segment의 크기가 저장되어 있다.
(이 부분은 Swaaping System의 메커니즘과 정확히 일치한다.)
* Segment Lookups

- Segment 번호를 통해 Base Register에 저장된 값을 알아내고 이에, Offset 값을 더하여 Physical Address를 구하는 방식이다.
- 이 때, Limit Register에 저장된 값을 통해, Offset 값이 해당 Segment의 범위를 벗어나는지 확인한다.
(Segment간 Protection 구현)
* One Dimensional Memory

- 위 그림과 같은 One-Dimension Address Space의 경우,
어느 한 Logical Unit의 크기가 커지게 되면 다른 Logical Unit과의 충돌이 발생될 수 있다.
* Segmented Memory

- 각 Segment들은 크기가 증감되어도, One Dimensional Memory에서와 같은 충돌 문제가 발생하지 않는다.
* Pure Segmentation

- Pure Segmentation에서는 Segment들 사이의 잉여 공간으로 인한 External Fragmentation 문제가 존재한다.
- 이는 Memory Compaction 작업을 필요로하게 만든다.
- 즉, Segmentation은 Swapping System에서 프로그램의 크기가 메인 메모리의 크기보다 크면
Load가 불가능했던 문제를 "어느정도" 해결한 형태이다.
(그러나, Segmentation에서도 한 Segment의 크기가 메인 메모리의 크기를 넘어서면 Load될 수 없다.)
* Segmentation Advantages
1) Logical Unit(Object)의 크기 증감이 자유롭게 행해질 수 있다.
2) Segment의 메모리 상 위치가 변화되어도, <Segment #, Offset>와 같은 주소값은 변하지 않는다.
3) Segment Sharing과 Protection이 간단하다.
- Segment의 메모리 위치가 변화하거나, Segment의 크기가 변화해도,
해당 Segment의 Segment Table에서 해당 Segment의 Entry 하나만 수정하면 된다.
4) Compiler에 의한 Linking이 쉽고, Object들이 각자의 Virtual Address를 가지므로, 보다 높은 Modularity를 갖는다.
* Segmentation Problems
- Segmentation에는 Swapping System에서의 단점들이 모두 드러난다.
1) External Fragmentation 문제가 존재한다.
- Memory Allocation시에 빈 공간을 찾기위한 Overhead의 원인이 된다.
- 이를 해결하기 위해, Memory Compaction이 도중에 수행되어야 한다.
2) Segment에 대한 적절한 Memory Allocation이 어렵다.
3) 한 Segment가 통채로 Memory에 Load되어야 하는데, 이 Segment의 크기가 Memory의 크기를 초과하면 Load될 수없다.
* Paging vs Segmentation
| Consideration | Paging | Segmentation |
| 프로그래머가 해당 메커니즘을 숙지해야 하는가? |
No | Yes - 프로그래머가 Logical Entity를 구분해야 한다. |
| 얼마나 많은 Linear Address Space가 존재하는가? |
1 | Many - Logical Unit마다 Address Space가 할당된다. |
| Total Address Space가 Physical Memory의 크기를 초과할 수 있는가? |
Yes | Yes - 단, Segment의 크기는 Physical Memory의 크기를 초과할 수 없다. |
| Procedure와 Data가 구분되어 Protection되는가? |
No | Yes - Data와 Procedure에 각각 Segment를 할당하여 Protection을 제공할 수 있다. |
| 크기가 유동적인 Table을 쉽게 운용할 수 있는가? |
No - Virtual Address상에서의 충돌이 발생될 수 있다. |
Yes - Virtual Address상에서의 충돌이 발생될 염려가 없다. |
| Sharing이 가능한가? | No - Page Share가 가능은 하지만, 해당 Logical Unit에 연관된 모든 Page들을 Update해야 한다. |
Yes |
| 기술의 의의 | - Physical Memory보다 큰 메모리 영역을 사용할 수 있게 되었다. - 메모리 관리가 쉽다. - External Fragmentation이 없다. |
- 각각의 Logical Unit들이 Segment들로 구현되어 Sharing과 Protection이 쉽다. |
Paged Segmentation
- Paging System과 Segmentation System을 결합한 형태이다.
- Segment는 Logically Related Unit으로 Stack, File, Module, Heap등이 Segment에 해당된다.
- Segment들의 크기는 제각기 다르며, 일반적으로 한 Page보다 크기가 크다.
- Page는 하나의 Segment를 고정된 크기로 분할한 형태이다.
* Paged Segmentation Advantages
- Paging System과 Segmentation System의 장점이 서로 취합된다.
1) External Fragmentation 문제가 없다.
- Segment들이 Page로 분할되었기 때문이다.
2) 한 Segment의 크기가 Physical Memory의 크기를 초과할 수 있다.
- 필요한 Page만 그 때 그 때 Page Fault를 발생시켜 Physical Memory에 Load하면 되기 때문이다.
* Paged Segmentation Disadvantages
1) Segment가 Page 단위로 분할되므로, Internal Fragmentation이 존재할 수 있다.
2) Memory에 Access하는데 Overhead가 증가된다.
- Physical Memory에 접근하기 전, Segment Table에 접근해야 하기 때문이다.
- 그래서 TLB의 중요성이 더욱 강조된다.
* 34Bits MULTICS System Virtual Address Space

- MULTICS 시스템에서는 한 프로세스가 \(2^{18}\)개의 Segment를 가질 수 있었다.
- 각 Segment의 크기는 \(2^{16}\) = 64KB이었고, 각 페이지는 \(2^{10}\) = 1KB이었으며,
각 Segment에 이러한 페이지가 \(2^6\) = 64개 존재할 수 있었다.
* Paged Segmentation Mechanism
- Paged Segmentation 시스템에서 Physical Address로의 변환 과정은 아래와 같다.

- 32Bits System에 \(2^{10}\)개의 Segment, 각 Segment에 \(2^{10}\)개의 Page, 각 Page의 크기는 12Bits라 가정하자.
(즉, Segment의 최대 크기는 \(2^{22}\) = 4MB이다.)
1) Segment Number(#)과 Segment Table PTR(Table 시작 주소; PA형태)을 이용하여 Segment Table에 접근한다.
- 여기서, Segment Table PTR에 값이 할당이 안 되어 있는 경우는, Page Table이 생성되지 않았음을 의미하고,
이는 Segment Fault 상황이므로, Page Table을 생성하기 시작한다.
2) Segment Table로부터 해당 Segment의 크기와 Base 값을 리턴받는다.
- 이 때, Base 값은 해당 Segment의 물리주소가 아닌, Page Table의 시작주소(PA형태)이다.
3) Base 값(해당 Segment의 Page Table 시작 주솟값)과 Page Number(#)을 통해 Page Table Entry에 접근한하여,
Page Frame Number(#)를 리턴받는다.
4) 도출된 Page Frame #에 Offset을 붙여 Physical Address를 완성시킨다. (Page Frame을 할당한다.)
- 즉, 해당 Segment의 해당 Page가 Frame에 Loading된다.
- Segmented Paging에서 Segment Table과 Page Table의 크기는 구현에 따라 달라질 수 있지만,
Segment Table의 크기는 최대 Segment 개수에 맞게,
Page Table의 크기는 최대 Page 개수에 맞게 생성하는 것이 일반적이다.
- Segmented Paging에서도 Paging System과 같이, Paga Table에 접근, Physical Memory에 접근
총 두 번의 메모리 접근이 필요하기 때문에, 마찬가지로 TLB의 적절한 활용이 중요하다.
* TLB for Paged Segmenation in MULTICS System

Example. Segmentation with Paging in Intel Pentium System

Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)