
Chapter 4. File Systems
* Long-Term Information Storage의 자격요건
1) 대량의 Data를 저장할 수 있어야 한다.
2) Persistent한 Data. 프로세스가 Data를 사용한 이후 혹은 System의 Power가 Off되어도 Data가 보존되어야 한다.
3) 여러 프로세스들이 동시에 Access하기에 편리해야 한다.
- 위 조건들을 충족시키기 위해, "File System"이라는 개념이 등장했다.
- File들은 Disk에 저장되며, Disk는 Linear Sequence of Fixed-Size Block이다.
(Block 단위로 Read/Write이 가능하다.)
Files
File Naming
- File의 명명법은 System마다 상이하다.
* Typical File Extension (전형적인 파일 확장자)

- UNIX에서는 파일 확장자를 지정하지 않아도 오류가 없는 경우가 많지만,
Windows에서는 파일을 선택하면 해당 확장자를 통해 맞는 프로그램을 고르기 때문에 오류가 생길 수 있다.
File Structure
* Byte Sequence
- File을 Sequence of Byte로하는 구조이다.
- File의 의미는 Application의 해석 방법에 따라 달라진다.
- UNIX와 Windows가 채택한 File 구조이다.
- File에서 Address될 수 있는 최소 단위는 Byte이다.
* Record Sequence
- File을 Fixed-Length Record로 하는 구조이다.
- 과거, Mainframe에서 사용했던 File 구조이다.
* Tree
- File을 Tree로 표현하는 구조이다.
- Record Sequence와 마찬가지로, 과거 Mainframe에서 사용했던 File 구조이다.
File Type
- File의 유형은 시스템마다 다양할 수 있지만, 일반적으로 Directory와 Regular File로 구분된다.
* UNIX에서는 Character Special File과 Block Special File이 존재한다.
- Device는 크게 Character Device와 Block Device로 나뉘는데,
Character Device는 키보드나 네트워크로부터 들어오는 Stream Data를 처리하는 Device이고,
Block Device는 디스크와 같이 Data를 Block 단위로 처리하는 Device이다.
- 즉, Character Device로부터 처리되는 Data가 저장되는 File이 Character Special File이고,
Block Device로부터 처리되는 Data가 저장되는 File이 Block Special File이다.
* Regular File
- 보통, ASCII File 혹은 Binary File을 의미한다.
- Binary File은 Execution File 등을 의미한다.
File Access
* Sequential Access
- Byte 순서대로 읽으며 접근하는 방식이다.
- 최적화가 쉽다.
* Random Access
- Byte Sequence에 무작위로 접근하는 방식이다.
- 주로 DB System에서 택하는 방식이다.
- 최적화가 힘들다.
File Attribute
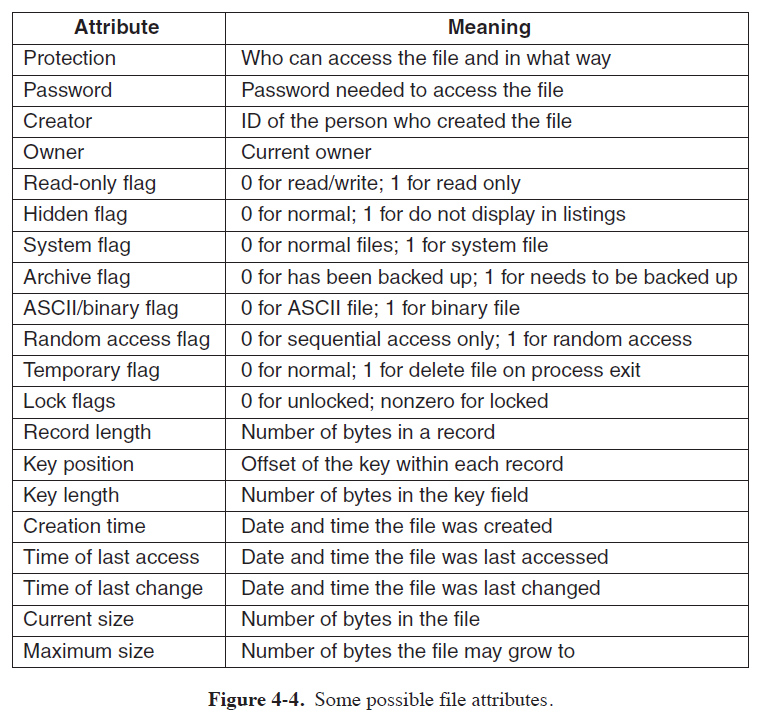
Basic File Operation
| Create | Delete | Open | Close |
| Read | Write | Append | Seek |
| Get Attribute | Set Attribute | Rename |
| File Operation in UNIX | Description |
| create(name) | |
| open(name, mode) | |
| read(fd, buf, len) | |
| write(fd, buf, len) | |
| sync(fd) | - Caching중인 파일영역과 Disk에 저장된 파일영역의 데이터를 동기화시키는 연산이다. |
| seek(fd, pos) | - File Read/Write시, 읽는 Disk 영역의 시작점을 지정하는 연산이다. |
| close(fd) | |
| unlink(name) | |
| rename(old, new) | |
| fcntl(fd, cmd, *lock) | - File Control |
File System Call Example
copyfile abd xyz위와 같은 File Operation을 수행할 때 실행되는 코드는 아래와 같다.
/* File copy program. Error checking and reporting is minimal. */
#include <sys/types.h> /* include necessary header files */
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]); /* ANSI prototype */
#define BUF_SIZE 4096 /* use a buffer size of 4096 bytes */
#define OUTPUT_MODE 0700 /* protection bits for output file */
int main(int argc, char *argv[])
{
int in_fd, out_fd, rd_count, wt_count;
char buffer[BUF_SIZE];
if (argc != 3) exit(1); /* syntax error if argc is not 3 */
/* Open the input file and create the output file */
in_fd = open(argv[1], O RDONLY); /* open the source file */
if (in_fd < 0) exit(2); /* if it cannot be opened, exit */
out_fd = creat(argv[2], OUTPUT MODE); /* create the destination file */
if (out_fd < 0) exit(3); /* if it cannot be created, exit */
/* Copy loop */
while (TRUE) {
rd_count = read(in_fd, buffer, BUF_SIZE); /* read a block of data */
if (rd_count <= 0) break; /* if end of file or error, exit loop */
wt_count = write(out_fd, buffer, rd_count); /* wr ite data */
if (wt_count <= 0) exit(4); /* wt count <= 0 is an error */
}
/* Close the files */
close(in_fd);
close(out fd);
if (rd_count == 0) /* no error on last read */
exit(0);
else
exit(5); /* error on last read */
}Directories
- File들을 Organize할 수 있게 하고, File들에 Namespace를 제공한다.
Single Level Directory Systems
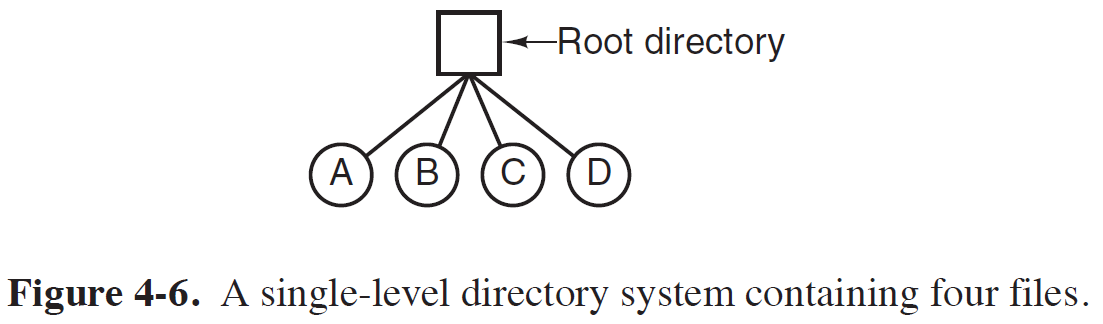
- Directory 개념이 없는 시스템이다.
- 아주 작은 시스템에서 채택하는 방식이다.
Hierarchical Directory Systems
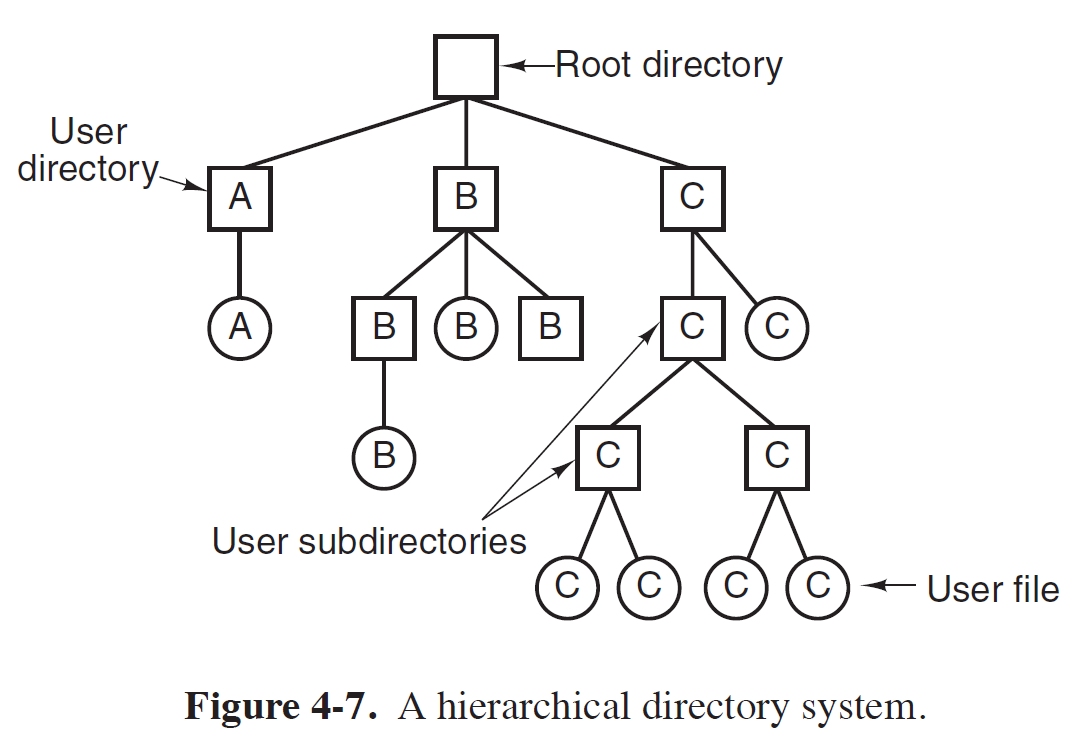
- Tree를 이용하여 FIle들을 계층적으로 구분하는 시스템이다.
- 대부분의 시스템이 채택한 방식으로, Multi-Level Directory로 구성된다.
- File을 지칭할 때에는 Slash(/)를 이용한 Path Name을 기술하여 지칭한다.
ex) /usr/local/bin
- Current Directory(Working Directory)는 .(한 개의 Dot)으로 표현하며,
Parent Directory는 ..(두 개의 Dot)으로 표현한다.
Path Name
- Absolute Path Name과 Relative Path Name으로 구분된다.
1) Absolute Path Name
- File System의 Root Directory부터 목적지 까지 전부를 기술한 Path Name이다.
ex) /usr/local/bin
2) Relative Path Name
- Current Directory를 기준으로 기술한 Path Name이다.
ex) bin (Current Directory에 bin Directory가 존재하는 경우 유효하다.)
Directory Operation
| Create | Delete | Opendir | Closedir |
| Readdir | Rename | Link | Unlink |
* Directory Internals
- Directory는 리스트로 구현되어 있다.
- List를 구성하는 Item은 File의 이름과, File Attribute로 구성되어 있다.
- Attribute는 Size, Protection, Location on Disk, Creation Time, Access Time 등이 될 수 있다.
File-System Implementation
File System Layout
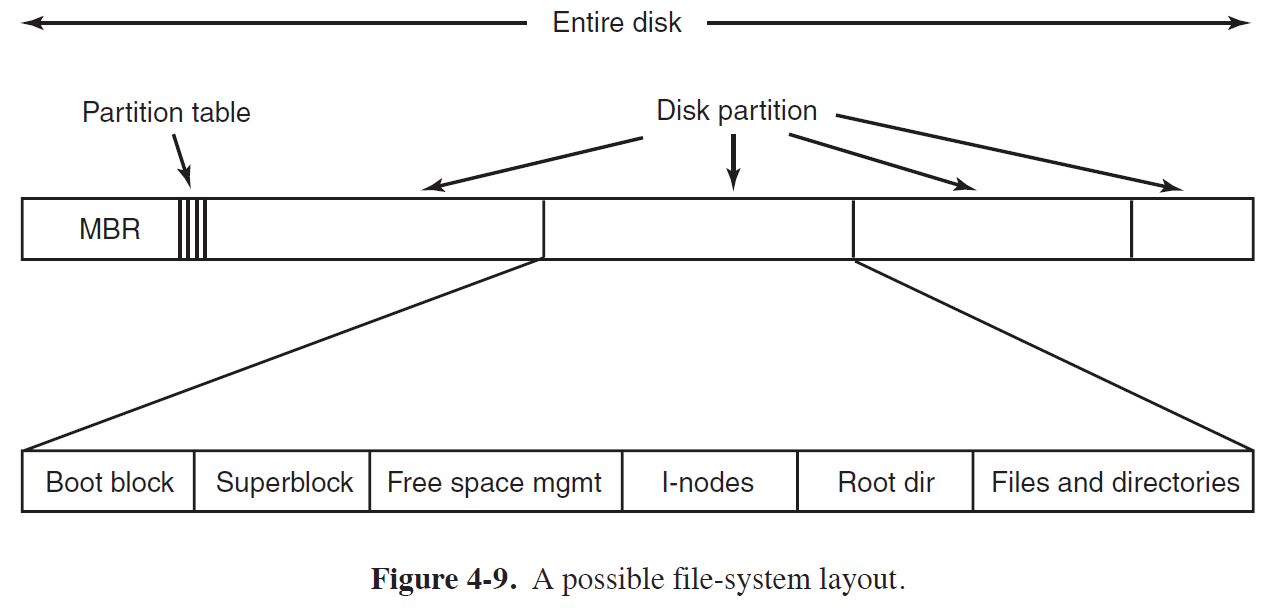
- Partition Table에는 각 Disk Partition의 정보가 저장되어 있다.
- 각 Disk Partition에는 위 그림과 같은 정보들이 저장되어 있으며, 이는 시스템마다 다를 수 있다.
| Disk Partition Component | Description |
| Boot Block | - 부팅시에 사용될 프로그램들이 저장되어 있다. |
| Superblock | - File System에 대한 Parameter들이 저장되어 있다. - Parameter에는 File System Type을 규정하는 Magic Number, Block의 개수 등이 해당된다. |
| Free Space MGMT (Management) | - Free된 Block된 정보들이 저장되어 있다. |
| I-Nodes | - File Attribute나 File의 Disk Address를 저장하고 있는 Node로, File당 하나의 I-Node를 갖고 있다. |
| Root DIR | - Root Directory에 대한 정보가 저장되어 있다. |
| Files and Directories |
* MBR : Master Boot Record
- 부팅에 사용된다.
- Partition Table에 대한 정보가 저장되어 있다.
* Partition Table
- 각 Partition들의 Starting Address와 Ending Address가 저장되어 있다.
- 어떤 Partition이 Active Partition인지에 대한 정보가 저장되어 있다.
* Boot Sequence
1) 시스템이 Power-On되면 BIOS가 수행되어 부팅에 사용될 Disk의 MBR을 읽는다.
2) MBR을 통해 Active Partition을 찾아내어 Boot Block에 있는 프로그램을 실행시킨다.
3) Boot Block에 위치한 프로그램은 OS가 저장된 Partition에서 OS를 Load시킨다.
Implementing Files
File Implementation #1 : Contiguous Allocation
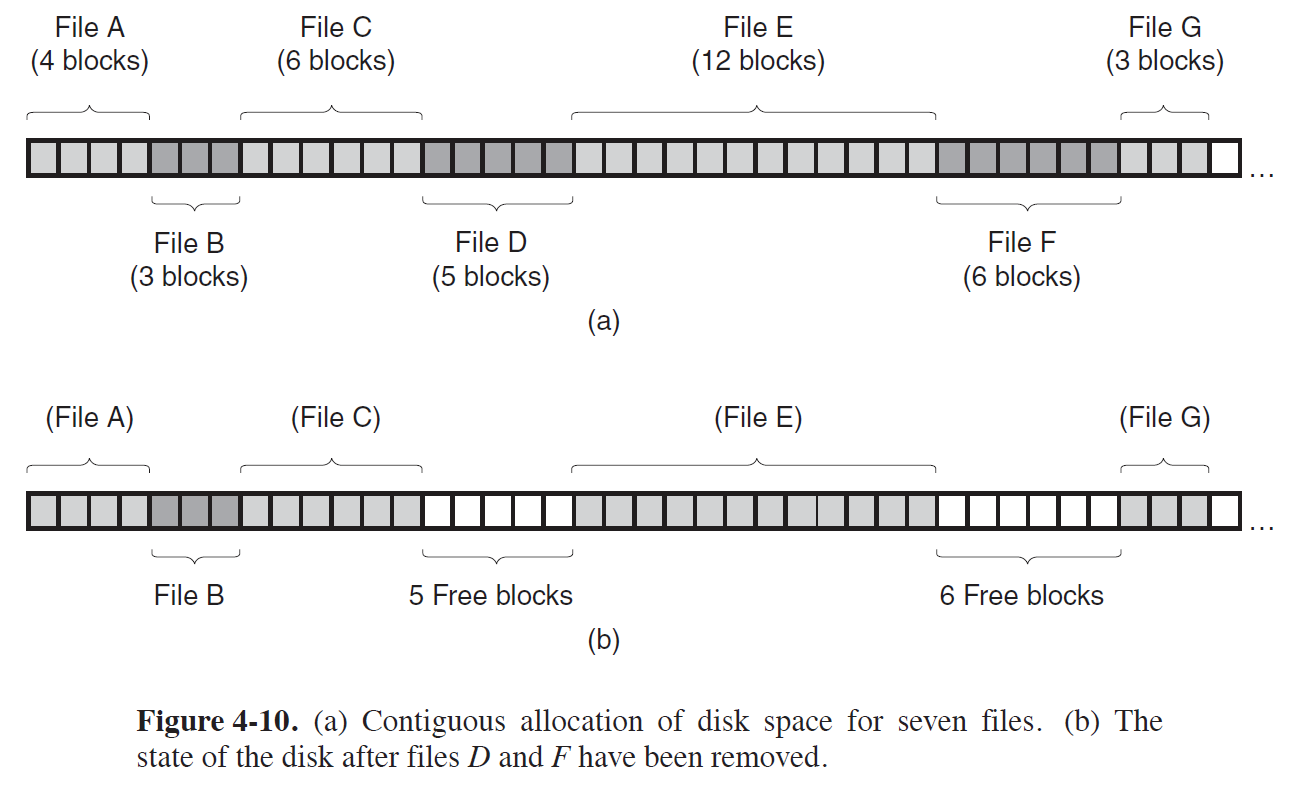
- 위 그림에서 각각의 사각형들은 Block을 의미한다.
- File은 Sequence of Block이며, Contiguous Allocation에서 File들은 연속된 Block들을 할당받는다.
- 이후에, File이 Delete되면, 해당 File이 차지하고 있던 Block들이 Free된다.
- 위 (b) 경우에서, 7개의 Block을 차지하는 새로운 FILE H는 현재상황에서 Allocation될 수 없다.
* Contiguous Allocation Advantage
1) File의 시작주소와 크기만 알면 되므로, Implementation이 간단하다.
2) Sequential Access를 수행하기 때문에 Read Performance가 우수하다.
* Contiguous Allocation Disadvantage
1) External Disk Fragmentation이 존재하여, Compaction 연산이 필요하다.
2) Internal Disk Fragmentation이 존재한다.
- Allocation Unit이 존재하는한, Internal Fragmentation은 존재할 수 밖에 없다.
* Contiguous Allocation Applicability
- Contiguous Allocation은 대개, 한 번 정해지면 변하지 않는 구조에 많이 이용된다.
1) CD-ROM
2) File Size가 미리 알려진 구조
3) File Size가 변하지 않는 구조
File Implementation #2 : Linked List Allocation
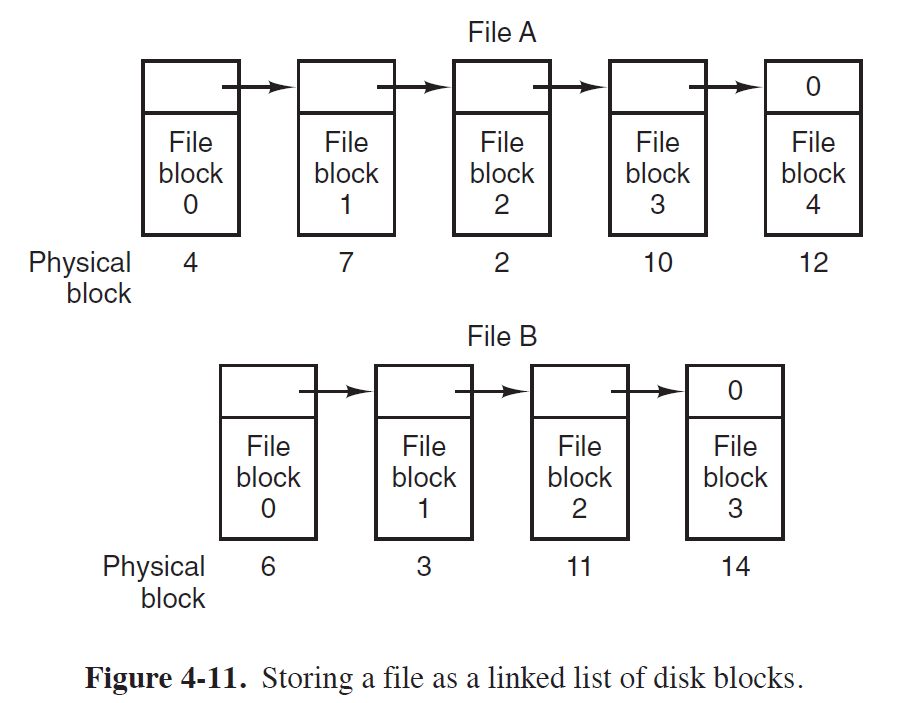
- Physical Block에 해당 File이 저장되어 있는 다음 Physical Block을 가리키는 포인터 필드를 포함시켜서,
Physical Block들이 논리적으로 Sequential하게 구현되도록 하는 방법이다.
- 위 그림처럼, File A와 B가 저장되어 있는 Physical Block들은 포인터 필드를 통해 논리적으로 연결되어 있지만,
실제로 각각의 Block들은 Physical Block들 사이에서 산개되어 있다.
* Linked List Allocation Advantage
1) Contiguous하게 Allocation할 필요가 없어, External Disk Fragmentation이 없다.
2) 빈 Block들이 크기에 상관없이 사용될 수 있다. (즉, 빈 Block들을 알뜰하게 사용할 수 있다.)
* Linked List Allocation Disadvantage
1) 포인터 필드로 File의 첫 Physical Block부터 접근해야하기 때문에
Sequential Access 혹은 Random Access 방식에서 속도 측면에서 불리하다.
- File의 중간부분에 접근하고자 한다 하더라도, File의 첫 부분부터 접근하여 포인터 필드를 통해 이동해야 하기 때문에
이로 인한 Overhead가 상당하다.
- Disk에 접근하는 것이기 때문에, Physical Block의 포인터 필드에 접근하는 연산은 모두 다 I/O연산임에 유의하자.
2) 각 Physical Block에 위치한 포인터 필드로 인해 추가적인 Physical Block이 필요할 수 있다.
3) Internal Disk Fragmentation이 존재한다.
- Allocation Unit이 존재하는한, Internal Fragmentation은 존재할 수 밖에 없다.
File Implementation #3 : Linked List Allocation Using a Table in Memory (FAT)

- File Allocation Table(FAT)에는 다음 Block의 인덱스 값이 저장되어 있다.
(FAT의 Index는 곧 Physical Block의 번호이다.)
ex) 어떤 File A는 4번 Block에 처음으로 할당되어 4 - 7 - 2 - 10 - 12와 같은 순서로 Block들에 할당되었음을 알 수 있다.
ex) 어떤 File B는 6번 Block에 처음으로 할당되어 6 - 3 - 11 - 14와 같은 순서로 Block들에 할당되었음을 알 수 있다.
- FAT Entry는 Block의 개수만큼 형성된다.
(즉, 최대로 생성할 수 있는 File의 개수는 FAT Entry의 개수와 같다. = 각 File들이 하나의 FAT Entry만 차지할 경우)
- FAT는 File System이 형성되면 Disk에 저장되어 있다가, Main Memory에 Mount(Load)되어 사용된다.
- FAT의 각 Entry에는 Cluster 혹은 Block에 대한 정보가 저장되어 있다.
- Starting Block의 번호는 File이 위치한 Directory Entry에 저장되어 있다.
- FAT은 Critical Resource이다. FAT이 한 Point라도 손상되면, File System에서의 Block 배치를 알 수 없게된다.
- 그러므로, FAT에 변화가 생길때마다 Disk에도 변화된 정보가 즉시 반영된다.
(Critical Resource이기 때문에 바로바로 백업해놓는 것이다.)
+) 그래서, FAT Storage는 컴퓨터에서 바로 제거해도 문제가 없을 수 있지만,
NTFS Storage는 컴퓨터에서 바로 제거하면 문제가 생길 수 있다.
* Cluster
- 연속된 Physical Block을 한 덩어리로 묶어 Addressing하는 것을 의미한다.
- 수많은 Block을 FAT이 모두 표현할 수 있게하기 위해 고안된 개념이다.
ex) 위 그림의 FAT은 16개의 FAT Entry를 가진다. 단, FAT Entry의 크기가 3Bits인 경우, 0~7까지밖에 표현하지 못하므로,
두 개의 Physical Block를 하나의 Cluster로 묶어 Indexing한다면, FAT이 모든 Entry를 커버할 수 있게 된다.
ex) FAT Entry의 크기가 3Bits인데, 32개의 Physical Block을 커버해야 한다면,
적어도 4개의 Physical Block을 하나의 Cluster로 묶어야 한다.
- FAT16 시스템의 경우, FAT Entry가 16Bits로 구성되어 최대 64K개의 Cluster를 Addressing할 수 있다.
(즉, FAT16에서 FAT Entry의 개수는 64K개이고, 최대로 생성할 수 있는 File의 개수도 64K개이다.)
- 즉, Cluster가 새로운 Allocation Unit이 된다.
- Cluster의 크기가 커질수록 Internal Fragmentation 문제가 발생될 가능성이 높아진다.
* FAT Advantage
1) FAT은 항상 Main Memory에 Load되어 있기 떄문에 Random Access가 빠르게 이루어진다.
2) Disk Access없이도, Block Address를 얻을 수 있다.
3) Directory Entry에는 Block의 시작 인덱스만 저장되어 있으면 된다.
* FAT Disadvantage
1) FAT은 모든 부분이 항상 Main Memory에 Load되어 있어야한다. 즉, Memory를 많이 차지한다.
- Block Size가 1KB인 200GB의 Disk의 FAT은 200M개의 Entry를 갖는다.
FAT32의 경우, 하나의 FAT Entry가 4Bytes의 크기를 가지므로, 이 시스템의 FAT은 800MB의 크기를 차지한다.
즉, Main Memory의 800MB가 항상 FAT이 차지하고 있게 된다.
File Implementation #4 : Index Node (I Node)
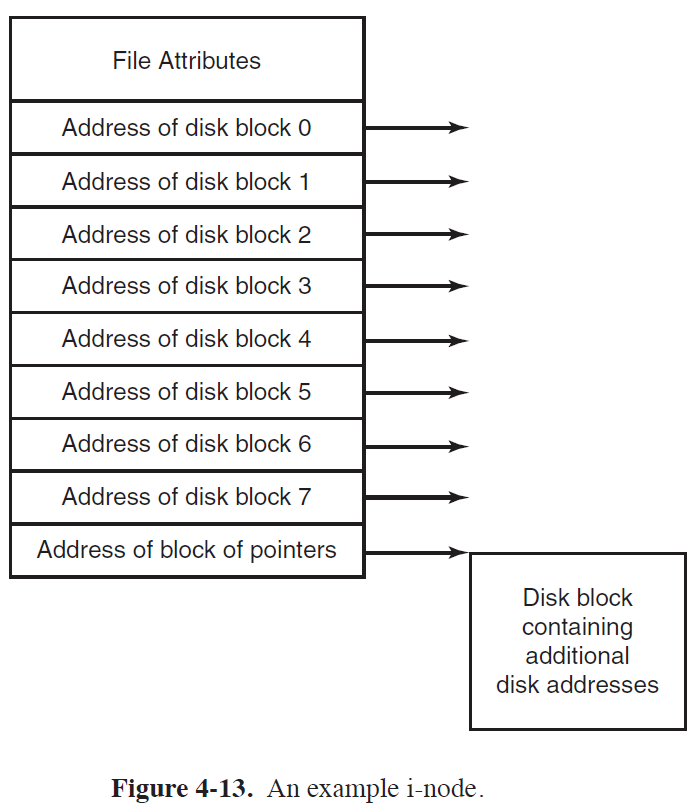
- 한 File당, 하나의 I Node가 할당된다.
- File이 생성되면, 빈 I Node가 할당되고, File에 Data가 쓰여지기 시작되면, Disk Block을 I Node에 할당하게 된다.
- File Attribute에는 File에 대한 정보들이 저장된다.
- File이 차지한 Disk Block들이 Array Structure처럼 순서대로 저장되어 있다.
- FAT와 달리, 시스템에서 FILE A에 접근하고자 하는 경우, A의 I Node만 Main Memory에 Load한다.
(FAT에서는 FAT가 상시 Main Memory에 Load된다.)
※ Main Memory는 Byte단위로 주소가 부여되고, Disk는 Block단위로 주소가 부여된다.
* 큰 File을 I Node 방식으로 커버하는 방법
- 1MB 크기의 File을 1KB 크기의 Block을 가진 I Node가 커버하려면, 1,024개의 Entry를 필요로하게 되고,
이는 I Node의 크기를 매우 비대하게 만드는 문제가 있다.
- 이러한 문제를, I Node 방식에서는 아래와 같이 해결한다.
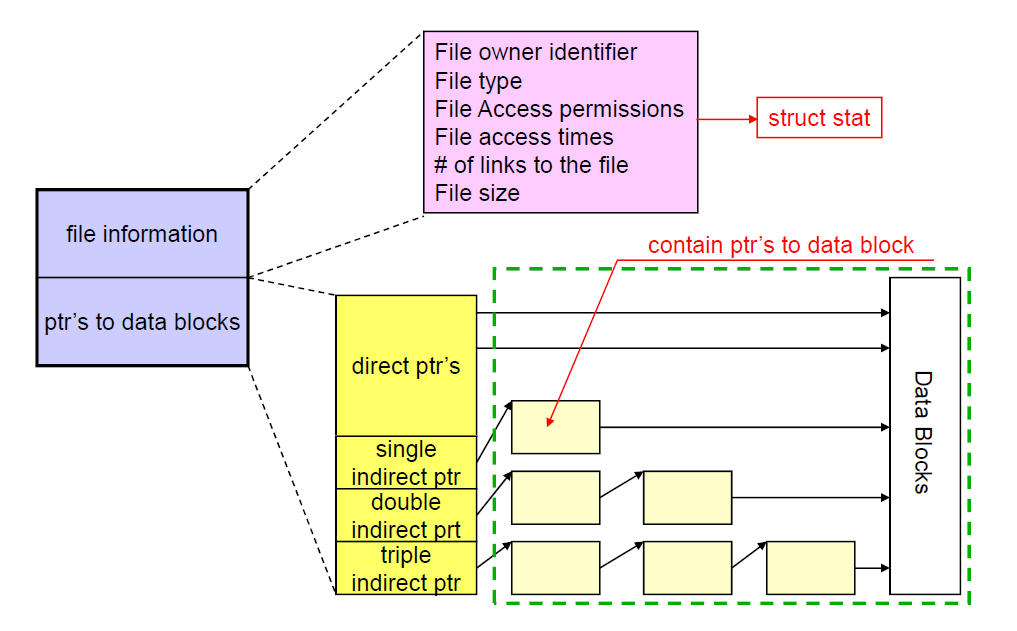
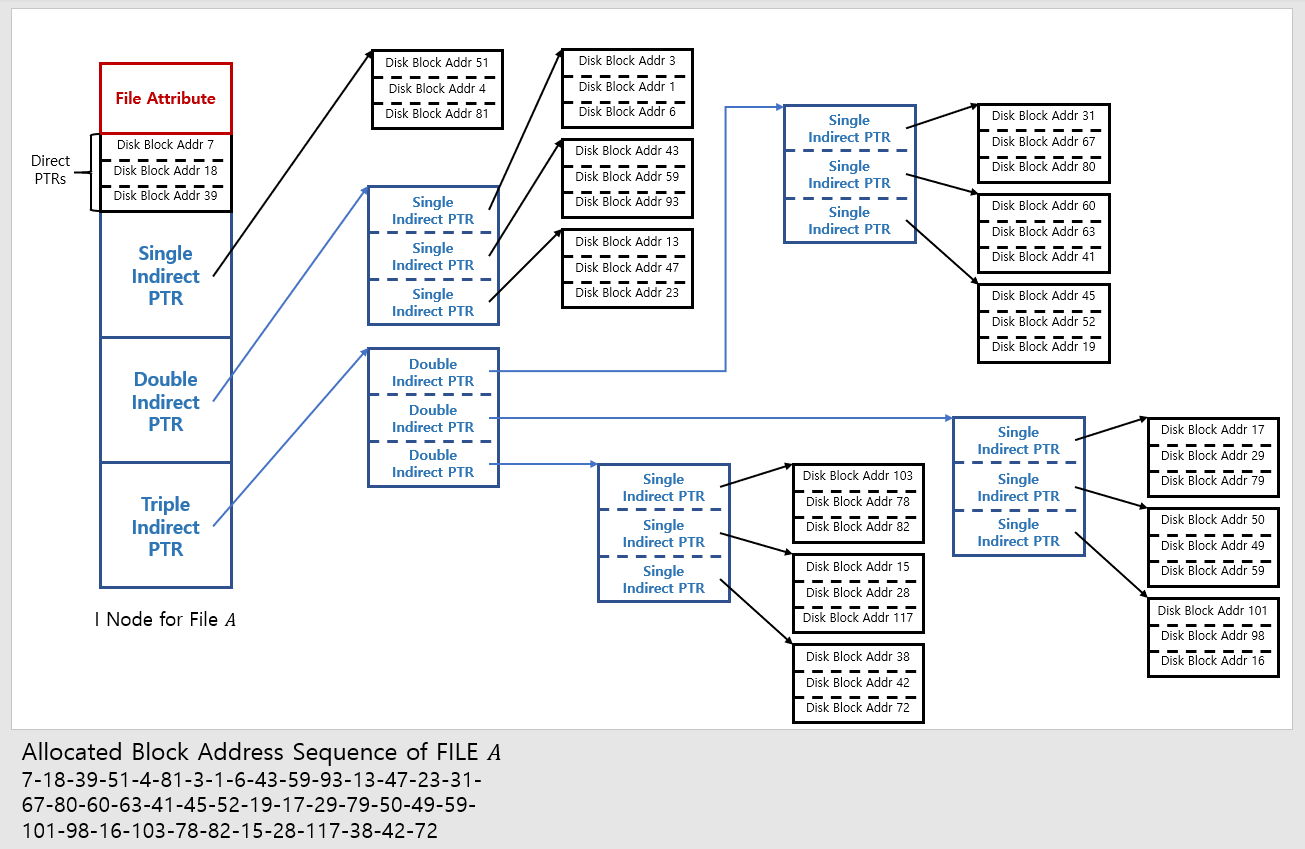
* 위 그림에서는 Single Indirect Pointer가 3개의 Block Address Array를 Pointing한다 가정한다.
Direct Pointer: 사용하고 있는 Block의 주소가 저장되어 있다. (즉, Block 주소를 직접적으로 Pointing하고 있는 포인터이다.)
Single Indirect Pointer: Direct Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
Double Indirect Pointer: Single Indirect Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
Triple Indirect Pointer: Double Indirect Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
\(\qquad\qquad \vdots\)
- I Node의 하나의 Entry가 Indirection을 통해, 여러 Block을 커버할 수 있게 하는 방법이다.
- Indiret Pointer의 계층이 심화될수록, 기하급수적으로 많은 Block들을 커버할 수 있게 되지만,
부가적인 Disk Access 횟수 또한 증가한다.
- I Node Entry의 Indirect 구조는 Designer의 재량이다.
(즉, 그림처럼 Single -> Double -> Triple일 필요는 없으며, 모든 Entry가 Double Indirect 형태일수도 있으며,
이외에 다른 여러가지 형태로 존재할 수 있다.)
Example. I Node in UNIX V7 File System
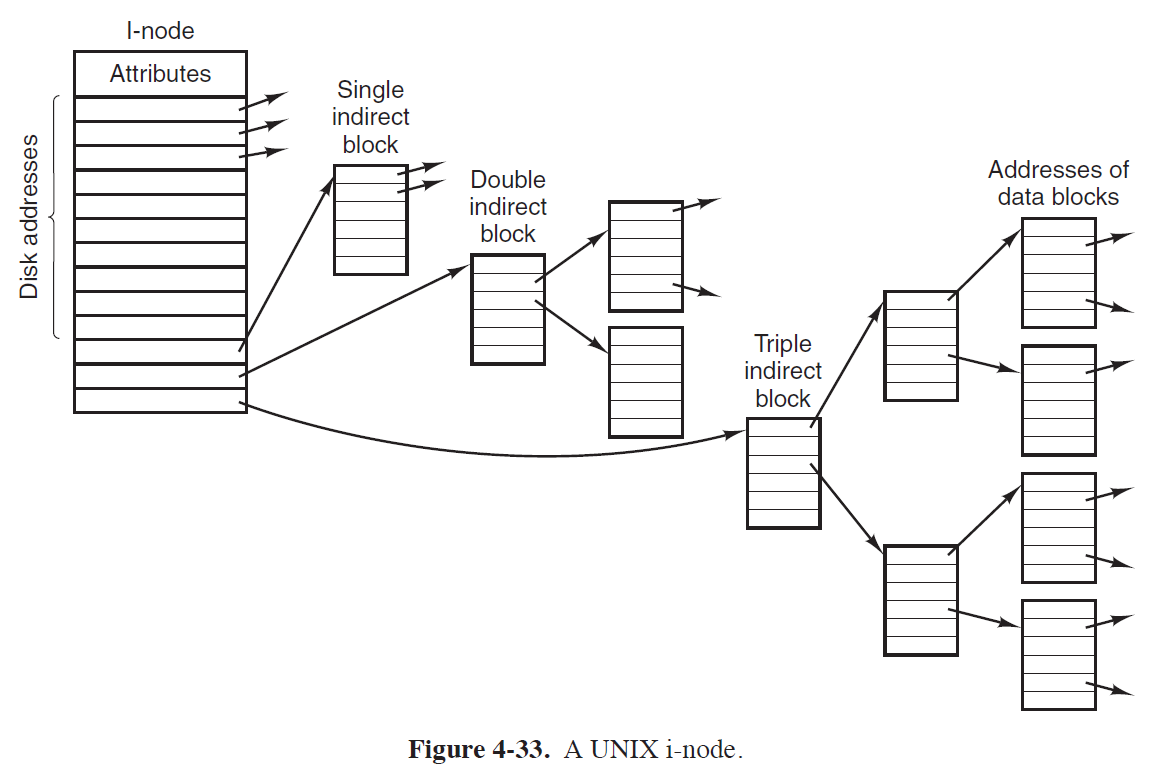
- 1KB Block에 Direct Pointer Size가 4Byte인 경우,
하나의 Pointer Field Entry가 1KB/4Byte(=256)개의 Disk Block 주소를 커버할 수 있다.
- 즉, 위 시스템에서 Single Indirect Block은 \(256^1\)개의 Disk Block 주소를,
Double Indirect Block은 \(256^2\)개의 Disk Block 주소를,
Triple Indirect Block은 \(256^3\)개의 Disk Block 주소를 커버할 수 있다.
- 따라서, 위 그림에서는 \(10 + 256 + 256^2 + 256^3\) 개의 Disk Block을 구분지을 수 있다.
Direct PTR 10개 = Disk Block \(10\)개
Single Indirect Pointer 1개 = Disk Block \(256\)개
Double Indirect Pointer 1개 = Disk Block \(256^2\)개
Triple Indirect Pointer 1개 = Disk Block \(256^3\)개
(Disk Block Size가 1KB인 경우, 위 I Node에 해당하는 File의 크기는
\(10 + 256 + 256^2 + 256^3\) * 1KB = 16.8GB 이다.)
* I Node Advantage
1) Main Memory를 효율적으로 사용할 수 있다.
- FAT과 달리, 접근하고자 하는 FILE의 I Node만 Main Memory에 Load시키기 때문이다.
* I Node Disadvantage
1)
Example. UNIX File System
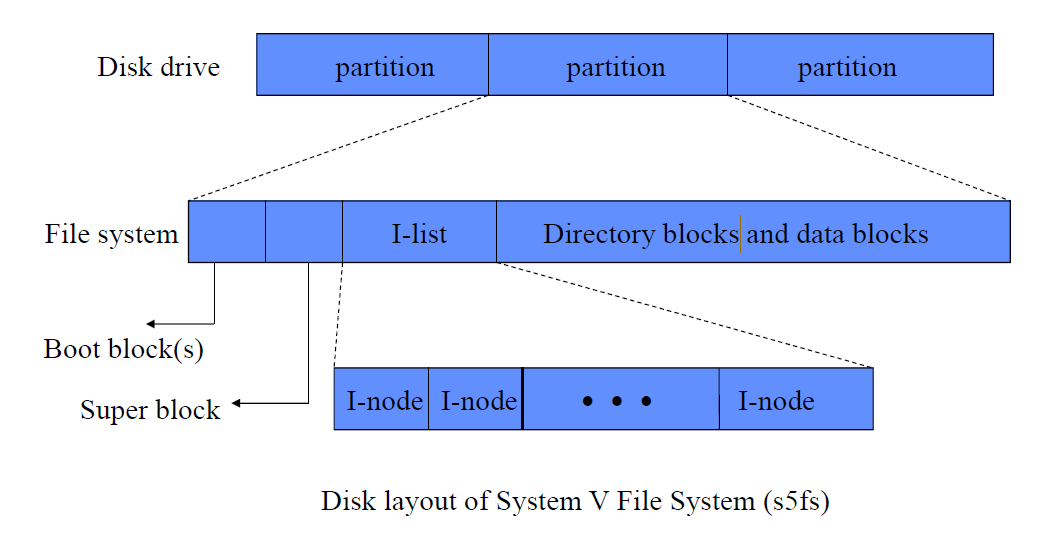
- Disk를 Partition으로 나누고,
각각의 Partition에는 Boot Block과 Super Block, I Nodes, Directory Block과 Data Block으로 구성된다.
1) Super Block
- File System에 대한 전반적인 정보가 저장되어 있다.
- File System의 크기, I-List의 크기,
Free Block의 개수, Free I Node의 개수,
Free Block List, Free I Node List,
다음에 할당할 Free Block의 Index, 다음에 할당한 Free I-Node의 Index 등이 저장되어 있다.
(Free Block, Free I-Node란, 사용되고 있지 않은 Block, I-Node를 의미한다.)
- 최대로 생성할 수 있는 File의 개수는 I Node의 개수에 관련되어 있다.
2) I-List
- 각 File들에 대한 정보(I Node들의 List)가 저장되어 있다.
- Array와 같은 Container Structure에 File이 사용하고 있는 Block 정보가 차례대로 연결되어 있다.
3) Directory Block and Data Block
- File의 이름과, File에 해당하는 I Node의 번호가 저장되어 있다.
- Directory Block과 Data Block 사이에 특별한 구분은 없다.
(Directory를 위한 내용이 있으면 Directory Block이고, File에 대한 내용이 있으면 Data Block이다.)
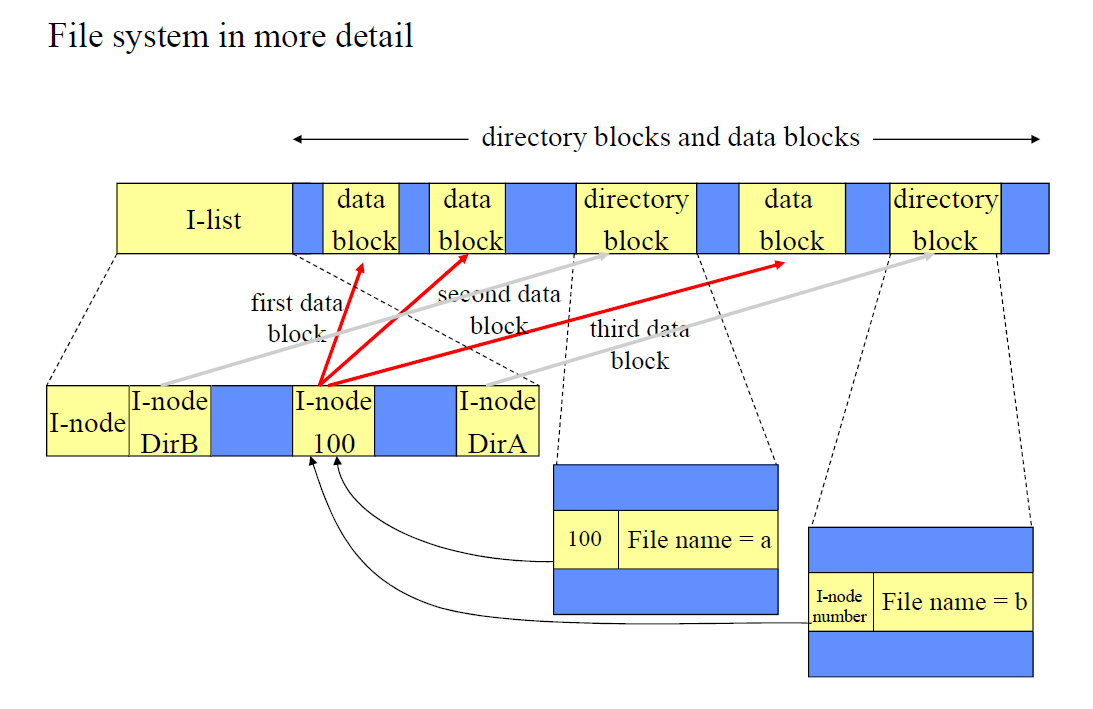
* Hierarchical Structre of File System
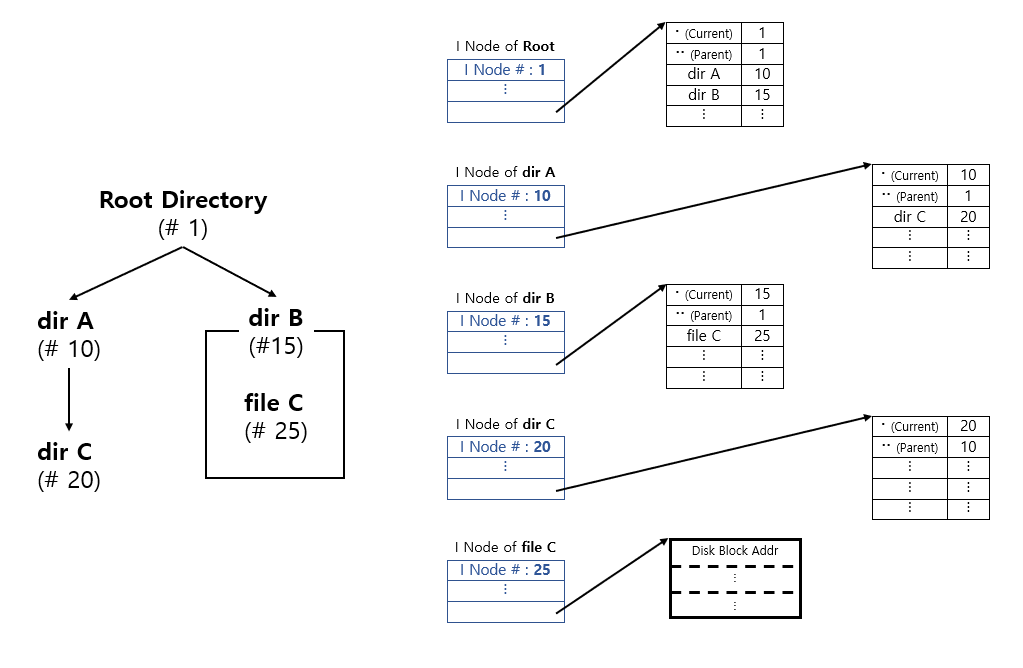
- 위 그림에서는 I Node가 Direct PTR들로 구성된다 가정한다.
- File과 Directory File에는 각각 하나의 I Node가 부여되어 있다.
- Directory File의 I Node가 지칭하고 있는 Disk Block에는
Parent File(..; Double Dot)의 I Node Number와
Current File(.; Single Dot)의 I Node Nume,
(Child File의 이름, 해당 Child File의 I Node Number) Pairs 정보가 저장되어 있다.
- File의 Path가 주어지면, Root Directory부터 Path를 참고하여, 해당 File의 I Node Number를 알아낸 다음,
해당 File의 I Node에 접근하여 데이터에 Access한다.
ex) Path : "/dirB/C" 를 통해 File C에 접근하면, Main Memory에는 25번 I Node가 Load된다.
- 또한, Path를 통한 접근 시, Path에 명시된 모든 File들의 I Node가 한 번씩은 Main Memory에 Load된다.
(즉, File Open시에는 꽤 많은 횟수의 Disk Access가 발생된다.)
* I Node Attribute: Link Count

- 한 File에 대해, 존재할 수 있는 Path의 개수이다.
- 예를 들어, 하나의 File에 접근할 수 있는 Path의 수가 4이면, 해당 File의 I Node의 Link Count 값은 4이다.
- Link Count는 다른 경로가 발견될 때 마다 1씩 증가한다.
(File System Tree를 모두 순회하며 Link Count를 계산하지 않는다.)
- 예를 들어, Directory A에 하위 Directory(Child Directory) B가 생생되면,
Directory B의 I Node에 Parent Directory A의 I Node #이 기록되므로,
Directory A의 Link Count가 1 증가하게 된다.
(하지만, Directory가 아닌, File이 생성될 땐 Parent Directory의 Link Count값에 변함이 없다.)
ex) 위 그림의 1267 Directory의 Link Count값이 3인 이유는
Current Directory(자기 자신)를 가리키는 Link,
Child Directory 2549에 존재하는 Link,
1267의 Parent의 Directory Block에 저장된 내용에 의해 지시되는 Link(그림에는 표현되지 않음)
때문이다.
※ Directory File의 Link Count값은 Child Directory가 생성될 때 마다 증가한다.
※ File의 Link Count값은 Directory Block내에 해당 File의 I Node #이 저장될 때 마다 증가한다.
(즉, 어떤 Directory에서 해당 File을 포함시킬 때 증가한다.)
Example. Open File in UNIX V7 File System
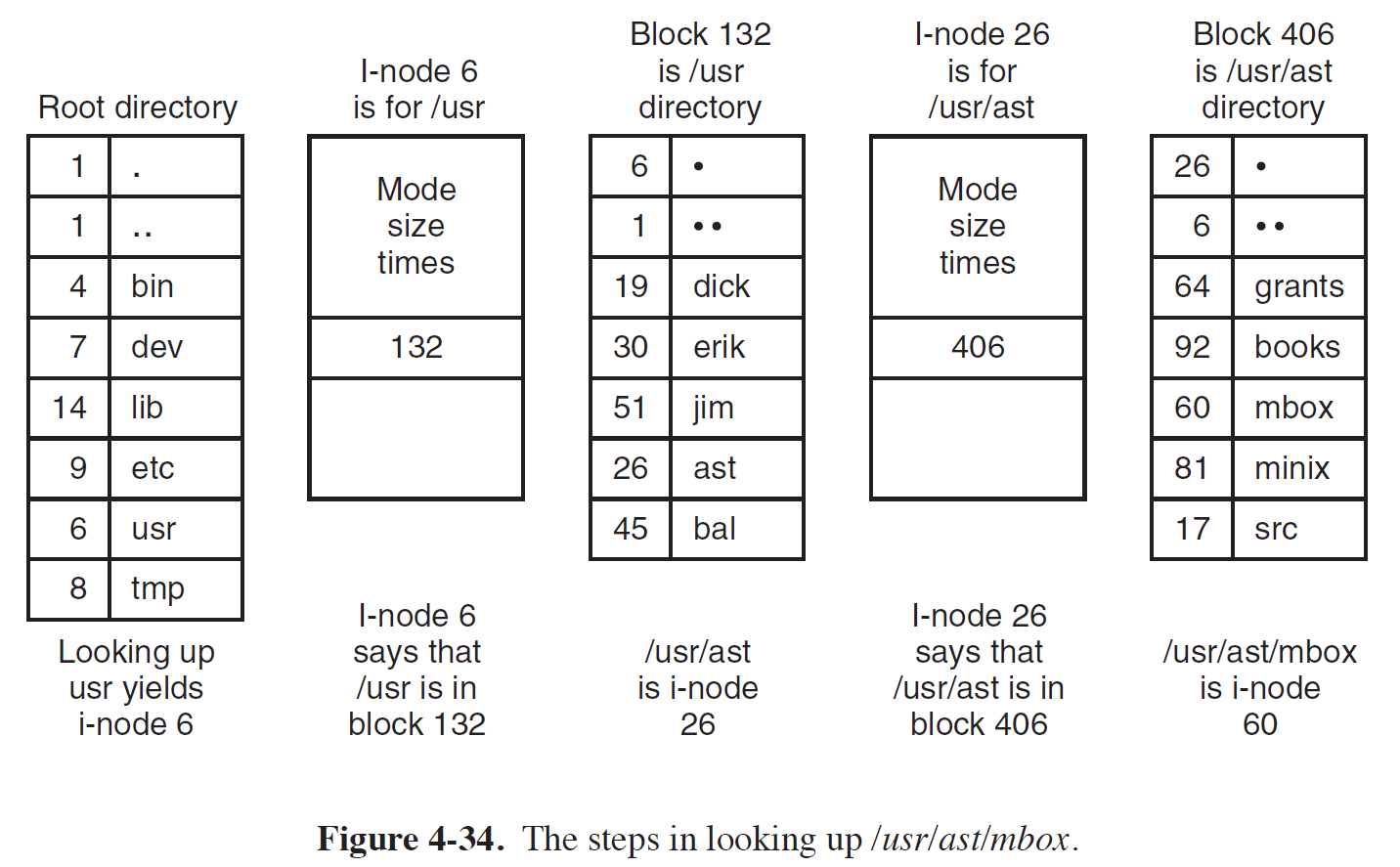
* 위 그림에서는 Root Directory의 I Node의 정보를 통해 Root의 Directory Block에 접근하는 것은 생략되었다.
- Root Directory에서 mbox File에 접근하기 까지의 Flow는 아래와 같다.
1) Root Directory의 I Node에 접근하여 Root Directory의 Directory Block에 접근 (그림에 없음)
2) Root Directory의 Directory Block에서 usr Directory의 I-Node #을 검색
usr Directory의 I-Node #은 6임을 알아내어 usr의 I-Node로 접근
3) usr I-Node로부터 usr Directory Block이 저장된 Disk Block Address 132를 통해 usr Directory Block에 접근
4) usr Directory Block에서 ast Directory의 I-Node #은 검색
ast Directory의 I-Node #은 26임을 알아내어 ast의 I-Node로 접근
5) ast의 I-Node로부터 ast Directory Block이 저장된 Disk Block Address 406을 통해 ast Directory Block에 접근
6) ast Directory Block에서 mbox 의 I-Node #을 검색
mbox의 I-Node #은 60임을 알아내어 mbox의 I-Node로 접근
Implementing Directories
- Directory Block에 (File 이름, File I-Node #) Pair를 저장지킬지,
I-Node #대신, I-Node의 모든 Contents(전체 File Attribute)를 다 저장시킬지는 구현에 따라 달라질 수 있다.
* I-Node가 저장하는 Contents = Size, Protection, Location on Disk(Direct PTR), Creation Time, Access Time, etc
- Directory List는 보통 Unordered 상태로 존재한다. (일반적으로, Sorting되어 있지 않다.)
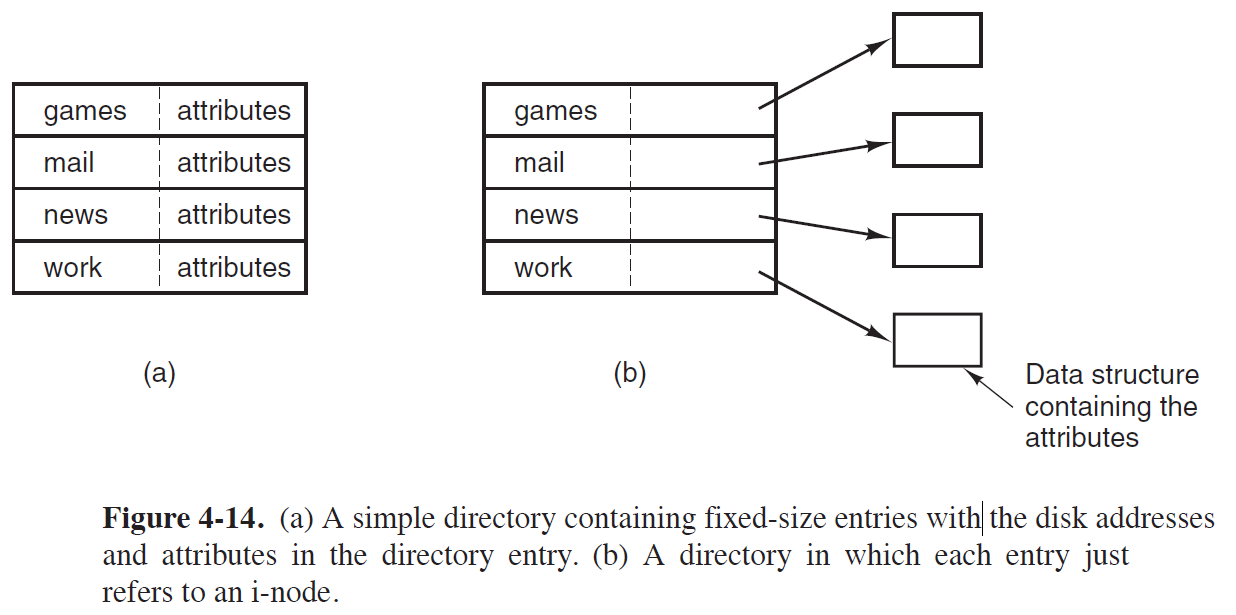
(a) Simple Directory
- Fixed Size Entries로 구성된다.
- Directory Entry에 Disk Address와 Attribute가 모두 저장되어 있는 구조이다.
- MS-DOS, Windows에서 채택한 방식이다.
(b) Directory with I-Node
- Fixed Size Entries와 I-Node Number(#)들로 구성된다.
- Disk Address와 Attribute는 I-Node에 저장되어 있고, Directory Block에는 I-Node #이 저장되어 있다.
- UNIX에서 채택한 방식이다.
Handling File Name
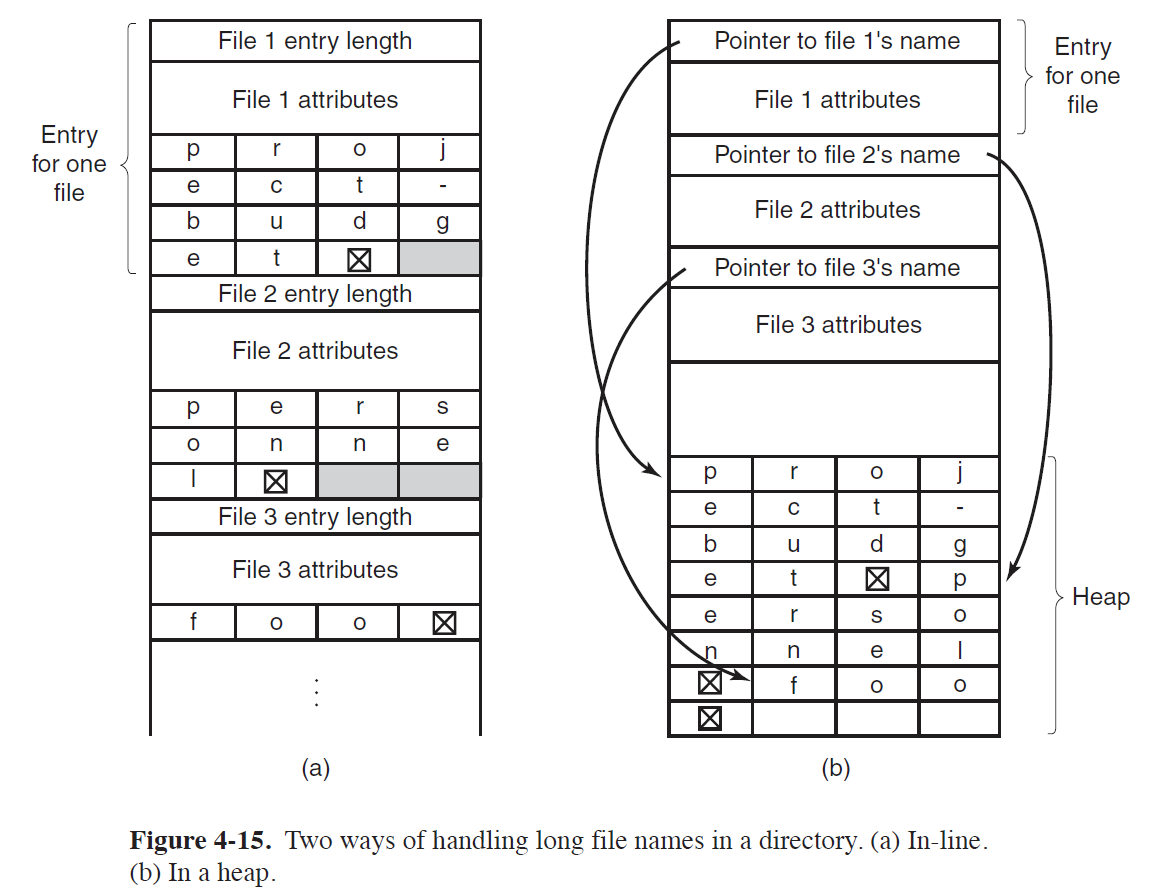
(a) In-Line
- File 이름의 길이 정보(File 1 entry length)를 미리 저장해놓고,
File 이름을 저장할 수 있을 만큼의 공간을 확보하여 저장하는 방식이다.
- 즉, Entry의 크기가 가변적이다.
(b) In a Heap
- 여러 File의 이름들을 End Mark(\(\boxtimes\))로 서로 구분지어 놓은 상태로 Heap에 저장해놓고,
각 File의 Entry에서 해당 File 이름이 저장된 Heap의 위치를 Pointing하게 해놓은 방식이다.
- Entry의 크기가 고정적이다.
Speeding Up the File Name Search
- Path를 통해 File을 Root Directory부터 검색해갈 때의 Performance를 향상시키는 방법은 아래와 같다.
1) Using Hash Table
- File Name을 Hashing한다.
- Administration이 더욱 복잡해진다.
- Directory에 많은 File들이 저장될 때 적합하다.
2) Using Caching
- Search 결과를 Caching하는 방법이다.
- 자주 Search하는 File의 개수가 적을 때 적합하다. (Cache의 특성)
Tracking Free Block, Free I-Node

- File이 새롭게 생성되면Super Block에 저장되어 있는 정보를 토대로,
Free I-Node 중 하나를 선정하여 새로 생성된 File에 할당하게 된다.
- File에 Data가 입력되면 Data Block을 Free Block 중에서 선정하여 할당하게 된다.
(a) Linked List
- Free Block에 대한 정보를 Free Block에 저장하는 방식이다.
- Free Block들은 서로 연결되어 있다.
(그림과 달리, 16번 Block(왼쪽)의 끝에는 17이 저장되어 있고, 17번 Block(중간)의 끝에는 18이 저장되어 연결되어 있다.)
- 16번 Block에 저장되어 있는 Free Block들이 모두 File에 할당되하고, 16번 Block 자체도 할당된 이후에는
17번 Block의 Free Block들을 할당하게 된다.
(16번 Block 자체를 할당할 경우, 다음 Free Block들이 저장된 곳이 17번임을 Super Block에 저장해야한다.)
- 어차피 사용되지 않던 Free Block을 활용하는 방법이기 때문에, Bitmap보다 Disk 효율성이 높다.
(Free Block을 저장하는데 발생되는 Space Overhead가 없다.)
ex) 시판되는 500GB Disk의 경우, 488M개의 Block으로 구성되는데,
이 중 1.9M개의 Block들이 Free Block들을 저장하는데 사용된다.
(이렇게만 보면, Bitmap 방식보다 비효율적이라 볼 수 있겠지만, Linked List 방식은 어차피 사용되지 않던 Free Block을 활용하는 방법이기 때문에 Bitmap 방식보다 효율적이라 할 수 있다.)
(b) Bitmap
- File이 사용중인 Disk Block은 1, Free Block은 0으로 표시하는 방식이다.
- Bit의 순서와 Disk Block의 순서는 일치한다.
ex) 011이면, 첫 번째 Block은 Free Block이며, 두세번째 Block은 사용중인 Block임을 의미한다.
- Bitmap을 저장하기 위한 Block이 추가적으로 필요하게 된다. (Bitmap의 크기는 결코 작지 않다.)
ex) 시판되는 500GB Disk의 경우, 컴퓨터에서는 488M개의 Bit로 인식됨에 따라,
Bitmap은 60,000개의 1KB짜리 Block들을 요구한다.
Shared Files
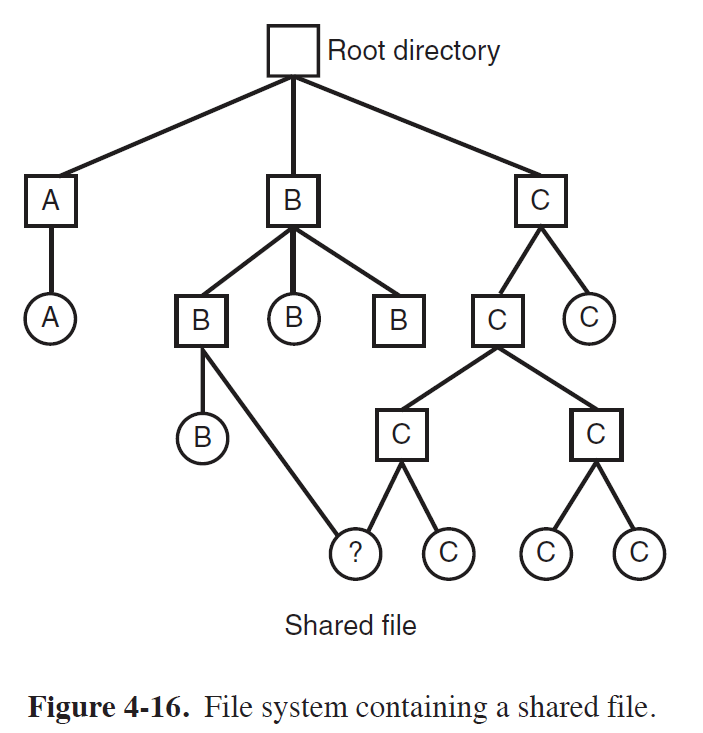
- Path가 두 개 이상으로 존재할 수 있는 File을 의미한다.
(위 그림에서는, "/B/B/?" 와 "/C/C/C/?" 두 가지로 존재한다.)
- 같은 File을 Sharing하는 Directory들이 해당 Shared File에 대한 저마다의 Disk Address를 가지면 안되므로,
이에 대한 해결책들은 아래와 같다.
1) Using I-Node (= Hard Link Method)
- Shared File을 가진 Directory들이 해당 Shared File에 대해 같은 I-Node를 가리키게 하는 방법이다.
* Problem with I-Node Method
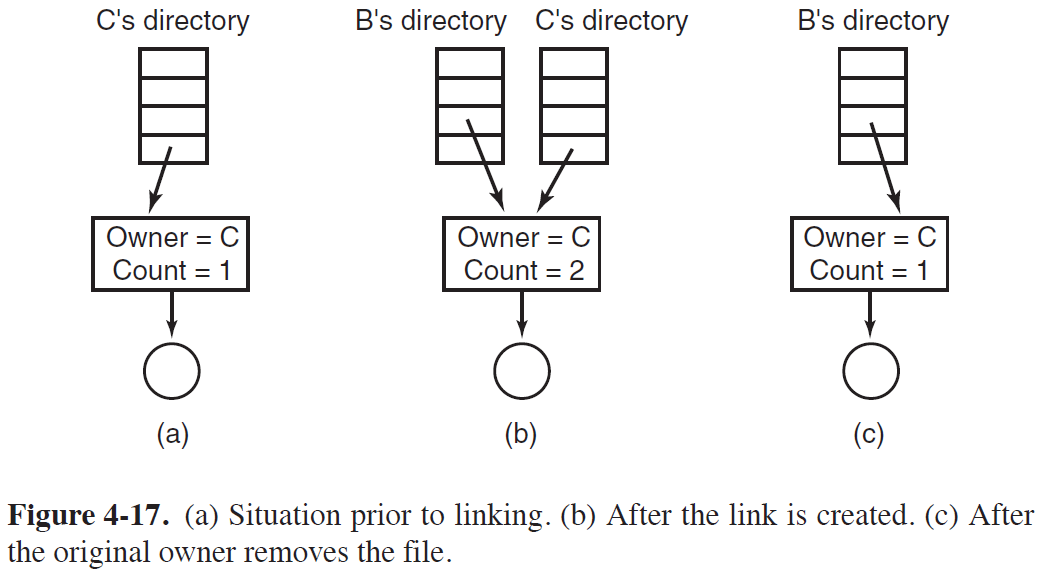
a) Owner Directory가 Shared File을 삭제해도, 삭제되지 않는 문제
- 위 그림의 (b)번 상황에서(두 개의 Directory가 File을 Share하는 상황)
C Directory에서 해당 File을 지워도, B Directory에서의 Path가 유효하기 때문에
해당 File은 삭제되지 않는 문제가 발생된다.
- 또한, 해당 File은 C Diretory에서 만들어졌기 때문에,
B Directory에서 접근할 경우 권한 문제로 인해 File에 대한 제어가 원활하지 못할 수 있다.
- 이에 대한 해결책으로는, Owner인 C Directory에서 해당 File을 삭제하면,
File System의 Tree 구조를 뒤져서 해당 File을 삭제시키는 방법이 있으나, Overhead가 너무 커서 현실적이지 못하다.
- UNIX System에서는 위 그림과 같이 Owner가 삭제해도, 다른 Path가 존재하면 해당 File을 삭제시키지 않는 방식을 채택하고 있다.
b) 다른 Partition에서 Shared File에 접근할 수 없는 문제
- I-Node는 하나의 Partition 내에서만 유효한 개념이기 때문에, 다른 Partition에서의 I-Node #는 무효하다.
2) Using Symbolic Link (= Soft Link Method)
- Directory Entry에 접근하여 해당 File이 LINK Type File임을 알아내면,
해당 File에 저장된 Path Name을 통해, 해당 File의 진짜 경로로 접근한다. (즉, 한번 더 Disk Access를 수행한다.)
- Hard Link와 달리, 해당 File의 Owner가 File을 삭제하면, 어떠한 방법으로도 해당 File에 접근할 수 없다.
(즉, 진짜 삭제된다.)
- Soft Link 방식에서는 다른 Partition의 File에 대한 Path Name을 생성할 수 있다. 즉, Hard Link 방식보다 Flexible하다.
- Windows에서는 Symbolic Link 개념이 "바로가기"로 구현되어 있다.
* Problem with Symbolic Link Method
- LINK Type의 File을 위한 I-Node가 필요하고, 그에 따른 Data Block이 하나 더 필요하게 된다.
- Directory Entry에 접근하여 LINK Type File에 저장된 Path Name을 얻어오기 위해,
Disk Access가 추가적으로 1회 더 수행된다.
Log-Structured File Systems
※ 대부분의 Read 연산은 File System의 Cache를 이용하여 Disk Access 횟수를 줄이는데 문제가 없지만,
File Structure에 관한 Write 연산에 Cache를 이용하게 되면,
Cache의 내용과 Disk의 내용에 차이가 생길 수 있고, 이로 인해 Crash가 발생될 수 있다.
- 그래서, File의 Meta Data*들은 Update될 때 마다, 곧바로 Disk에 Write된다. (Caching하지 않는다.)
- 이러한 Meta Data Update들은 Disk의 곳곳에서 소규모로 자주 발생되는데, 이들을 최적화하는 것이 Main Issue이다.
* Meta Data
- Data Block에 저장된 내용들 이외의 데이터를 통칭하는 용어이다.
- File System Structure에 관련된 데이터들이다.
- Update 된 내용들을 Segment 한 곳으로 모아서, Disk에 Log로 저장하는 방식이다.
- Log에는 최근에 변경된 I-Node Number, Directory Block, Data Block, Segment Summary 등이 저장된다.
- Log는 Disk 내에서 Continuous하게 저장되므로, Log의 Write Performance가 우수하다.
- 그러나, 가장 최근에 변경된 I-Node를 쉽게 알아내기 위해서는 Log 정보를 계속해서 Tracking하며
최근에 변경된 I-Node Number를 저장해놓고 있어야 한다.
- Cleaner를 통해 오래되어 쓸모없는 Segment들은 Free시켜서 Log의 크기가 무한정으로 커지는 것을 방지해야 한다.
Journaling File Systems
- 갑작스런 Power-Off나 Crash등으로 인해 File에 Failure가 발생했을 때, File System Check을 수행하게 되는데,
이는 실행시간이 적지 않은 Operation이다.
- 어떤 File Operation에 대한 Journal을 생성하여 해당 File Operation을 수행하기 이전에 Disk에 Journal을 저장한다.
- Operation이 수행된 후, Journal은 삭제된다.
- 만약, Operation을 수행하던 도중, Crash가 발생되어 Operation이 완료되지 못하면,
Journal에는 해당 Operation이 완료되었는지 아닌지에 대한 여부가 저장되어 있으므로,
해당 Operation의 Journal을 참고하여, 완전히 수행되지 못했다면, 해당 Operation을 처음부터 다시 수행한다.
(단, 일부과정이 반복되어도 지장이 없는 Idempotent Operation이어야 한다.)
- 또한, File Operation을 완료한 이후에는 해당 Journal을 삭제하는데,
File Operation을 완수한 후 Journal을 삭제하기 이전에 Crash가 발생하면, 해당 File Operation을 또 다시 수행한다.
(즉, File Operation을 수행하고 Journal을 삭제하는 과정까지가 하나의 과정이다.)
(Idempotent Operation이기 때문에 반복해도 문제는 없다. 단지, 시간이 더 소요될 뿐이다.)
- 즉, Journaling File System에서는 File System에 Crash가 발생하여 다시 시작할 때,
전체 File System을 점검할 필요 없이, Journal만 점검하면 된다.
Example. Removing File
Process of Removing a File
1) 해당 File을 Parent Directory Entry에서 삭제한다.
2) 해당 File에 할당된 I-Node를 Free시킨다.
3) 해당 File에 할당된 Data Block들을 Free시킨다.
- 만약, 2번 과정까지 수행한 후, Crash가 발생되었다면,
File System이 System으로 다시 Load될 때 1번 과정부터 다시 시작한다.
※ File System에서 Remove Operation을 구현할 경우, 반드시 위처럼 1~3번 순서로 구현해야 한다.
- 위 순서는 File System에 Crash가 발생되어 다시 재개해도 문제가 없게 수행하는 순서이다.
(File System의 종류에 관계없이, File System에 문제가 생겨 다시 재개되는 상황을 고려해야 한다.)
- 1번 과정이 먼저 선행됨으로써, 1번 과정을 수행한 후 Crash가 발생되고,
다른 File에서 Removing 대상이 되는 File의 Disk Block을 할당받아도 문제가 없게 된다.
Virtual File Systems
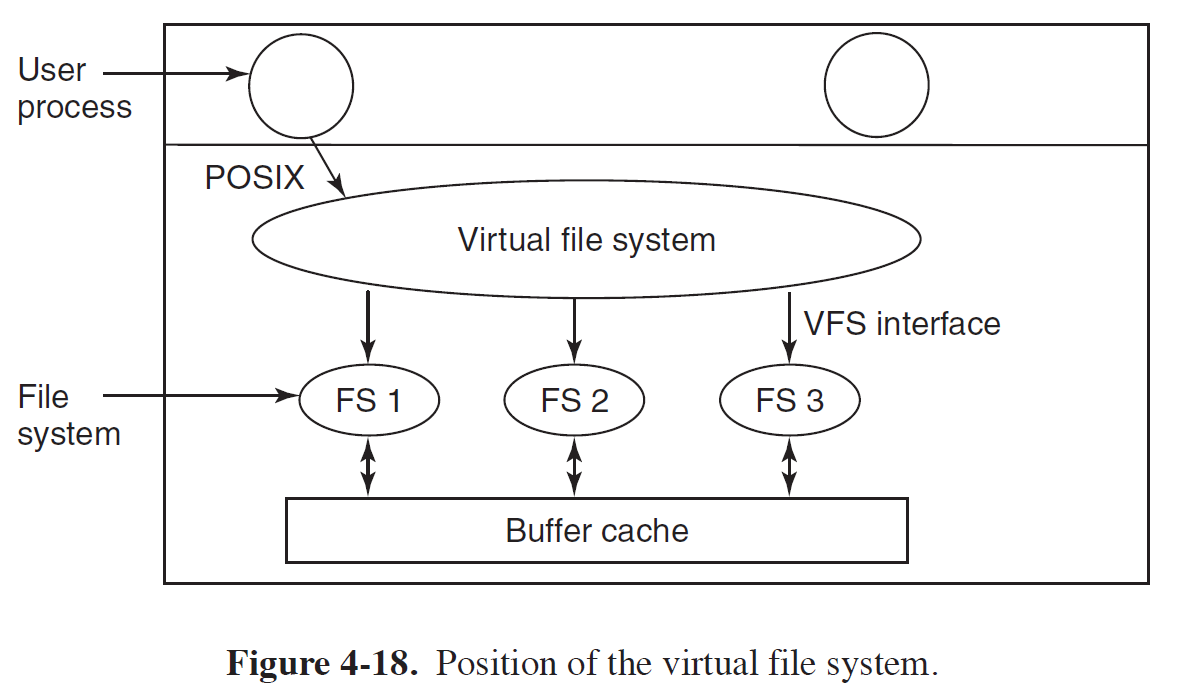
- Virtual File System은 다양한 File System을 하나로 아울러서 User Process에게 일관된 Interface를 제공한다.
File-System Management and Optimization
Disk Space Management
- Block Size는 그 크기에 따른 Trade-Off가 존재한다.
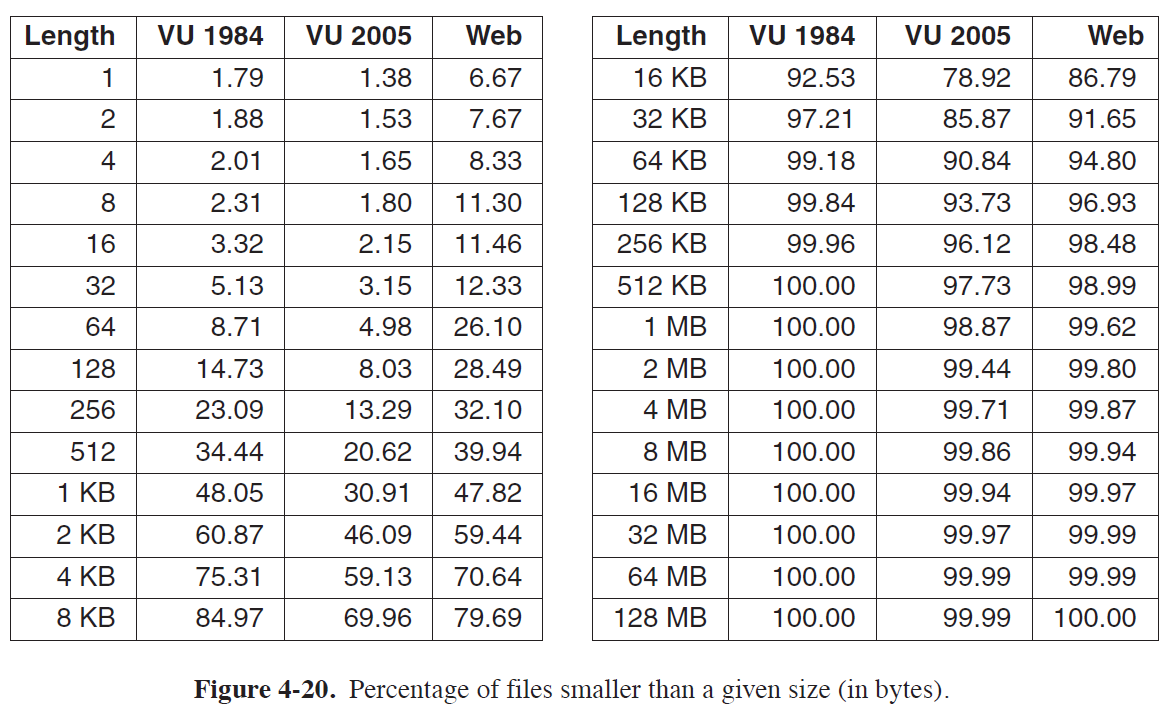
- 위 Table은 각 System에서 특정 Size의 File이 차지하는 비율을 누적하여 나타낸 결과이다.
ex) VU 2005에서 512Byte 이하의 File들이 전체 File System의 20.62%를 차지한다.
ex) VU 2005에서 Block Size를 1KB로 설정할 경우, 전체 File의 69.96%가 8개의 Direct PTR로 커버가 가능하다.
ex) VU 2005에서 Block Size를 4KB로 설정할 경우, 전체 File의 85.87%가 8개의 Direct PTR로 커버가 가능하다.
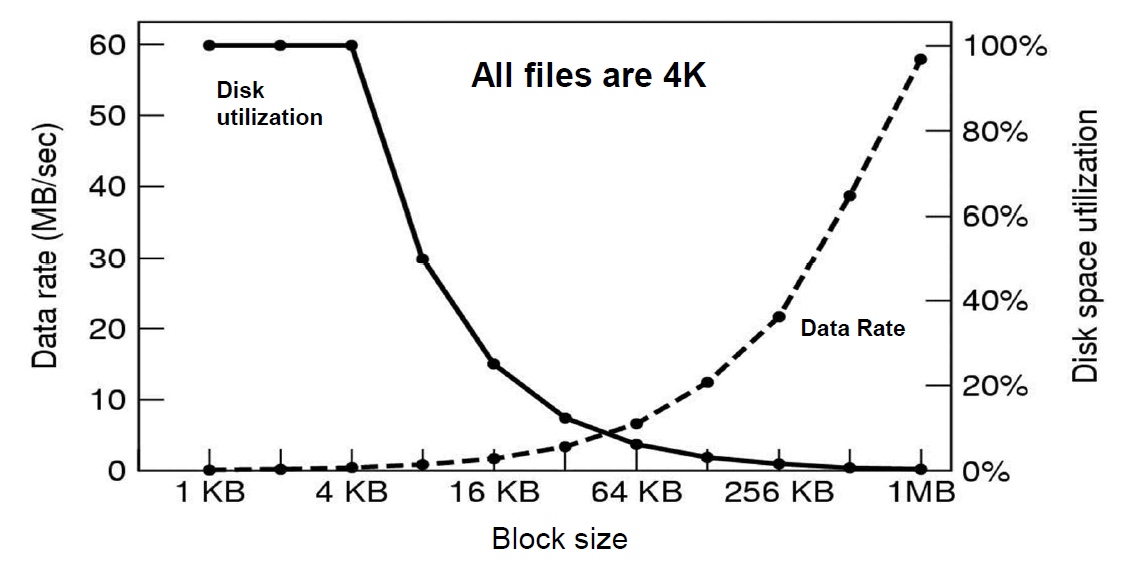
- 모든 File의 크기가 4KB라는 가정하에,
Block Size에 따른 Data Rate(데이터 전송량)과 Disk Utilization(디스크 활용률)의 변화를 나타낸 그래프이다.
- Block Size가 작으면, Block를 검색할 때의 Overhead로 인해 Date Rate이 느려지는 반면, Disk Utilization은 우수하다.
- Block Size가 커지면, 한 번에 옮겨지는 Block의 양이 많아 Date Rate이 우수한 반면, Disk Utilization은 떨어질 수 밖에 없다.
File System Backups
- Disasters, Stupidity로 인해 데이터의 손실에 대비하기 위해 Dump(Backup)이 필요하다.
* Backup = Dump
1) Incermental Dumps
- 처음 File System 전체를 백업한 이후에는 수정된 내용만 백업하는 형태이다.
2) Compressed Format Backup
- 데이터를 압축하여 백업하는 형태이다.
3) Offline or Online
- Offline Back up: 백업 시, System을 Stop시키고, Offline에서 File System을 Backup하는 형태이다.
- Online Back up: System을 Stop시키지 않고, 진행되는 동안에 File System을 Backup하는 형태이다.
- 백업의 종류로는 Physical Dump, Logical Dump
Backups: Physical Dump
- Disk Image를 그대로 Copy하는 백업하는 형태이다.
- 해당 Disk에 어떤 데이터가 있는지, 어떤 File System인지에 관계없이, Simple하고 빠르게 진행된다.
(부분적으로 백업하거나, 수정된 부분만 백업하거나, 특정 파일을 복구하는 등의 기능은 없다.)
- 사용되지 않는 Disk Block까지 모두 Copy하므로 비효율적일 수 있다.
- Disk에 Physical Bad Block이 있는 경우, 이에 대한 처리방법도 구현되어야 한다.
Backups: Logical Dump
- 해당 File System에 구성된 Tree 구조를 따라가며 백업하는 형태이다.
- 특정 Directory 혹은 Dump Directory에서 시작하여 하위 File들을 백업해나간다.
- File System을 Full Dump(전체 백업)한 이후에는,
특정 File 혹은 Directory만을 백업하거나 복구할 수 있고, 변화된 파일만 백업할 수 있다.
- 특정 파일만 백업할 수 있으므로, 빠르고 용량도 작다.
- 특히, 변화된 파일을 백업할 경우, Root에서 해당 File까지의 Path에 있는 모든 File들도 같이 백업되어야 한다.
(해당 File의 상위 File에 문제가 생겼을 경우에 대비해야 하기 때문이다.)
Example. Logical Dumping Algorithm

- 위 그림에서 회색으로 색칠된 Node들은 수정된 File 혹은 수정된 Directory를 의미한다.
(Node에 적힌 숫자는 I-Node Number를 의미한다.)
- 만약 3번 Node를 Dump하고자 한다면, Path에 있는 1번, 2번 Node도 같이 Dump된다.

(a) Modified File or Directory와 그들의 Path에 있는 모든 File or Directory들을 전부 Mark한다.
(b) Modified되지 않은 File or Directory들은 Unmark한다.
- 위 그림에서는 10, 11, 14, 27, 29, 30이 Unmark되었다.
- 즉 Modified File or Directory와 연관된 Node들만 Mark된 상태로 남는다.
(c) Makr된 Directory들을 모두 Dump한다.
(d) Mark된 File들을 모두 Dump한다.
File System Consistency
- File System의 Tree구조가 오류없이 잘 유지되고 있는지를 Check해야 한다.
- Block에 대한 Consistency Check와 File에 대한 Consistency Check를 수행한다.
- UNIX에서는 \(\texttt{fsck}\) Instruction을 통해, Windows에서는 \(\texttt{scandisk}\) Instruction을 통해
File System의 Free Block과 Used Block들을 확인하여 구조에 오류가 감지되면 에러 메시지를 출력한다.
Block Consistency Check
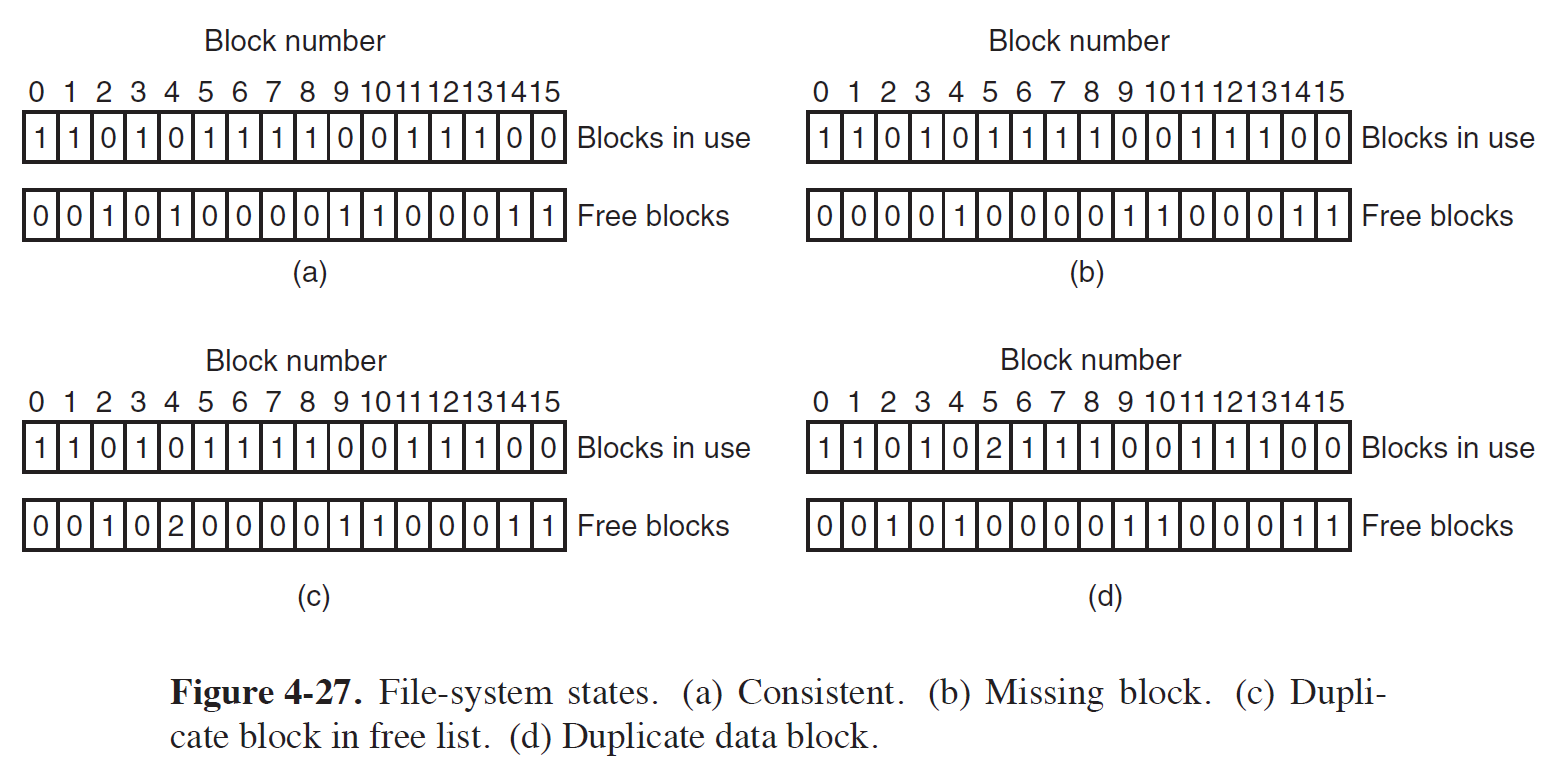
- File System의 Tree 구조 전체를 순회하면서 Block in use들을 모두 찾아낸다.
- Free Block List를 순회하며 Free Blocks들을 모두 찾아낸다.
(a) Consistent
- Disk Block들이 Consistent한 경우이다.
(b) Missing Block (Block 2)
- 특정 Block이 사용되고 있지도 않고, Free Block List에도 없는 상황이다.
- Data Block을 Free시키기 이전에 Crash가 발생되고, 이를 방치했을 때 야기될 수 있는 상황이다.
- 2번 Block을 Free Block List에 삽입하여 해결할 수 있다.
(c) Duplicate Block in Free List (Block 4)
- 특정 Block이 Free List에 두 번 이상 삽입된 경우이다.
- Bitmap 구조에서는 이러한 상황이 잘 발생되지 않지만, Linked List 구조에서는 이러한 상황이 발생될 수 있다.
- Duplicate Block을 하나만 남기고 전부 Pop시켜서 해결할 수 있다. (즉, 중복을 제거하면 된다.)
(d) Duplicate Data Block (Block 5) (Critical)
- 특정 Block이 두 File 이상에서 사용되고(할당되어) 있는 경우이다.
- 어느 한 쪽 File에 Data Block을 새로 할당하여 해결할 수 있다.
- 단, 중복되어 할당된 Block은 어떤 File의 데이터가 저장되어 있는지 시스템은 알 수가 없으므로,
해당 Block에 Contents를 복구하는 작업은 오로지 사용자의 몫이다. (즉, 기존의 Contents가 Overwrite될 수 밖에 없다.)
Directory Consistency Check
- File System의 Tree 구조를 순회하며 계산한 Usage Count값을 기존의 Link Count값과 비교하여 File System을 점검한다.
i) Link Count > Usage Count
- 측정 결과(Usage Count)가 기존의 Link Count값보다 작은 경우이다.
(즉, 원래 알려진 경로보다 실제로 접근할 수 있는 경로의 수가 더 적은 경우이다.)
- 이 상황이 Fix되지 않으면, File System Tree에서 해당 File을 삭제해도 Link Count값이 0이 되지 않아,
해당 File에 접근할 수는 없는데 할당된 Disk Block은 Free되지 않는 상태가 지속되게 된다.
- 이 경우, Link Count값을 Usage Count 값으로 대체하여 해결한다.
ii) Link Count < Usage Count
- 측정 결과(Usage Count)가 기존의 Link Count값보다 큰 경우이다.
(즉, 원래 알려진 경로보다 실제로 접근할 수 있는 경로의 수가 더 많은 경우이다.)
- 이 상황이 Fix되지 않으면, File System Tree에서 다수의 경로 중 어느 한 쪽 경로만 삭제했는데, Link Count 값이 0이 되어,
경로가 존재함에도 불구하고 해당 File에 할당된 Disk Block이 Free되게 된다.
- Disk Block이 Free되고, 다른 File에 할당되게 되면 다수의 File에서 같은 Disk Block을 사용하는 상황이 벌어질 수 있다.
- 이 경우, Link Count값을 Usage Count 값으로 대체하여 해결한다.
File System Performance
File System Cache
- Buffer Cache는 Disk Driver와 File System 사이에 위치하여 Cache의 역할을 한다.
- Disk Access 횟수를 줄이는 것을 목표로 하여 I/O 속도 향상을 도모한다.
- Cache를 사용한다는 것은 Disk Access에 Locality가 있다는 전제하에 진행되는 것이다.
- Buffer Cache는 Main Memory에 위치하게 되므로, Buffer Cache의 크기를 증가시키면
I/O 속도는 향상되는 대신, Main Memory의 가용 공간이 줄어드는 Trade-Off 관계가 있다.
- Buffer Cache Miss가 발생되면, 해당 Disk Block을 Disk에서 Buffer Cache에 새로 Load하게 되는데,
이 과정에서 다른 Caching Algorithm과 같이, Replacement가 발생된다.
(일반적으로 Full LRU* Replacement를 수행한다.)
* Full LRU
- I/O 명령은 Memory Reference처럼 자주 일어나는 연산이 아니기 때문에,
Memory에서와 같이 LRU를 Simulate하는 방식이 아닌, Full LRU를 수행한다.
(일반적으로, Linked-List를 이용한 FIFO Queue로 구현한다.)
File System Caching에서 LRU가 불리한 경우
1) I-Node를 Caching하는 경우
- 대개 I-Node는 한 번 Access한 이후, 곧바로 다시 Access하지 않는다.
2) Meta Data를 Caching하는 경우
- Meta Data(File Structure에 대한 정보 등)가 오랫동안 Cache Hit되어 Cache에만 저장되고,
Disk에는 오래된 정보만 남아있는 상태에서 Crash가 발생되면 결국 오래된 Meta Data만 남게된다.
- 이를 방지하기 위해, File System Meta Data가 Update되면 Cache에도 Overwrite하고, Disk에도 곧바로 Overwrite한다.
- 물론, Meta Data가 아닌, 일반적인 Data Block 또한 일정 주기로 Disk에 Overwrite한다.
(UNIX의 경우 Sync 혹은 Update Daemon, MS-DOS의 경우 Write-Through Cache로 구현되어 있다.)
※ 즉, Meta Data는 Write-Through 방식(곧바로 Disk에도 Write함)으로,
Data Block은 Write-Back 방식(일정 주기로 Cache를 Flush하고, Cache의 내용을 Disk에 Write함)으로 Caching한다.
- File System Caching에서는 Read Performance는 준수하지만, Write Performance가 미흡하여
Log Structured File System 개념이 등장했다.
LRU Replacement in File System Caching
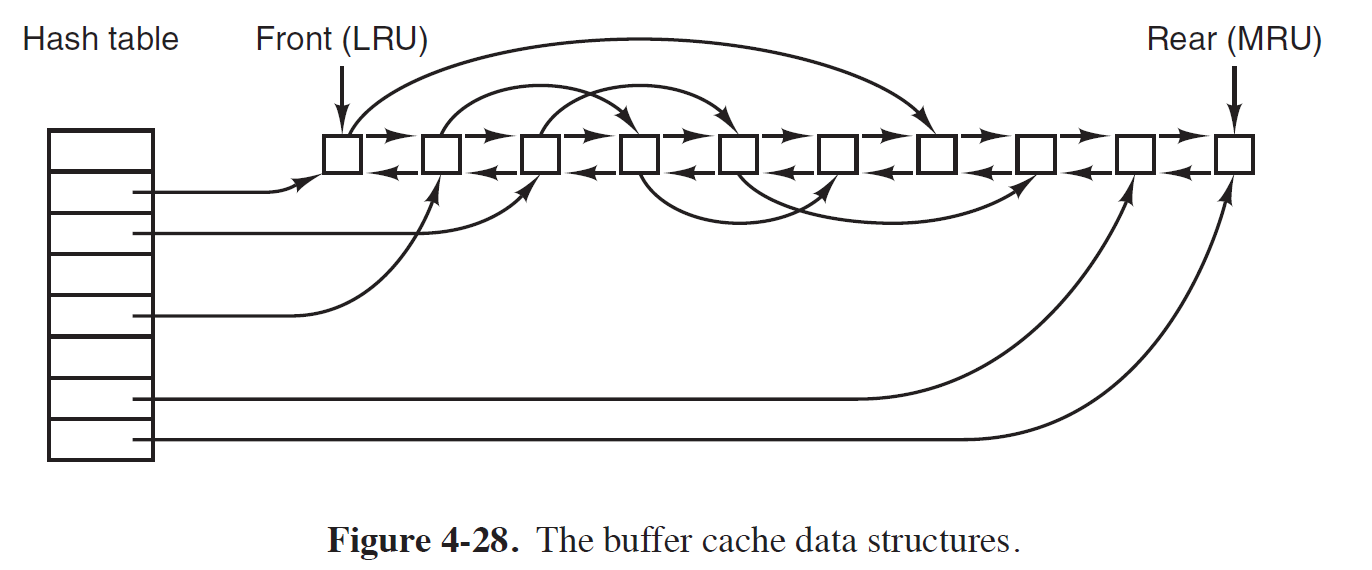
- (Device ID, Block Number)값 Pair를 Hashing하여 Hash Table의 Index를 알아내어,
해당 Index로 Hash Table에 접근하여 Buffer Cache에 Access한다.
- Cache Hit의 경우, 해당 Buffer Cache를 Rear(MRU)로 옮긴다.
- I-Node가 저장된 Block의 경우, 자주 Access되지 않으므로,
Designer는 I-Node가 저장된 Block을 Caching할 지에 대한 여부를 결정해야한다.
- Buffer Cache의 크기(Allocation Unit)를 크게하여 다수의 Disk Block을 한꺼번에 Caching할 수도 있다.
(Internal Fragmentation문제가 발생될 수 있다.)
Defragmentation Disks
- File의 Data Block이 Disk의 곳곳에 흩어져 있어, 이들을 다시 한곳으로 모아주는 작업을 Defragmentation이라 한다.
- Data Block들이 산개해 있을수록,
해당 Data Block에 접근할 때 Disk Arm이 움직여야 하는 거리가 늘어나 I/O Performance를 저해하게 된다.
Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)
Chapter 4. File Systems
* Long-Term Information Storage의 자격요건
1) 대량의 Data를 저장할 수 있어야 한다.
2) Persistent한 Data. 프로세스가 Data를 사용한 이후 혹은 System의 Power가 Off되어도 Data가 보존되어야 한다.
3) 여러 프로세스들이 동시에 Access하기에 편리해야 한다.
- 위 조건들을 충족시키기 위해, "File System"이라는 개념이 등장했다.
- File들은 Disk에 저장되며, Disk는 Linear Sequence of Fixed-Size Block이다.
(Block 단위로 Read/Write이 가능하다.)
Files
File Naming
- File의 명명법은 System마다 상이하다.
* Typical File Extension (전형적인 파일 확장자)
- UNIX에서는 파일 확장자를 지정하지 않아도 오류가 없는 경우가 많지만,
Windows에서는 파일을 선택하면 해당 확장자를 통해 맞는 프로그램을 고르기 때문에 오류가 생길 수 있다.
File Structure
* Byte Sequence
- File을 Sequence of Byte로하는 구조이다.
- File의 의미는 Application의 해석 방법에 따라 달라진다.
- UNIX와 Windows가 채택한 File 구조이다.
- File에서 Address될 수 있는 최소 단위는 Byte이다.
* Record Sequence
- File을 Fixed-Length Record로 하는 구조이다.
- 과거, Mainframe에서 사용했던 File 구조이다.
* Tree
- File을 Tree로 표현하는 구조이다.
- Record Sequence와 마찬가지로, 과거 Mainframe에서 사용했던 File 구조이다.
File Type
- File의 유형은 시스템마다 다양할 수 있지만, 일반적으로 Directory와 Regular File로 구분된다.
* UNIX에서는 Character Special File과 Block Special File이 존재한다.
- Device는 크게 Character Device와 Block Device로 나뉘는데,
Character Device는 키보드나 네트워크로부터 들어오는 Stream Data를 처리하는 Device이고,
Block Device는 디스크와 같이 Data를 Block 단위로 처리하는 Device이다.
- 즉, Character Device로부터 처리되는 Data가 저장되는 File이 Character Special File이고,
Block Device로부터 처리되는 Data가 저장되는 File이 Block Special File이다.
* Regular File
- 보통, ASCII File 혹은 Binary File을 의미한다.
- Binary File은 Execution File 등을 의미한다.
File Access
* Sequential Access
- Byte 순서대로 읽으며 접근하는 방식이다.
- 최적화가 쉽다.
* Random Access
- Byte Sequence에 무작위로 접근하는 방식이다.
- 주로 DB System에서 택하는 방식이다.
- 최적화가 힘들다.
File Attribute
Basic File Operation
| Create | Delete | Open | Close |
| Read | Write | Append | Seek |
| Get Attribute | Set Attribute | Rename |
| File Operation in UNIX | Description |
| create(name) | |
| open(name, mode) | |
| read(fd, buf, len) | |
| write(fd, buf, len) | |
| sync(fd) | - Caching중인 파일영역과 Disk에 저장된 파일영역의 데이터를 동기화시키는 연산이다. |
| seek(fd, pos) | - File Read/Write시, 읽는 Disk 영역의 시작점을 지정하는 연산이다. |
| close(fd) | |
| unlink(name) | |
| rename(old, new) | |
| fcntl(fd, cmd, *lock) | - File Control |
File System Call Example
copyfile abd xyz위와 같은 File Operation을 수행할 때 실행되는 코드는 아래와 같다.
/* File copy program. Error checking and reporting is minimal. */
#include <sys/types.h> /* include necessary header files */
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char *argv[]); /* ANSI prototype */
#define BUF_SIZE 4096 /* use a buffer size of 4096 bytes */
#define OUTPUT_MODE 0700 /* protection bits for output file */
int main(int argc, char *argv[])
{
int in_fd, out_fd, rd_count, wt_count;
char buffer[BUF_SIZE];
if (argc != 3) exit(1); /* syntax error if argc is not 3 */
/* Open the input file and create the output file */
in_fd = open(argv[1], O RDONLY); /* open the source file */
if (in_fd < 0) exit(2); /* if it cannot be opened, exit */
out_fd = creat(argv[2], OUTPUT MODE); /* create the destination file */
if (out_fd < 0) exit(3); /* if it cannot be created, exit */
/* Copy loop */
while (TRUE) {
rd_count = read(in_fd, buffer, BUF_SIZE); /* read a block of data */
if (rd_count <= 0) break; /* if end of file or error, exit loop */
wt_count = write(out_fd, buffer, rd_count); /* wr ite data */
if (wt_count <= 0) exit(4); /* wt count <= 0 is an error */
}
/* Close the files */
close(in_fd);
close(out fd);
if (rd_count == 0) /* no error on last read */
exit(0);
else
exit(5); /* error on last read */
}Directories
- File들을 Organize할 수 있게 하고, File들에 Namespace를 제공한다.
Single Level Directory Systems
- Directory 개념이 없는 시스템이다.
- 아주 작은 시스템에서 채택하는 방식이다.
Hierarchical Directory Systems
- Tree를 이용하여 FIle들을 계층적으로 구분하는 시스템이다.
- 대부분의 시스템이 채택한 방식으로, Multi-Level Directory로 구성된다.
- File을 지칭할 때에는 Slash(/)를 이용한 Path Name을 기술하여 지칭한다.
ex) /usr/local/bin
- Current Directory(Working Directory)는 .(한 개의 Dot)으로 표현하며,
Parent Directory는 ..(두 개의 Dot)으로 표현한다.
Path Name
- Absolute Path Name과 Relative Path Name으로 구분된다.
1) Absolute Path Name
- File System의 Root Directory부터 목적지 까지 전부를 기술한 Path Name이다.
ex) /usr/local/bin
2) Relative Path Name
- Current Directory를 기준으로 기술한 Path Name이다.
ex) bin (Current Directory에 bin Directory가 존재하는 경우 유효하다.)
Directory Operation
| Create | Delete | Opendir | Closedir |
| Readdir | Rename | Link | Unlink |
* Directory Internals
- Directory는 리스트로 구현되어 있다.
- List를 구성하는 Item은 File의 이름과, File Attribute로 구성되어 있다.
- Attribute는 Size, Protection, Location on Disk, Creation Time, Access Time 등이 될 수 있다.
File-System Implementation
File System Layout
- Partition Table에는 각 Disk Partition의 정보가 저장되어 있다.
- 각 Disk Partition에는 위 그림과 같은 정보들이 저장되어 있으며, 이는 시스템마다 다를 수 있다.
| Disk Partition Component | Description |
| Boot Block | - 부팅시에 사용될 프로그램들이 저장되어 있다. |
| Superblock | - File System에 대한 Parameter들이 저장되어 있다. - Parameter에는 File System Type을 규정하는 Magic Number, Block의 개수 등이 해당된다. |
| Free Space MGMT (Management) | - Free된 Block된 정보들이 저장되어 있다. |
| I-Nodes | - File Attribute나 File의 Disk Address를 저장하고 있는 Node로, File당 하나의 I-Node를 갖고 있다. |
| Root DIR | - Root Directory에 대한 정보가 저장되어 있다. |
| Files and Directories |
* MBR : Master Boot Record
- 부팅에 사용된다.
- Partition Table에 대한 정보가 저장되어 있다.
* Partition Table
- 각 Partition들의 Starting Address와 Ending Address가 저장되어 있다.
- 어떤 Partition이 Active Partition인지에 대한 정보가 저장되어 있다.
* Boot Sequence
1) 시스템이 Power-On되면 BIOS가 수행되어 부팅에 사용될 Disk의 MBR을 읽는다.
2) MBR을 통해 Active Partition을 찾아내어 Boot Block에 있는 프로그램을 실행시킨다.
3) Boot Block에 위치한 프로그램은 OS가 저장된 Partition에서 OS를 Load시킨다.
Implementing Files
File Implementation #1 : Contiguous Allocation
- 위 그림에서 각각의 사각형들은 Block을 의미한다.
- File은 Sequence of Block이며, Contiguous Allocation에서 File들은 연속된 Block들을 할당받는다.
- 이후에, File이 Delete되면, 해당 File이 차지하고 있던 Block들이 Free된다.
- 위 (b) 경우에서, 7개의 Block을 차지하는 새로운 FILE H는 현재상황에서 Allocation될 수 없다.
* Contiguous Allocation Advantage
1) File의 시작주소와 크기만 알면 되므로, Implementation이 간단하다.
2) Sequential Access를 수행하기 때문에 Read Performance가 우수하다.
* Contiguous Allocation Disadvantage
1) External Disk Fragmentation이 존재하여, Compaction 연산이 필요하다.
2) Internal Disk Fragmentation이 존재한다.
- Allocation Unit이 존재하는한, Internal Fragmentation은 존재할 수 밖에 없다.
* Contiguous Allocation Applicability
- Contiguous Allocation은 대개, 한 번 정해지면 변하지 않는 구조에 많이 이용된다.
1) CD-ROM
2) File Size가 미리 알려진 구조
3) File Size가 변하지 않는 구조
File Implementation #2 : Linked List Allocation
- Physical Block에 해당 File이 저장되어 있는 다음 Physical Block을 가리키는 포인터 필드를 포함시켜서,
Physical Block들이 논리적으로 Sequential하게 구현되도록 하는 방법이다.
- 위 그림처럼, File A와 B가 저장되어 있는 Physical Block들은 포인터 필드를 통해 논리적으로 연결되어 있지만,
실제로 각각의 Block들은 Physical Block들 사이에서 산개되어 있다.
* Linked List Allocation Advantage
1) Contiguous하게 Allocation할 필요가 없어, External Disk Fragmentation이 없다.
2) 빈 Block들이 크기에 상관없이 사용될 수 있다. (즉, 빈 Block들을 알뜰하게 사용할 수 있다.)
* Linked List Allocation Disadvantage
1) 포인터 필드로 File의 첫 Physical Block부터 접근해야하기 때문에
Sequential Access 혹은 Random Access 방식에서 속도 측면에서 불리하다.
- File의 중간부분에 접근하고자 한다 하더라도, File의 첫 부분부터 접근하여 포인터 필드를 통해 이동해야 하기 때문에
이로 인한 Overhead가 상당하다.
- Disk에 접근하는 것이기 때문에, Physical Block의 포인터 필드에 접근하는 연산은 모두 다 I/O연산임에 유의하자.
2) 각 Physical Block에 위치한 포인터 필드로 인해 추가적인 Physical Block이 필요할 수 있다.
3) Internal Disk Fragmentation이 존재한다.
- Allocation Unit이 존재하는한, Internal Fragmentation은 존재할 수 밖에 없다.
File Implementation #3 : Linked List Allocation Using a Table in Memory (FAT)
- File Allocation Table(FAT)에는 다음 Block의 인덱스 값이 저장되어 있다.
(FAT의 Index는 곧 Physical Block의 번호이다.)
ex) 어떤 File A는 4번 Block에 처음으로 할당되어 4 - 7 - 2 - 10 - 12와 같은 순서로 Block들에 할당되었음을 알 수 있다.
ex) 어떤 File B는 6번 Block에 처음으로 할당되어 6 - 3 - 11 - 14와 같은 순서로 Block들에 할당되었음을 알 수 있다.
- FAT Entry는 Block의 개수만큼 형성된다.
(즉, 최대로 생성할 수 있는 File의 개수는 FAT Entry의 개수와 같다. = 각 File들이 하나의 FAT Entry만 차지할 경우)
- FAT는 File System이 형성되면 Disk에 저장되어 있다가, Main Memory에 Mount(Load)되어 사용된다.
- FAT의 각 Entry에는 Cluster 혹은 Block에 대한 정보가 저장되어 있다.
- Starting Block의 번호는 File이 위치한 Directory Entry에 저장되어 있다.
- FAT은 Critical Resource이다. FAT이 한 Point라도 손상되면, File System에서의 Block 배치를 알 수 없게된다.
- 그러므로, FAT에 변화가 생길때마다 Disk에도 변화된 정보가 즉시 반영된다.
(Critical Resource이기 때문에 바로바로 백업해놓는 것이다.)
+) 그래서, FAT Storage는 컴퓨터에서 바로 제거해도 문제가 없을 수 있지만,
NTFS Storage는 컴퓨터에서 바로 제거하면 문제가 생길 수 있다.
* Cluster
- 연속된 Physical Block을 한 덩어리로 묶어 Addressing하는 것을 의미한다.
- 수많은 Block을 FAT이 모두 표현할 수 있게하기 위해 고안된 개념이다.
ex) 위 그림의 FAT은 16개의 FAT Entry를 가진다. 단, FAT Entry의 크기가 3Bits인 경우, 0~7까지밖에 표현하지 못하므로,
두 개의 Physical Block를 하나의 Cluster로 묶어 Indexing한다면, FAT이 모든 Entry를 커버할 수 있게 된다.
ex) FAT Entry의 크기가 3Bits인데, 32개의 Physical Block을 커버해야 한다면,
적어도 4개의 Physical Block을 하나의 Cluster로 묶어야 한다.
- FAT16 시스템의 경우, FAT Entry가 16Bits로 구성되어 최대 64K개의 Cluster를 Addressing할 수 있다.
(즉, FAT16에서 FAT Entry의 개수는 64K개이고, 최대로 생성할 수 있는 File의 개수도 64K개이다.)
- 즉, Cluster가 새로운 Allocation Unit이 된다.
- Cluster의 크기가 커질수록 Internal Fragmentation 문제가 발생될 가능성이 높아진다.
* FAT Advantage
1) FAT은 항상 Main Memory에 Load되어 있기 떄문에 Random Access가 빠르게 이루어진다.
2) Disk Access없이도, Block Address를 얻을 수 있다.
3) Directory Entry에는 Block의 시작 인덱스만 저장되어 있으면 된다.
* FAT Disadvantage
1) FAT은 모든 부분이 항상 Main Memory에 Load되어 있어야한다. 즉, Memory를 많이 차지한다.
- Block Size가 1KB인 200GB의 Disk의 FAT은 200M개의 Entry를 갖는다.
FAT32의 경우, 하나의 FAT Entry가 4Bytes의 크기를 가지므로, 이 시스템의 FAT은 800MB의 크기를 차지한다.
즉, Main Memory의 800MB가 항상 FAT이 차지하고 있게 된다.
File Implementation #4 : Index Node (I Node)
- 한 File당, 하나의 I Node가 할당된다.
- File이 생성되면, 빈 I Node가 할당되고, File에 Data가 쓰여지기 시작되면, Disk Block을 I Node에 할당하게 된다.
- File Attribute에는 File에 대한 정보들이 저장된다.
- File이 차지한 Disk Block들이 Array Structure처럼 순서대로 저장되어 있다.
- FAT와 달리, 시스템에서 FILE A에 접근하고자 하는 경우, A의 I Node만 Main Memory에 Load한다.
(FAT에서는 FAT가 상시 Main Memory에 Load된다.)
※ Main Memory는 Byte단위로 주소가 부여되고, Disk는 Block단위로 주소가 부여된다.
* 큰 File을 I Node 방식으로 커버하는 방법
- 1MB 크기의 File을 1KB 크기의 Block을 가진 I Node가 커버하려면, 1,024개의 Entry를 필요로하게 되고,
이는 I Node의 크기를 매우 비대하게 만드는 문제가 있다.
- 이러한 문제를, I Node 방식에서는 아래와 같이 해결한다.
* 위 그림에서는 Single Indirect Pointer가 3개의 Block Address Array를 Pointing한다 가정한다.
Direct Pointer: 사용하고 있는 Block의 주소가 저장되어 있다. (즉, Block 주소를 직접적으로 Pointing하고 있는 포인터이다.)
Single Indirect Pointer: Direct Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
Double Indirect Pointer: Single Indirect Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
Triple Indirect Pointer: Double Indirect Pointer를 저장하고 있는 Disk Block을 Pointing하고 있는 포인터이다.
\(\qquad\qquad \vdots\)
- I Node의 하나의 Entry가 Indirection을 통해, 여러 Block을 커버할 수 있게 하는 방법이다.
- Indiret Pointer의 계층이 심화될수록, 기하급수적으로 많은 Block들을 커버할 수 있게 되지만,
부가적인 Disk Access 횟수 또한 증가한다.
- I Node Entry의 Indirect 구조는 Designer의 재량이다.
(즉, 그림처럼 Single -> Double -> Triple일 필요는 없으며, 모든 Entry가 Double Indirect 형태일수도 있으며,
이외에 다른 여러가지 형태로 존재할 수 있다.)
Example. I Node in UNIX V7 File System
- 1KB Block에 Direct Pointer Size가 4Byte인 경우,
하나의 Pointer Field Entry가 1KB/4Byte(=256)개의 Disk Block 주소를 커버할 수 있다.
- 즉, 위 시스템에서 Single Indirect Block은 \(256^1\)개의 Disk Block 주소를,
Double Indirect Block은 \(256^2\)개의 Disk Block 주소를,
Triple Indirect Block은 \(256^3\)개의 Disk Block 주소를 커버할 수 있다.
- 따라서, 위 그림에서는 \(10 + 256 + 256^2 + 256^3\) 개의 Disk Block을 구분지을 수 있다.
Direct PTR 10개 = Disk Block \(10\)개
Single Indirect Pointer 1개 = Disk Block \(256\)개
Double Indirect Pointer 1개 = Disk Block \(256^2\)개
Triple Indirect Pointer 1개 = Disk Block \(256^3\)개
(Disk Block Size가 1KB인 경우, 위 I Node에 해당하는 File의 크기는
\(10 + 256 + 256^2 + 256^3\) * 1KB = 16.8GB 이다.)
* I Node Advantage
1) Main Memory를 효율적으로 사용할 수 있다.
- FAT과 달리, 접근하고자 하는 FILE의 I Node만 Main Memory에 Load시키기 때문이다.
* I Node Disadvantage
1)
Example. UNIX File System
- Disk를 Partition으로 나누고,
각각의 Partition에는 Boot Block과 Super Block, I Nodes, Directory Block과 Data Block으로 구성된다.
1) Super Block
- File System에 대한 전반적인 정보가 저장되어 있다.
- File System의 크기, I-List의 크기,
Free Block의 개수, Free I Node의 개수,
Free Block List, Free I Node List,
다음에 할당할 Free Block의 Index, 다음에 할당한 Free I-Node의 Index 등이 저장되어 있다.
(Free Block, Free I-Node란, 사용되고 있지 않은 Block, I-Node를 의미한다.)
- 최대로 생성할 수 있는 File의 개수는 I Node의 개수에 관련되어 있다.
2) I-List
- 각 File들에 대한 정보(I Node들의 List)가 저장되어 있다.
- Array와 같은 Container Structure에 File이 사용하고 있는 Block 정보가 차례대로 연결되어 있다.
3) Directory Block and Data Block
- File의 이름과, File에 해당하는 I Node의 번호가 저장되어 있다.
- Directory Block과 Data Block 사이에 특별한 구분은 없다.
(Directory를 위한 내용이 있으면 Directory Block이고, File에 대한 내용이 있으면 Data Block이다.)
* Hierarchical Structre of File System
- 위 그림에서는 I Node가 Direct PTR들로 구성된다 가정한다.
- File과 Directory File에는 각각 하나의 I Node가 부여되어 있다.
- Directory File의 I Node가 지칭하고 있는 Disk Block에는
Parent File(..; Double Dot)의 I Node Number와
Current File(.; Single Dot)의 I Node Nume,
(Child File의 이름, 해당 Child File의 I Node Number) Pairs 정보가 저장되어 있다.
- File의 Path가 주어지면, Root Directory부터 Path를 참고하여, 해당 File의 I Node Number를 알아낸 다음,
해당 File의 I Node에 접근하여 데이터에 Access한다.
ex) Path : "/dirB/C" 를 통해 File C에 접근하면, Main Memory에는 25번 I Node가 Load된다.
- 또한, Path를 통한 접근 시, Path에 명시된 모든 File들의 I Node가 한 번씩은 Main Memory에 Load된다.
(즉, File Open시에는 꽤 많은 횟수의 Disk Access가 발생된다.)
* I Node Attribute: Link Count
- 한 File에 대해, 존재할 수 있는 Path의 개수이다.
- 예를 들어, 하나의 File에 접근할 수 있는 Path의 수가 4이면, 해당 File의 I Node의 Link Count 값은 4이다.
- Link Count는 다른 경로가 발견될 때 마다 1씩 증가한다.
(File System Tree를 모두 순회하며 Link Count를 계산하지 않는다.)
- 예를 들어, Directory A에 하위 Directory(Child Directory) B가 생생되면,
Directory B의 I Node에 Parent Directory A의 I Node #이 기록되므로,
Directory A의 Link Count가 1 증가하게 된다.
(하지만, Directory가 아닌, File이 생성될 땐 Parent Directory의 Link Count값에 변함이 없다.)
ex) 위 그림의 1267 Directory의 Link Count값이 3인 이유는
Current Directory(자기 자신)를 가리키는 Link,
Child Directory 2549에 존재하는 Link,
1267의 Parent의 Directory Block에 저장된 내용에 의해 지시되는 Link(그림에는 표현되지 않음)
때문이다.
※ Directory File의 Link Count값은 Child Directory가 생성될 때 마다 증가한다.
※ File의 Link Count값은 Directory Block내에 해당 File의 I Node #이 저장될 때 마다 증가한다.
(즉, 어떤 Directory에서 해당 File을 포함시킬 때 증가한다.)
Example. Open File in UNIX V7 File System
* 위 그림에서는 Root Directory의 I Node의 정보를 통해 Root의 Directory Block에 접근하는 것은 생략되었다.
- Root Directory에서 mbox File에 접근하기 까지의 Flow는 아래와 같다.
1) Root Directory의 I Node에 접근하여 Root Directory의 Directory Block에 접근 (그림에 없음)
2) Root Directory의 Directory Block에서 usr Directory의 I-Node #을 검색
usr Directory의 I-Node #은 6임을 알아내어 usr의 I-Node로 접근
3) usr I-Node로부터 usr Directory Block이 저장된 Disk Block Address 132를 통해 usr Directory Block에 접근
4) usr Directory Block에서 ast Directory의 I-Node #은 검색
ast Directory의 I-Node #은 26임을 알아내어 ast의 I-Node로 접근
5) ast의 I-Node로부터 ast Directory Block이 저장된 Disk Block Address 406을 통해 ast Directory Block에 접근
6) ast Directory Block에서 mbox 의 I-Node #을 검색
mbox의 I-Node #은 60임을 알아내어 mbox의 I-Node로 접근
Implementing Directories
- Directory Block에 (File 이름, File I-Node #) Pair를 저장지킬지,
I-Node #대신, I-Node의 모든 Contents(전체 File Attribute)를 다 저장시킬지는 구현에 따라 달라질 수 있다.
* I-Node가 저장하는 Contents = Size, Protection, Location on Disk(Direct PTR), Creation Time, Access Time, etc
- Directory List는 보통 Unordered 상태로 존재한다. (일반적으로, Sorting되어 있지 않다.)
(a) Simple Directory
- Fixed Size Entries로 구성된다.
- Directory Entry에 Disk Address와 Attribute가 모두 저장되어 있는 구조이다.
- MS-DOS, Windows에서 채택한 방식이다.
(b) Directory with I-Node
- Fixed Size Entries와 I-Node Number(#)들로 구성된다.
- Disk Address와 Attribute는 I-Node에 저장되어 있고, Directory Block에는 I-Node #이 저장되어 있다.
- UNIX에서 채택한 방식이다.
Handling File Name
(a) In-Line
- File 이름의 길이 정보(File 1 entry length)를 미리 저장해놓고,
File 이름을 저장할 수 있을 만큼의 공간을 확보하여 저장하는 방식이다.
- 즉, Entry의 크기가 가변적이다.
(b) In a Heap
- 여러 File의 이름들을 End Mark(\(\boxtimes\))로 서로 구분지어 놓은 상태로 Heap에 저장해놓고,
각 File의 Entry에서 해당 File 이름이 저장된 Heap의 위치를 Pointing하게 해놓은 방식이다.
- Entry의 크기가 고정적이다.
Speeding Up the File Name Search
- Path를 통해 File을 Root Directory부터 검색해갈 때의 Performance를 향상시키는 방법은 아래와 같다.
1) Using Hash Table
- File Name을 Hashing한다.
- Administration이 더욱 복잡해진다.
- Directory에 많은 File들이 저장될 때 적합하다.
2) Using Caching
- Search 결과를 Caching하는 방법이다.
- 자주 Search하는 File의 개수가 적을 때 적합하다. (Cache의 특성)
Tracking Free Block, Free I-Node
- File이 새롭게 생성되면Super Block에 저장되어 있는 정보를 토대로,
Free I-Node 중 하나를 선정하여 새로 생성된 File에 할당하게 된다.
- File에 Data가 입력되면 Data Block을 Free Block 중에서 선정하여 할당하게 된다.
(a) Linked List
- Free Block에 대한 정보를 Free Block에 저장하는 방식이다.
- Free Block들은 서로 연결되어 있다.
(그림과 달리, 16번 Block(왼쪽)의 끝에는 17이 저장되어 있고, 17번 Block(중간)의 끝에는 18이 저장되어 연결되어 있다.)
- 16번 Block에 저장되어 있는 Free Block들이 모두 File에 할당되하고, 16번 Block 자체도 할당된 이후에는
17번 Block의 Free Block들을 할당하게 된다.
(16번 Block 자체를 할당할 경우, 다음 Free Block들이 저장된 곳이 17번임을 Super Block에 저장해야한다.)
- 어차피 사용되지 않던 Free Block을 활용하는 방법이기 때문에, Bitmap보다 Disk 효율성이 높다.
(Free Block을 저장하는데 발생되는 Space Overhead가 없다.)
ex) 시판되는 500GB Disk의 경우, 488M개의 Block으로 구성되는데,
이 중 1.9M개의 Block들이 Free Block들을 저장하는데 사용된다.
(이렇게만 보면, Bitmap 방식보다 비효율적이라 볼 수 있겠지만, Linked List 방식은 어차피 사용되지 않던 Free Block을 활용하는 방법이기 때문에 Bitmap 방식보다 효율적이라 할 수 있다.)
(b) Bitmap
- File이 사용중인 Disk Block은 1, Free Block은 0으로 표시하는 방식이다.
- Bit의 순서와 Disk Block의 순서는 일치한다.
ex) 011이면, 첫 번째 Block은 Free Block이며, 두세번째 Block은 사용중인 Block임을 의미한다.
- Bitmap을 저장하기 위한 Block이 추가적으로 필요하게 된다. (Bitmap의 크기는 결코 작지 않다.)
ex) 시판되는 500GB Disk의 경우, 컴퓨터에서는 488M개의 Bit로 인식됨에 따라,
Bitmap은 60,000개의 1KB짜리 Block들을 요구한다.
Shared Files
- Path가 두 개 이상으로 존재할 수 있는 File을 의미한다.
(위 그림에서는, "/B/B/?" 와 "/C/C/C/?" 두 가지로 존재한다.)
- 같은 File을 Sharing하는 Directory들이 해당 Shared File에 대한 저마다의 Disk Address를 가지면 안되므로,
이에 대한 해결책들은 아래와 같다.
1) Using I-Node (= Hard Link Method)
- Shared File을 가진 Directory들이 해당 Shared File에 대해 같은 I-Node를 가리키게 하는 방법이다.
* Problem with I-Node Method
a) Owner Directory가 Shared File을 삭제해도, 삭제되지 않는 문제
- 위 그림의 (b)번 상황에서(두 개의 Directory가 File을 Share하는 상황)
C Directory에서 해당 File을 지워도, B Directory에서의 Path가 유효하기 때문에
해당 File은 삭제되지 않는 문제가 발생된다.
- 또한, 해당 File은 C Diretory에서 만들어졌기 때문에,
B Directory에서 접근할 경우 권한 문제로 인해 File에 대한 제어가 원활하지 못할 수 있다.
- 이에 대한 해결책으로는, Owner인 C Directory에서 해당 File을 삭제하면,
File System의 Tree 구조를 뒤져서 해당 File을 삭제시키는 방법이 있으나, Overhead가 너무 커서 현실적이지 못하다.
- UNIX System에서는 위 그림과 같이 Owner가 삭제해도, 다른 Path가 존재하면 해당 File을 삭제시키지 않는 방식을 채택하고 있다.
b) 다른 Partition에서 Shared File에 접근할 수 없는 문제
- I-Node는 하나의 Partition 내에서만 유효한 개념이기 때문에, 다른 Partition에서의 I-Node #는 무효하다.
2) Using Symbolic Link (= Soft Link Method)
- Directory Entry에 접근하여 해당 File이 LINK Type File임을 알아내면,
해당 File에 저장된 Path Name을 통해, 해당 File의 진짜 경로로 접근한다. (즉, 한번 더 Disk Access를 수행한다.)
- Hard Link와 달리, 해당 File의 Owner가 File을 삭제하면, 어떠한 방법으로도 해당 File에 접근할 수 없다.
(즉, 진짜 삭제된다.)
- Soft Link 방식에서는 다른 Partition의 File에 대한 Path Name을 생성할 수 있다. 즉, Hard Link 방식보다 Flexible하다.
- Windows에서는 Symbolic Link 개념이 "바로가기"로 구현되어 있다.
* Problem with Symbolic Link Method
- LINK Type의 File을 위한 I-Node가 필요하고, 그에 따른 Data Block이 하나 더 필요하게 된다.
- Directory Entry에 접근하여 LINK Type File에 저장된 Path Name을 얻어오기 위해,
Disk Access가 추가적으로 1회 더 수행된다.
Log-Structured File Systems
※ 대부분의 Read 연산은 File System의 Cache를 이용하여 Disk Access 횟수를 줄이는데 문제가 없지만,
File Structure에 관한 Write 연산에 Cache를 이용하게 되면,
Cache의 내용과 Disk의 내용에 차이가 생길 수 있고, 이로 인해 Crash가 발생될 수 있다.
- 그래서, File의 Meta Data*들은 Update될 때 마다, 곧바로 Disk에 Write된다. (Caching하지 않는다.)
- 이러한 Meta Data Update들은 Disk의 곳곳에서 소규모로 자주 발생되는데, 이들을 최적화하는 것이 Main Issue이다.
* Meta Data
- Data Block에 저장된 내용들 이외의 데이터를 통칭하는 용어이다.
- File System Structure에 관련된 데이터들이다.
- Update 된 내용들을 Segment 한 곳으로 모아서, Disk에 Log로 저장하는 방식이다.
- Log에는 최근에 변경된 I-Node Number, Directory Block, Data Block, Segment Summary 등이 저장된다.
- Log는 Disk 내에서 Continuous하게 저장되므로, Log의 Write Performance가 우수하다.
- 그러나, 가장 최근에 변경된 I-Node를 쉽게 알아내기 위해서는 Log 정보를 계속해서 Tracking하며
최근에 변경된 I-Node Number를 저장해놓고 있어야 한다.
- Cleaner를 통해 오래되어 쓸모없는 Segment들은 Free시켜서 Log의 크기가 무한정으로 커지는 것을 방지해야 한다.
Journaling File Systems
- 갑작스런 Power-Off나 Crash등으로 인해 File에 Failure가 발생했을 때, File System Check을 수행하게 되는데,
이는 실행시간이 적지 않은 Operation이다.
- 어떤 File Operation에 대한 Journal을 생성하여 해당 File Operation을 수행하기 이전에 Disk에 Journal을 저장한다.
- Operation이 수행된 후, Journal은 삭제된다.
- 만약, Operation을 수행하던 도중, Crash가 발생되어 Operation이 완료되지 못하면,
Journal에는 해당 Operation이 완료되었는지 아닌지에 대한 여부가 저장되어 있으므로,
해당 Operation의 Journal을 참고하여, 완전히 수행되지 못했다면, 해당 Operation을 처음부터 다시 수행한다.
(단, 일부과정이 반복되어도 지장이 없는 Idempotent Operation이어야 한다.)
- 또한, File Operation을 완료한 이후에는 해당 Journal을 삭제하는데,
File Operation을 완수한 후 Journal을 삭제하기 이전에 Crash가 발생하면, 해당 File Operation을 또 다시 수행한다.
(즉, File Operation을 수행하고 Journal을 삭제하는 과정까지가 하나의 과정이다.)
(Idempotent Operation이기 때문에 반복해도 문제는 없다. 단지, 시간이 더 소요될 뿐이다.)
- 즉, Journaling File System에서는 File System에 Crash가 발생하여 다시 시작할 때,
전체 File System을 점검할 필요 없이, Journal만 점검하면 된다.
Example. Removing File
Process of Removing a File
1) 해당 File을 Parent Directory Entry에서 삭제한다.
2) 해당 File에 할당된 I-Node를 Free시킨다.
3) 해당 File에 할당된 Data Block들을 Free시킨다.
- 만약, 2번 과정까지 수행한 후, Crash가 발생되었다면,
File System이 System으로 다시 Load될 때 1번 과정부터 다시 시작한다.
※ File System에서 Remove Operation을 구현할 경우, 반드시 위처럼 1~3번 순서로 구현해야 한다.
- 위 순서는 File System에 Crash가 발생되어 다시 재개해도 문제가 없게 수행하는 순서이다.
(File System의 종류에 관계없이, File System에 문제가 생겨 다시 재개되는 상황을 고려해야 한다.)
- 1번 과정이 먼저 선행됨으로써, 1번 과정을 수행한 후 Crash가 발생되고,
다른 File에서 Removing 대상이 되는 File의 Disk Block을 할당받아도 문제가 없게 된다.
Virtual File Systems
- Virtual File System은 다양한 File System을 하나로 아울러서 User Process에게 일관된 Interface를 제공한다.
File-System Management and Optimization
Disk Space Management
- Block Size는 그 크기에 따른 Trade-Off가 존재한다.
- 위 Table은 각 System에서 특정 Size의 File이 차지하는 비율을 누적하여 나타낸 결과이다.
ex) VU 2005에서 512Byte 이하의 File들이 전체 File System의 20.62%를 차지한다.
ex) VU 2005에서 Block Size를 1KB로 설정할 경우, 전체 File의 69.96%가 8개의 Direct PTR로 커버가 가능하다.
ex) VU 2005에서 Block Size를 4KB로 설정할 경우, 전체 File의 85.87%가 8개의 Direct PTR로 커버가 가능하다.
- 모든 File의 크기가 4KB라는 가정하에,
Block Size에 따른 Data Rate(데이터 전송량)과 Disk Utilization(디스크 활용률)의 변화를 나타낸 그래프이다.
- Block Size가 작으면, Block를 검색할 때의 Overhead로 인해 Date Rate이 느려지는 반면, Disk Utilization은 우수하다.
- Block Size가 커지면, 한 번에 옮겨지는 Block의 양이 많아 Date Rate이 우수한 반면, Disk Utilization은 떨어질 수 밖에 없다.
File System Backups
- Disasters, Stupidity로 인해 데이터의 손실에 대비하기 위해 Dump(Backup)이 필요하다.
* Backup = Dump
1) Incermental Dumps
- 처음 File System 전체를 백업한 이후에는 수정된 내용만 백업하는 형태이다.
2) Compressed Format Backup
- 데이터를 압축하여 백업하는 형태이다.
3) Offline or Online
- Offline Back up: 백업 시, System을 Stop시키고, Offline에서 File System을 Backup하는 형태이다.
- Online Back up: System을 Stop시키지 않고, 진행되는 동안에 File System을 Backup하는 형태이다.
- 백업의 종류로는 Physical Dump, Logical Dump
Backups: Physical Dump
- Disk Image를 그대로 Copy하는 백업하는 형태이다.
- 해당 Disk에 어떤 데이터가 있는지, 어떤 File System인지에 관계없이, Simple하고 빠르게 진행된다.
(부분적으로 백업하거나, 수정된 부분만 백업하거나, 특정 파일을 복구하는 등의 기능은 없다.)
- 사용되지 않는 Disk Block까지 모두 Copy하므로 비효율적일 수 있다.
- Disk에 Physical Bad Block이 있는 경우, 이에 대한 처리방법도 구현되어야 한다.
Backups: Logical Dump
- 해당 File System에 구성된 Tree 구조를 따라가며 백업하는 형태이다.
- 특정 Directory 혹은 Dump Directory에서 시작하여 하위 File들을 백업해나간다.
- File System을 Full Dump(전체 백업)한 이후에는,
특정 File 혹은 Directory만을 백업하거나 복구할 수 있고, 변화된 파일만 백업할 수 있다.
- 특정 파일만 백업할 수 있으므로, 빠르고 용량도 작다.
- 특히, 변화된 파일을 백업할 경우, Root에서 해당 File까지의 Path에 있는 모든 File들도 같이 백업되어야 한다.
(해당 File의 상위 File에 문제가 생겼을 경우에 대비해야 하기 때문이다.)
Example. Logical Dumping Algorithm
- 위 그림에서 회색으로 색칠된 Node들은 수정된 File 혹은 수정된 Directory를 의미한다.
(Node에 적힌 숫자는 I-Node Number를 의미한다.)
- 만약 3번 Node를 Dump하고자 한다면, Path에 있는 1번, 2번 Node도 같이 Dump된다.
(a) Modified File or Directory와 그들의 Path에 있는 모든 File or Directory들을 전부 Mark한다.
(b) Modified되지 않은 File or Directory들은 Unmark한다.
- 위 그림에서는 10, 11, 14, 27, 29, 30이 Unmark되었다.
- 즉 Modified File or Directory와 연관된 Node들만 Mark된 상태로 남는다.
(c) Makr된 Directory들을 모두 Dump한다.
(d) Mark된 File들을 모두 Dump한다.
File System Consistency
- File System의 Tree구조가 오류없이 잘 유지되고 있는지를 Check해야 한다.
- Block에 대한 Consistency Check와 File에 대한 Consistency Check를 수행한다.
- UNIX에서는 \(\texttt{fsck}\) Instruction을 통해, Windows에서는 \(\texttt{scandisk}\) Instruction을 통해
File System의 Free Block과 Used Block들을 확인하여 구조에 오류가 감지되면 에러 메시지를 출력한다.
Block Consistency Check
- File System의 Tree 구조 전체를 순회하면서 Block in use들을 모두 찾아낸다.
- Free Block List를 순회하며 Free Blocks들을 모두 찾아낸다.
(a) Consistent
- Disk Block들이 Consistent한 경우이다.
(b) Missing Block (Block 2)
- 특정 Block이 사용되고 있지도 않고, Free Block List에도 없는 상황이다.
- Data Block을 Free시키기 이전에 Crash가 발생되고, 이를 방치했을 때 야기될 수 있는 상황이다.
- 2번 Block을 Free Block List에 삽입하여 해결할 수 있다.
(c) Duplicate Block in Free List (Block 4)
- 특정 Block이 Free List에 두 번 이상 삽입된 경우이다.
- Bitmap 구조에서는 이러한 상황이 잘 발생되지 않지만, Linked List 구조에서는 이러한 상황이 발생될 수 있다.
- Duplicate Block을 하나만 남기고 전부 Pop시켜서 해결할 수 있다. (즉, 중복을 제거하면 된다.)
(d) Duplicate Data Block (Block 5) (Critical)
- 특정 Block이 두 File 이상에서 사용되고(할당되어) 있는 경우이다.
- 어느 한 쪽 File에 Data Block을 새로 할당하여 해결할 수 있다.
- 단, 중복되어 할당된 Block은 어떤 File의 데이터가 저장되어 있는지 시스템은 알 수가 없으므로,
해당 Block에 Contents를 복구하는 작업은 오로지 사용자의 몫이다. (즉, 기존의 Contents가 Overwrite될 수 밖에 없다.)
Directory Consistency Check
- File System의 Tree 구조를 순회하며 계산한 Usage Count값을 기존의 Link Count값과 비교하여 File System을 점검한다.
i) Link Count > Usage Count
- 측정 결과(Usage Count)가 기존의 Link Count값보다 작은 경우이다.
(즉, 원래 알려진 경로보다 실제로 접근할 수 있는 경로의 수가 더 적은 경우이다.)
- 이 상황이 Fix되지 않으면, File System Tree에서 해당 File을 삭제해도 Link Count값이 0이 되지 않아,
해당 File에 접근할 수는 없는데 할당된 Disk Block은 Free되지 않는 상태가 지속되게 된다.
- 이 경우, Link Count값을 Usage Count 값으로 대체하여 해결한다.
ii) Link Count < Usage Count
- 측정 결과(Usage Count)가 기존의 Link Count값보다 큰 경우이다.
(즉, 원래 알려진 경로보다 실제로 접근할 수 있는 경로의 수가 더 많은 경우이다.)
- 이 상황이 Fix되지 않으면, File System Tree에서 다수의 경로 중 어느 한 쪽 경로만 삭제했는데, Link Count 값이 0이 되어,
경로가 존재함에도 불구하고 해당 File에 할당된 Disk Block이 Free되게 된다.
- Disk Block이 Free되고, 다른 File에 할당되게 되면 다수의 File에서 같은 Disk Block을 사용하는 상황이 벌어질 수 있다.
- 이 경우, Link Count값을 Usage Count 값으로 대체하여 해결한다.
File System Performance
File System Cache
- Buffer Cache는 Disk Driver와 File System 사이에 위치하여 Cache의 역할을 한다.
- Disk Access 횟수를 줄이는 것을 목표로 하여 I/O 속도 향상을 도모한다.
- Cache를 사용한다는 것은 Disk Access에 Locality가 있다는 전제하에 진행되는 것이다.
- Buffer Cache는 Main Memory에 위치하게 되므로, Buffer Cache의 크기를 증가시키면
I/O 속도는 향상되는 대신, Main Memory의 가용 공간이 줄어드는 Trade-Off 관계가 있다.
- Buffer Cache Miss가 발생되면, 해당 Disk Block을 Disk에서 Buffer Cache에 새로 Load하게 되는데,
이 과정에서 다른 Caching Algorithm과 같이, Replacement가 발생된다.
(일반적으로 Full LRU* Replacement를 수행한다.)
* Full LRU
- I/O 명령은 Memory Reference처럼 자주 일어나는 연산이 아니기 때문에,
Memory에서와 같이 LRU를 Simulate하는 방식이 아닌, Full LRU를 수행한다.
(일반적으로, Linked-List를 이용한 FIFO Queue로 구현한다.)
File System Caching에서 LRU가 불리한 경우
1) I-Node를 Caching하는 경우
- 대개 I-Node는 한 번 Access한 이후, 곧바로 다시 Access하지 않는다.
2) Meta Data를 Caching하는 경우
- Meta Data(File Structure에 대한 정보 등)가 오랫동안 Cache Hit되어 Cache에만 저장되고,
Disk에는 오래된 정보만 남아있는 상태에서 Crash가 발생되면 결국 오래된 Meta Data만 남게된다.
- 이를 방지하기 위해, File System Meta Data가 Update되면 Cache에도 Overwrite하고, Disk에도 곧바로 Overwrite한다.
- 물론, Meta Data가 아닌, 일반적인 Data Block 또한 일정 주기로 Disk에 Overwrite한다.
(UNIX의 경우 Sync 혹은 Update Daemon, MS-DOS의 경우 Write-Through Cache로 구현되어 있다.)
※ 즉, Meta Data는 Write-Through 방식(곧바로 Disk에도 Write함)으로,
Data Block은 Write-Back 방식(일정 주기로 Cache를 Flush하고, Cache의 내용을 Disk에 Write함)으로 Caching한다.
- File System Caching에서는 Read Performance는 준수하지만, Write Performance가 미흡하여
Log Structured File System 개념이 등장했다.
LRU Replacement in File System Caching
- (Device ID, Block Number)값 Pair를 Hashing하여 Hash Table의 Index를 알아내어,
해당 Index로 Hash Table에 접근하여 Buffer Cache에 Access한다.
- Cache Hit의 경우, 해당 Buffer Cache를 Rear(MRU)로 옮긴다.
- I-Node가 저장된 Block의 경우, 자주 Access되지 않으므로,
Designer는 I-Node가 저장된 Block을 Caching할 지에 대한 여부를 결정해야한다.
- Buffer Cache의 크기(Allocation Unit)를 크게하여 다수의 Disk Block을 한꺼번에 Caching할 수도 있다.
(Internal Fragmentation문제가 발생될 수 있다.)
Defragmentation Disks
- File의 Data Block이 Disk의 곳곳에 흩어져 있어, 이들을 다시 한곳으로 모아주는 작업을 Defragmentation이라 한다.
- Data Block들이 산개해 있을수록,
해당 Data Block에 접근할 때 Disk Arm이 움직여야 하는 거리가 늘어나 I/O Performance를 저해하게 된다.
Reference: Modern Operating Systems 4E
(Andrew S. Tanenbaum, Herbert Bos 저, PEARSON, 2015)