
[Story 01 프로그래머가 프로세서도 알아야 해요?]
- 현대 CPU는 하나의 집적회로로 만들어진 마이크로프로세서로 표현하는 것이 더 바람직하다.
- 튜링머신: 디지털 컴퓨터를 극단적으로 추상화한 가상의 기계. 입력 테이프, 계산 장치, 출력 테이프,를 구성요소로 가진다. 계산 장치는 입력 테이프의 값과 현재 상태에 따라 다음 상태를 어디로 갈 것인지, 또 출력 테이프에 어떤 내용을 기록하는가를 정의한다. 이론적으로 모든 컴퓨터의 연산을 구현할 수 있다.
[Story 02 프로세서의 언어 : 명령어 집합 구조]
컴퓨터 구조 설계 첫 번째 원칙
"Make Common Case Fast"
- 컴퓨터 구조적 상태(architectural state): 외부에서 보이는 현재 프로세서의 상태. 현재 프로세서가 수행 중인 프로세스의 상태를 지닌 각종 레지스터의 값들. 멀티코어 프로세서는 이 컴퓨터 구조적 상태를 하드웨어 스레드(논리 프로세서) 개수만큼 동시에 가진다.
- 프로그래머는 자신이 만든 코드가 한 줄씩 순차적으로 실행되는 것으로 이해하고 있고 이것은 하나의 규범이다. 하지만, 현대 프로세서는 훨씬 복잡한 방법으로 처리하여 성능을 높이는 방식을 채택하고 있는데, 프로세서 실행 도중 상태를 살펴보면 순서가 지켜지지 않은 채로 있을 수 있다. 그러나 프로그래머와 프로세서 간 규범으로 인해 이런 복잡함은 프로그래머에게 노출시키지 않는다. 아무리 내부 구현이 복잡해도 프로세서는 프로그래머와 약속된 컴퓨터 구조적 상태를 정확하게 보여준다.
- 명령어 집합 구조(ISA, Instruction Set Architecture)
: 프로그래머와 프로세서가 직접적으로 소통할 수 있게하는 언어
- 프로그래밍 방법론을 정의할 뿐 아니라 프로세서 구현의 많은 부분도 ISA가 결정한다.
- 명령어 종류, 피연산자 타입, 레지스터 개수, 인코딩 방법 등 여러 가지를 ISA가 정의한다.
- 다른 종류의 프로세서들마다의 ISA끼리는 서로 호환이 되지 않는데, 이를 해결하기 위해 Sun사의 JVM, 마이크로소프트사의 Dot NET Framework 가 개발되었다.
- 실제로 프로그램이 구동되기 위해서는 ISA 위에 ABI(Application Binary Interface)라는 응용프로그램과 운영체제 사이의 약속도 필요하다. Calling Convections(함수호출규약)이나 바이너리 포맷에 대한 규약이 대표적이다.
* Instruction: 프로세서가 이해하는 명령어 하나하나.
- 명령어는 성격에 따라 여러 종류로 나뉘는 데,
1. 기본적인 사칙 연산, 논리 연산
2. 메모리에 쓰고 읽는 명령
3. 프로그램의 실행 흐름을 제어하는 분기, 호출 명령
들로 크게 구분지을 수 있다.
그 외에도 시스템 내부를 제어하거나 상태를 관찰하는 명령도 있다.
- 인코딩(encoding): 명령어를 기계어로 변환하는 것
- 디코딩(decoding): 기계어를 명령어로 변환하는 것
CISC (Complex Instruction Set Computer)
: 과거 메모리가 매우 비싸던 시절, 명령어의 크기가 조금이라도 작았어야 했던 때에는 짧은 길이의 명령어에 많은 뜻을 함축시켰어야 했다. 이러한 이유로 최초의 ISA는 복잡한 형태의 CISC의 형태를 띄었다.
: CISC의 내부에서는 하나의 instruction을 micro-op로 쪼개어 마치 RISC처럼 작동시키며, 복잡한 CISC 명령어를 해독하는 로직을 따로 운용한다. 즉, CISC에서는 RISC의 장점을 이용할 여지는 있다.
- 대표적인 예로 인텔의 x86 명령어 구조, 이제는 사라진 DEC의 VAX(Virtual Address Extension)명령어 구조 등이 있다.
- 명령어 길이가 가변적, 여러 복잡한 형태의 Addressing mode, 비교적 많지 않은 범용 레지스터(GPR)의 수.
- Register spill: 자주 사용하는 데이터는 레지스터에, 자주 사용되지 않는 데이터는 메모리에 저장하는 방식
- CISC는 RISC에 비해 프로그래머가 접근 가능한 레지스터 수가 부족하여 레지스터에 저장되는 데이터 수가 적고 큰 크기의 캐시로 어느 정도 극복은 가능하지만 많은 수의 메모리 입출력 명령어들은 성능을 저하시키는 주요한 원인이 되며, 이런메모리 입출력을 어떻게 효율적으로 처리할 지는 매우 중요한 이슈가 된다.
RISC (Reduced Instruction Set Computer)
: 1970년대 IBM 연구원들은 실제 사용되는 명령어 종류가 그렇게 많지 않다는 사실을 밝혀냈다. 컴파일러가 CISC 명령어 집합이 지원하는 모든 명령어와 주소 모드를 사용하지 않고 일부만 자주 사용했다.
: 간단한 명령어는 그만큼 회로가 단순해져 더 저렴한 비용으로 제조할 수 있게 하지만, 소프트웨어인 컴파일러가 일을 더 하게 한다.
: 실제 사용하는 명령어 패턴은 훨씬 간단함을 발견하고, 명령어 크기를 고정시키고 그 개수를 대폭 줄인 명령어 구조가 RISC이다.
: CISC와 달리 명령어 길이가 고정적이므로 CISC가 간단히 처리할 수 있는 작업도 여러 단계에 거쳐서 해결해야 한다.
(ex. 크기가 큰 상수의 처리, Stack에서의 Push/Pop 연산 - CISC에선 Push/Pop 연산에 일대일로 대응하는 명령어가 있다.)
- 대표적인 예로 스마트폰에 많이 쓰이는 ARM과 IBM의 PowerPC, 그리고 MIPS(Microprocessor without Interlocked Pipeline Stages 가 있다.
* CISC는 컴퓨터 프로그램의 복잡함을 하드웨어가 도맡아 처리한다. RISC는 하드웨어의 복잡함을 일부 소프트웨어, 즉 컴파일러로 넘긴 형태이다. 이제는 기계어로 프로그래밍하는 경우는 드물고, 컴파일러가 똑똑하게 번역해주기에 굳이 ISA를 다양하게 제공할 필요가 없다. 이렇게 하드웨어의 복잡함을 덜어서 절약한 트렌지스터 수를 RISC는 성능 향상에 투자한 것이다. 결국, 프로그램을 빠르게 실행해야 한다는 목적은 같지만, 하드웨어와 소프트웨어가 어떻게 일을 분담하고, 어떻게 서로 소통하느냐는 문제를 RISC와 CISC는 다르게 접근하는 것이다.
번외 ISA: VLIW (Very Long Istruction Word) = IA-64
: 인텔 Itanium 프로세서에 쓰이는 ISA
: 하드웨어가 처리해야 할 많은 부분을 소프트웨어로 넘긴 형태가 특징
[Story 03 프로세서의 기본 부품과 개념들]
Microarchitecture (u-arch): 마이크로프로세서 하나를 만드는 데 필요한 알고리즘 및 회로 수준의 구조를 자세히 정의해놓은 것
ex) intel- Pentium pro P6 구조
현대 마이크로프로세서 설계단계
1. 마이크로아키텍처 설계: 목표한 성능을 가능케 하는 여러 알고리즘과 테크닉을 개발
- 고안한 아이디어가 합리적인지를 성능 모델을 만들어 평가한다.
- 평가는 보통 시뮬레이터를 이용하며, 아이디어가 몇 사이클이나 아낄 수 있는지, 전력은 얼마나 아낄 수 있는지 등을 평가한다.
- 위 과정을 통해 정제된 마이크로아키텍처의 알고리즘은 RTL (Register transfer Language) 로 기술된다.
2. 로직 설계: 앞서 얻은 RTL 코드를 실제 하드웨어 구현에 적합한지 테스트하고 최종적으로 HDL (Hardware -Description Language) 로 기술한다.
- 캐시 알고리즘이 우수해도 이를 직접 효율적인 회로로 만드는 기술은 컴퓨터공학과는 또 다른 영역이다.
- 즉, 전자공학의 영역...
산술 논리 장치 (ALU, Arithmetic Logical Unit)
ALU가 지원하는 연산
- 정수 사칙 연산: + - * /
- 비트 논리 연산: AND, OR, XOR, 1의 보수
- 비트 시프트 연산: 왼쪽(<<), 오른쪽(>>)

* 위와 같은 기본 연산은 보통 프로세서가 명령어로 바로 지원한다.
ex) x86 ISA는 add, sub, imul, idiv, and, or, xor 같은 연산 명령어가 있으며, ||, &&와 같은 Boolean 연산은 별도의 명령어가 아닌 분기문의 조합으로 구성된다.
i = j & k; // AND 연산
// intel x86에서의 비트 AND 연산 구현방법
mov eax, dword ptr [k] ! 레지스터 eax에 변수 k값 저장
and eax, dword ptr [j] ! j와 eax 값을 & 연산한 후, 결과를 eax에 저장
mov dword ptr [i], eax ! eax에 있는 값을 변수 i에 저장
부동소수점 처리
- 실수는 보통 IEEE 754 규약에 따라 2진수 부동소수점 형태로 표현된다.
- 정수와 달리 IEEE 754에 따른 실수 표현은 근사적 표현이라는 컴퓨터 구조적 특수로 인해 발생하는 점을 프로그래머는 이해해야 한다.
- 과거, 회로 집적도가 낮았던 시절 FPU를 프로세서와 같은 die위에 놓을 수 없어 FPU는 프로세서 외부에 위치하여 보조 연산 장치로 지원되었다. ex) Intel x86 Coprocessor
- 현재 FPU는 프로세서 내부에 내장되어 있다.
* Intel Pentium processor FDIV (Floating Division) 버그
- 과거 RISC 타입 컴퓨터가 부동소수점 연산을 더 빠르게 처리하였는데, 그래서 팬티엄 설계자들은 이전 세대 486DX에 쓰인 부동 소수점 처리기보다 더 빠른 장치를 만들고자 새로운 알고리즘을 도입했다. 이 때, 전통적인 방식 대신 테이블을 이용해 빠르게 계산하는 것이 특징인 "SRT 알고리즘"을 도입한다.
- 이 테이블은 총 2,048 X 2,048 크기의 행렬로 표현되었는데, 실제 값이 들어있는 경우는 1,066개였다.
- 이 과정에서 인텔의 한 엔지니어가 이 테이블을 만들다가 실수로 5개 항목을 빠뜨렸는데, 이 부분이 테스트 과정에서 발견되지 못한 채로 실제 칩으로 구현되어 판매되기 시작했다.
- 이 버그는 실생활에서 발견될 확률은 극히 낮았지만 엄밀한 계산이 필요한 분야에서는 이러한 버그를 무시할 수 없었다.
- FDIV 버그는 1994년 한 교수가 이전 프로세서의 결과와 펜티엄 칩의 결과가 서로 다른 것을 보고 발견되었고, 인텔은 막대한 비용을 들여 펜티엄 칩을 회수해야 했다.
- 이 예시는 부동소수점 처리기 설계가 결코 쉽지 않음을 보여주며, 이외에도 마이크로소프트의 엑셀 2007 버전에서 부동소수점 계산에 오류가 있음이 확인되기도 했다.
Finite State Machine (유한 상태 기계)
Clock: 오케스트라에서 지휘자에 해당하는 개념. 회로에 마디(Cycle에 해당하는 개념)의 시작을 알리는 신호를 준다.
ex) 클럭 속도가 2GHz인 프로세서는 1초에 20억번까지 내부 상태(State)가 바뀔 수 있음을 의미한다.
State: 마디에 해당하는 개념. 이름 그대로 상태를 의미한다.
Finite State Machine: 디지털 회로와 같은 의미의 용어. 기계어 명령 하나를 처리하려면 시작 상태(State)에서 출발하여 여러 중간 상태(State)들을 지나 마지막 상태(State)로 도달해야 하나의 명령이 완료됨에서 유래된 용어이다.
Memory Hierarchy (메모리 계층)
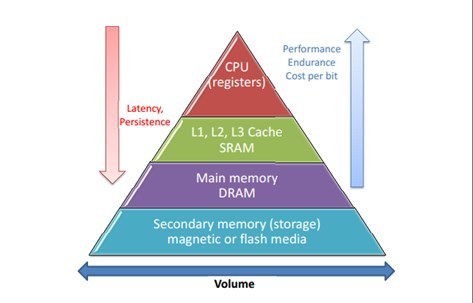
- 메인 메모리는 현재 DRAM (Dynamic Random Access Memory) 으로 구현된다.
문제는 DRAM이 현재 기술로는 프로세서에서 멀리 떨어진 곳에 있을 수 밖에 없고, 데이터를 가져오는일도 비교적 많은 사이클이 지나야 완수된다.
- 위와 같은 속도 차이(병목 현상)를 극복하려면 레지스터와 메인 메모리 사이에 캐시 메모리가 필요하다.
GPR (General Purpose Register, 범용 목적 레지스터): 프로세서가 메모리에서 데이터를 읽어 계산하는 과정에서 값들을 임시로 저장할 목적으로 사용하는 레지스터
PC (Program Counter): 현재 수행중인 명령어의 주소를 저장하는 레지스터
디버거에서 중단점에 해당하는 위치가 PC에 저장되어 있는 주소이다.
x86에서는 IP(Instruction Pointer)라 칭한다. 32비트에서는 EIP 레지스터, 64비트 RIP 레지스터가 이에 해당한다.
CR (Control Register): 시스템 내부 상태를 관리/저장하는 레지스터로, CR은 x86 프로세서에 있는 레지스터 이름이다.
CR0, CR4는 컨트롤 상태를 저장하고 있으며, CR3는 현재 수행 중인 프로세스의 페이지 테이블(가상 메모리 변환을 위한 자료구조)을 가리킨다.
* 상기에 명시된 레지스터들은 프로그래머가 볼 수 있는 구조 레지스터(Architectural Registers = Logical Registers, 논리 레지스터) 라 하며, 외부로 노출되지 않는 레지스터를 물리 레지스터(Physical Registers)라 한다.
Register File: 레지스터 배열에 읽기/쓰기 함수가 제공되는 형태
Control Unit
- 명령어를 메모리에서 읽어와서 해독하고 이를 적절한 ALU에 넣어 결과 값을 얻게하는 장치들을 통칭하는 개념.
- ALU나 레지스터 파일은 Data path로 구분된다. (Control unit 아님!)
* Processor = Control unit + Data path
Process & Thread
Process: 실행 중인 프로그램
Thread: 프로세서를 사용하는 최소 단위, 여러 스레드가 하나의 프로세스 내에 만들어질 수 있다.
컴퓨터 구조적 상태는 현재 실행 중인 프로세스&스레드의 상태를 보여주는데,
스레드는 자신의 레지스터 상태나 호출 스택 상태를 가지고 있어 하나의 실행 흐름을 유지한다.
PID(프로세스 ID), 주소 공간, 프로세스 우선순위, 현재 열려 있는 파일 목록 같은 것은 프로세스가 가지고 있다.
위에 열거한 것들을 통칭해 문맥(Context)이라 칭한다.
OS는 문맥 교환(Context Switching)으로 여러 스레드와 프로세스를 제한된 수의 프로세서에 최대한 공정하고 균형있게 배분한다.
현대 OS는 선점형(Preemptive) 멀티태스킹을 구현한다.
* Round-Robin Scheduling: 정해진 시간이 지나면 스레드가 계속 프로세서를 요구해도 무시하고 우선순위를 고려해 다음 스레드에 프로세서를 쓸 기회를 주는 스케쥴링 방식
가상 메모리 (Virtual Memory)
- 프로세스마다 연속적이고 충분히 큰 가상 메모리가 있게끔 함으로써 물리 메모리보다 더 큰 메모리를 가용할 수 있게 하며, OS의 안정성 또한 크게 향상시키는 기능을 하는 기법.
- 가상 메모리 개념은 실제 컴퓨터의 메모리 수준에 관계없이, 32비트 OS라면 4GB의 메모리가 있다고 가정하고 프로그래밍을 하고, 가상 메모리가 실제로 어떻게 물리 메모리로 연결되는지는 OS가 처리할 일이니 저수준의 최적화 작업이 아닌 이상, 프로그래머가 신경 써야할 영역이 줄어들어 편리해진다는 이점이 있다.
- 또한 가상 메모리의 다른 중요한 의미로 OS의 안정성을 제고시킨다는 점이 있다. 가상 메모리는 프로세스마다 각자의 주소 공간을 할당하므로 하나의 프로세스가 다른 프로세스의 데이터를 침범하는 일을 방지한다. 다른 프로세스가 사용하는 데이터의 주소를 알아내도 실제 물리 메모리 주소까지는 알지 못한다는 원리이다. 사실 이는 프로세스 간에 데이터를 공유해야 될 때 방해가 될 수 있는데, 이 점에서 OS는 IPC(Inter Process Communication), 파이프, 공유 메모리(Memory Mapped File과 같은 것)와 같은 방법으로 극복한다.가상 메모리는 "부족한 물리 메모리를 하드디스크를 이용해 확장시키는 것"이라기 보다는 "프로세스마다 고유한 주소 공간을 부여해 서로 침범할 수 없게 하는 것"이라고 이해하는 것이 더 바람직하다.
* Address space (주소 공간): 프로세스마다 주어지는 가상 메모리. 32비트 OS에서 각 프로세스는 2^32byte (=4GB)* 만큼의 가상 메모리 공간을 가진다. OS 부팅 후, 많은 프로세스가 가동되는데, 이 프로세스들은 모두 각자 4GB 만큼의 메모리를 가지고 있다고 생각하며 프로그램을 실행하게 된다.
이 주소 공간은 커널 영역, 텍스트(프로그램 코드가 위치하는 영역), 데이터(전역 변수 등), heap(동적 메모리), 스택(함수 호출, 지역 변수 등)으로 논리적으로 나뉜다.
* KB, MB, GB 같은 데이터 양의 단위는 10진수 기반이라 1KB는 1,024byte가 아닌 1,000byte이다. 2진수 기반의 단위는 KiB(키비바이트), MiB(메비바이트), GiB(기비바이트) 등이 있으며 1KiB = 1,024byte가 된다. 2^32byte는 엄밀히 말하면 4GiB가 맞으나, 관례적으로 4GB라고 표기한다.
* 가상 메모리 주소를 물리 메모리 주소로 변환하는 방법
: OS와 프로세서가 가상 메모리 주소를 물리 메모리 주소로 변환하는 방식은 가상 주소를 받아서 물리 주소로 변환하는 함수에 입력하여 그 변환 내역을 기억하는 것이다. 그런데 가상 주소의 범위가 2^32 또는 2^64 이므로 바이트 단위로의 가상 주소에 대응되는 물리 주소를 기억하는 것을 불가능하다. 그래서 주소 변환을 용이하게 하기 위해 OS는 Page라는 고정된 크기의 덩어리로 나누어 가상 메모리를 관리한다(가상 메모리는 항상 페이지 단위로만 할당되고 반환된다). 그리고 OS는 각 프로세스마다 페이지를 Page table을 이용해 물리 메모리로 변환한다. 하드웨어도 이 부분을 가속하기 위한 메모리 변환 장치와 TLB(Translation Lookaside Buffer)라는 캐시를 지원한다.
* Heap memory 관리자(malloc, new 등)들의 역할
: 대부분의 프로그램들에서 페이지 크기보다 훨씬 작은 크기의 메모리를 빈번히 할당시키는 역할을 한다. OS로부터 페이지 단위의 커다란 가상 메모리를 얻어온 뒤(Win32의 VirtualAlloc, Linux의 sbrk 함수)작은 크기로 나누어 프로그램들에게 할당한다. 따라서 힙 할당자는 커널 영역이 아닌 유저 영역에서 작동한다.
* OS설치 시에 할당하는 Page/Swap 파일의 역할
: 프로세스가 최초로 실행될 때엔 코드와 데이터가 디스크에 있게 되는데, 한 프로그램이 실제 물리 메모리 용량보다 더 많은 메모리를 쓴다면 쓰지 않는 페이지를 디스크로 잠시 보냄으로써 부족한 물리 메모리의 한계를 극복하게한다.
* Page fault
: 가상 메모리 주소 -> 물리 메모리 주소 변환과정에서 변환하고자 하는 가상 주소의 mapping 관계가 아직 Page table에 없는 예외 상황.
: Page fault가 살뱅하면 현재 프로그램으 실행을 잠시 멈추고 제어권을 OS에 다시 돌려주게된다. OS는 디스크에서 이 페이지 내용을 읽어 메인 메모리에 저장하고 Page table에 유효한 mapping 관계를 작성한다. 긜고 중단지점부터 프로그램이 다시 실행되게 한다.
* 각 Page는 권한 여부 또한 갖고 있기 때문에, 읽기/쓰기/실행 권한의 유무가 Page마다 설정돼있다. 프로세스가 Page에 대해 읽기/쓰기/실행 권한이 있는지를 검사한다.
: 이 또한 프로그램의 안정성을 높이는 역할을 한다.
[Story 04 암달의 법칙과 프로세서의 성능 지표]
암달의 법칙
\(Amdahl`s\ law: {{1}\over{(1-P)+{P \over S}}}\)
: 전체 프로그램 시간(1이라는 전제 하에) 중 P 부분이 S만큼 개선될 때 기대되는 전체 성능 향상
이러한 종류의 성능 향상을 보통 "Speed up"이라고 부른다.
P: 최적화된 부분의 비율, S: 최적화된 부분의 성능 향상 (스피드업)
- 암달의 법칙은 프로그래머가 프로그램 성능을 개선시킬 때, 가장 많은 시간이 소요되는 부분을 중점적으로 개발시켜야 함을 의미한다.
- 자세히는, 병렬 컴퓨팅에서 컴퓨터 성능 최적화의 한계점을 측정할 때 이용하는 공식이다.
- 프로세서 설계자 역시 자신이 최적화하려는 부분이 전체에서 얼마나 중요한지를 생각하고 우선순위를 결정해야 한다.
- "Make the common case fast."와 일맥상통한다.
* 노르웨이계 미국 컴퓨터 공학자인 Gene amdahl의 이름을 딴 법칙이다. IBM에서 Mainframe개발에 크게 공헌했다.
병렬처리에서의 암달의 법칙
\({1 \over {(1-P) + {P \over N}}}\)
P: 병렬화가 가능한 부분의 비율, N: 프로세서 개수
: 직렬화 가능한 부분(1-P)은 최소화, 병렬화 가능한 부분은 최대화 하는 것이 핵심이다.
* 암달의 법칙의 제한
- 프로세서 N이 완벽하게 P만큼의 일을 병렬 처리한다는 이상적인 가정 하에 세워진 공식이며,
또, 병렬성에 대한 구체적인 정의 없이 단순히 병렬 가능한 부분이 오나벽히 프로세서 개수만큼 수행 시간이 줄어든다고 가정했다. 실제 병렬화 후 얻어지는 성능은 이보다 크게 낮을 가능성이 있다.
- 병렬화에는 스레드 생성 비용과 같은 고정 비용 및 프로세스/스레드 사이에 뮤텍스* 같은 동기화 객체로 효율이 떨어지게 되므로 큰 성능 향상이 이루어지지 않을 수 있다.
* MUTEX: 상호 배제(MUTual EXclusion)의 약자이다.
* Embarrassingly parallel: 주어진 작업이 별 노력 없이 완벽히 병렬화 가능한 경우에 해당 작업을 지칭하는 용어
프로그램 수행시간
- 컴퓨터의 속도는 프로그램을 얼마나 빠르게 완료하는가(1), 단위 시간당 얼마나 많이 처리 가능한가(2) 이 두가지 요소로 판단할 수 있다.
(1) Latency: 응답 시간(response time) 또는 실행 시간(execution time) 과 반대되는 개념이며, 레이턴시는 보통 지연시간을 의미한다. 레이턴시를 개선한다고 하면 보통 레이턴시를 낮추는 것을 의미한다. 레이턴시를 개선하기 위해 대표적으로 사용하는 수단이 Cache이다.
\(T= N*T_{inst}\)
T: 프로그램 전체 실행시간, N: 주어진 프로그램이 실행한 명렁어 수, \(T_{inst}\): 한 명령어를 처리하는데 드는 평균 시간
: 현대 OS는 여러 프로그램과 백그라운드 서비스가 작동 중이어서 이런 이상적인 공식이 정확히 들어맞지는 않으나, 충분히 큰 N이라면 이런 잡음은 무시할 정도가 되어버린다.
: 실행한 명령어의 개수 N의 경우, static한 크기가 아닌, dynamic하게 실행될 때의 명령어 개수를 의미하므로 정확히 계산하려면 프로그램이 실제 입력 값으로 실행될 때 어떤 명령어가 실행되는지 그 trace를 뽑아야 한다. 이런 작업은 보통 instrumentation 기법으로 쉽게 구현할 수 있다.
: 명령어 하나를 처리하는데 걸리는 평균 시간 \(T_{inst}\)은 프로그램 내에 존재하는 종류별 명령어 분포와 각각의 명령어 종류가 해당 프로세서에서 수행될 때 평균적으로 얼만큼의 시간이 걸리는지를 알아야 한다.
전자의 경우, 위에서 언급한대로 프로그램의 실행 trace를 분석해 간단히 알아낼 수 있고, 명령어 종류별 처리시간은 프로세서 제조사가 정보를 공개했다면 쉽게 알 수 있다. 하지만 공개하지 않았더라도 실험을 통해 어느 정도 추측은 가능하다.
* \(T_{inst}\)의 단위는 sec/instruction 인데, 이 값은 프로세서의 클럭 속도에 따라 다르므로 시간 차원 대신 cycle로 치환하는 것이 낫다. 그렇다면 CPI(Clock per Instruction, 명령어 당 평균 소요 사이클)를 이용하여 \(T = N * CPI * T_{cycle}\) 이렇게 바꿀 수 있겠다. 앞서 말했듯이, 명령어 종류마다 처리 시간이 상이하므로 좀 더 상세하게 수정하면,\(\ T = (\sum_{i} N_{i}*CPI_{i})*T_{cycle}\) 로 수정할 수 있겠다.
* ISA가 같은 두 프로세서의 성능을 비교할 때는 동일한 벤치마크 프로그램을 돌리기 때문에 \(N\)항은 같은 값일 것이다. 클럭(\(T_{cycle}\)의 역수)도 같을 것이기 때문에 결국 CPI값만을 비교하면 된다. 그러나 보통 CPI보다는 이것의 역수, IPC(한 사이클 당 수행한 명령어 수)를 더 자주 이용한다. 최신 프로세서는 슈퍼스케일러를 이용하므로 한 사이클에 하나 이상의 명령어를 수행한다.
예를 들어, 캐시 관리 정책을 개선하고 성능 향상도를 체크하고 싶다면, IPC가 가장 좋은 지표가 된다.
ex) MIPS : Million Instructions Per Second ; 1초당 수행된 명령어 수를 백만 단위로 표기한 것, 단순히 단위 시간당 수행된 명령어 개수만 헤아리는 탓에 다른 ISA라면 결과 값이 다를 수 있으며, 이상적인 명령어 흐름에서 최고값(peak value)를 주로 사용해서 오해의 여지가 있음
ex) FLOPS : FLOating point Per Second ; 초당 부동소수점 명령어 처리수를 의미, GPU의 성능을 표현할 때 자주 쓰임
(2) Throughput: 우리말로 처리율이라 하며 단위 시간당 얼마나 많이 처리할 수 있는가에 대한 양이다. 처리율을 향상시키는 대표적인 기법이 Pipelining 이다.
성능 향상 기법
1. 명령어 개수 N을 줄이는 방법
- 컴파일러는 여러 최적화 기법으로 그 의미를 헤치지 않는 정도에서 불필요한 연산을 제거/대체한다.
: 대표적인 최적화로 Common Sub-expression Elimination(중복 수식 제거), Constant Propagation(상수 전파), Dead Store Elimination(죽은 쓰기 제거)등이 있고, 고급 최적화 기법 중 PRE(Partial Redundancy Elimination, 부분 중복 제거)도 있는데, 예를 들어 (a+b)가 반복해서 나온다면 이를 미리 한 번만 계산해놓고 이용하는 것이다. 또 어떤 변수가 상수로 정의되었다면 그 이후 변수가 사용되는 모든 곳을 컴파일시에 상수 값으로 대체하는 것이다. 이러한 최적화는 컴파일러가 프로그래머 이상으로 잘 수행하기 때문에 프로그래머의 최적화가 필요한 분야는 임베디드 환경처럼 컴파일러가 최적화를 지원하지 못하는 척박한 환경정도이다.
- 항상 프로그램 크기를 줄인다고 해서 성능향상이 이루어지는것은 아니며, Inlining(인라인화), Loop unrolling(루프 풀기)와 같은 기법을 통해 프로그램의 크기가 조금 늘지만 오히려 성능을 향상시키는 기법들도 있다. 하지만 이런 기법들은 trade-off(어느 한 쪽을 위해 다른쪽이 희생하는) 관계에 있어서 최적점을 찾아서 해당 기법을 적당한 횟수로 수행하는 것이 중요하다.
- 프로세서 내부에서 dynamic하게 명령어 개수를 줄이는 기법들도 있다.
ex) x86에서 구현된 Macro-op Fusion & Micro-op Fusion 기법 등
2. CPI를 줄이는 방법
- RISC는 가장 기본적인 연산이 주로 제공되므로 일반적으로 컴파일되는 기계어의 양이 많다고 볼 수 있다.(N이 커짐) 대신, RISC 명령어는 비교적 간단하기떄문에 CISC에 비해 CPI값이 낮다. 그래서 두 항의 상관관계를 조심스럽게 고려해야 한다.
- CISC 구조는 겉으로는 N값이 작고, CPI가 크다고 볼 수 있으나 내부에서는 RISC 형태의 uop(micro-op)로 나누어지므로 CISC 형태의 명령어 개수보다 마이크로옵에 대한 개수와 CPI를 고려하는 것에 역점을 두어야 한다.
- CPI는 마이크로아키텍처에 가장 큰 영향을 받는데, 캐시를 개선하거나 기타 여러 장치를 개선함으로써 이 값을 직접적으로 개선할 여지가 있다.
- CPI의 개선 기법으로 파이프라인, 슈퍼스케일러, 비순차 실행, 분기 예측, 투기적 실행 등이 있다. 이들은 모두 CPI를 줄이는(IPC를 늘리는) 방법이다.
3. Clock 속도를 증가시키는 방법
- 반도체 제조 기술(대표적으로 공정수준) 즉, 프로세서 제작에 쓰이는 회로의 기본 폭이 작으면 작을수록 같은 면적에 많은 트렌지스터를 집적시킬 수 있으므로 공정을 미세화함으로써 캐시 용량을 늘릴 수 있다.
- 컴퓨터 속도에 가장 큰 영향을 미치는 클럭 속도 또한 미세 공정을 통해 물리적으로 전자가 이동해야 하는 거리를 줄여서 개선시킬 수 있게된다.
- 마이크로아키텍처 수준에서도 클럭 속도를 개선시킬 수 있는 여지가 있는데, 클럭을 결정짓는 주요 요소는 한 사이클에 완료되어야 하는 일의 양인데, 이 일의 양을 줄이면 클럭 속도를 높일 수 있다.
[Story 05 프로그램의 의미를 결정 짓는 의존성]
- 의존성이 있는 명령어들은 반드시 그 순서대로 실행되어야만 정확한 문맥을 유지할 수 있다.
- 명령어 사이에 의존성이 없다면 이들은 어떤 순서, 병렬로 실행되어도 상관없다.
- 의존성 분석을 하며 컴파일러, 프로세서는 최적의 명령어 실행 순서를 정하게 되는데, 이를 보통
Instruction Reordering (명령어 재배치 최적화) 혹은 Instruction Scheduling (명령어 스케줄링 최적화) 라고 한다.
Data dependence(Data dependency, 데이터 의존성): 명령어들 사이의 데이터 흐름으로, 프로그램의 문맥을 결정하는 중요한 요소. 특히, 컴파일러 최적화 시에 의존성 파악은 가장 중요한 작업으로 꼽힌다. 컴파일러는 명령어들의 순서를 바꾸며 최적화를 수행하기도 하는데, 이때 의존성은 반드시 고려되어야 하는 요소이다. 의존성이 있는 명령어는 곧 순서대로 실행되어야 하는 명령어임을 의미한다.
- 명령어 사이에서 일어나는 데이터 의존성은 읽기/쓰기 순서에 따라 RAW, WAW, WAR로 나뉜다.
- 컴퓨터 구조에 한정지어, 이런 의존성을 Hazard로 표현하기도 하고, "RAW 해저드" 이런식으로 표현하기도 한다.
- 컴파일러 분야에서는 RAW 의존성을 Flow dependence(흐름 의존성), WAW 의존성을 Output dependence(출력 의존성), WAR 의존성을 Antidependence(반의존성) 이라고 부르기도 한다.
1. RAW: Read After Write (Flow dependence)
// RAW about "x"
x = y + 1;
z = x * 2;2. WAW: Write After Write (Output dependence)
// WAW about "x"
x = y + 1;
x = z * 2;3. WAR: Write After Read (Antidependence)
// WAR about "x"
z = x + 2;
x = y * 3;* RAW 의존성을 True dependence(진짜 의존성), WAW, WAR 의존성을 False dependence(가짜 의존성) 또는 Name dependence(이름 의존성) 으로 분류하곤 하는데, WAW/WAR 의존성은 RAW 의존성과 성격이 크게 다르고, 이 두 의존성은 약간의 트릭(변수 이름 바꾸기)으로 없앨 수 있기 때문에 이렇게 분류하는 것이다.
// Original WAR about "x"
Z = X * 2; // Read
X = Y + 1; // Write
A = X / 2; // Read
// 첫 번째, 두 번째 문장 사이에 WAR 의존성
// 두 번째, 세 번째 문장 사이에 RAW 의존성
// Avoding WAR
Z = X * 2; // Read
X1 = Y + 1; // "X1" Write
A = X1 / 2; // "X1" Read
// 첫 번째, 두 번째 문장 사이에 WAR 의존성은 해결됨!
// 두 번째, 세 번째 문장 사이에 RAW 의존성은 존재함!
// = RAW 의존성은 이런 변수 이름바꾸기로는 결코 해결하지 못한다!
Control dependence (컨트롤 의존성)
- Control flow(실행흐름)로 인해 생기는 의존성
ex) 분기문의 결정에 따라 결과가 달라지는 경우에 생기는 의존성
- Uncondition branch(무조건 분기)는 컨트롤 의존성을 만들지 않는다.
- Function call(함수 호출)의 경우, 이 자체는 무조건 분기를 하지만 호출이 완료되면 다음 문장으로 이어지므로 겉으로 보기에 컨트롤 의존성을 만들지 않는 것으로 볼 수 있으나, 함수 호출에 연관된 argument들이나 함수 내부에 복잡한 제어 흐름이 있다면 컨트롤 의존성 유무를 쉽게 판별할 수 없게 된다.
- 컨트롤 의존성은 PC 레지스터(실행해야할 명령어)에 의한 RAW 데이터 의존성으로 볼 수도 있다.
(분기문의 경우, PC값을 쓸 수 있는데, 명령어가 실행된다는 것은 PC 레지스터를 읽는 행위를 함축하고 있으므로)
- 컨트롤 의존성 파악 문제는 프로세서, 컴파일러, 소프트웨어 테스팅 등 전반적인 영역에서 필요하다.
* Interprocedural analysis (프로시저 간 분석)
: 하나의 함수 범위를 벗어나 함수 호출을 추적해가며 분석하는 것
* IPO (InterProcedural Optimization) : 프로시저간 최적화
Memory dependence (메모리 의존성)
- 비포인터형 데이터가 아닌, 포인터형 데이터들 사이에서 일어나는 의존성
- 의존성 파악을 위해 포인터 변수가 가리키는 목적지를 정확히 알야아만 파악할 수 있다.
(메모리 의존성에서의 주요 Issue)
- Load/Store 대상을 실행하지 않고서는 메모리 의존성 여부를 정확히 파악하기 어렵다.
- 컴파일러가 두 메모리 연산 사이에 의존성을 예측하는 것은 일반적으로 매우 어려운 과제인데, 이는 의존성 여부를 판단하려면 결국 두 메모리 연산이 가리키는 주소 값의 범위를 코드를 실행하지 않고서 알아내기는 어렵기 때문이다.
(이러한 문제들을 "Pointer analysis Problem (포인터 분석 문제)"라 한다.)
- 위와 같은 이유들로 인해 컴파일러는 보수적으로* 의존성 여부를 파악하는 경우가 많다.
(= 의존성 유무 여부가 불분명할 시에 그냥 의존성이 존재한다고 가정해 버리는 것.)
* 보수적 (Conservatively) : 어떤 판단을 할 때 최악의 상태라 가정하고 최대한 안전한 방향으로 선책하는 경향
* 공격적 (Aggressively) : "보수적으로"의 반의어
* Memory Disambiguation (메모리 명확화)
- 명령어들 사이에 메모리 의존성 유무를 판별하는 것
- 컴파일러에서는 포인터가 가리키는 값을 알아내야 하므로 Memory Disambiguation 을 Pointer Analysis 라 부르기도한다.
예시.
mov [esi+0], eax ; *(esi+0) = eax
mov ebx, [edi+8] ; ebx = *(edi+8);
mov [ebp-8], ecx ; *(ebp-8) = ecx;
add ebx, 1 ; ebx = ebx + 1;\(
\begin{cases}
RAW\;dependence, & \mbox{if }\mbox{ (edi+8) == (esi+0)} \\
WAR\;dependence, & \mbox{if }\mbox{ (ebp-8) == (edi+8)} \\
WAW\;dependence, & \mbox{if }\mbox{ (ebp-8) == (esi+0)}
\end{cases}
\)
Loop-carried Dependence (루프 전이 의존성)
- 데이터 의존성 중 루프에서 나타나는 특별한 형태의 의존성
- 루프 전이 의존성도 마찬가지로 RAW, WAR, WAW로 분류된다.
for (int i = 1; i < N; ++i)
A[i] = A[i-1] + 1; 루프 순환에 따른 2번 구문의 메모리 접근을 표현하자면,
i = 1: A[1] = A[0] + 1;
i = 2: A[2] = A[1] + 1; // A[1]에 대해 RAW 의존성 발생
i = 3: A[3] = A[2] + 1; // A[2]에 대해 RAW 의존성 발생
단, N=2일 경우 의존성을 만들지 않는다.
여기서, "배열 A는 이 루프에 대해 루프 전이 RAW 의존성을 가진다"라고 표현한다.
* Loop-independent Dependence (루프 무관 의존성)
- 루프 전이 의존성과 구분하여, 루프 순환 사이에 걸쳐 발생하지 않는 의존성
* 루프 전이 의존성과 루프 무관 의존성은 모두 데이터 의존성의 부분 집합이다.
루프 전이 WAR 의존성 해결 예시
(배열 복제로 의존성을 제거하는 방법 = 임시 배열(이름 바꾸기)을 통한 방법)
// WAR 의존성이 존재하는 코드
for (int i = 0; i < N-1; ++i)
A[i] = A[i+1] + 1;
// 임시 배열을 통해 WAR 의존성이 제거된 코드
int oldA[N];
memcpy (oldA, A, N * sizeof(int));
for (int i = 0; i < N-1; ++i)
A[i] = oldA[i+1] + 1;
* 이런식으로 루프에서 루프 전이 의존성이 제거되면 루프의 병렬화가 가능해진다.
- 각 루프의 순환이 여러 스레드애서 동시에 실행 가능해진다.
- 루프 전이 RAW 의존성은 알고리즘의 대폭적인 수정 없이는 제거하기가 힘들지만,
루프 전이 WAR/WAW는 프로그래밍 테크닉으로 회피하기가 가능하다.
- 컴파일러는 이런 의존성 분석을 통해 루프에 의존성이 없음을 판단하고 자동으로 병렬화할 수 있다.
- Loop Fusion(루프 병합), Loop Interchange(루프 바꾸기) 와 같은 최적화 기법도 의존성 분석을 반드시 거쳐야 한다.
[Story 06 프로세서 기본 동작]
- Microprocessor는 명령어 하나하나를 처리하므로 Instruction Set Processor(명령어 집합 프로세서) 라 부르기도 하며, 거시적으로 봤을 때, 프로세서는 프로그램에 있는 명령어의 흐름을 지시대로 처리해 Architectural State(컴퓨터 구조적 상태)만 약속대로 반영하는 역할을 한다. 미시적으로 본다면 명령어 하나를 처리해 그에 맞는 레지스터 및 메모리 상태를 변화시키는 것이 프로세서의 역할이라 볼 수 있다.
특성에 따른 명령어 구분
1. ALU Operation : 사칙 연산, AND, XOR 같은 비트 논리 연산
2. Memory Load : 피연산자에 기록된 메모리 주소를 구해 그 내용을 읽어 지정된 레지스터에 값을 쓴다.
3. Memory Store : 메모리 로드와 반대로 주어진 레지스터의 내용을 지정된 메모리 주소에 쓴다.
4. Branch : 주어진 조건을 계산해 (조건 분기문일 때)다음에 수행될 PC값을 얻는다.
명령어 처리의 기본적인 다섯 단계
- 대개, 명령어 처리 작업을 최대한 공통적인 세부 단계로 나누어 구현된다.
- 실제 프로세서 디자인 과정에서는 이런 다섯 단계에서 일부 단계를 합치거나 나누기도 한다.
1. IF (Instruction Fetch) : 명령어 인출
2. ID (Instruction Decoding) : 명령어 해독
3. OF (Operand Fetch) : 피연산자 인출
4. EX (Instruction Execution) : 명령어 실행
5. OS/WB (Operand Store/ Write Back) : 결과 저장
1. IF : Instruction Fetch
- 처리할 명령어를 메모리로 부터 가져오는 단계
- 처리할 명령어는 PC Register 혹은 IP Register 가 가리키는 주소에 있다.
- 명령어 캐시에서 PC가 가리키는 곳의 내용, 즉 아직 해독되지 않은 Raw Byte Data 뭉치를 읽어와 Byte Queue 에 넣는다.
* Instruction Fetch의 간략한 구현 : IL1에서 바이트 배열을 읽어 큐에 저장하는 과정
void CoreFetch::step() {
core_->memory_->ITLB_.CacheProcess();
// 명령어 TLB를 읽는 작업을 수행
// TLB: Translation Lookaside Buffer (고속 캐시의 일종)
core_->memory_->IL1_.CacheProcess();
// 명령어 캐시를 읽는 작업을 수행
// IL1: 1차 명령어 캐시
byteQ_.Request(pc_ & byteQ_line_mask);
// Byte Queue를 채우라고 지시
UpdatePC();
// PC값 업데이트 (다음 명령어를 가져올 곳을 계산)
core_->memory_->ITLB_.Enqueue(CACHE_READ, pc_, ITLB_Callback, ...);
core_->memory_->IL1.Enqueue(CACHE_READ, pc_, IL1_Callback, ...);
// 명령어 TLB와 캐시에 위 두 내용을 요청
// 여기서 Callback은 이벤트 핸들러 콜백 함수를 의미하며,
// 캐시 내에서 발생하는 이벤트를 처리하는 역할을 한다.
}* TLB (Translation Lookaside Buffer)
- VPN 변환(가상주소를 프로세스의 페이지 테이블을 참조하여 물리주소로 변환하는 작업, VPN -> PPN)이 반복되는 경우에 실행시간을 개선시켜주는 캐시
- 프로그래머가 보는 메모리는 프로세스마다 가상 주소 공간을 사용하게 되는데, 이 때문에 데이터뿐 아니라 코드 역시 모두 가상 주소 기반이므로 PC에 저장되어 있는 값도 가상 주소이다. 따라서, 이 PC값에 해당하는 데이터를 읽어오기 위해 가상 주소를 실제 물리 주소로 변환하는 작업이 필요한데, 이 작업을 보통 MMU(Memory Management Unit)라는 장치가 처리한다. TLB는 이 MMU라는 처리장치를 보조하는 역할을 하는 캐시인 것이다.
- 보통 1차 캐시가 데이터 캐시와 명령어 캐시로 분리되듯, TLB도 ITLB (명령어 TLB) 와 DTLB (데이터 TLB) 로 나뉜다.
UpdatePC( )
- RISC의 경우 모든 명령어가 4 Byte로 구성되어 있어 UpdatePC() 함수를 "PC += 4" 정도로 구현할 수 있다.
(CISC의 경우 가변 길이 명령어를 사용하므로 이렇게 간단히 구현하기가 사실상 불가)
- 분기문, 함수 호출문의 경우 PC값 수정이 간단치 않다. 분기문은 무조건 분기문과 조건 분기문으로 나뉘며 또, 분기 목적지를 바로 알 수 있는 경우(직접 분기문)와 그렇지 않는 경우(간접 분기문)로 나뉘므로 분기문의 종류에 따라 PC값을 적절히 구하는 테크닉이 필요하다.
void UpdatePC() {
Mop_t* Mop = Oracle_->Execute(pc_);
if(Mop->IsBranchOrCall())
pc_ = Oracle_.어디로_갈지_알려주세요(Mop);
else
pc_ = pc_ + Mop->Length();
}
// "Oracle" 이란, CPU 시뮬레이터를 만들 때
// 쉽게 프로그램을 검증할 목적으로 앞으로 일어날 모든일을 알려주는 역할을 하는 모듈이다.
// "Mop_t" 란, x86 CISC 명령어를 나타내는 Macro-op(Micro-op의 반대개념) 자료구조이다.[Story 07 고성능 프로세서의 시작 : 명령어 파이프라인]
- 파이프라인은 작업을 여러 단계로 나누고 세부 단계가 서로 동시에 실행될 수 있게 한다. 이 방법으로 명령어 처리율(Throughput)을 극대화해서 프로세서 성능을 크게 향상시킨다. H/W 개념뿐만 아니라 S/W 에도 널리 쓰이는 기법이다.
- 파이프라인은 연속으로 주어지는 어떤 작업을 처리하는 데 있어 처리율을 높이는 일반적인 알고리즘을 가리킨다. 파이프라인 알고리즘의 핵심은 재사용과 병렬 실행이다. 먼저, 파이프라인화 하려는 작업을 여러 세부 단계로 나눈 다음 처리할 첫 번째 데이터는 파이프라인의 첫 번째 단계로 들어가서 그 작업을 완료한다. 이 데이터는 두 번째 단계로 넘어가고 첫 번째 단계는 비게 되는데 이때 다음 데이터를 받아 첫 번째 단계에서 처리하면 동시에 두 데이터가 처리된다. 이런 방법으로 처리율, 단위 시간당 처리할 수 있는 일의 양을 크게 향상시킬 수 있다.
- 이상적인 파이프라인 처리율 : \(Throughput = {N-1 \over k} + 1 ; N\) : 동시에 처리되는 Task 수, \(k\) : 분할된 파이프라인 단계 수
- 일반적으로, 파이프라인의 단계는 분기문의 결과를 알 수 있는 단계까지로 정의되는데, 이는 분기문의 결과가 밝혀진다는 것은 투기적 실행(speculation)을 구현하는 대부분 프로세서에서 상당이 중요한 일로 간주되기 때문이다.
- 파이프라인 깊이(pipeline depth) : 파이프라인 단계 수, 파이프라인 설계에 있어 파이프라인 깊이는 성능에 큰 영향을 미치는 중요한 설계 변수이다. 파이프라인 깊이가 곧 프로세서의 클럭 속도를 결정하기 때문이다. 파이프라인의 한 단계는 한 사이클 내에 완료되어져야 한다. 깊이가 깊어지면, 다시 말해 파이프라인 단계를 더 잘게 나누어 단계 수를 늘리면, 각 단계에서 해야 할 일의 양이 줄어들게 되어 보다 빠른 클럭속도를 얻을 수 있으나, 레이턴시가 증가한다는 단점도 있다. 이 둘을 절충하여 최적의 깊이를 찾는 것이 중요하다. 파이프라인 단계 수 설정은 기대되는 이득과 들어가는 비용을 면밀히 조사해서 결정해야 하는 아주 어려운 작업이다.
이상적인 처리율 증가(speedup)는 파이프라인 단계 수 만큼 이루어진다. 이상적으로 k단계로 나눈 파이프라인은 처리율이 k배로 증가한다. 이상적인 k배의 처리율을 얻으려면 다음 네 가지 조건이 만족되어야한다.
1. 균등한 파이프라인 단계(중요도 높음) : 파이프라인의 각 단계는 균등한 길이로 나뉜다. 파이프라인의 효율은 파이프라인 단계 중 가장 느린 단계가 결정한다.(가장 긴 파이프라인의 단계가 프로세서의 클럭 속도를 결정 짓는다.)
2. 같은 작업 : 파이프라인은 항상 같은 작업만 수행한다.
3. 독립적인 작업 : 파이프라인에 투입되는 작업은 서로 의존 관계가 없다.
4. 파이프라인 유지 비용의 최소화 : 레이턴시를 고려하여 최적의 파이프라인 깊이(pipeline depth)를 찾는다. 파이프라인 깊이를 증가시키면 처리율이 상승하는 대신, 레이턴시 또한 상승하는 경향이 있다. 파이프라인이 어느 정도 깊으면 처리율이 높아지지만 너무 깊은 파이프라인은 피해야 한다. 파이프라인은 채우는데 또 비우는데 시간이 걸리기 때문이다. 최적의 파이프라인 깊이가 결정되면 파이프라인 스톨을 최소로 줄이는 것이 핵심이다.
- 파이프라인 스톨 (pipeline stall) : 여러 가지 이유로 지연된 task로 인해 다음 단계를 처리하는 프로세서가 처리할 task가 없어 놀고 있는 상태
- IPC (Instruction Per Cycle) : 한 클럭 당 완료되는 명령어의 개수를 나타내는 단위.
- 캐시(cache)는 명령어가 완료될 때 발생하는 레이턴시를 개선하는 대표적인 수단이다. 명령어 처리율을 높일 수 있는 근본 원리는 최대한 많은 일을 병렬로 처리함에 있다. 멀티코어가 대표적인 병렬처리 수단이다. 멀티코어는 일부 캐시를 제외하고 모든 프로세서 자원을 복제하므로 병렬 처리에 이상적이다.
- 최초의 병렬 기술은 비트 수준의 병렬성(bit level parallelism)이다. 예를 들면, 32비트 정수를 AND 연산할 때 각 비트는 동시에 처리가 가능하여 계산 회로를 복제해 병렬 처리를 통해 빠르게 계산된다.
- 최초의 파이프라인 프로세서는 1960년대 초반 IBM의 7030컴퓨터였다. 그 후, 1980년대에 RISC 프로세서의 주요 구현 방식으로 자리잡게 되었다. x86 CISC 구조에서는 인텔 i486에 최초로 1989년에 구현되었다.
- 파이프라인의 단편화(pipeline fragmentation)를 줄이는 것이 파이프라인의 각 단계를 균형있게 만들어서 효율을 높이는 실질적인 방법이다. 실행시간이 오래 걸리는 단계는 분할시키고, 실행시간이 짧은 몇 가지 단계들은 서로 합쳐서 각 단계별 실행시간을 비교적 균등하게 만드는 것이 그 예시이다. 예를 들어 RISC구조에서 명령어 인출(IF)과 명령어 해독(ID)과정은 비교적 간단하므로 합쳐질 수 있다. 반면 x86 프로세서는 가변 길이의 명령어를 읽어야 하고, 복잡한 명령어 포맷과 마이크로 명령어로 변환까지 해야 하므로 IF와 ID가 해야할 일이 많다.(실행시간이 길다) 즉, 프로세서의 종류에 따라 합치고 분할하는 방법을 달리해야 함을 의미한다.
- 파이프라인 해저드(pipeline hazard) : 파이프라인 프로세서에서 의존성으로 발생할 수 있는 문제. 가장 간단한 해결방법은 해저드가 발생할 때마다 파이프라인을 멈추는 것(pipeline stall)이다. 해저드에는 구조 해저드, 데이터 해저드, 컨트롤 해저드가 있다. 파이프라인 해저드는 전적으로 파이프라인 구성에 달렸다. 파이프라인 구성과 여러 제약 조건에 따라 해저드의 형태가 언제나 다르게 나타날 수 있다.
- 구조 해저드(structual hazard) : 프로세서의 자원이 부족해서 발생하는 스톨. 간단한 해결책으로 자원을 늘리는 방법이 있다. 파이프라인 프로세서에서는 피연산자를 읽는(OF)단계에 있는 명령어와, 최종적으로 결과를 쓰는(OS/WB)명령어가 동시에 작동하므로 레지스터 파일은 반드시 최대 두 개의 읽기와 한 번의 스기가 동시에 가능해야 하며, 또 이 작업이 사이클마다 가능하게 지원해야 한다. 레지스터 파일에 많은 읽기와 쓰기를 동시에 처리하도록 하는 것(멀티 포트화)은 매우 어려운 작업이며 반도체 설계 공간도 전력도 모두 많이 소비하게 된다. 대안으로 적은 수의 읽기/쓰기 포트를 가지는 작은 크기의 컴포넌트를 여러 개 두는 방법을 쓴다. 이 단위를 캐시에서는 뱅크, 레지스터 파일은 클러스터라 부른다.
- 컨트롤 해저드(control hazard) : 컨트롤/데이터 해저드는 프로그램이 근본적으로 갖는 의존성 때문에 발생한다.
- 분기문의 경우, PC값을 구하려면 다음으로 진행될 명령어의 주소를 알기 위해 분기문의 계산이 완료될 때 까지 기다려야 한다. 그런데 이 분기문 계산을 EXE단계에 배치하게 되면 수 단계의 파이프라인 단계들이 stall 되게 되어 작지 않은 손실이 발생하게 되고, 심지어 이러한 분기문은 코드 상에서 꽤나 흔한 명령어에 속한다. 해결 방법으로는 분기문 계산을 OF단계에 배치하고 분기문 바로 다음에 분기문과 관계없이 반드시 실행되는 명령어를 배치하거나 아무 일도 하지 않는 NOP(No operation)명령어를 배치하는 지연 슬롯 기법(delay slot method)가 있으며 이런 명령어 재배치는 컴파일러에 의해 이루어진다. MIPS 프로세서에서 사용하는 방법이기도 하다. 그러나 이는 지연 슬롯에 들어간 명령어는 실제 프로그램의 순서와 다르게 완료되므로 프로그래머에게 혼동을 줄 수 있다는 단점이 있다. 이를 보완하기 위해 나온 기법이 분기 예측(branch prediction)이다.
- 분기 예측(branch prediction) : 말 그대로, 분기문의 결과를 미리 점치는 기술. 분기 여부를 미리 예측해 파이프라인을 진행시키는 것이다. 예측이 옳으면 파이프라인 스톨이 전혀 발생하지 않으므로 큰 성능 향상으로 이어지지만, 분기 예측이 틀리면 파이프라인을 비우고 다시 진행해야 한다.